Доброго времени суток, уважаемое Харбасообщество!
Под катом изложена некоторая информация касательно написания расширений для PHP c использованием C++, почерпнутая мной из различных источников (по большей части англоязычных) и ковыряния исходников Zend Engine 2 во время разработки одного модуля для собственных нужд. Так как объем ее достаточно велик, далее я старался быть краток.
Итак, в этой части:
А вот до C++ в этой части мы так и не доберемся… =)
Маленький дисклеймер: содержимое статьи не есть истина в первой инстанции, не основывается на официальной документации (а есть ли она?) и является моим субъективным взглядом на ZE 2. Тем не менее, в свое время я был бы рад найти нечто подобное на просторах Рунета, дабы сэкономить время на начальных этапах разработки.
Zend Engine 2 написан на C. Это сильно повлияло на его внутреннюю экосистему. В отсутствие класс-объектной парадигмы внутри ZE 2 расплодились глобальные переменные, свободные функции и подобия пользовательских типов данных — структуры. На все случаи жизни существуют свои комбинации простых и составных типов данных и процедур, предназначенных для их обработки.
Наиболее часто встречается структура zval (zend-значение?). Структура является представлением PHP-переменной по обратную сторону от userspace (под userspace здесь и далее будем понимать код, написанный на PHP, выполнением которого и занимается ZE, следовательно, обратная сторона userspace — это код на C).
PHP является языком со слабой динамической типизацией и автоматическим управлением памятью, переменные в этом языке могут менять свой тип на протяжении своего жизненного цикла и не требуют явного удаления программистом после того, как необходимость в них отпадает (сборщик мусора самостоятельно позаботится об этом). За эти прихоти отчасти отдуваться приходится и zval`у. На данный момент (PHP 5.3.3) эта структура определена следующим образом (zend.h):
Что же мы здесь видим? Как это не удивительно, zend-значение (zval) не является непосредственно значением переменной. Значение переменной хранится в поле value, тип которого zvalue_value (ниже). Тип значения, хранящегося в value, определяется полем type и может быть одним из следующих (zend.h):
Ага, вот они — те самые 8 типов данных PHP, которые люди так часто не могут перечислить на собеседованиях! Плюс два отдельно стоящих значения IS_CONSTANT и IS_CONSTANT_ARRAY.
Структура также содержит информацию о количестве ссылок на данную переменную (refcount__gc) и флаг, определяющий, является ли эта переменная ссылкой (is_ref__gc). Эта информация нужна для организации эффективной работы с памятью внутри ZE. Например следующая ситуация в userspace:
приведет к созданию объекта zval val, имеющего тип IS_LONG (все целочисленные в userspace соответствуют C long по другую сторону от userspace), установке у него is_ref_gc в 0 и refcount_gc в 1 (первая строка) и регистрации символа «foo» (об этом в следующих сериях) в текущей таблице символов процесса (на самом деле просто ассоциативный массив имен переменных и их значений) с val в качестве значения. На второй же строке новый экземпляр zval создан не будет. У только что помещенного в таблицу символов val`а будет увеличен на 1 счетчик ссылок, и символ «bar» будет зарегистрирован в таблице символов с этим же самым val`ом. За счет этого будет сокращено количество необходимых выделений памяти для создания новых переменных.
Когда же интерпретатор встретит код:
он извлечет из текущей таблицы символов процесса zval, соответствующий символу «bar», и, в первую очередь, проверит количество ссылок на это значение. Если оно больше 1 и zval не является ссылкой (is_ref_gc == 0), то интерпретатор создаст копию текущего значения $bar, выполнит действия с ней (в нашем случае приравняет строковому значению '42') и поместит в таблицу символов «bar» с уже новым значением. В случае же, если refcoun_gc == 1 или is_ref_gc == 1 действия будут выполнены непосредственно над значением, полученным из таблицы символов. Таким образом в следующей (достаточно искусственной, но имеющей право на жизнь) ситуации:
интерпретатор обойдется всего одним zval`ом, но двумя символами, соответствующими ему. Это возможно, потому что на строке с комментарием 1 будет создан zval val у которого количество ссылок будет равно 1. На строке c комментарием 2 будет зарегистрирован новый символ «bar» со значением val, у которого при этом refcoun_gc уже равен 2, но на строке с комментарием 3 новый zval создан не будет, так как после вызова unset($bar) количество ссылок на val снова сократится до 1.
Как не сложно догадаться is_ref_gc становится равным 1, когда в userspace встречаются конструкции вида $b = &$a.
Описанный выше подход можно назвать «отделение при модификации» (separate on write).
Теперь посмотрим на тип zvalue_value (zend.h):
Не трудно заметить, что это объединение. Это значит, что данные, лежащие в памяти по адресу переменной типа zvalue_value могут быть удобным для программиста способом проинтерпретированы как на этапе разработки, так и на этапе выполнения как любой из типов данных, входящих в состав объединения. Именно эта особенность zvalue_value позволяет userspace-переменным PHP так легко менять свой тип в течение жизни (напомню, что текущий тип переменной zval можно выяснить, обратившись к ее полю type).
Однако, вы можете сказать, что видите здесь всего 5 уникальных полей, а типов данных 8. Отображение типов PHP на объединение zvalue_value следующее:
Что же полезного можно вынести из рассмотрения структуры zvalue_value?
Вот мы и добрались до объектов. Структура zend_object_value предназначена для представления userspace-переменных, содержащими в себе объекты. А что из себя представляют объект в класс-объектной парадигме? Объект — это симбиоз данных и методов по их обработке. Теперь давайте посмотрим на структуру zend_object_value (zend_type.h):
Структура представляет собой объединение некоторого целочисленного идентификатора (handle) и еще одной структуры (zend_object_handlers *handlers), содержащей в себе указатели на функции, которые будут вызываться движком ZE 2 при наступлении тех или иных событий, связанных с объектом. К таким событиям относятся: приравнивание новой переменной значения переменной, содержащей в себе объект (zend_object_add_ref_t add_ref), выход за пределы области видимости, инициализация другим значением или вызов unset для переменной, содержащей в себе объект (zend_object_del_ref_t del_ref), клонирование объекта вызовом __clone ( zend_object_clone_obj_t clone_obj), обращение к свойству объекта (zend_object_read_property_t read_property), запись свойства объекта (zend_object_write_property_t write_property) и т.д. Сама структура zend_object_handlers выглядит следующим образом (zend_object_handlers.h):
а прочитать о ней подробно можно здесь.
Отвлеклись, вернемся к zend_object_value. Итак, что в ней содержится помимо указателей на функции-обработчики событий? А ничего! Если некое подобие попытки определения поведения объекта мы увидели в _zend_object_handlers, то кроме какого-то странного идентификатора (handle) никаких данных, специфичных для конкретного экземпляра в ней не наблюдается. Но идентификатор сам по себе (сферический в вакууме) смысла не имеет. Значит должно быть какое-то хранилище однородных сущностей, где этот идентификатор будет отличать одну сущность от другой.
Таким хранилищем в ZE является Zend Object Storage. Ключами в нем являются дескрипторы объектов (zend_object_value.handle), а значениями… Да, да, вы уже наверное догадались — еще один вид структур — zend_object (zend.h):
Здесь из разрозненных кусочков уже начинает складываться картинамаслом. HashTable *properties — вот где можно держать данные, специфичные для конкретного экземпляра. Поле properties — это стандартный для ZE ассоциативный массив, ключами которого должны являться имена полей класса текущего объект, а значениями — текущие значения полей (свойств) этого объекта.
Итак, на данный момент мы имеем следующие возможности для работы с объектами — умеем переопределять стандартное поведение объекта в тех или иных ситуация (за счет переопределения соответствующих функций в zend_object_handlers) и можем хранить данные в полях экземпляров, записывая их в HashTable *properties, связанную с текущим объектом. Чего-то не хватает… Ах да, а как же добавлять пользовательское поведение объекту (создавать новые методы)? Так как методы — это нечто общее для всех объектов одного класса, их логично было бы разместить в некоторой структуре, разделяемый доступ к которой был бы у всех объектов класса. Такой структурой является zend_class_entry (zend.h):
Назначение структуры zend_class_entry — представлять общие аспекты всех объектов одного класса. zend_class_entry фактически и есть сам класс. Структура, как видите, не маленькая и рассматривать назначение каждого из ее полей не есть задача этой статьи. Остановим наше внимание на полях, которые я пометил комментариями.
const struct _zend_function_entry *builtin_functions — указатель на массив структур _zend_function_entry. Не трудно догадаться, что это и есть методы нашего будущего класса. Так как он помечен модификатором const, изменять элементы этого массива (т.е. переопределять методы инстанцированного объекта класса) не возможно (в отличие от zend_object_value.handlers).
Поля, начиная с constructor по unserialize_func, являются магическими методами PHP (не трудно догадаться, что unserialize_func — это __wakeup, а serialize_func — это __sleep, остальные же методы имеют схожую мнемонику).
В процессе создания собственного расширения можно как добавлять записи в builtin_functions, так и переопределять магические методы будущего класса.
Последним, но не по значению, героем этого экскурса в увлекательный мир структур ZE, будет структура, которая занимается представлением самого модуля расширения — zend_module_entry (zend_modules.h):
Так как в общем случае расширение может реализовывать не один, а сразу несколько классов, или же наоборот — экспортировать одни лишь функции (на ООП свет клином не сошелся, как говорится), рассмотрим, как это повлияло на дизайн вышеупомянутой структуры:
В предыдущем пункте мы рассмотрели путь от рядового zval до генерала zend_module_entry. Умело оперируя этими типами, можно создать свое расширение PHP и организовать слаженную фабрику по производству объектов. На самом деле, модуль расширения PHP похож на школу по подготовке кадров для userspace. Сначала ее нужно построить (вызвать PHP_MINIT_FUNCTION) и зарегистрировать на бирже труда (объявив в PHP_MINIT_FUNCTION экспортируемые классы или функции) в качестве рекрутерского агенства с определенной направленностью, а затем по первому запросу на получение сотрудника (нового экземпляра класса) запускать цикл по подготовке бойца (создания объекта). Подготовка заключается в выделении памяти под создаваемый объект, связывании его со специфическими обработчиками событий (zend_object_handlers) и собственным классом (zend_class_entry), в котором содержатся методы будущего объекта, и регистрации объекта в Zend Object Storage с последующим присвоением ему уникального идентификатора. Такая подготовка обычно помещается в функцию имя_расширения_objects_new и связывается с полем zend_class_entry.create_object.
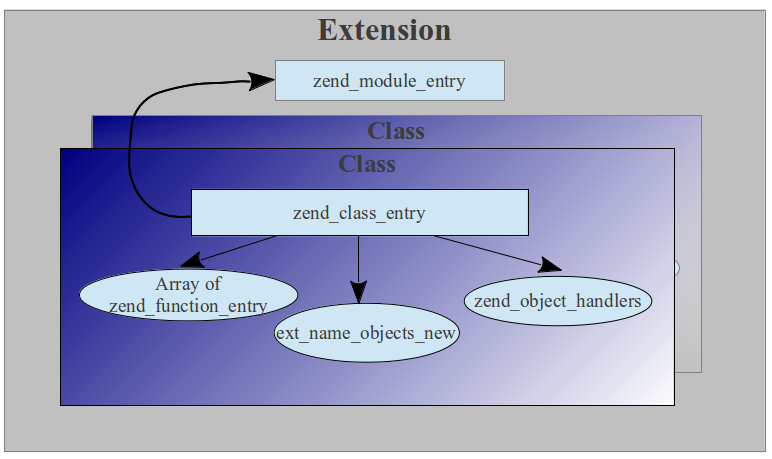
Схематически, структуру расширения можно изобразить в следующем виде:
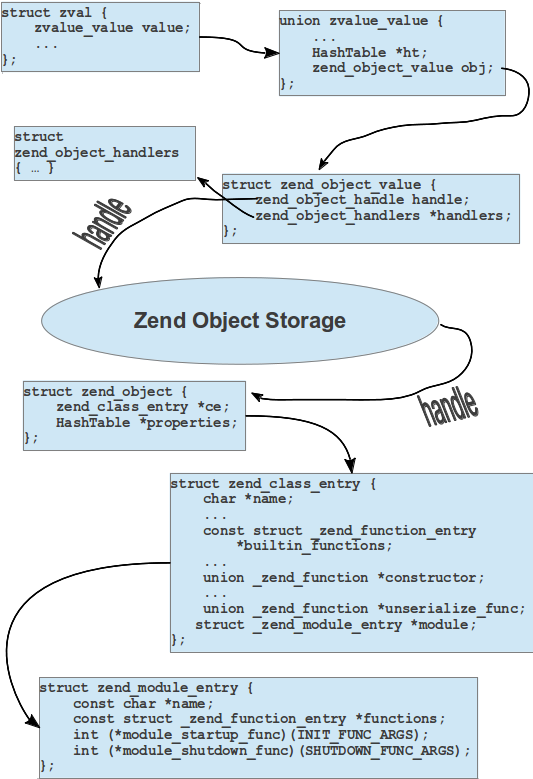
А чтобы более наглядно представить себе иерархию типов данных в расширении приведу следующую схемку:
В статье получилось много текста и совсем мало кода, но без экскурса в мир типов данных ZE 2 пытаться понять назначение вызовов тех или иных функций было бы достаточно сложно. В следующей части я приведу объяснение первых шагов, которые нужно выполнить, чтобы создать свой модуль расширения PHP, но перед этим затрону тему работы с zval`ами и управления выделением памятью.
P.S. Отличная подборка статей для интересующихся лежит здесь.
Под катом изложена некоторая информация касательно написания расширений для PHP c использованием C++, почерпнутая мной из различных источников (по большей части англоязычных) и ковыряния исходников Zend Engine 2 во время разработки одного модуля для собственных нужд. Так как объем ее достаточно велик, далее я старался быть краток.
Итак, в этой части:
А вот до C++ в этой части мы так и не доберемся… =)
Маленький дисклеймер: содержимое статьи не есть истина в первой инстанции, не основывается на официальной документации (а есть ли она?) и является моим субъективным взглядом на ZE 2. Тем не менее, в свое время я был бы рад найти нечто подобное на просторах Рунета, дабы сэкономить время на начальных этапах разработки.
Внутренний мир Zend Engine 2
Основные типы данных
Zend Engine 2 написан на C. Это сильно повлияло на его внутреннюю экосистему. В отсутствие класс-объектной парадигмы внутри ZE 2 расплодились глобальные переменные, свободные функции и подобия пользовательских типов данных — структуры. На все случаи жизни существуют свои комбинации простых и составных типов данных и процедур, предназначенных для их обработки.
Наиболее часто встречается структура zval (zend-значение?). Структура является представлением PHP-переменной по обратную сторону от userspace (под userspace здесь и далее будем понимать код, написанный на PHP, выполнением которого и занимается ZE, следовательно, обратная сторона userspace — это код на C).
PHP является языком со слабой динамической типизацией и автоматическим управлением памятью, переменные в этом языке могут менять свой тип на протяжении своего жизненного цикла и не требуют явного удаления программистом после того, как необходимость в них отпадает (сборщик мусора самостоятельно позаботится об этом). За эти прихоти отчасти отдуваться приходится и zval`у. На данный момент (PHP 5.3.3) эта структура определена следующим образом (zend.h):
typedef struct _zval_struct zval; struct _zval_struct { /* Variable information */ zvalue_value value; /* value */ zend_uint refcount__gc; zend_uchar type; /* active type */ zend_uchar is_ref__gc; };
Что же мы здесь видим? Как это не удивительно, zend-значение (zval) не является непосредственно значением переменной. Значение переменной хранится в поле value, тип которого zvalue_value (ниже). Тип значения, хранящегося в value, определяется полем type и может быть одним из следующих (zend.h):
#define IS_NULL 0 #define IS_LONG 1 #define IS_DOUBLE 2 #define IS_BOOL 3 #define IS_ARRAY 4 #define IS_OBJECT 5 #define IS_STRING 6 #define IS_RESOURCE 7 #define IS_CONSTANT 8 #define IS_CONSTANT_ARRAY 9
Ага, вот они — те самые 8 типов данных PHP, которые люди так часто не могут перечислить на собеседованиях! Плюс два отдельно стоящих значения IS_CONSTANT и IS_CONSTANT_ARRAY.
Структура также содержит информацию о количестве ссылок на данную переменную (refcount__gc) и флаг, определяющий, является ли эта переменная ссылкой (is_ref__gc). Эта информация нужна для организации эффективной работы с памятью внутри ZE. Например следующая ситуация в userspace:
<?php $foo = 5; // 1 $bar = $foo; // 2
приведет к созданию объекта zval val, имеющего тип IS_LONG (все целочисленные в userspace соответствуют C long по другую сторону от userspace), установке у него is_ref_gc в 0 и refcount_gc в 1 (первая строка) и регистрации символа «foo» (об этом в следующих сериях) в текущей таблице символов процесса (на самом деле просто ассоциативный массив имен переменных и их значений) с val в качестве значения. На второй же строке новый экземпляр zval создан не будет. У только что помещенного в таблицу символов val`а будет увеличен на 1 счетчик ссылок, и символ «bar» будет зарегистрирован в таблице символов с этим же самым val`ом. За счет этого будет сокращено количество необходимых выделений памяти для создания новых переменных.
Когда же интерпретатор встретит код:
... $bar = '42';
он извлечет из текущей таблицы символов процесса zval, соответствующий символу «bar», и, в первую очередь, проверит количество ссылок на это значение. Если оно больше 1 и zval не является ссылкой (is_ref_gc == 0), то интерпретатор создаст копию текущего значения $bar, выполнит действия с ней (в нашем случае приравняет строковому значению '42') и поместит в таблицу символов «bar» с уже новым значением. В случае же, если refcoun_gc == 1 или is_ref_gc == 1 действия будут выполнены непосредственно над значением, полученным из таблицы символов. Таким образом в следующей (достаточно искусственной, но имеющей право на жизнь) ситуации:
<?php $foo = 100500; //1 $bar = $foo; //2 echo $bar; unset($bar); $foo = '42'; //3
интерпретатор обойдется всего одним zval`ом, но двумя символами, соответствующими ему. Это возможно, потому что на строке с комментарием 1 будет создан zval val у которого количество ссылок будет равно 1. На строке c комментарием 2 будет зарегистрирован новый символ «bar» со значением val, у которого при этом refcoun_gc уже равен 2, но на строке с комментарием 3 новый zval создан не будет, так как после вызова unset($bar) количество ссылок на val снова сократится до 1.
Как не сложно догадаться is_ref_gc становится равным 1, когда в userspace встречаются конструкции вида $b = &$a.
Описанный выше подход можно назвать «отделение при модификации» (separate on write).
Теперь посмотрим на тип zvalue_value (zend.h):
typedef union _zvalue_value { long lval; /* long value */ double dval; /* double value */ struct { char *val; int len; } str; HashTable *ht; /* hash table value */ zend_object_value obj; } zvalue_value;
Не трудно заметить, что это объединение. Это значит, что данные, лежащие в памяти по адресу переменной типа zvalue_value могут быть удобным для программиста способом проинтерпретированы как на этапе разработки, так и на этапе выполнения как любой из типов данных, входящих в состав объединения. Именно эта особенность zvalue_value позволяет userspace-переменным PHP так легко менять свой тип в течение жизни (напомню, что текущий тип переменной zval можно выяснить, обратившись к ее полю type).
Однако, вы можете сказать, что видите здесь всего 5 уникальных полей, а типов данных 8. Отображение типов PHP на объединение zvalue_value следующее:
- long lval — целочисленные (integer), логический тип (boolean) и ресурсы (resource)
- double dval — тут однозначно (double)
- struct… str — строки PHP (string)
- HashTable *ht — массивы (array)
- zend_object_value obj — объекты PHP (object) — как SPL, так и пользовательские.
- null — значение не имеет никакого значения (zval.type == IS_NULL).
Что же полезного можно вынести из рассмотрения структуры zvalue_value?
- Тип resource представлен только лишь целочисленным идентификатором, и поэтому в userspace выглядит темной лошадкой. По другую сторону от userspace такому идентификатору может быть сопоставлен дескриптор открытого файла, TCP сокет, объект соединения с БД и т.п. Сопоставление происходит через специальное хранилище ресурсов (на стороне C, естественно).
- Все вещественные в PHP имеют двойную точность и занимают 8 байт.
- Строки в принципе могут быть binary safe, т.е. использовать внутри себя нулевые символы. Достигается за счет того, что длина строки хранится вместе с указателем на память, где эта строка располагается. Операция strlen является быстрой в userspace. Нулевой символ на конце строки не обязателен. На самом же деле многие расширения используют именно нуль-терминированные строки и не брезгуют сишной strlen.
- Массивы представлены внутренним типом HashTable. HashTable — это очередная структура, но рассмотрение ее и принципов работы с ней выходит за рамки этой статьи.
- Объекты в PHP представляются структурой zend_object_value. О ней мы поговорим далее, так как именно с созданием собственного типа данных и связана разработка нашего расширения.
- Создание переменной в PHP потратит минимум 16 байт на 32-битной архитектуре, какого бы типа переменная не была (складываем размеры полей zval с учетом того, что размер объединения равен размеру максимального из полей в его составе).
Вот мы и добрались до объектов. Структура zend_object_value предназначена для представления userspace-переменных, содержащими в себе объекты. А что из себя представляют объект в класс-объектной парадигме? Объект — это симбиоз данных и методов по их обработке. Теперь давайте посмотрим на структуру zend_object_value (zend_type.h):
typedef unsigned int zend_object_handle; typedef struct _zend_object_handlers zend_object_handlers; typedef struct _zend_object_value { zend_object_handle handle; zend_object_handlers *handlers; } zend_object_value;
Структура представляет собой объединение некоторого целочисленного идентификатора (handle) и еще одной структуры (zend_object_handlers *handlers), содержащей в себе указатели на функции, которые будут вызываться движком ZE 2 при наступлении тех или иных событий, связанных с объектом. К таким событиям относятся: приравнивание новой переменной значения переменной, содержащей в себе объект (zend_object_add_ref_t add_ref), выход за пределы области видимости, инициализация другим значением или вызов unset для переменной, содержащей в себе объект (zend_object_del_ref_t del_ref), клонирование объекта вызовом __clone ( zend_object_clone_obj_t clone_obj), обращение к свойству объекта (zend_object_read_property_t read_property), запись свойства объекта (zend_object_write_property_t write_property) и т.д. Сама структура zend_object_handlers выглядит следующим образом (zend_object_handlers.h):
struct _zend_object_handlers { /* general object functions */ zend_object_add_ref_t add_ref; zend_object_del_ref_t del_ref; zend_object_clone_obj_t clone_obj; /* individual object functions */ zend_object_read_property_t read_property; zend_object_write_property_t write_property; zend_object_read_dimension_t read_dimension; zend_object_write_dimension_t write_dimension; zend_object_get_property_ptr_ptr_t get_property_ptr_ptr; zend_object_get_t get; zend_object_set_t set; zend_object_has_property_t has_property; zend_object_unset_property_t unset_property; zend_object_has_dimension_t has_dimension; zend_object_unset_dimension_t unset_dimension; zend_object_get_properties_t get_properties; zend_object_get_method_t get_method; zend_object_call_method_t call_method; zend_object_get_constructor_t get_constructor; zend_object_get_class_entry_t get_class_entry; zend_object_get_class_name_t get_class_name; zend_object_compare_t compare_objects; zend_object_cast_t cast_object; zend_object_count_elements_t count_elements; zend_object_get_debug_info_t get_debug_info; zend_object_get_closure_t get_closure; };
а прочитать о ней подробно можно здесь.
Отвлеклись, вернемся к zend_object_value. Итак, что в ней содержится помимо указателей на функции-обработчики событий? А ничего! Если некое подобие попытки определения поведения объекта мы увидели в _zend_object_handlers, то кроме какого-то странного идентификатора (handle) никаких данных, специфичных для конкретного экземпляра в ней не наблюдается. Но идентификатор сам по себе (сферический в вакууме) смысла не имеет. Значит должно быть какое-то хранилище однородных сущностей, где этот идентификатор будет отличать одну сущность от другой.
Таким хранилищем в ZE является Zend Object Storage. Ключами в нем являются дескрипторы объектов (zend_object_value.handle), а значениями… Да, да, вы уже наверное догадались — еще один вид структур — zend_object (zend.h):
typedef struct _zend_object { zend_class_entry *ce; HashTable *properties; HashTable *guards; /* protects from __get/__set ... recursion */ } zend_object;
Здесь из разрозненных кусочков уже начинает складываться картина
Итак, на данный момент мы имеем следующие возможности для работы с объектами — умеем переопределять стандартное поведение объекта в тех или иных ситуация (за счет переопределения соответствующих функций в zend_object_handlers) и можем хранить данные в полях экземпляров, записывая их в HashTable *properties, связанную с текущим объектом. Чего-то не хватает… Ах да, а как же добавлять пользовательское поведение объекту (создавать новые методы)? Так как методы — это нечто общее для всех объектов одного класса, их логично было бы разместить в некоторой структуре, разделяемый доступ к которой был бы у всех объектов класса. Такой структурой является zend_class_entry (zend.h):
struct _zend_class_entry { char type; char *name; zend_uint name_length; struct _zend_class_entry *parent; int refcount; zend_bool constants_updated; zend_uint ce_flags; HashTable function_table; HashTable default_properties; HashTable properties_info; HashTable default_static_members; HashTable *static_members; HashTable constants_table; const struct _zend_function_entry *builtin_functions; //ПОЛЬЗОВАТЕЛЬСКИЕ МЕТОДЫ union _zend_function *constructor; //МЕТОДЫ, КОТОРЫМИ ОБЛАДАЮТ ОБЪЕКТЫ union _zend_function *destructor; //ЛЮБОГО БЕЗ ИСКЛЮЧЕНИЯ КЛАССА union _zend_function *clone; union _zend_function *__get; union _zend_function *__set; union _zend_function *__unset; union _zend_function *__isset; union _zend_function *__call; union _zend_function *__callstatic; union _zend_function *__tostring; union _zend_function *serialize_func; union _zend_function *unserialize_func; zend_class_iterator_funcs iterator_funcs; /* handlers */ zend_object_value (*create_object)(zend_class_entry *class_type TSRMLS_DC); zend_object_iterator *(*get_iterator)(zend_class_entry *ce, zval *object, int by_ref TSRMLS_DC); int (*interface_gets_implemented)(zend_class_entry *iface, zend_class_entry *class_type TSRMLS_DC); /* a class implements this interface */ union _zend_function *(*get_static_method)(zend_class_entry *ce, char* method, int method_len TSRMLS_DC); /* serializer callbacks */ int (*serialize)(zval *object, unsigned char **buffer, zend_uint *buf_len, zend_serialize_data *data TSRMLS_DC); int (*unserialize)(zval **object, zend_class_entry *ce, const unsigned char *buf, zend_uint buf_len, zend_unserialize_data *data TSRMLS_DC); zend_class_entry **interfaces; zend_uint num_interfaces; char *filename; zend_uint line_start; zend_uint line_end; char *doc_comment; zend_uint doc_comment_len; struct _zend_module_entry *module; };
Назначение структуры zend_class_entry — представлять общие аспекты всех объектов одного класса. zend_class_entry фактически и есть сам класс. Структура, как видите, не маленькая и рассматривать назначение каждого из ее полей не есть задача этой статьи. Остановим наше внимание на полях, которые я пометил комментариями.
const struct _zend_function_entry *builtin_functions — указатель на массив структур _zend_function_entry. Не трудно догадаться, что это и есть методы нашего будущего класса. Так как он помечен модификатором const, изменять элементы этого массива (т.е. переопределять методы инстанцированного объекта класса) не возможно (в отличие от zend_object_value.handlers).
Поля, начиная с constructor по unserialize_func, являются магическими методами PHP (не трудно догадаться, что unserialize_func — это __wakeup, а serialize_func — это __sleep, остальные же методы имеют схожую мнемонику).
В процессе создания собственного расширения можно как добавлять записи в builtin_functions, так и переопределять магические методы будущего класса.
Последним, но не по значению, героем этого экскурса в увлекательный мир структур ZE, будет структура, которая занимается представлением самого модуля расширения — zend_module_entry (zend_modules.h):
struct _zend_module_entry { unsigned short size; unsigned int zend_api; unsigned char zend_debug; unsigned char zts; const struct _zend_ini_entry *ini_entry; const struct _zend_module_dep *deps; const char *name; const struct _zend_function_entry *functions; int (*module_startup_func)(INIT_FUNC_ARGS); int (*module_shutdown_func)(SHUTDOWN_FUNC_ARGS); int (*request_startup_func)(INIT_FUNC_ARGS); int (*request_shutdown_func)(SHUTDOWN_FUNC_ARGS); void (*info_func)(ZEND_MODULE_INFO_FUNC_ARGS); const char *version; size_t globals_size; #ifdef ZTS ts_rsrc_id* globals_id_ptr; #else void* globals_ptr; #endif void (*globals_ctor)(void *global TSRMLS_DC); void (*globals_dtor)(void *global TSRMLS_DC); int (*post_deactivate_func)(void); int module_started; unsigned char type; void *handle; int module_number; char *build_id; };
Так как в общем случае расширение может реализовывать не один, а сразу несколько классов, или же наоборот — экспортировать одни лишь функции (на ООП свет клином не сошелся, как говорится), рассмотрим, как это повлияло на дизайн вышеупомянутой структуры:
- const struct _zend_function_entry *functions — указатель на массив функций, экспортируемых расширением. По аналогии с zend_class_entry.builtin_functions.
- int (*module_startup_func)(INIT_FUNC_ARGS) — указатель на функцию, которая будет вызвана при подключении расширения. В частности, если расширение экспортирует классы, именно в этой функции классы должны быть зарегистрированы во внутреннем реестре классов ZE 2.
- int (*module_shutdown_func)(SHUTDOWN_FUNC_ARGS) — указатель на функцию, которая вызывается при выгрузке расширения. Здесь мы должны подтереть за собой.
Иерархия типов данных
В предыдущем пункте мы рассмотрели путь от рядового zval до генерала zend_module_entry. Умело оперируя этими типами, можно создать свое расширение PHP и организовать слаженную фабрику по производству объектов. На самом деле, модуль расширения PHP похож на школу по подготовке кадров для userspace. Сначала ее нужно построить (вызвать PHP_MINIT_FUNCTION) и зарегистрировать на бирже труда (объявив в PHP_MINIT_FUNCTION экспортируемые классы или функции) в качестве рекрутерского агенства с определенной направленностью, а затем по первому запросу на получение сотрудника (нового экземпляра класса) запускать цикл по подготовке бойца (создания объекта). Подготовка заключается в выделении памяти под создаваемый объект, связывании его со специфическими обработчиками событий (zend_object_handlers) и собственным классом (zend_class_entry), в котором содержатся методы будущего объекта, и регистрации объекта в Zend Object Storage с последующим присвоением ему уникального идентификатора. Такая подготовка обычно помещается в функцию имя_расширения_objects_new и связывается с полем zend_class_entry.create_object.
Схематически, структуру расширения можно изобразить в следующем виде:
А чтобы более наглядно представить себе иерархию типов данных в расширении приведу следующую схемку:
Заключение
В статье получилось много текста и совсем мало кода, но без экскурса в мир типов данных ZE 2 пытаться понять назначение вызовов тех или иных функций было бы достаточно сложно. В следующей части я приведу объяснение первых шагов, которые нужно выполнить, чтобы создать свой модуль расширения PHP, но перед этим затрону тему работы с zval`ами и управления выделением памятью.
P.S. Отличная подборка статей для интересующихся лежит здесь.

