
В этой статье я продолжу знакомить хабрасообщество с техниками, обеспечивающими написание lock-free контейнеров, попутно рекламируя (надеюсь, не слишком навязчиво) свою библиотеку libcds.
Речь пойдет об ещё одной технике безопасного освобождения памяти для lock-free контейнеров — RCU. Эта техника существенно отличается от рассмотренных ранее алгоритмов a la Hazard Pointer.
Read – Copy Update (RCU) – техника синхронизации, предназначенная для «почти read-only», то есть редко изменяемых, структур данных. Типичными примерами такой структуры являются map и set – в них большинство операций является поиском, то есть чтением данных. Считается, что для типичного map'а более 90% вызываемых операций — это поиск по ключу, поэтому важно, чтобы операция поиска была наиболее быстрой; синхронизация поиска в принципе не нужна — читатели при отсутствии писателей могут работать параллельно. RCU обеспечивает наименьшие накладные расходы как раз для read-операций.
Откуда взялось название Read – Copy Update? Первоначально идея была очень проста: есть некоторая редко изменяемая структура данных. Если нам требуется изменить её, то мы делаем её копию и производим изменение — добавление или удаление данных — именно в копии. При этом параллельные читатели работают с первоначальной, не измененной структурой. В некоторый безопасный момент времени, когда нет читателей, мы можем подменить структуру данных на измененную копию. В результате все последующие читатели будут видеть изменения, произведенные писателем.
Создателем и активным популяризатором техники RCU является Paul McKenney. Он возглавляет целую школу «любителей RCU», из которой вышло немало известных ученых в области lock-free и нетрадиционных схем синхронизации, а также он является «главным по RCU» в ядре Linux (Linux-kernel RCU maintainer) и автором ряда работ по RCU.
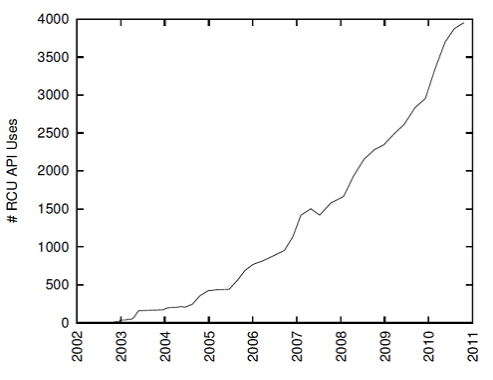
RCU была внедрена в ядро Linux в 2002 году и с тех пор все более и более врастает в код ядра, см. рисунок справа. Долгое время она позиционировалась как техника синхронизации именно для ядра операционной системы. Так как ядро имеет полный контроль над всеми потоками, — как пользовательскими, так и системными, — то в ядре довольно просто определить тот безопасный момент времени подмены данных на измененную копию. Но нас интересует прикладное применение RCU, возможно ли оно? Прежде чем ответить на этот вопрос, рассмотрим подробнее теорию RCU и применяемую в ней терминологию.
Общее описание RCU
Приведенное выше описание идеи RCU очень упрощенно. Как мы знаем, имея атомарные операции, мы можем не делать копию данных, а изменять структуру данных «на лету» параллельно с её чтением. Тогда «читателем» становится поток, выполняющий любую операцию, кроме удаления элемента из структуры данных. Писателем будем называть поток, удаляющий что-либо из структуры. Удаление должно производиться в момент времени, когда никто не «наступил» на удаляемые данные, иначе мы получим букет трудно обнаружимых проблем — от ABA-проблемы до memory corruption. RCU решает все эти проблемы, причем методом, отличным от рассмотренной ранее схемы Hazard Pointers.
Читатели в технике RCU выполняются в критической секции чтения (read-side critical section). При входе в такую критическую секцию читатель вызывает функцию
rcu_read_lock(), при выходе — rcu_read_unlock(). Это очень легкие функции, практически не влияющие на производительность; в ядре Linux они не весят вообще ничего (zero-overhead). Если поток находится не в критической секции чтения, то говорят, что поток в спокойном состоянии (quiescent state, quiescent-состояние). Любой период времени, в котором каждый поток хотя бы единожды находился в quiescent-состоянии, называют grace period. Каждая критическая секция чтения, которая началась перед grace period, должна закончиться прежде, чем закончится grace period. Каждый grace period гарантированно конечен, так как любая критическая секция чтения конечна (подразумевается, что число потоков конечно, а также что мы хорошие программисты и избегаем бесконечных циклов, равно как и краха потока).
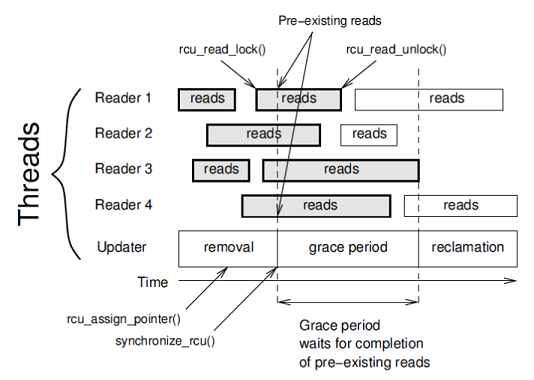
Поток-писатель, удаляющий элемент из структуры данных, исключает элемент из структуры, а затем ждет окончания grace-периода. Окончание grace-периода означает, что ни один читатель не имеет доступа к удаляемому элементу (см. рисунок, на нем прямоугольники «reads» — это критически секции чтения). Поэтому поток-писатель может безопасно физически удалить элемент.
Удаление производится в два этапа: первый этап — «removal» — атомарно удаляет элемент из структуры данных, но не производит физического освобождения памяти. Вместо этого писатель объявляет начало grace-периода вызовом специального примитива
synchronize_rcu() и ожидает его окончания. Удаленный элемент может быть доступен только тем читателям, которые объявили свою критическую секцию чтения параллельно с писателем (на рисунке такие секции выделены серым). По определению, все такие читатели закончат свою работу перед окончанием grace-периода. По окончании grace-периода, то есть когда все критические секции чтения, инициированные или активные во время grace-периода, завершатся, наступает второй этап удаления — «reclamation» — то есть физическое удаление памяти под элемент.Как видим, техника синхронизации RCU довольно проста. Остается вопрос — как определить окончание grace-периода в пользовательском коде? Оригинальный RCU сильно заточен на ядро Linux, где это определить значительно проще, так как мы имеем полный контроль над всеми потоками. Для user space-кода подходы оригинального RCU неприменимы.
User-space RCU
Решение дал в 2009 году M.Desnoyers, представитель школы P. McKenney, в своей диссертации, глава 6 которой так и называется: User-Level Implementations of RCU.
M.Desnoyers предлагает 3 решения для user-space RCU (URCU):
- Quiescent-State-Based Reclamation RCU – очень легкая для читателей схема, но требующая, чтобы потоки, находящиеся вне критической секции чтения, периодически объявляли «я нахожусь в quiescent-состоянии». Такое решение не подходит для библиотеки общего назначения, которой является libcds, поэтому я его рассматривать не буду.
- User-space RCU общего назначения (General-Purpose URCU) – подходящий для общей реализации алгоритм, который я опишу далее.
- User-space RCU на сигналах (RCU via Signal Handling) – тоже интересный алгоритм, основанный на сигналах (подходит для *nix-систем, неприменим для Windows). Реализован в библиотеке libcds, показывает производительность чуть хуже, чем general-purpose RCU. Я не буду его рассматривать в этой статье, интересующихся отсылаю к диссертации M.Desnoyers'а и к исходным кодам libcds.
General-Purpose URCU
M.Desnoyers настолько подробно и тщательно разбирает алгоритм URCU, что мне остается только следовать за ним, изменив только название некоторых переменных и функций, чтобы они соответствовали принятым в libcds.
В схеме URCU определены две переменные:
std::atomic<uint32_t> g_nGlobalCtl(1) ; struct thread_record { std::atomic<uint32_t> nThreadCtl; thread_record * pNext; thread_record(): nThreadCtl(0), pNext(nullptr) {} };
Структура
thread_record содержит локальные для потока данные и связывает все такие объекты в список RCU-потоков.Младшие 31 бита
nThreadCtl содержит счетчик глубины вложенности вызовов URCU (да, URCU допускает практически неограниченную вложенность критических секций чтения), старший бит определяет идентификатор grace-периода на момент входа потока в критическую секцию чтения. В описываемой схеме достаточно только двух идентификаторов для grace-периода.Старший бит глобальной переменной
g_nGlobalCtl содержит идентификатор текущего grace-периода, младшие биты служат для инициализации per-thread переменных nThreadCtl и не изменяются.Для входа/выхода в/из критической секции чтения служат функции
access_lock и access_unlock соответственно:static uint32_t const c_nControlBit = 0x80000000; static uint32_t const c_nNestMask = c_nControlBit — 1; void access_lock() { thread_record * pRec = get_thread_record(); assert( pRec != nullptr ); uint32_t tmp = pRec->nThreadCtl.load( std::memory_order_relaxed ); if ( (tmp & c_nNestMask) == 0 ) { pRec->nThreadCtl.store(g_nGlobalCtl.load( std::memory_order_relaxed ), std::memory_order_relaxed ); std::thread_fence( std::memory_order_acquire ); } else pRec->nThreadCtl.fetch_add( 1, std::memory_order_relaxed ); } void access_unlock() { thread_record * pRec = get_thread_record(); assert( pRec != nullptr ); pRec->nThreadCtl.fetch_sub( 1, std::memory_order_release ); }
При входе в критическую секцию URCU проверяется, вложенный это вызов или нет. Если вызов вложенный (то есть счетчик в младших 31 бите не ноль), счетчик вложенности просто инкрементируется. Если же вызов не вложенный, переменной
nThreadCtl текущего потока присваивается значение глобальной переменной g_nGlobalCtl; тем самым помечается, что вход в критическую секцию был произведен в определенный grace-период (старший бит g_nGlobalCtl), а единица в младших битах g_nGlobalCtl инициализирует счетчик вложенности текущего потока. При первом, самом внешнем входе в критическую секцию применяется acquire-барьер памяти. Он гарантирует, что последующий код не будет перенесен («оптимизирован») вверх за барьер ни процессором, ни компилятором. Тем самым обеспечивается видимость текущего grace-периода потока всем процессорам, — если нарушить этот порядок, алгоритм URCU рассыплется. При входе во вложенную критическую секцию барьера не требуется, так как текущий grace-период (старший бит) не изменяется.При выходе из критической секции (
access_unlock) просто декрементируется счетчик вложенности в nThreadCtl текущего потока. Применяется release-семантика атомарной операции; на самом деле, release-барьер необходим здесь только при выходе из самой верхней критической секции (при переходе от 1 к 0 счетчика вложенности), при выходе из вложенной критической секции достаточно relaxed-семантики. Release-барьер при обнулении счетчика требуется потому, что при переходе счетчика вложенности от 1 к 0 фактически происходит объявление «поток более не использует RCU», то есть выход из grace-периода, что является критическим для алгоритма URCU, — нарушение порядка компилятором или процессором приведет к неработоспособности алгоритма. Распознание ситуаций «0 — не 0» в коде потребует условного перехода, что вряд ли добавит производительности функции access_unlock, да и основной паттерн использования критических секций URCU – без вложенности, поэтому release-семантика применяется здесь всегда. Как видно, код со стороны читателей довольно легковесный. Используются атомарные чтение-запись и thread-local данные. Конечно, это не zero-overhead, но все же намного лучше, чем мьютекс или CAS.
Поток-писатель перед тем, как физически удалить элемент, должен убедиться, что grace-период завершен. Условия окончания grace-периода — одно из двух:
- Младшие биты (счетчик вложенности)
nThreadCtlкаждого потока равны нулю, что означает, что поток не находится в критической секции URCU - Старший бит
nThreadCtlне совпадает с со старшим битомg_nGlobalCtl, что означает, что читатель вошел в критическую секцию после начала grace-периода
Эти условия проверяются следующей функцией:
bool check_grace_period( thread_record * pRec ) { uint32_t const v = pRec->nThreadCtl.load( std::memory_order_relaxed ); return (v & general_purpose_rcu::c_nNestMask) && ((( v ^ g_nGlobalCtl.load( std::memory_order_relaxed )) & ~c_nNestedMask )); }
Писатель перед физическим удалением вызывает функцию
synchronize, которая ожидает окончания текущего grace-периода:std::mutex g_Mutex ; void synchronize() { std::atomic_thread_fence( std::memory_order_acquire ); { cds::lock::scoped_lock<std::mutex> sl( g_Mutex ); flip_and_wait(); flip_and_wait(); } std::atomic_thread_fence( std::memory_order_release ); }
Здесь
g_Mutex — глобальный для алгоритма URCU мьютекс (да-да! URCU все же техника синхронизации, так что без мьютекса никуда). Таким образом, только один поток-писатель может войти в synchronize. Не забываем, что RCU позиционируется для «почти read-only» данных, так что особой толкотни на этом мьютексе не ожидается.Писатель ожидает окончания grace-периода, вызывая функцию
flip_and_wait:void flip_and_wait() { g_nGlobalCtl.fetch_xor( c_nControlBit, std::memory_order_seq_cst ); for (thread_record* pRec = g_ThreadList.head(std::memory_order_acquire); pRec!= nullptr; pRec = pRec->m_pNext ) { while ( check_grace_period( pRec )) { sleep( 10 ); // ждем 10 миллисекунд CDS_COMPILER_RW_BARRIER ; } } }
Эта функция меняет идентификатор grace-периода, что означает начало нового grace-периода, с помощью атомарного
fetch_xor и ждет (вызовом check_grace_period), пока все потоки-читатели не закончат этот новый grace-период. В псевдокоде ожидание происходит простым sleep на 10 миллисекунд, в реальном коде libcds используется template-параметр, задающий back-off-стратегию.Почему писатель вызывает
flip_and_wait дважды? Для пояснения рассмотрим такую последовательность действий с двумя потоками A и B. Предположим, что вызов flip_and_wait в synchronize только один:- Поток A вызывает
access_lock. В теле этой функции определяется, что вызов не вложенный, читается глобальныйg_nGlobalCtl, но пока не присваивается переменнойnThreadCtlпотока (все выполняется параллельно, так что такая ситуация вполне допустима) - Поток B вызывает
synchronize. Вызывается первыйflip_and_wait, который изменяет бит-идентификатор grace-периода вg_nGlobalCtl. Текущим идентификатором grace-периода становится 1 - Так как в критической секции URCU никого нет (вспомним, что поток A ещё не успел присвоить значение своей переменной
nThreadCtl), поток B завершаетsynchronize - Поток A выполняет присваивание своей переменной
nThreadCtl. Вспомним, что поток прочитал старое значение grace-периода, равное 0 - Поток A завершает
access_lockи продолжает выполнение в критической секции - Поток B вызывает
synchronizeещё раз (видимо, опять хочет что-то удалить). Опять происходит обращение текущего grace-периода вg_nGlobalCtl, так что его идентификатор теперь 0.
Но поток A в критической секции, которая началась ранее, чем B изменил grace-период! Нарушение семантики URCU, которое приведет со временем ко всему букету — от ABA до memory corruption. Вспомним:
synchronize вызывается писателем перед тем, как физически удалить память под элементВызывая
flip_and_wait дважды, то есть дважды ожидая окончания grace-периода, мы решаем вышеописанную проблему, причина которой — конкурентное выполнение потоков.Другое решение
Можно, конечно, решить эту проблему и по-другому, если использовать вместо бита-идентификатора grace-периода некий счетчик. Но тут возникает проблема, которую мы уже видели в статье про алгоритм tagged pointer, — счетчик подвержен переполнению! Для надежности счетчик должен быть 32-битным, тогда переполнение нам не страшно. Но такой счетчик приводит к необходимости иметь 64-битный атомарный тип на 32-битовых платформах. Такого типа либо нет, либо он довольно неэффективен. Либо нам придется отказаться от вложенности критических секций URCU, что тоже не очень удобно.
Поэтому остановимся на общем решении с битом в качестве идентификатора grace-периода и вызовом двух
Поэтому остановимся на общем решении с битом в качестве идентификатора grace-периода и вызовом двух
flip_and_waitРеализация URCU в libcds

Вышеописанный алгоритм URCU хорош всем, кроме того, что перед каждым удалением требуется вызывать довольно тяжелый
synchronize. Можно ли как-то это улучшить?Да, можно, причем таким же методом, как и в алгоритме Hazard Pointer, — применить отложенное удаление. Будем вместо удаления помещать элементы в некоторый буфер. Функцию
synchronize будем вызывать только когда буфер заполнится. В отличие от Hazard Pointer, в URCU буфер будет общим для всех потоков (вообще, можно сделать и per-thread буферы, ничто этому не мешает). Более того, чтобы не тормозить писателя, на долю которого выпала доля чистить буфер при его переполнении, функционал очистки буфера, то есть действительного удаления, можно поручить отдельному потоку.
Библиотека libcds имеет пять реализаций URCU, все они живут в пространстве имен
cds::urcu:general_instant— реализация, точно следующая описанному алгоритму URCU: каждое удаление вызываетsynchronize, никакой буферизации. Если удаление у нас довольно частая операция, то есть структура не слишком-то «почти read-only», данная реализация довольно тормознаяgeneral_buffered— реализация с общим lock-free буфером предопределенного размера. В качестве lock-free буфера используется очередь Дмитрия Вьюкова —cds::container::VyukovMPMCCycleQueue. Производительность такой реализации сравнима с Hazard Pointergeneral_threaded— подобнаgeneral_buffered, но очистку буферов производит выделенный поток. Такая реализация немного уступаетgeneral_bufferedза счет дополнительной синхронизации с выделенным потоком, зато не тормозит писателейsignal_buffered— аналогgeneral_buffered, но основан на signal-handled URCU. Не для Windows-системsignal_threaded— аналогgeneral_threadedдля signal-handled URCU. Также не для Windows
Такое обилие реализаций URCU порождает проблему написания специализаций контейнеров под URCU. Дело в том, что реализация контейнеров под схему URCU значительно отличается от реализации для Hazard Pointer. Поэтому требуется отдельная специализация для URCU. Хотелось бы иметь одну специализацию, а не пять.
Для облегчения написания специализации под URCU был введен класс-обертка
cds::urcu::gc:template <typename RCUimpl> class gc;
где
RCUimpl — одна из реализаций URCU: general_instant, general_buffered и т. д. Имея такую обертку, специализацию для URCU написать легко и она будет единственной:template < class RCU, typename Key, typename Value, class Traits > class SplitListMap< cds::urcu::gc< RCU >, Key, Value, Traits > ...
Cледует отметить, что в libcds основной функцией алгоритма URCU при удалении является не
synchronize, а retire_ptr. Эта функция помещает удаляемый элемент в буфер URCU и в нужный момент (например, когда буфер заполнен) вызывает synchronize. Так что явный вызов synchronize не требуется, хотя и допустим. К тому же такое решение унифицирует интерфейс URCU и Hazard Pointer.Все перечисленные алгоритмы URCU реализованы в типичной для libcds манере: для каждой существует глобальный объект-синглтон, инициализация которого происходит вызовом конструктора объекта-обертки
cds::urcu::gc<cds::urcu::general_buffered<> > в начале main(), после вызова cds::Initialize():#include <cds/init.h> //cds::Initialize и cds::Terminate #include <cds/gc/general_buffered.h> // general_buffered URCU int main(int argc, char** argv) { // Инициализируем libcds cds::Initialize() ; { // Инициализируем general_buffered URCU синглтон cds::urcu::gc<cds::urcu::general_buffered<> > gbRCU ; // Если main thread использует lock-free контейнеры // main thread должен быть подключен // к инфраструктуре libcds cds::threading::Manager::attachThread() ; // Всё, libcds готова к использованию // Далее располагается ваш код ... } // Завершаем libcds cds::Terminate() ; }
Так же, как и для схемы Hazard Pointer, каждый поток, использующий URCU-контейнеры, должен быть инициализирован особым образом:
// cds::threading::Manager #include <cds/threading/model.h> int myThreadEntryPoint(void *) { // Подключение потока к инфраструктуре libcds cds::threading::Manager::attachThread() ; // Теперь в данном потоке мы можем использовать // lock-free контейнеры libcds ... // Отключение потока от libcds cds::threading::Manager::detachThread() ; return 0; }
Использование URCU-контейнеров библиотеки libcds совершенно прозрачно: достаточно просто объявить объект-контейнер с URCU gc, — и всё. Вся специфика работы с URCU спрятана внутри URCU-специализации контейнера. Никакой внешней синхронизации при доступе к такому контейнеру не требуется.
UPD: Упс!
«Никакой внешней синхронизации не требуется» — это я несколько погорячился.
На самом деле, некоторые методы некоторых URCU-контейнеров требуют предварительного входа в критическую секцию чтения. Как правило, это методы удаления (извлечения) элемента контейнера. URCU может обеспечить нам возможность возврата указателя на найденный по ключу элемент. Такая возможность — редкое исключение в мире lock-free, где обычно возврат указателя смерти подобен, так как элемент может быть удален в любой момент конкурирующим потоком. Но чтобы безопасно работать с возвращенным указателем на элемент, мы должны находится в критической секции чтения. Так что в этом случае следует явно перед вызовом метода контейнера вызвать
В описании каждого метода URCU-контейнера библиотеки libcds отмечается, как следует вызывать данный метод — в критической секции или нет.
На самом деле, некоторые методы некоторых URCU-контейнеров требуют предварительного входа в критическую секцию чтения. Как правило, это методы удаления (извлечения) элемента контейнера. URCU может обеспечить нам возможность возврата указателя на найденный по ключу элемент. Такая возможность — редкое исключение в мире lock-free, где обычно возврат указателя смерти подобен, так как элемент может быть удален в любой момент конкурирующим потоком. Но чтобы безопасно работать с возвращенным указателем на элемент, мы должны находится в критической секции чтения. Так что в этом случае следует явно перед вызовом метода контейнера вызвать
access_lock, а по завершении работы с указателем — access_unlock, а лучшей (exception-safe) методикой будет применение scoped-lock в отдельном блоке кода.В описании каждого метода URCU-контейнера библиотеки libcds отмечается, как следует вызывать данный метод — в критической секции или нет.
Если же вы решитесь сделать свой собственный класс контейнера, основанный на реализации URCU из libcds, следует подробно разобраться с внутренним устройством URCU-контейнеров библиотеки. В принципе, ничего сверхестественного нет: при входе в метод вызываем
gc::access_lock(), при выходе — gc::access_unlock() (здесь gc — это одна из реализаций URCU; для безопасности исключений лучше использовать технику scoped lock вместо вызова функций). Единственный тонкий момент — удаление элемента: метод удаления также должен входить в критическую секцию чтения, но физическое удаление элемента, осуществляемое вызовом gc::retire_ptr, должно производиться вне критической секции, иначе возможен deadlock: метод gc::retire_ptr внутри может вызвать synchronize.Libcds определяет URCU-специализации для всех классов set и map. URCU-специализации для контейнеров типа «очередь» и «стек» не определено, — это не «почти read-only» контейнеры, так что URCU не для них.
Lock-free структуры данных

