Бытует мнение, что русская морфология у Яндекса реализована лучше чем у Google. В этой статье я покажу, что дело обстоит ровным счетом наоборот.

Эта статья адаптация моей статьи на SeoNews для Хабра
В русском языке несколько сотен тысяч слов, причем каждое из них может быть во множестве словоформ. Например, прилагательное может быть в 100 словоформах:


В итоге, если сохранять морфологический словарь «в лоб» нам нужно около 500 мб. 500.000(число слов) * 75(ср. число словоформ) * (10 (ср. длина слова) + 4 байта (на сохранение номера слова + 2 байта на сохранение номера словоформы)). Для ускорения необходимо держать все эти данные в памяти, а скорость критична в случае поисковой системы.
Существует «сжатый» вид. Многие слова имеют одинаковые окончания в одинаковой форме. Например, «великий» и «могучий». Нам нужно сохранить лишь начало слова («велик» и «могуч») и номер группы. В итоге нам понадобиться около 5мб. 500.000 * (8(ср. длина начала)+ 2(номер группы)). Однако, в этом случае база будет содержать артефакты.
Правил преобразования глаголов(делать) в причастия(делающий) не много. Поэтому в сжатой базе деепричастия и причастия считаются словоформами глагола, а не отдельными словами.
А вот правил преобразования глаголов в совершенный вид (делать->сделать, купить->покупать, искать->найти) бессчетное множество, поэтому для сжатой базы глаголы совершенного и несовершенного вида — разные слова.
Эти артефакты критичны только для поиска, в котором морфология используется, чтобы объединять словоформы.
Яндекс подсвечивает не только словоформы, но еще и синонимы. Однако, подсветку синонимов можно отключить при помощи оператора "+".

Связь совершенного и несовершенного вида глаголов в Яндексе организована через синонимы, а не через морфологию.
А вот связь глаголов и причастий — реализована через морфологию.
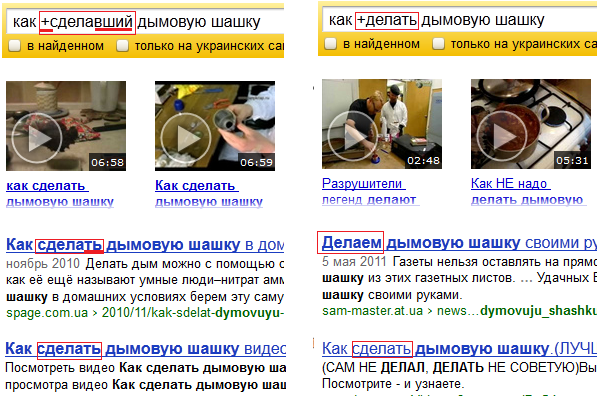
На этой картинке четко видны артефакты сжатия морфологического словаря. Другими словами Яндекс использует сжатие.
Быть может подсветка просто «отстает от мозгов». Однако, для высокочастотных запросов подсветка синонимом сама отключается. Это показывает, то что подсветка связана с мозгами в случае синонимов — не может же она просто так отключаться. Единственное объяснение этому — результатов в выдаче итак хватает и Яндекс экономит ресурсы не подключая поиск по синонимам.
Разница в выдаче хорошо наблюдается в запросах содержащих глагол в обоих видах и причастие. Например, «сделать клизму», «делать клизму» и «сделавший клизму», если набрать их в Яндекс и в Google.
Мы показали наличие артефактов морфологии Яндекс и то что они влияют на ранжирование, хотя, они могут не влиять на качество выдачи. Однако, мне удалось довольно быстро найти несколько исключений в Яндексе: купить и покупать, выщипывать и выщипать, отправлять и отправить склеены на уровне морфологии. Единственная гипотеза почему эти исключения появились — их добавили для улучшения выдачи. Следовательно, артефакты, как минимум, в частных случаях ухудшают выдачу.
Google
Google использует несжатую морфологию. По крайней мере, «артефакты сжатия» мне не удалось найти.
Единственное несоответствие формальной модели русского языка в Google — обычная (хороший) и превосходная (лучший) степени прилагательных разделены в морфологии. Вероятно они соединены как синонимы, однако, Google не подсвечивает синонимы.
Это не объясняется как артефакт сжатия, поскольку правил преобразования преобразования форм прилагательных не так много (красивый->красивейший, умный->умнейший) и ни база AOT.ru и ни словарь Зализняка не разделяет формы прилагательных.
Разделение прилагательных по степени, объясняется оптимизацией качества выдачи. Степень прилагательных изменяет их «окраску», делая их смысловую связь более похожей на синонимы, чем на словоформы. Например, запрос «прекрасные фото» по смыслу намного ближе к «красивые фото» чем «красивейшие фото».
Это совпадает с интуитивным представлением о языке. Я несколько раз встречался с тем, что «хороший» и «лучше» приводили в пример того, что Яндекс понимает синонимы.
Морфология в Яндексе писалась лет 10 назад, а тогда 500 мб. памяти для нескольких сотен серверов могли обойтись в копеечку. С тех пор память подешевела, но изменение морфологии привело бы к целому каскаду изменений в БД Яндекса. Поэтому, в Яндексе используется сжатый вид морфологии.
Google изначально английская поисковая система. В английском языке слова имеют всего несколько словоформ и в сжатии морфологии нет смысла. Видимо, поэтому, в русской морфологии Google не используется сжатие.
Морфология у Google организована «правильнее» и немного лучше чем у Яндекса. Ирония в том, что причина этому в английском происхождении Google.
Однако, морфология это лишь один из многих аспектов в выдаче. Сказать, что у Google лучше выдача чем у Яндекса только на основе морфологии, тоже самое что оценивать интеллект по высоте лба. Цель статьи была в развеивании убеждения о том, что морфология в Google организована хуже чем в Яндексе.
Эта статья адаптация моей статьи на SeoNews для Хабра
Русская морфология
В русском языке несколько сотен тысяч слов, причем каждое из них может быть во множестве словоформ. Например, прилагательное может быть в 100 словоформах:


В итоге, если сохранять морфологический словарь «в лоб» нам нужно около 500 мб. 500.000(число слов) * 75(ср. число словоформ) * (10 (ср. длина слова) + 4 байта (на сохранение номера слова + 2 байта на сохранение номера словоформы)). Для ускорения необходимо держать все эти данные в памяти, а скорость критична в случае поисковой системы.
Существует «сжатый» вид. Многие слова имеют одинаковые окончания в одинаковой форме. Например, «великий» и «могучий». Нам нужно сохранить лишь начало слова («велик» и «могуч») и номер группы. В итоге нам понадобиться около 5мб. 500.000 * (8(ср. длина начала)+ 2(номер группы)). Однако, в этом случае база будет содержать артефакты.
Артефакты
Правил преобразования глаголов(делать) в причастия(делающий) не много. Поэтому в сжатой базе деепричастия и причастия считаются словоформами глагола, а не отдельными словами.
А вот правил преобразования глаголов в совершенный вид (делать->сделать, купить->покупать, искать->найти) бессчетное множество, поэтому для сжатой базы глаголы совершенного и несовершенного вида — разные слова.
Эти артефакты критичны только для поиска, в котором морфология используется, чтобы объединять словоформы.
Яндекс
Яндекс подсвечивает не только словоформы, но еще и синонимы. Однако, подсветку синонимов можно отключить при помощи оператора "+".
Связь совершенного и несовершенного вида глаголов в Яндексе организована через синонимы, а не через морфологию.
А вот связь глаголов и причастий — реализована через морфологию.
На этой картинке четко видны артефакты сжатия морфологического словаря. Другими словами Яндекс использует сжатие.
Разница в выдаче
Быть может подсветка просто «отстает от мозгов». Однако, для высокочастотных запросов подсветка синонимом сама отключается. Это показывает, то что подсветка связана с мозгами в случае синонимов — не может же она просто так отключаться. Единственное объяснение этому — результатов в выдаче итак хватает и Яндекс экономит ресурсы не подключая поиск по синонимам.
Разница в выдаче хорошо наблюдается в запросах содержащих глагол в обоих видах и причастие. Например, «сделать клизму», «делать клизму» и «сделавший клизму», если набрать их в Яндекс и в Google.
Влияние на качество выдачи
Мы показали наличие артефактов морфологии Яндекс и то что они влияют на ранжирование, хотя, они могут не влиять на качество выдачи. Однако, мне удалось довольно быстро найти несколько исключений в Яндексе: купить и покупать, выщипывать и выщипать, отправлять и отправить склеены на уровне морфологии. Единственная гипотеза почему эти исключения появились — их добавили для улучшения выдачи. Следовательно, артефакты, как минимум, в частных случаях ухудшают выдачу.
Google использует несжатую морфологию. По крайней мере, «артефакты сжатия» мне не удалось найти.
Единственное несоответствие формальной модели русского языка в Google — обычная (хороший) и превосходная (лучший) степени прилагательных разделены в морфологии. Вероятно они соединены как синонимы, однако, Google не подсвечивает синонимы.
Это не объясняется как артефакт сжатия, поскольку правил преобразования преобразования форм прилагательных не так много (красивый->красивейший, умный->умнейший) и ни база AOT.ru и ни словарь Зализняка не разделяет формы прилагательных.
Разделение прилагательных по степени, объясняется оптимизацией качества выдачи. Степень прилагательных изменяет их «окраску», делая их смысловую связь более похожей на синонимы, чем на словоформы. Например, запрос «прекрасные фото» по смыслу намного ближе к «красивые фото» чем «красивейшие фото».
Это совпадает с интуитивным представлением о языке. Я несколько раз встречался с тем, что «хороший» и «лучше» приводили в пример того, что Яндекс понимает синонимы.
Почему так произошло
Морфология в Яндексе писалась лет 10 назад, а тогда 500 мб. памяти для нескольких сотен серверов могли обойтись в копеечку. С тех пор память подешевела, но изменение морфологии привело бы к целому каскаду изменений в БД Яндекса. Поэтому, в Яндексе используется сжатый вид морфологии.
Google изначально английская поисковая система. В английском языке слова имеют всего несколько словоформ и в сжатии морфологии нет смысла. Видимо, поэтому, в русской морфологии Google не используется сжатие.
Итого
Морфология у Google организована «правильнее» и немного лучше чем у Яндекса. Ирония в том, что причина этому в английском происхождении Google.
Однако, морфология это лишь один из многих аспектов в выдаче. Сказать, что у Google лучше выдача чем у Яндекса только на основе морфологии, тоже самое что оценивать интеллект по высоте лба. Цель статьи была в развеивании убеждения о том, что морфология в Google организована хуже чем в Яндексе.
