Введение
Ни для кого не секрет, что такой архитектурный антипаттерн как God object препятствует эффективному поддерживанию кода проекта. Однако его все равно можно встретить в Legacy-системах корпоративного сектора. Со временем код становится настолько сложным, что изменить его функциональность, даже при наличии Unit-тестирования, становится большой проблемой. Такие системы никто не хочет поддерживать, все боятся что-либо улучшать, количество проблем в трекере держится постоянным числом, но может и расти. Как правило, у команды упавшее настроение, которое со временем становится чемоданным: все хотят свалить.

Часто в таких случаях генеральное руководство идет на рискованный шаг: не останавливая поддержки старой системы (чем-то же зарплату выдавать нужно), начать проектирование и разработку новой системы на основе опыта прошлых лет. В ходе своей работы в роли архитектора в одной компании мне пришлось вгрызаться в написанную до меня систему, изучать ее, вылавливать закономерности, бизнес-правила, да еще делать это так, чтобы изменения были экономически эффективным.
Взгляд в код
Анализируемая система является слоем доступа к базе данных и представляет собой класс с интерфейсом, содержащим большое число методов. Внутри каждого метода содержится SQL-запрос к базе данных в формате строки и вызов хелпер-класса, выполняющего операции подстановки параметров, чтения и записи данных. Этот слой используется в Web-части приложения, которая вызывает отдельные методы. Такой незамысловатый способ применялся на протяжении многих лет. Были некоторые попытки со стороны разработчиков решить назревшую проблему, однако успеха не получили: требуемое фичивание заглушало процессы улучшения кодовой базы. В конце концов проект, начатый почти десяток лет назад, стал требовать капитального ремонта.
Было необходимо подготовить кодовую базу проекта к категоричному и эффективному пересмотру в сжатые сроки: разбить на понимаемые части, очистить от рудиментов. В конечном итоге хотелось бы из одного GodObject получить классы доступа к данным, каждый из которых ответственен только за какой-то конкретный участок системы, а не всю систему целиком. Было бы здорово выделить такие классы на каждую таблицу, если это получится.
План работ
Задача решалась в несколько этапов:
- Сбор количественной информации кода слоя доступа к данным.
- Анализ количества таблиц, используемых методом.
- Анализ количества методов, использующих таблицу.
- Кластеризация методов с учета используемых ими таблиц.
- Группировка кластеров по видам сущностей предметной области.
- Автоматический рефакторинг переноса методов в рассчитанные кластеры-классы.
- Ручное исправление особых случаев.
Жирным выделены те пункты, которые рассмотрены в этой статье. Остальные в следующей.
Поехали!
Сбор количественной информации
Так как кульминационной стадией задачи является кластеризация полученных данных, то необходимо собрать данные в таком виде, в котором было бы удобно отражать связи между методами и таблицами. На мой взгляд, таким форматом может служить матрица, строки которой отражают методы, столбцы — таблицы, а ячейки могут принимать два значения: 0 (таблица методом не используется) и 1 (таблица методом используется):
| Таблица 1 | Таблица 2 | |
| Метод 1 | 1 | 1 |
| Метод 2 | 0 | 1 |
Остается только собрать такие данные по коду. Слой доступа к данным написан на C#, что несколько упрощает эту задачу. Есть такой проект, как NRefactory. Он представляет из себя парсер и преобразователь C#-кода для таких широко известных в узких кругах IDE как SharpDevelop и (с недавнего момента) MonoDevelop. Вменяемой документации на текущую версию найти не удалось, зато есть отличная демка, из которой понятны основные принципы работы с библиотекой. За пару часов был написан сборщик
Анализ
После получения искомой матрицы, мне было интересно посмотреть, как выглядят графики количества таблиц на один метод и количества методов на таблицу, если после суммирования по строкам и столбцам отсортировать данные в убывающем порядке. Результат представлен на рисунках 1 и 2.
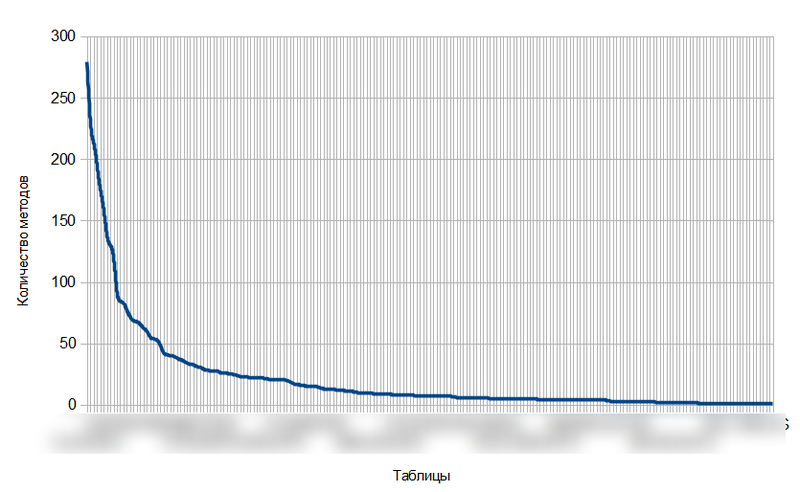
Рисунок 1.
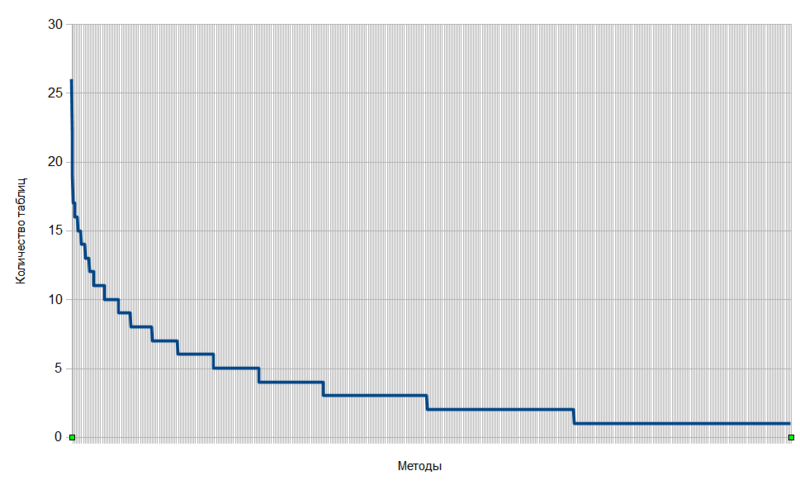
Рисунок 2.
На обоих графиках можно выделить три области:
1. Область крутого подъема (в начале графиков).
2. Область плавного спуска (в конце графиков).
3. Область вида “вроде бы подъем, хотя уже спуск” (в середине графиков).
Мы могли бы задаться некоторыми величинами для определения коридора 3-ей области, однако быстрый гуглинг не дал каких-либо вменяемых результатов, а разрабатывать свои показатели на основе какого-нибудь среднего не хотелось — все равно бы вышла игра в салки. Поэтому я выполнил разбивку обоих графиков на три кластера с помощью алгоритма карт Кохонена в ПО Deductor. Пример результата для случая количества методов на таблицу показан на рисунке 3.
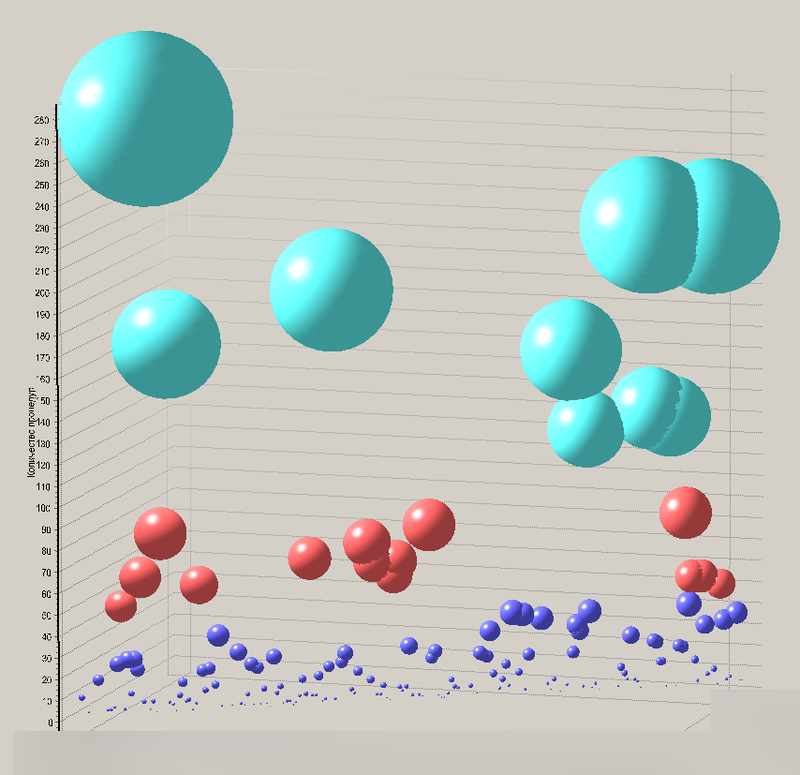
Рисунок 3. Диаграмма результата кластеризации таблиц. Tаблицы изображены в виде шаров, цвет шара определяется номером кластера, а его радиус — количеством методов, использующих эту таблицу.
Рассмотрим подробнее диаграмму на рисунке 3. На ней хорошо видно, что есть некоторые такие таблицы, которые входят в большое число методов. Я предполагаю, что сущности, представленные этими таблицами, являются основными, базовыми, “агрегационными” (если говорить в терминологии DDD): они используются практически во всех бизнес-операциях. Следующая устойчивая группа, отмеченная красным цветом, может представлять собой такие сущности, которые являются наиболее характерными представителями отдельных служб и модулей системы. Это основное поле действий в будущем. Последняя группа, отмеченная синим цветом, представляет собой маленькие сущности, которые, скорее всего, являются локально значимыми в пределах службы. Таким образом было получено черновое представление системы в виде набора служб, простых сущностей и корней агрегации.
Следующим этапом является такой же анализ рисунка 2, однако в этом случае можно предположить, что выделенные три группы (и еще одни частный случай) представляют собой:
- Очень сложные методы, кластеризацию которых в автоматическом режиме выполнить вряд ли получится. Представляют собой жуткий спагетти-код, собирающий куски огромного SQL-запроса в единое демоническое целое и шарахающее результат в пользователя. Только ручная работа, только хардкор.
- Сложные методы, с которыми надежда еще есть. Их все равно придется рефакторить руками, однако выполнить кластеризацию попробовать можно.
- Простые методы, затрагивающие не более 6-ти таблиц. Результат кластеризации должен быть очень хорошим.
- Как особый случай, можно выделить методы, оперирующие всего одной таблицей, для них кластеризацию выполнять не нужно, здесь и так все понятно. Т.е. мы еще даже не подошли к кульминационной части, а уже почти 25% всей работы сделали.
Итоги
Подведу некоторые итоги, статья получилась немаленькая, а все еще впереди. Удалось взглянуть на проблему с дальней дистанции, выяснить некоторые особенности предметной области. Уже понятно, какие объекты являются ключевыми, а какие — второстепенными. Далее, на основе выделенных методов, оперирующих одной таблицей, уже можно выделить некоторые классы. Если учесть, что таких методов 25%, то уже на четверть подзадача анализа решена.
Что дальше?
В следующей части (частях?): завершение анализа, автоматическое выделение классов на основе результатов кластеризации, создание инструмента на основе SDK Resharper для более тонкого выделения классов и методов в ручном режиме.
- Интересно ли почитать статью по NRefactory?
- Стоит ли написать отдельно статью по написанию рефакторингов в Resharper?
- Кто-либо занимался чем-то подобным? Очень интересны результаты, гуглинг что-то не помогает.
- А как выглядят такие графики у вас?

