Тема нейронных сетей была уже ни раз освещена на хабре, однако сегодня я бы хотел познакомить читателей с алгоритмом обучения многослойной нейронной сети методом обратного распространения ошибки и привести реализацию данного метода.
Сразу хочу оговориться, что не являюсь экспертом в области нейронных сетей, поэтому жду от читателей конструктивной критики, замечаний и дополнений.
Данный материал предполагает знакомство с основами нейронных сетей, однако я считаю возможным ввести читателя в курс темы без излишних мытарств по теории нейронных сетей. Итак, для тех, кто впервые слышит словосочетание «нейронная сеть», предлагаю воспринимать нейронную сеть в качестве взвешенного направленного графа, узлы ( нейроны ) которого расположены слоями. Кроме того, узел одного слоя имеет связи со всеми узлами предыдущего слоя. В нашем случае у такого графа будут иметься входной и выходной слои, узлы которых выполняют роль входов и
выходов соответственно. Каждый узел ( нейрон ) обладает активационной функцией — функцией, ответственной за вычисление сигнала на выходе узла ( нейрона ). Также существует понятие смещения, представляющего из себя узел, на выходе которого всегда появляется единица. В данной статье мы будем рассматривать процесс обучения нейронной сети, предполагающий наличие «учителя», то есть процесс обучения, при котором обучение происходит путем предоставления сети последовательности обучающих примеров с правильными откликами.
Как и в случае с большинством нейронных сетей, наша цель состоит в обучении сети таким образом, чтобы достичь баланса между способностью сети давать верный отклик на входные данные, использовавшиеся в процессе обучения ( запоминания ), и способностью выдавать правильные результаты в ответ на входные данные, схожие, но неидентичные тем, что были использованы при обучении ( принцип обобщения). Обучение сети методом обратного распространения ошибки включает в себя три этапа: подачу на вход данных, с последующим распространением данных в направлении выходов, вычисление и обратное распространение соответствующей ошибки и корректировку весов. После обучения предполагается лишь подача на вход сети данных и распространение их в направлении выходов. При этом, если обучение сети может являться довольно длительным процессом, то непосредственное вычисление результатов обученной сетью происходит очень быстро. Кроме того, существуют многочисленные вариации метода обратного распространения ошибки, разработанные с целью увеличения скорости протекания
процесса обучения.
Также стоит отметить, что однослойная нейронная сеть существенно ограничена в том, обучению каким шаблонам входных данных она подлежит, в то время, как многослойная сеть ( с одним или более скрытым слоем ) не имеет такого недостатка. Далее будет дано описание стандартной нейронной сети с обратным распространением ошибки.
На рисунке 1 показана многослойная нейронная сеть с одним слоем скрытых нейронов ( элементы Z ).
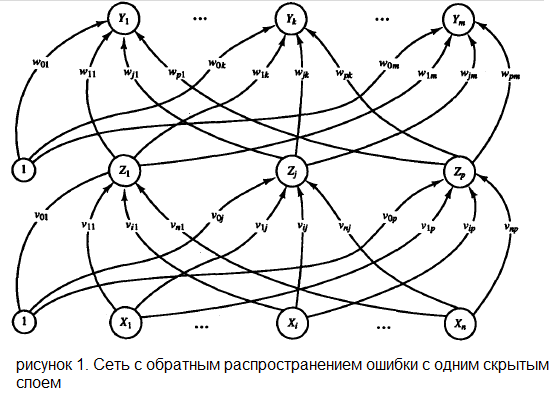
Нейроны, представляющие собой выходы сети ( обозначены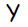 ), и скрытые нейроны могут иметь смещение( как показано на изображении ). Смещение, соответствующий выходу
), и скрытые нейроны могут иметь смещение( как показано на изображении ). Смещение, соответствующий выходу  обозначен
обозначен , скрытому элементу
, скрытому элементу  —
— 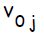 . Эти смещения служат в качестве весов на связях, исходящих от нейронов, на выходе которых всегда появляется 1 ( на рисунке 1 они показаны, но обычно явно не отображаются, подразумеваясь). Кроме того, на рисунке 1 стрелками показано перемещение информации в ходе фазы распространения данных от входов к выходам. В процессе обучения сигналы распространяются в обратном направлении.
. Эти смещения служат в качестве весов на связях, исходящих от нейронов, на выходе которых всегда появляется 1 ( на рисунке 1 они показаны, но обычно явно не отображаются, подразумеваясь). Кроме того, на рисунке 1 стрелками показано перемещение информации в ходе фазы распространения данных от входов к выходам. В процессе обучения сигналы распространяются в обратном направлении.
Алгоритм, представленный далее, применим к нейронной сети с одним скрытым слоем, что является допустимой и адекватной ситуацией для большинства приложений. Как уже было сказано ранее, обучение сети включает в себя три стадии: подача на входы сети обучающих данных, обратное распространение ошибки и корректировка весов. В ходе первого этапа каждый входной нейрон получает сигнал и широковещательно транслирует его каждому из скрытых нейронов
получает сигнал и широковещательно транслирует его каждому из скрытых нейронов  . Каждый скрытый нейрон затем вычисляет результат его активационной функции ( сетевой функции ) и рассылает свой сигнал
. Каждый скрытый нейрон затем вычисляет результат его активационной функции ( сетевой функции ) и рассылает свой сигнал  всем выходным нейронам. Каждый выходной нейрон , в свою очередь, вычисляет результат своей активационной функции
всем выходным нейронам. Каждый выходной нейрон , в свою очередь, вычисляет результат своей активационной функции  , который представляет собой ничто иное, как выходной сигнал данного нейрона для соответствующих входных данных. В процессе обучения, каждый нейрон на выходе сети сравнивает вычисленное значение с предоставленным учителем
, который представляет собой ничто иное, как выходной сигнал данного нейрона для соответствующих входных данных. В процессе обучения, каждый нейрон на выходе сети сравнивает вычисленное значение с предоставленным учителем  ( целевым значением ), определяя соответствующее значение ошибки для данного входного шаблона. На основании этой ошибки вычисляется
( целевым значением ), определяя соответствующее значение ошибки для данного входного шаблона. На основании этой ошибки вычисляется  .
.  используется при распространении ошибки от до всех элементов сети предыдущего слоя ( скрытых нейронов, связанных с ), а также позже при изменении весов связей между выходными нейронами и скрытыми. Аналогичным образом вычисляется
используется при распространении ошибки от до всех элементов сети предыдущего слоя ( скрытых нейронов, связанных с ), а также позже при изменении весов связей между выходными нейронами и скрытыми. Аналогичным образом вычисляется 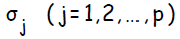 для каждого скрытого нейрона . Несмотря на то, что распространять ошибку до входного слоя необходимости нет,
для каждого скрытого нейрона . Несмотря на то, что распространять ошибку до входного слоя необходимости нет, 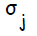 используется для изменения весов связей между нейронами скрытого слоя и входными нейронами. После того как все
используется для изменения весов связей между нейронами скрытого слоя и входными нейронами. После того как все 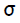 были определены, происходит одновременная корректировка весов всех связей.
были определены, происходит одновременная корректировка весов всех связей.
В алгоритме обучения сети используются следующие обозначения:
 Входной вектор обучающих данных
Входной вектор обучающих данных 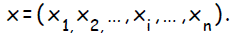
 Вектор целевых выходных значений, предоставляемых учителем
Вектор целевых выходных значений, предоставляемых учителем
Составляющая корректировки весов связей 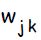 , соответствующая ошибке выходного нейрона ; также, информация об ошибке нейрона , которая распространяется тем нейронам скрытого слоя, которые связаны с .
, соответствующая ошибке выходного нейрона ; также, информация об ошибке нейрона , которая распространяется тем нейронам скрытого слоя, которые связаны с .
Составляющая корректировки весов связей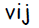 , соответствующая распространяемой от выходного слоя к скрытому нейрону информации об ошибке.
, соответствующая распространяемой от выходного слоя к скрытому нейрону информации об ошибке.
 Скорость обучения.
Скорость обучения.
 Нейрон на входе с индексом i. Для входных нейронов входной и выходной сигналы одинаковы — .
Нейрон на входе с индексом i. Для входных нейронов входной и выходной сигналы одинаковы — .
Смещение скрытого нейрона j.
Скрытый нейрон j; Суммарное значение подаваемое на вход скрытого элемента обозначается 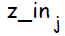 :
: 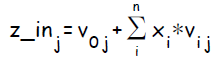
Сигнал на выходе ( результат применения к активационной функции ) обозначается : 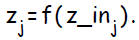
Смещение нейрона на выходе.
Нейрон на выходе под индексом k; Суммарное значение подаваемое на вход выходного элемента обозначается 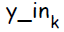 :
:  . Сигнал на выходе ( результат применения к активационной функции ) обозначается :
. Сигнал на выходе ( результат применения к активационной функции ) обозначается :
Функция активация в алгоритме обратного распространения ошибки должна обладать несколькими важными характеристиками: непрерывностью, дифференцируемостью и являться монотонно неубывающей. Более того, ради эффективности вычислений, желательно, чтобы ее производная легко находилась. Зачастую, активационная функция также является функцией с насыщением. Одной из наиболее часто используемых активационных функций является бинарная сигмоидальная функция с областью значений в ( 0, 1 ) и определенная как:


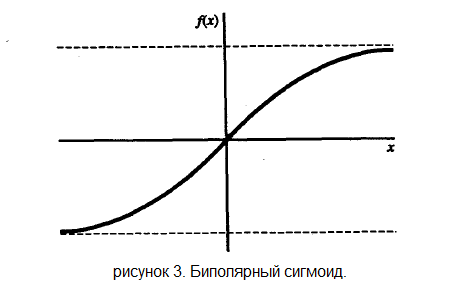
Другой широко распространенной активационной функцией является биполярный сигмоид с областью значений ( -1, 1 ) и определенный как:
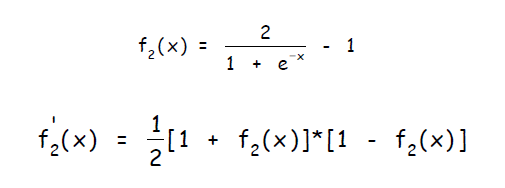
Алгоритм обучения выглядит следующим образом:
Инициализация весов ( веса всех связей инициализируются случайными небольшими значениями ).
До тех пор пока условие прекращения работы алгоритма неверно, выполняются шаги 2 — 9.
Для каждой пары { данные, целевое значение } выполняются шаги 3 — 8.
Каждый входной нейрон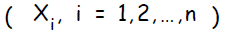 отправляет полученный сигнал всем нейронам в следующем слое ( скрытом ).
отправляет полученный сигнал всем нейронам в следующем слое ( скрытом ).
Каждый скрытый нейрон суммирует взвешенные входящие сигналы: и применяет активационную функцию: После чего посылает результат всем элементам следующего слоя ( выходного ).
суммирует взвешенные входящие сигналы: и применяет активационную функцию: После чего посылает результат всем элементам следующего слоя ( выходного ).
Каждый выходной нейрон суммирует взвешенные входящие сигналы: и применяет активационную функцию, вычисляя выходной сигнал:
суммирует взвешенные входящие сигналы: и применяет активационную функцию, вычисляя выходной сигнал: 
Каждый выходной нейрон получает целевое значение — то выходное значение, которое является правильным для данного входного сигнала, и вычисляет ошибку:  , так же вычисляет величину, на которую изменится вес связи :
, так же вычисляет величину, на которую изменится вес связи :  . Помимо этого, вычисляет величину корректировки смещения:
. Помимо этого, вычисляет величину корректировки смещения:  и посылает нейронам в предыдущем слое.
и посылает нейронам в предыдущем слое.
Каждый скрытый нейрон суммирует входящие ошибки ( от нейронов в последующем слое )  и вычисляет величину ошибки, умножая полученное значение на производную активационной функции:
и вычисляет величину ошибки, умножая полученное значение на производную активационной функции: 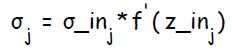 , так же вычисляет величину, на которую изменится вес связи :
, так же вычисляет величину, на которую изменится вес связи :  . Помимо этого, вычисляет величину корректировки смещения:
. Помимо этого, вычисляет величину корректировки смещения: 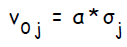
Каждый выходной нейрон изменяет веса своих связей с элементом смещения и скрытыми нейронами: 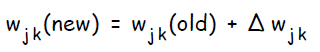
Каждый скрытый нейрон изменяет веса своих связей с элементом смещения и выходными нейронами: 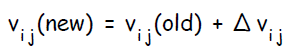
Проверка условия прекращения работы алгоритма.
Условием прекращения работы алгоритма может быть как достижение суммарной квадратичной ошибкой результата на выходе сети предустановленного заранее минимума в ходе процесса обучения, так и выполнения определенного количества итераций алгоритма. В основе алгоритма лежит метод под названием градиентный спуск. В зависимости от знака, градиент функции ( в данном случае значение функции — это ошибка, а параметры — это веса связей в сети ) дает направление, в котором значения функции возрастают (или убывают) наиболее стремительно.
Случайная инициализация. Выбор начальных весов окажет влияние на то, сумеет ли сеть достичь глобального ( или только локального) минимума ошибки, и насколько быстро этот процесс будет происходить. Изменение весов между двумя нейронами связано с производной активационной функции нейрона из последующего слоя и активационной функции нейрона слоя предыдущего. В связи с этим, важно избегать выбора таких начальных весов, которые обнулят активационную функцию или ее производную. Также начальные веса не должны быть слишком большими ( или входные сигнал для каждого скрытого или выходного нейрона скорее всего попадут в регион очень малых значений сигмоида ( регион насыщения ) ). С другой стороны, если начальные веса будут слишком маленькими, то входной сигнал на скрытые или выходные нейроны будет близок к нулю, что также приведет к очень низкой скорости обучения. Стандартная процедура инициализации весов состоит в присвоении им случайных значений в интервале ( -0,5; 0,5). Значения могут быть как положительными, так и отрицательными, так как конечные веса, получающиеся после обучения сети, могут быть обоих знаков. Инициализация Nguyen – Widrow. Представленная далее простая модификация стандартной процедуру инициализации способствует более быстрому обучению: Веса связей скрытых и выходных нейронов, а также смещение выходного слоя инициализируются также, как и в стандартной процедуре — случайными значениями из интервала ( -0,5; 0,5).
Введем обозначения:
 количество входных нейронов
количество входных нейронов
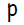 количество скрытых нейронов
количество скрытых нейронов
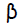 фактор масштабирования:
фактор масштабирования:
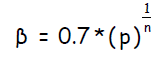
Процедура состоит из следующих простых шагов:
Для каждого скрытого нейрона:
инициализировать его вектор весов ( связей с входными нейронами ):
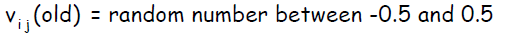
вычислить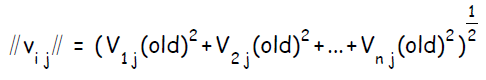
переинициализировать веса:
задать значение смещения: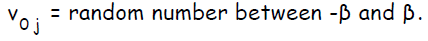
Начну с реализации концепции нейрона. Было решено представить нейроны входного слоя базовым классом, а скрытые и выходные как декораторы базового класса. Кроме того, нейрон хранит в себе информацию об исходящих и входящих связях, а также каждый нейрон композиционно имеет в своем составе активационную функцию.
Интерфейс нейронных связей представлен ниже, каждая связь хранит вес и указатель на нейрон:
Каждая активационная функция наследует от абстрактного класса, реализуя саму функцию и производную:
За производство нейронов ответственна нейронная фабрика:
Сама нейронная сеть хранит указатели на нейроны, организованные
слоями ( вообще, указатели на нейроны хранятся в векторах, которые
нужно заменить на объекты-слои ), включает в себя абстрактную
фабрику нейронов, а также алгоритм обучения сети.
И, наконец, сам интерфейс класса, ответственного за обучение сети:
Весь код доступен на github: Sovietmade/NeuralNetworks
В качестве заключения, хотелось бы отметить, что тема нейронных сетей на данный момент не разработана полностью, вновь и вновь мы видим на страницах хабра упоминания о новых достижениях ученых в области нейронных сетей, новых удивительных разработках. С моей стороны,
эта статья была первым шагом освоения интереснейшей технологии, и я надеюсь для кого — то она окажется небесполезной.
Алгоритм обучения нейронной сети был взят из изумительной книги:
Laurene V. Fausett “Fundamentals of Neural Networks: Architectures, Algorithms And Applications”.
Сразу хочу оговориться, что не являюсь экспертом в области нейронных сетей, поэтому жду от читателей конструктивной критики, замечаний и дополнений.
Теоретическая часть
Данный материал предполагает знакомство с основами нейронных сетей, однако я считаю возможным ввести читателя в курс темы без излишних мытарств по теории нейронных сетей. Итак, для тех, кто впервые слышит словосочетание «нейронная сеть», предлагаю воспринимать нейронную сеть в качестве взвешенного направленного графа, узлы ( нейроны ) которого расположены слоями. Кроме того, узел одного слоя имеет связи со всеми узлами предыдущего слоя. В нашем случае у такого графа будут иметься входной и выходной слои, узлы которых выполняют роль входов и
выходов соответственно. Каждый узел ( нейрон ) обладает активационной функцией — функцией, ответственной за вычисление сигнала на выходе узла ( нейрона ). Также существует понятие смещения, представляющего из себя узел, на выходе которого всегда появляется единица. В данной статье мы будем рассматривать процесс обучения нейронной сети, предполагающий наличие «учителя», то есть процесс обучения, при котором обучение происходит путем предоставления сети последовательности обучающих примеров с правильными откликами.
Как и в случае с большинством нейронных сетей, наша цель состоит в обучении сети таким образом, чтобы достичь баланса между способностью сети давать верный отклик на входные данные, использовавшиеся в процессе обучения ( запоминания ), и способностью выдавать правильные результаты в ответ на входные данные, схожие, но неидентичные тем, что были использованы при обучении ( принцип обобщения). Обучение сети методом обратного распространения ошибки включает в себя три этапа: подачу на вход данных, с последующим распространением данных в направлении выходов, вычисление и обратное распространение соответствующей ошибки и корректировку весов. После обучения предполагается лишь подача на вход сети данных и распространение их в направлении выходов. При этом, если обучение сети может являться довольно длительным процессом, то непосредственное вычисление результатов обученной сетью происходит очень быстро. Кроме того, существуют многочисленные вариации метода обратного распространения ошибки, разработанные с целью увеличения скорости протекания
процесса обучения.
Также стоит отметить, что однослойная нейронная сеть существенно ограничена в том, обучению каким шаблонам входных данных она подлежит, в то время, как многослойная сеть ( с одним или более скрытым слоем ) не имеет такого недостатка. Далее будет дано описание стандартной нейронной сети с обратным распространением ошибки.
Архитектура
На рисунке 1 показана многослойная нейронная сеть с одним слоем скрытых нейронов ( элементы Z ).
Нейроны, представляющие собой выходы сети ( обозначены
), и скрытые нейроны могут иметь смещение( как показано на изображении ). Смещение, соответствующий выходу обозначен, скрытому элементу — . Эти смещения служат в качестве весов на связях, исходящих от нейронов, на выходе которых всегда появляется 1 ( на рисунке 1 они показаны, но обычно явно не отображаются, подразумеваясь). Кроме того, на рисунке 1 стрелками показано перемещение информации в ходе фазы распространения данных от входов к выходам. В процессе обучения сигналы распространяются в обратном направлении.Описание алгоритма
Алгоритм, представленный далее, применим к нейронной сети с одним скрытым слоем, что является допустимой и адекватной ситуацией для большинства приложений. Как уже было сказано ранее, обучение сети включает в себя три стадии: подача на входы сети обучающих данных, обратное распространение ошибки и корректировка весов. В ходе первого этапа каждый входной нейрон
получает сигнал и широковещательно транслирует его каждому из скрытых нейронов . Каждый скрытый нейрон затем вычисляет результат его активационной функции ( сетевой функции ) и рассылает свой сигнал всем выходным нейронам. Каждый выходной нейрон , в свою очередь, вычисляет результат своей активационной функции , который представляет собой ничто иное, как выходной сигнал данного нейрона для соответствующих входных данных. В процессе обучения, каждый нейрон на выходе сети сравнивает вычисленное значение с предоставленным учителем ( целевым значением ), определяя соответствующее значение ошибки для данного входного шаблона. На основании этой ошибки вычисляется . используется при распространении ошибки от до всех элементов сети предыдущего слоя ( скрытых нейронов, связанных с ), а также позже при изменении весов связей между выходными нейронами и скрытыми. Аналогичным образом вычисляется для каждого скрытого нейрона . Несмотря на то, что распространять ошибку до входного слоя необходимости нет, используется для изменения весов связей между нейронами скрытого слоя и входными нейронами. После того как все были определены, происходит одновременная корректировка весов всех связей.Обозначения:
В алгоритме обучения сети используются следующие обозначения:
Входной вектор обучающих данных Вектор целевых выходных значений, предоставляемых учителем Составляющая корректировки весов связей , соответствующая ошибке выходного нейрона ; также, информация об ошибке нейрона , которая распространяется тем нейронам скрытого слоя, которые связаны с . Составляющая корректировки весов связей, соответствующая распространяемой от выходного слоя к скрытому нейрону информации об ошибке. Скорость обучения. Нейрон на входе с индексом i. Для входных нейронов входной и выходной сигналы одинаковы — . Смещение скрытого нейрона j. Скрытый нейрон j; Суммарное значение подаваемое на вход скрытого элемента обозначается : Сигнал на выходе
( результат применения к активационной функции ) обозначается : Смещение нейрона на выходе. Нейрон на выходе под индексом k; Суммарное значение подаваемое на вход выходного элемента обозначается : . Сигнал на выходе ( результат применения к активационной функции ) обозначается :Функция активации
Функция активация в алгоритме обратного распространения ошибки должна обладать несколькими важными характеристиками: непрерывностью, дифференцируемостью и являться монотонно неубывающей. Более того, ради эффективности вычислений, желательно, чтобы ее производная легко находилась. Зачастую, активационная функция также является функцией с насыщением. Одной из наиболее часто используемых активационных функций является бинарная сигмоидальная функция с областью значений в ( 0, 1 ) и определенная как:
Другой широко распространенной активационной функцией является биполярный сигмоид с областью значений ( -1, 1 ) и определенный как:
Алгоритм обучения
Алгоритм обучения выглядит следующим образом:
Шаг 0.
Инициализация весов ( веса всех связей инициализируются случайными небольшими значениями ).
Шаг 1.
До тех пор пока условие прекращения работы алгоритма неверно, выполняются шаги 2 — 9.
Шаг 2.
Для каждой пары { данные, целевое значение } выполняются шаги 3 — 8.
Распространение данных от входов к выходам:
Шаг 3.
Каждый входной нейрон
отправляет полученный сигнал всем нейронам в следующем слое ( скрытом ).Шаг 4.
Каждый скрытый нейрон
суммирует взвешенные входящие сигналы: и применяет активационную функцию: После чего посылает результат всем элементам следующего слоя ( выходного ).Шаг 5.
Каждый выходной нейрон
суммирует взвешенные входящие сигналы: и применяет активационную функцию, вычисляя выходной сигнал: Обратное распространение ошибки:
Шаг 6.
Каждый выходной нейрон
получает целевое значение — то выходное значение, которое является правильным для данного входного сигнала, и вычисляет ошибку: , так же вычисляет величину, на которую изменится вес связи : . Помимо этого, вычисляет величину корректировки смещения: и посылает нейронам в предыдущем слое.Шаг 7.
Каждый скрытый нейрон
суммирует входящие ошибки ( от нейронов в последующем слое ) и вычисляет величину ошибки, умножая полученное значение на производную активационной функции: , так же вычисляет величину, на которую изменится вес связи : . Помимо этого, вычисляет величину корректировки смещения: Шаг 8. Изменение весов.
Каждый выходной нейрон
изменяет веса своих связей с элементом смещения и скрытыми нейронами: Каждый скрытый нейрон
изменяет веса своих связей с элементом смещения и выходными нейронами: Шаг 9.
Проверка условия прекращения работы алгоритма.
Условием прекращения работы алгоритма может быть как достижение суммарной квадратичной ошибкой результата на выходе сети предустановленного заранее минимума в ходе процесса обучения, так и выполнения определенного количества итераций алгоритма. В основе алгоритма лежит метод под названием градиентный спуск. В зависимости от знака, градиент функции ( в данном случае значение функции — это ошибка, а параметры — это веса связей в сети ) дает направление, в котором значения функции возрастают (или убывают) наиболее стремительно.
Выбор первоначальных весов и смещения
Случайная инициализация. Выбор начальных весов окажет влияние на то, сумеет ли сеть достичь глобального ( или только локального) минимума ошибки, и насколько быстро этот процесс будет происходить. Изменение весов между двумя нейронами связано с производной активационной функции нейрона из последующего слоя и активационной функции нейрона слоя предыдущего. В связи с этим, важно избегать выбора таких начальных весов, которые обнулят активационную функцию или ее производную. Также начальные веса не должны быть слишком большими ( или входные сигнал для каждого скрытого или выходного нейрона скорее всего попадут в регион очень малых значений сигмоида ( регион насыщения ) ). С другой стороны, если начальные веса будут слишком маленькими, то входной сигнал на скрытые или выходные нейроны будет близок к нулю, что также приведет к очень низкой скорости обучения. Стандартная процедура инициализации весов состоит в присвоении им случайных значений в интервале ( -0,5; 0,5). Значения могут быть как положительными, так и отрицательными, так как конечные веса, получающиеся после обучения сети, могут быть обоих знаков. Инициализация Nguyen – Widrow. Представленная далее простая модификация стандартной процедуру инициализации способствует более быстрому обучению: Веса связей скрытых и выходных нейронов, а также смещение выходного слоя инициализируются также, как и в стандартной процедуре — случайными значениями из интервала ( -0,5; 0,5).
Введем обозначения:
количество входных нейронов количество скрытых нейронов фактор масштабирования:Процедура состоит из следующих простых шагов:
Для каждого скрытого нейрона
:инициализировать его вектор весов ( связей с входными нейронами ):
вычислить
переинициализировать веса:
задать значение смещения:
Практическая часть
Начну с реализации концепции нейрона. Было решено представить нейроны входного слоя базовым классом, а скрытые и выходные как декораторы базового класса. Кроме того, нейрон хранит в себе информацию об исходящих и входящих связях, а также каждый нейрон композиционно имеет в своем составе активационную функцию.
Интерфейс нейрона
/** * Neuron base class. * Represents a basic element of neural network, node in the net's graph. * There are several possibilities for creation an object of type Neuron, different constructors suites for * different situations. */ template <typename T> class Neuron { public: /** * A default Neuron constructor. * - Description: Creates a Neuron; general purposes. * - Purpose: Creates a Neuron, linked to nothing, with a Linear network function. * - Prerequisites: None. */ Neuron( ) : mNetFunc( new Linear ), mSumOfCharges( 0.0 ) { }; /** * A Neuron constructor based on NetworkFunction. * - Description: Creates a Neuron; mostly designed to create an output kind of neurons. * @param inNetFunc - a network function which is producing neuron's output signal; * - Purpose: Creates a Neuron, linked to nothing, with a specific network function. * - Prerequisites: The existence of NetworkFunction object. */ Neuron( NetworkFunction * inNetFunc ) : mNetFunc( inNetFunc ), mSumOfCharges( 0.0 ){ }; Neuron( std::vector<NeuralLink<T > *>& inLinksToNeurons, NetworkFunction * inNetFunc ) : mNetFunc( inNetFunc ), mLinksToNeurons(inLinksToNeurons), mSumOfCharges(0.0){ }; /** * A Neuron constructor based on layer of Neurons. * - Description: Creates a Neuron; mostly designed to create an input and hidden kinds of neurons. * @param inNeuronsLinkTo - a vector of pointers to Neurons which is representing a layer; * @param inNetFunc - a network function which is producing neuron's output signal; * - Purpose: Creates a Neuron, linked to every Neuron in provided layer. * - Prerequisites: The existence of std::vector<Neuron *> and NetworkFunction. */ Neuron( std::vector<Neuron *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ); virtual ~Neuron( ); virtual std::vector<NeuralLink<T > *>& GetLinksToNeurons( ){ return mLinksToNeurons; }; virtual NeuralLink<T> * at( const int& inIndexOfNeuralLink ) { return mLinksToNeurons[ inIndexOfNeuralLink ]; }; virtual void SetLinkToNeuron( NeuralLink<T> * inNeuralLink ){ mLinksToNeurons.push_back( inNeuralLink ); }; virtual void Input( double inInputData ){ mSumOfCharges += inInputData; }; virtual double Fire( ); virtual int GetNumOfLinks( ) { return mLinksToNeurons.size( ); }; virtual double GetSumOfCharges( ); virtual void ResetSumOfCharges( ){ mSumOfCharges = 0.0; }; virtual double Process( ) { return mNetFunc->Process( mSumOfCharges ); }; virtual double Process( double inArg ){ return mNetFunc->Process( inArg ); }; virtual double Derivative( ){ return mNetFunc->Derivative( mSumOfCharges ); }; virtual void SetInputLink( NeuralLink<T> * inLink ){ mInputLinks.push_back( inLink ); }; virtual std::vector<NeuralLink<T > *>& GetInputLink( ){ return mInputLinks; }; virtual double PerformTrainingProcess( double inTarget ); virtual void PerformWeightsUpdating( ); virtual void ShowNeuronState( ); protected: NetworkFunction * mNetFunc; std::vector<NeuralLink<T > *> mInputLinks; std::vector<NeuralLink<T > *> mLinksToNeurons; double mSumOfCharges; }; template <typename T> class OutputLayerNeuronDecorator : public Neuron<T> { public: OutputLayerNeuronDecorator( Neuron<T> * inNeuron ){ mOutputCharge = 0; mNeuron = inNeuron; }; virtual ~OutputLayerNeuronDecorator( ); virtual std::vector<NeuralLink<T > *>& GetLinksToNeurons( ){ return mNeuron->GetLinksToNeurons( ) ;}; virtual NeuralLink<T> * at( const int& inIndexOfNeuralLink ){ return ( mNeuron->at( inIndexOfNeuralLink ) ) ;}; virtual void SetLinkToNeuron( NeuralLink<T> * inNeuralLink ){ mNeuron->SetLinkToNeuron( inNeuralLink ); }; virtual double GetSumOfCharges( ) { return mNeuron->GetSumOfCharges( ); }; virtual void ResetSumOfCharges( ){ mNeuron->ResetSumOfCharges( ); }; virtual void Input( double inInputData ){ mNeuron->Input( inInputData ); }; virtual double Fire( ); virtual int GetNumOfLinks( ) { return mNeuron->GetNumOfLinks( ); }; virtual double Process( ) { return mNeuron->Process( ); }; virtual double Process( double inArg ){ return mNeuron->Process( inArg ); }; virtual double Derivative( ) { return mNeuron->Derivative( ); }; virtual void SetInputLink( NeuralLink<T> * inLink ){ mNeuron->SetInputLink( inLink ); }; virtual std::vector<NeuralLink<T > *>& GetInputLink( ) { return mNeuron->GetInputLink( ); }; virtual double PerformTrainingProcess( double inTarget ); virtual void PerformWeightsUpdating( ); virtual void ShowNeuronState( ) { mNeuron->ShowNeuronState( ); }; protected: double mOutputCharge; Neuron<T> * mNeuron; }; template <typename T> class HiddenLayerNeuronDecorator : public Neuron<T> { public: HiddenLayerNeuronDecorator( Neuron<T> * inNeuron ) { mNeuron = inNeuron; }; virtual ~HiddenLayerNeuronDecorator( ); virtual std::vector<NeuralLink<T > *>& GetLinksToNeurons( ){ return mNeuron->GetLinksToNeurons( ); }; virtual void SetLinkToNeuron( NeuralLink<T> * inNeuralLink ){ mNeuron->SetLinkToNeuron( inNeuralLink ); }; virtual double GetSumOfCharges( ){ return mNeuron->GetSumOfCharges( ) ;}; virtual void ResetSumOfCharges( ){mNeuron->ResetSumOfCharges( ); }; virtual void Input( double inInputData ){ mNeuron->Input( inInputData ); }; virtual double Fire( ); virtual int GetNumOfLinks( ){ return mNeuron->GetNumOfLinks( ); }; virtual NeuralLink<T> * ( const int& inIndexOfNeuralLink ){ return ( mNeuron->at( inIndexOfNeuralLink) ); }; virtual double Process( ){ return mNeuron->Process( ); }; virtual double Process( double inArg ){ return mNeuron->Process( inArg ); }; virtual double Derivative( ){ return mNeuron->Derivative( ); }; virtual void SetInputLink( NeuralLink<T> * inLink ){ mNeuron->SetInputLink( inLink ); }; virtual std::vector<NeuralLink<T > *>& GetInputLink( ){ return mNeuron->GetInputLink( ); }; virtual double PerformTrainingProcess( double inTarget ); virtual void PerformWeightsUpdating( ); virtual void ShowNeuronState( ){ mNeuron->ShowNeuronState( ); }; protected: Neuron<T> * mNeuron; };
Интерфейс нейронных связей представлен ниже, каждая связь хранит вес и указатель на нейрон:
Интерфейс нейронной связи
template <typename T> class Neuron; template <typename T> class NeuralLink { public: NeuralLink( ) : mWeightToNeuron( 0.0 ), mNeuronLinkedTo( 0 ), mWeightCorrectionTerm( 0 ), mErrorInformationTerm( 0 ), mLastTranslatedSignal( 0 ){ }; NeuralLink( Neuron<T> * inNeuronLinkedTo, double inWeightToNeuron = 0.0 ) : mWeightToNeuron( inWeightToNeuron ), mNeuronLinkedTo( inNeuronLinkedTo ), mWeightCorrectionTerm( 0 ), mErrorInformationTerm( 0 ), mLastTranslatedSignal( 0 ){ }; void SetWeight( const double& inWeight ){ mWeightToNeuron = inWeight; }; const double& GetWeight( ){ return mWeightToNeuron; }; void SetNeuronLinkedTo( Neuron<T> * inNeuronLinkedTo ){ mNeuronLinkedTo = inNeuronLinkedTo; }; Neuron<T> * GetNeuronLinkedTo( ){ return mNeuronLinkedTo; }; void SetWeightCorrectionTerm( double inWeightCorrectionTerm ){ mWeightCorrectionTerm = inWeightCorrectionTerm; }; double GetWeightCorrectionTerm( ){ return mWeightCorrectionTerm; }; void UpdateWeight( ){ mWeightToNeuron = mWeightToNeuron + mWeightCorrectionTerm; }; double GetErrorInFormationTerm( ){ return mErrorInformationTerm; }; void SetErrorInFormationTerm( double inEITerm ){ mErrorInformationTerm = inEITerm; }; void SetLastTranslatedSignal( double inLastTranslatedSignal ){ mLastTranslatedSignal = inLastTranslatedSignal; }; double GetLastTranslatedSignal( ){ return mLastTranslatedSignal; }; protected: double mWeightToNeuron; Neuron<T> * mNeuronLinkedTo; double mWeightCorrectionTerm; double mErrorInformationTerm; double mLastTranslatedSignal; };
Каждая активационная функция наследует от абстрактного класса, реализуя саму функцию и производную:
Интерфейс активационной функции
class NetworkFunction { public: NetworkFunction(){}; virtual ~NetworkFunction(){}; virtual double Process( double inParam ) = 0; virtual double Derivative( double inParam ) = 0; }; class Linear : public NetworkFunction { public: Linear(){}; virtual ~Linear(){}; virtual double Process( double inParam ){ return inParam; }; virtual double Derivative( double inParam ){ return 0; }; }; class Sigmoid : public NetworkFunction { public: Sigmoid(){}; virtual ~Sigmoid(){}; virtual double Process( double inParam ){ return ( 1 / ( 1 + exp( -inParam ) ) ); }; virtual double Derivative( double inParam ){ return ( this->Process(inParam)*(1 - this->Process(inParam)) );}; }; class BipolarSigmoid : public NetworkFunction { public: BipolarSigmoid(){}; virtual ~BipolarSigmoid(){}; virtual double Process( double inParam ){ return ( 2 / ( 1 + exp( -inParam ) ) - 1 ) ;}; virtual double Derivative( double inParam ){ return ( 0.5 * ( 1 + this->Process( inParam ) ) * ( 1 - this->Process( inParam ) ) ); }; };
За производство нейронов ответственна нейронная фабрика:
Интерфейс нейронной фабрики
template <typename T> class NeuronFactory { public: NeuronFactory(){}; virtual ~NeuronFactory(){}; virtual Neuron<T> * CreateInputNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ) = 0; virtual Neuron<T> * CreateOutputNeuron( NetworkFunction * inNetFunc ) = 0; virtual Neuron<T> * CreateHiddenNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ) = 0; }; template <typename T> class PerceptronNeuronFactory : public NeuronFactory<T> { public: PerceptronNeuronFactory(){}; virtual ~PerceptronNeuronFactory(){}; virtual Neuron<T> * CreateInputNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ){ return new Neuron<T>( inNeuronsLinkTo, inNetFunc ); }; virtual Neuron<T> * CreateOutputNeuron( NetworkFunction * inNetFunc ){ return new OutputLayerNeuronDecorator<T>( new Neuron<T>( inNetFunc ) ); }; virtual Neuron<T> * CreateHiddenNeuron( std::vector<Neuron<T > *>& inNeuronsLinkTo, NetworkFunction * inNetFunc ){ return new HiddenLayerNeuronDecorator<T>( new Neuron<T>( inNeuronsLinkTo, inNetFunc ) ); }; };
Сама нейронная сеть хранит указатели на нейроны, организованные
слоями ( вообще, указатели на нейроны хранятся в векторах, которые
нужно заменить на объекты-слои ), включает в себя абстрактную
фабрику нейронов, а также алгоритм обучения сети.
Интерфейс нейронной сети
template <typename T> class TrainAlgorithm; /** * Neural network class. * An object of that type represents a neural network of several types: * - Single layer perceptron; * - Multiple layers perceptron. * * There are several training algorithms available as well: * - Perceptron; * - Backpropagation. * * How to use this class: * To be able to use neural network , you have to create an instance of that class, specifying * a number of input neurons, output neurons, number of hidden layers and amount of neurons in hidden layers. * You can also specify a type of neural network, by passing a string with a name of neural network, otherwise * MultiLayerPerceptron will be used. ( A training algorithm can be changed via public calls); * * Once the neural network was created, all u have to do is to set the biggest MSE required to achieve during * the training phase ( or u can skip this step, then mMinMSE will be set to 0.01 ), * train the network by providing a training data with target results. * Afterwards u can obtain the net response by feeding the net with data; * */ template <typename T> class NeuralNetwork { public: /** * A Neural Network constructor. * - Description: A template constructor. T is a data type, all the nodes will operate with. Create a neural network by providing it with: * @param inInputs - an integer argument - number of input neurons of newly created neural network; * @param inOutputs- an integer argument - number of output neurons of newly created neural network; * @param inNumOfHiddenLayers - an integer argument - number of hidden layers of newly created neural network, default is 0; * @param inNumOfNeuronsInHiddenLayers - an integer argument - number of neurons in hidden layers of newly created neural network ( note that every hidden layer has the same amount of neurons), default is 0; * @param inTypeOfNeuralNetwork - a const char * argument - a type of neural network, we are going to create. The values may be: * <UL> * <LI>MultiLayerPerceptron;</LI> * <LI>Default is MultiLayerPerceptron.</LI> * </UL> * - Purpose: Creates a neural network for solving some interesting problems. * - Prerequisites: The template parameter has to be picked based on your input data. * */ NeuralNetwork( const int& inInputs, const int& inOutputs, const int& inNumOfHiddenLayers = 0, const int& inNumOfNeuronsInHiddenLayers = 0, const char * inTypeOfNeuralNetwork = "MultiLayerPerceptron" ); ~NeuralNetwork( ); /** * Public method Train. * - Description: Method for training the network. * - Purpose: Trains a network, so the weights on the links adjusted in the way to be able to solve problem. * - Prerequisites: * @param inData - a vector of vectors with data to train with; * @param inTarget - a vector of vectors with target data; * - the number of data samples and target samples has to be equal; * - the data and targets has to be in the appropriate order u want the network to learn. */ bool Train( const std::vector<std::vector<T > >& inData, const std::vector<std::vector<T > >& inTarget ); /** * Public method GetNetResponse. * - Description: Method for actually get response from net by feeding it with data. * - Purpose: By calling this method u make the network evaluate the response for u. * - Prerequisites: * @param inData - a vector data to feed with. */ std::vector<int> GetNetResponse( const std::vector<T>& inData ); /** * Public method SetAlgorithm. * - Description: Setter for algorithm of training the net. * - Purpose: Can be used for dynamic change of training algorithm. * - Prerequisites: * @param inTrainingAlgorithm - an existence of already created object of type TrainAlgorithm. */ void SetAlgorithm( TrainAlgorithm<T> * inTrainingAlgorithm ) { mTrainingAlgoritm = inTrainingAlgorithm; }; /** * Public method SetNeuronFactory. * - Description: Setter for the factory, which is making neurons for the net. * - Purpose: Can be used for dynamic change of neuron factory. * - Prerequisites: * @param inNeuronFactory - an existence of already created object of type NeuronFactory. */ void SetNeuronFactory( NeuronFactory<T> * inNeuronFactory ) { mNeuronFactory = inNeuronFactory; }; /** * Public method ShowNetworkState. * - Description: Prints current state to the standard output: weight of every link. * - Purpose: Can be used for monitoring the weights change during training of the net. * - Prerequisites: None. */ void ShowNetworkState( ); /** * Public method GetMinMSE. * - Description: Returns the biggest MSE required to achieve during the training phase. * - Purpose: Can be used for getting the biggest MSE required to achieve during the training phase. * - Prerequisites: None. */ const double& GetMinMSE( ){ return mMinMSE; }; /** * Public method SetMinMSE. * - Description: Setter for the biggest MSE required to achieve during the training phase. * - Purpose: Can be used for setting the biggest MSE required to achieve during the training phase. * - Prerequisites: * @param inMinMse - double value, the biggest MSE required to achieve during the training phase. */ void SetMinMSE( const double& inMinMse ){ mMinMSE = inMinMse; }; /** * Friend class. */ friend class Hebb<T>; /** * Friend class. */ friend class Backpropagation<T>; protected: /** * Protected method GetLayer. * - Description: Getter for the layer by index of that layer. * - Purpose: Can be used by inner implementation for getting access to neural network's layers. * - Prerequisites: * @param inInd - an integer index of layer. */ std::vector<Neuron<T > *>& GetLayer( const int& inInd ){ return mLayers[inInd]; }; /** * Protected method size. * - Description: Returns the number of layers in the network. * - Purpose: Can be used by inner implementation for getting number of layers in the network. * - Prerequisites: None. */ unsigned int size( ){ return mLayers.size( ); }; /** * Protected method GetNumOfOutputs. * - Description: Returns the number of units in the output layer. * - Purpose: Can be used by inner implementation for getting number of units in the output layer. * - Prerequisites: None. */ std::vector<Neuron<T > *>& GetOutputLayer( ){ return mLayers[mLayers.size( )-1]; }; /** * Protected method GetInputLayer. * - Description: Returns the input layer. * - Purpose: Can be used by inner implementation for getting the input layer. * - Prerequisites: None. */ std::vector<Neuron<T > *>& GetInputLayer( ){ return mLayers[0]; }; /** * Protected method GetBiasLayer. * - Description: Returns the vector of Biases. * - Purpose: Can be used by inner implementation for getting vector of Biases. * - Prerequisites: None. */ std::vector<Neuron<T > *>& GetBiasLayer( ) { return mBiasLayer; }; /** * Protected method UpdateWeights. * - Description: Updates the weights of every link between the neurons. * - Purpose: Can be used by inner implementation for updating the weights of links between the neurons. * - Prerequisites: None, but only makes sense, when its called during the training phase. */ void UpdateWeights( ); /** * Protected method ResetCharges. * - Description: Resets the neuron's data received during iteration of net training. * - Purpose: Can be used by inner implementation for reset the neuron's data between iterations. * - Prerequisites: None, but only makes sense, when its called during the training phase. */ void ResetCharges( ); /** * Protected method AddMSE. * - Description: Changes MSE during the training phase. * - Purpose: Can be used by inner implementation for changing MSE during the training phase. * - Prerequisites: * @param inInd - a double amount of MSE to be add. */ void AddMSE( double inPortion ){ mMeanSquaredError += inPortion; }; /** * Protected method GetMSE. * - Description: Getter for MSE value. * - Purpose: Can be used by inner implementation for getting access to the MSE value. * - Prerequisites: None. */ double GetMSE( ){ return mMeanSquaredError; }; /** * Protected method ResetMSE. * - Description: Resets MSE value. * - Purpose: Can be used by inner implementation for resetting MSE value. * - Prerequisites: None. */ void ResetMSE( ) { mMeanSquaredError = 0; }; NeuronFactory<T> * mNeuronFactory; /*!< Member, which is responsible for creating neurons @see SetNeuronFactory */ TrainAlgorithm<T> * mTrainingAlgoritm; /*!< Member, which is responsible for the way the network will trained @see SetAlgorithm */ std::vector<std::vector<Neuron<T > *> > mLayers; /*!< Inner representation of neural networks */ std::vector<Neuron<T > *> mBiasLayer; /*!< Container for biases */ unsigned int mInputs, mOutputs, mHidden; /*!< Number of inputs, outputs and hidden units */ double mMeanSquaredError; /*!< Mean Squared Error which is changing every iteration of the training*/ double mMinMSE; /*!< The biggest Mean Squared Error required for training to stop*/ };
И, наконец, сам интерфейс класса, ответственного за обучение сети:
Интерфейс алгоритма обучения
template <typename T> class NeuralNetwork; template <typename T> class TrainAlgorithm { public: virtual ~TrainAlgorithm(){}; virtual double Train(const std::vector<T>& inData, const std::vector<T>& inTarget) = 0; virtual void WeightsInitialization() = 0; protected: }; template <typename T> class Hebb : public TrainAlgorithm<T> { public: Hebb(NeuralNetwork<T> * inNeuralNetwork) : mNeuralNetwork(inNeuralNetwork){}; virtual ~Hebb(){}; virtual double Train(const std::vector<T>& inData, const std::vector<T>& inTarget); virtual void WeightsInitialization(); protected: NeuralNetwork<T> * mNeuralNetwork; }; template <typename T> class Backpropagation : public TrainAlgorithm<T> { public: Backpropagation(NeuralNetwork<T> * inNeuralNetwork); virtual ~Backpropagation(){}; virtual double Train(const std::vector<T>& inData, const std::vector<T>& inTarget); virtual void WeightsInitialization(); protected: void NguyenWidrowWeightsInitialization(); void CommonInitialization(); NeuralNetwork<T> * mNeuralNetwork; };
Весь код доступен на github: Sovietmade/NeuralNetworks
В качестве заключения, хотелось бы отметить, что тема нейронных сетей на данный момент не разработана полностью, вновь и вновь мы видим на страницах хабра упоминания о новых достижениях ученых в области нейронных сетей, новых удивительных разработках. С моей стороны,
эта статья была первым шагом освоения интереснейшей технологии, и я надеюсь для кого — то она окажется небесполезной.
Использованная литература:
Алгоритм обучения нейронной сети был взят из изумительной книги:
Laurene V. Fausett “Fundamentals of Neural Networks: Architectures, Algorithms And Applications”.

