Сейчас на хабре продолжают обсуждать сортировки и рейтингования сущностей (записей, постов, комментов), так что я сам этим заинтересовался и, как раз находясь на реддите, решил узнать как там работает сортировка, и наткнулся на отличную и короткую статью.
Этот пост — продолжение разбора алгоритмов сортировки (в прошлый раз был Hacker News). В этот раз, мы разберем как работает сортировка постов и комментариев на Reddit. Алгоритмы у Реддита достаточно простые, чтобы понять их и реализовать.
Первая часть этой записи будет сфокусирована на сортировке постов, а вторая на сортировке комментариев. Они довольно сильно различаются, и за идеей способа сортировки комментариев стоит Randall Munroe (автор xkcd).
Реддит open-source-ный проект и его код полностью доступен на гитхабе. Он написан на питоне, исходники вы можете увидеть тут. Их алгоритмы сортировки написаны под Pyrex, для дальнейшей компиляции (трансляции) в C-код. Pyrex был выбран из-за производительности. Я переписал их реализации на чистый питон, чтобы они легче читались.
Дефолтный алгоритм сортировки, названный «hot ranking» реализуется так:
В математической записи, этот алгоритм выглядит так:

Вот что можно сказать об устаревании относительно сортировочных рейтингов (далее просто рейтингов) и сортировки:
Вот визуализация, как выглядит рейтинг статей с одинаковым кол-вом плюсов и минусов, но разным временем публикации:

Hot ranking использует логарифм для того, чтобы первые n голосов весили больше чем будущие n+r голоса. В итоге получается, что первые 10 плюсов имеют такой же вес, как следующие 100, которые имеют такой же вес как следующие 1000, и т.д.
Вот как это выглядит:

А вот как выглядело бы без логарифма:

Реддит — один из тех сайтов, на котором можно минусовать. Как вы видели в коде, «score» поста равен разнице плюсов и минусов.
В итоге это выглядит так:
Это оказывает большое влияние на посты, которые получают много плюсов и минусов (т.н. спорные посты), они получают меньший рейтинг, чем посты только с плюсами. Наверное поэтому котята так часто бывают на главной :) (прим. пер. — на самом деле это из-за того, что вы не отписались от /r/aww)
Randall Munroe из xkcd стоит за идеей Реддитовского best ranking. Он написал отличную статью про это: reddit's new comment sorting system
Вам стоит прочитать эту статью, в ней он очень понятно объясняет принцип работы алгоритма. Резюмируя ее, можно сказать:
Алгоритм сортировки по доверию реализован в _sorts.pyx, я его также переписал на чистый питон (и убрал некоторые кеширующие оптимизации):
Сортировка по доверию использует Вильсоновский интервал и математическая запись выглядит так:

Список параметров этой формулы:
Давайте подведем итог сказанному выше:
У Рэнделла есть отличный пример, как происходит рейтингование комментариев:
Как мы видим, на этот алгоритм никак не влияет устаревание записей.
Давайте посмотрим, как это выглядит:

Как вы видите, такую сортировку волнует не сколько голосов получил комментарий, а сколько плюсов в отношении к общему числу голосов и размеру выборки.
Как отмечает Evan Miller, Вилсоновский интервал можно использовать не только для рейтинга.
Вот три примера, которые он привел:
Этот пост — продолжение разбора алгоритмов сортировки (в прошлый раз был Hacker News). В этот раз, мы разберем как работает сортировка постов и комментариев на Reddit. Алгоритмы у Реддита достаточно простые, чтобы понять их и реализовать.
Первая часть этой записи будет сфокусирована на сортировке постов, а вторая на сортировке комментариев. Они довольно сильно различаются, и за идеей способа сортировки комментариев стоит Randall Munroe (автор xkcd).
Разбираем сортировку постов
Реддит open-source-ный проект и его код полностью доступен на гитхабе. Он написан на питоне, исходники вы можете увидеть тут. Их алгоритмы сортировки написаны под Pyrex, для дальнейшей компиляции (трансляции) в C-код. Pyrex был выбран из-за производительности. Я переписал их реализации на чистый питон, чтобы они легче читались.
Дефолтный алгоритм сортировки, названный «hot ranking» реализуется так:
#Rewritten code from /r2/r2/lib/db/_sorts.pyx from datetime import datetime, timedelta from math import log epoch = datetime(1970, 1, 1) def epoch_seconds(date): """Returns the number of seconds from the epoch to date.""" td = date - epoch return td.days * 86400 + td.seconds + (float(td.microseconds) / 1000000) def score(ups, downs): return ups - downs def hot(ups, downs, date): """The hot formula. Should match the equivalent function in postgres.""" s = score(ups, downs) order = log(max(abs(s), 1), 10) sign = 1 if s > 0 else -1 if s < 0 else 0 seconds = epoch_seconds(date) - 1134028003 return round(order + sign * seconds / 45000, 7)
В математической записи, этот алгоритм выглядит так:
Устаревание записей
Вот что можно сказать об устаревании относительно сортировочных рейтингов (далее просто рейтингов) и сортировки:
- Возраст статьи оказывает большое влияние на ее рейтинг, чем новее — тем выше рейтинг она получит
- Рейтинг не уменьшается с устареванием статей, но растет с новыми статьями
Вот визуализация, как выглядит рейтинг статей с одинаковым кол-вом плюсов и минусов, но разным временем публикации:
Логарифмическая шкала
Hot ranking использует логарифм для того, чтобы первые n голосов весили больше чем будущие n+r голоса. В итоге получается, что первые 10 плюсов имеют такой же вес, как следующие 100, которые имеют такой же вес как следующие 1000, и т.д.
Вот как это выглядит:
А вот как выглядело бы без логарифма:
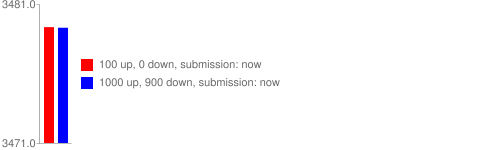
Воздействие «минусов»
Реддит — один из тех сайтов, на котором можно минусовать. Как вы видели в коде, «score» поста равен разнице плюсов и минусов.
В итоге это выглядит так:
Это оказывает большое влияние на посты, которые получают много плюсов и минусов (т.н. спорные посты), они получают меньший рейтинг, чем посты только с плюсами. Наверное поэтому котята так часто бывают на главной :) (прим. пер. — на самом деле это из-за того, что вы не отписались от /r/aww)
Заключение по сортировке постов
- Время добавления — очень важный параметр, более новые посты получат более высокий рейтинг
- Кривая рейтинга строится по логарифму десяти. Первые 10 плюсов равны следующим 100
- Спорные посты, получившие и плюсы и минусы будут ниже просто «заплюсованных» постов
Как работает сортировка комментариев
Randall Munroe из xkcd стоит за идеей Реддитовского best ranking. Он написал отличную статью про это: reddit's new comment sorting system
Вам стоит прочитать эту статью, в ней он очень понятно объясняет принцип работы алгоритма. Резюмируя ее, можно сказать:
- Алгоритм hot ranking не подходит для рейтинга комментариев, так как он очень сильно опирается на возраст записи
- В комментариях, вам нужно ставить лучшие комменты выше, вне зависимости от того, когда их отправили
- Решение для этого было найдено в 1927 году Эдвином Вилсоном и названо «Вилсоновский рейтинговый интервал» («Wilson score interval»), Вилсоновский интервал может быть использован для «сортировки по доверию»
- При сортировке по доверию общее кол-во голосов представляется как статистическая выборка гипотетического полного голоса от каждого — как в опросе мнений
- How Not To Sort By Average Rating — хорошо описывает алгоритм рейтингования по доверию, очень рекомендую к прочтению! (прим. пер. — также есть хорошая статья на хабре)
Исследуем код сортировки комментариев
Алгоритм сортировки по доверию реализован в _sorts.pyx, я его также переписал на чистый питон (и убрал некоторые кеширующие оптимизации):
#Rewritten code from /r2/r2/lib/db/_sorts.pyx from math import sqrt def _confidence(ups, downs): n = ups + downs if n == 0: return 0 z = 1.0 #1.0 = 85%, 1.6 = 95% phat = float(ups) / n return sqrt(phat+z*z/(2*n)-z*((phat*(1-phat)+z*z/(4*n))/n))/(1+z*z/n) def confidence(ups, downs): if ups + downs == 0: return 0 else: return _confidence(ups, downs)
Сортировка по доверию использует Вильсоновский интервал и математическая запись выглядит так:
Список параметров этой формулы:
- p — доля положительных оценок
- n — общее кол-во голосов
- zα/2 — это (1-α/2) квантиль стандартного нормального распределения
Давайте подведем итог сказанному выше:
- Сортировка по доверию представляет кол-во голосов как статистическую выборку гипотетического полного голоса каждого
- Сортировка по доверию дает прогнозируемую оценку комментарию, которую он с вероятностью 85% получит
- Чем больше голосов, тем ближе предполагаемый рейтинг подходит к действительному
- Интервал Вилсона хорош также и для малого кол-ва голосов и в случаях крайней вероятности
У Рэнделла есть отличный пример, как происходит рейтингование комментариев:
Если у комментария один плюс и ноль минусов, у него 100%-ный рейтинг, но так как у нас слишком мало данных, система будет держать его внизу. Но, если у него 10 плюсов и всего один минус, система может иметь достаточно доверия (уверенности), чтобы поместить его выше какого-нибудь комментария с 40 плюсами и 20 минусами, предположив, что когда он тоже получит 40 плюсов — у него будет меньше 20-ти минусов. И лучшая часть в том, что даже если это будет неверно (что бывает в 15% случаев), система быстро получит больше данных (т.к. плохой коммент оказался вверху, его увидят и заминусуют) и коммент попадет туда, куда следует.
Как мы видим, на этот алгоритм никак не влияет устаревание записей.
Давайте посмотрим, как это выглядит:
Как вы видите, такую сортировку волнует не сколько голосов получил комментарий, а сколько плюсов в отношении к общему числу голосов и размеру выборки.
Как отмечает Evan Miller, Вилсоновский интервал можно использовать не только для рейтинга.
Вот три примера, которые он привел:
- Обнаруживать спам: какой процент людей, которые видят это, отметят это как спам?
- Создание списка «лучшее»: какой процент людей, кто увидит это, отметят как «лучшее»?
- Создание списка «most emailed»: какой процент людей, которые видят эту страницу, нажмут «Email»?

