В наш век только бесполезные вещи и необходимы человеку. Оскар Уайльд, Портрет Дориана Грея (источник)
А вы никогда не задумывались, чем обычный пост на хабре (порошок обычныйTM) отличается от tutorial? И как это «отличается» вообще можно измерить? Есть ли здесь какие-то закономерности и можно ли по ним предсказать метку:

В данной статье мы обсудим так называемый exploratory data analysis или кратко EDA (исследовательский анализ данных) применительно к статьям Хабрахабра, а в частности уделим особое внимание tutorial. Прежде всего EDA направлен на детальное изучение данных, и необходим для понимания, с чем мы собственно работаем. Важной частью является сбор и очистка данных и сам выбор какие данные собирать. Особенность метода состоит в визуализации и поиске важных характеристик и тенденций.
Exploratory data analysis — это первый шаг в изучении и понимании данных, без него мы можем загнать себя в многочисленные ловушки, описанные ранее автором в статье: "Как правильно лгать с помощью статистики".
Как выглядит обычный хабра-tutorial
В качестве простой демонстрации рассмотрим простейшую картину из трех параметров: просмотры, избранное (favourites) и рейтинг (количество плюсов), для трех классов: все статьи вместе, обычный пост (не-tutorial) и tutorial.
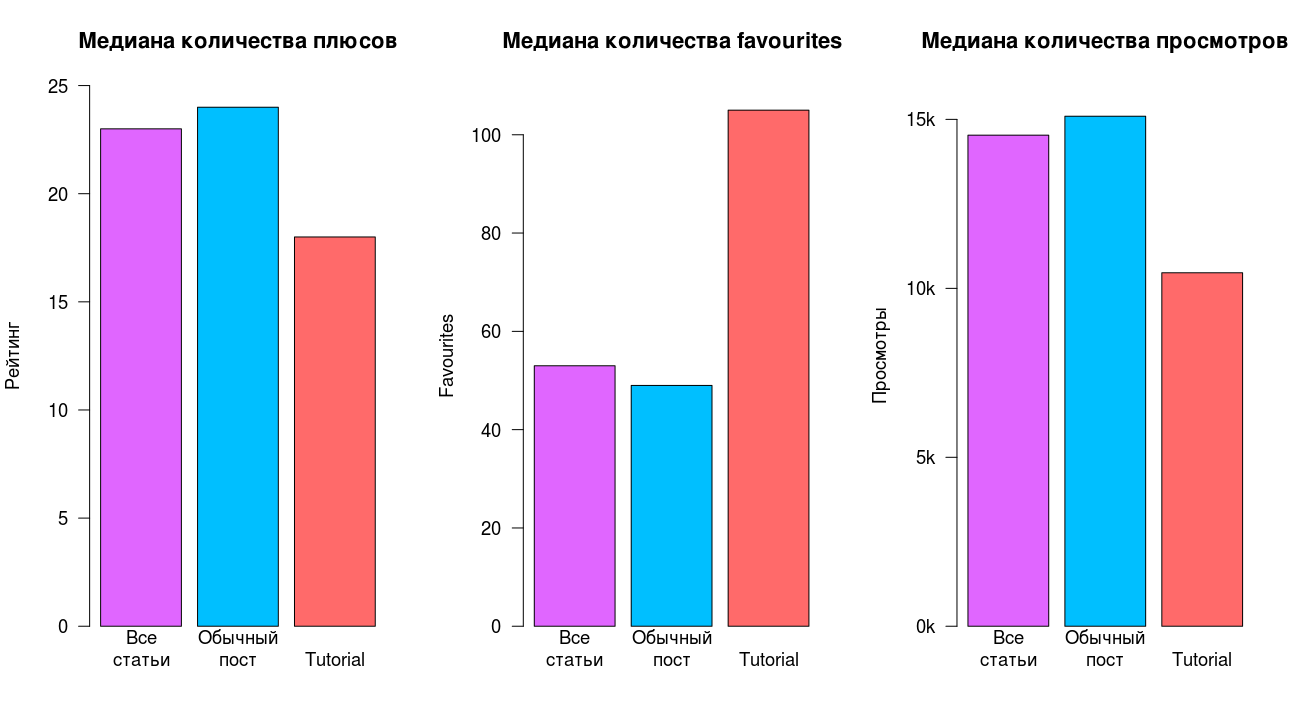
Даже в столь упрощенной картине, заметна разница между классами. Наша интуиция и здравый смысл подсказывают нам, что tutorial в среднем чаще добавляют в избранное, но интуиция не говорит насколько чаще, и что они набирают меньше плюсов и просмотров. Эти и многие другие интересные вопросы мы рассмотрим далее в статье.
Структура статьи
- Как выглядит обычный хабра-tutorial
- Собираем данные
- Хабра-данные
- Исследуем tutorials
- Разбираем интересные примеры
- Предсказываем метку tutorial
- Как сделать набор данных лучше
- Заключение
- Дальнейшее чтение
Собираем данные
Одно из важнейших свойств исследования и эксперимента — это его воспроизводимость и прозрачность. Поэтому это невероятно важно предоставить все исходные материалы, которые идут с работой — данные, алгоритм их сбора, алгоритм подсчета, реализация, визуализация и выходные характеристики. К данной статье прилагается весь код, данные и скрипты для анализа и визуализации — они доступны через github. Для графиков и скриптов приведены отдельные ссылки, наиболее важные и интересные части кода также доступны в статье в виде раскрывающегося текста («спойлеров»).
Это позволяет проверить аутентичность данных, визуализацию и корректность вычислений. Например, исходное изображение гистограмм в начале статьи сделано с помощь скрипта histograms_into.R на датасете all.csv (описание приводится ниже).
Начнем с высокоуровневого описания алгоритма сбора данных по хабра-статьям

Мы просто последовательно проходимся по каждой ссылке и парсим страницу.
Одна из возможных реализаций перебора статей по id (а так же сбор статей из лучшего) приведена здесь, весь алгоритм состоит из трех компонент: перебор страниц статей (приведен выше в виде псевдо-кода), parsing страницы (
processPage) и записи (класса) Хабра-статья (habra-article). Реализация перебора статей на python
from __future__ import print_function import time from habraPageParser import HabraPageParser from article import HabraArticle class HabraPageGenerator: @staticmethod def generatePages(rooturl): articles = [] suffix = "page" for i in range(1,101): if i > 1: url = rooturl+suffix+str(i) else: url = rooturl print(url) pageArticles = HabraPageParser.parse(url) if pageArticles is not None: articles = articles + pageArticles else: break return articles @staticmethod def generateTops(): WEEK_URL = 'http://habrahabr.ru/posts/top/weekly/' MONTH_URL = 'http://habrahabr.ru/posts/top/monthly/' ALLTIME_URL = 'http://habrahabr.ru/posts/top/alltime/' articles = [] articles = articles + HabraPageGenerator.generatePages(ALLTIME_URL) articles = articles + HabraPageGenerator.generatePages(MONTH_URL) articles = articles + HabraPageGenerator.generatePages(WEEK_URL) return articles @staticmethod def generateDataset(dataset_name): FIRST_TUTORIAL = 152563 LAST_INDEX = 219000 BASE_URL = 'http://habrahabr.ru/post/' logname = "log-test-alive.txt" logfile = open(logname, "w") datafile = HabraArticle.init_file(dataset_name) print("generate all pages", file=logfile) print(time.strftime("%H:%M:%S"), file=logfile) logfile.flush() for postIndex in range(FIRST_TUTORIAL, LAST_INDEX): url = BASE_URL + str(postIndex) print("test: "+url, file=logfile) try: article = HabraPageParser.parse(url) if article: print("alive: "+url, file=logfile) assert(len(article) == 1) article[0].write_to_file(datafile) except: continue logfile.flush() logfile.close() datafile.close()
Код habra-article:
Реализация класса хабра-статья
from __future__ import print_function class HabraArticle: def __init__(self,post_id,title,author,score,views,favors,isTutorial): self.post_id = post_id self.title = title self.author = author self.score = score self.views = views self.favors = favors if isTutorial: self.isTutorial = 1 else: self.isTutorial = 0 def printall(self): print("id: ", self.post_id ) print("title: ", self.title) print("author: ", self.author ) print("score: ", self.score ) print("views: ", self.views ) print("favors: ", self.favors ) print("isTutorial: ", self.isTutorial) def get_csv_line(self): return self.post_id+","+self.title+","+self.author+","+ self.score+","+self.views+","+self.favors+","+str(self.isTutorial) +"\n" @staticmethod def printCSVHeader(): return "id, title, author, score, views, favors, isTutorial" @staticmethod def init_file(filename): datafile = open(filename, 'w') datafile.close() datafile = open(filename, 'a') print(HabraArticle.printCSVHeader(), file=datafile) return datafile def write_to_file(self,datafile): csv_line = self.get_csv_line() datafile.write(csv_line.encode('utf-8')) datafile.flush()
Код (beautifulsoup) функции:
processPage:processPage
import urllib2 from bs4 import BeautifulSoup import re from article import HabraArticle class HabraPageParser: @staticmethod def parse(url): try: response = urllib2.urlopen(url) except urllib2.HTTPError, err: if err.code == 404: return None else: raise html = response.read().decode("utf-8") soup = BeautifulSoup(html) #print(soup.decode('utf-8')) #if the post is closed, return None cyrillicPostIsClosed = '\xd0\xa5\xd0\xb0\xd0\xb1\xd1\x80\xd0\xb0\xd1\x85\xd0\xb0\xd0\xb1\xd1\x80 \xe2\x80\x94 \xd0\x94\xd0\xbe\xd1\x81\xd1\x82\xd1\x83\xd0\xbf \xd0\xba \xd1\x81\xd1\x82\xd1\x80\xd0\xb0\xd0\xbd\xd0\xb8\xd1\x86\xd0\xb5 \xd0\xbe\xd0\xb3\xd1\x80\xd0\xb0\xd0\xbd\xd0\xb8\xd1\x87\xd0\xb5\xd0\xbd' if soup.title.text == cyrillicPostIsClosed.decode('utf-8'): return None articles = soup.find_all(class_="post shortcuts_item") habraArticles = [] for article in articles: isScoreShown = article.find(class_="mark positive ") #if the score is published already, then article is in, otherwise we go on to next one if not isScoreShown: continue post_id = article["id"] author = article.find(class_="author") if author: author = author.a.text title = article.find(class_="post_title").text score = article.find(class_="score" ).text views = article.find(class_="pageviews" ).text favors = article.find(class_="favs_count").text tutorial = article.find(class_="flag flag_tutorial") #we need to escape the symbols in the title, it might contain commas title = re.sub(r',', " comma ", title) #if something went wrong skip this article if not post_id or not author or not title: return None habraArticle = HabraArticle(post_id,title,author,score,views,favors,tutorial) habraArticles.append(habraArticle) return habraArticles
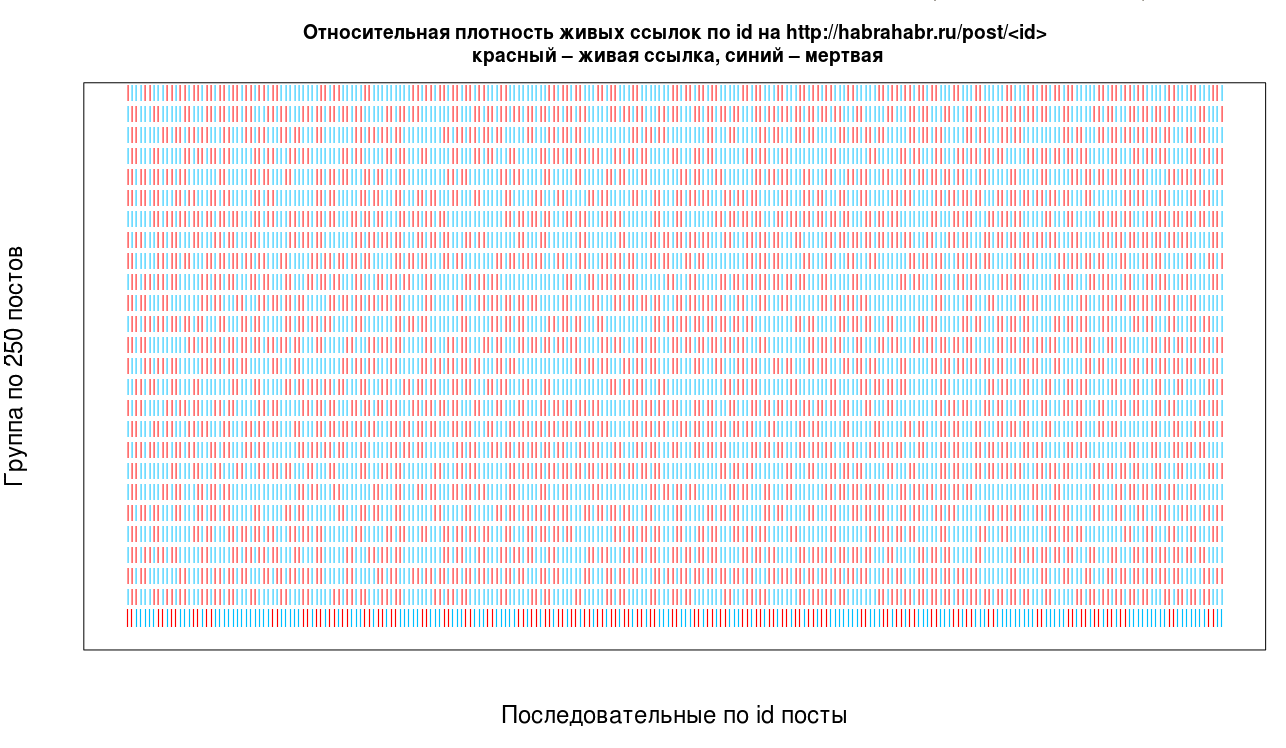
(получено применением скрипта scale_id.R на первых 6.5к точек датасета alive_test_id.csv)
Читать график нужно следующим образом: возьмем 250 последовательных значений id и выпишем их в строчку, если страница живая то пометим красным, иначе синим. Возьмем следующие 250 значений и выпишем их в следующую строчку и т.д.
Реальная плотность живых ссылок с момента публикации первого tutorial (27 сентября 2012) составляет 23%. Если предположить, что id выдается последовательно на каждый черновик, три четвертых хабра-статей, либо скрыты, либо не были дописаны.
Но(!) скорее всего реальная плотность занижена в измерениях. Это связано с недостатком метода сбора статей: проблемы с соединением, парсингом страниц или кратковременной недоступностью хабрахабра. Ручная проверка данных показала (на all.csv), что в небольшом количестве случаев <= 5-10%, реально существующие страницы не были обработаны. C учетом данной ошибки, рационально предположить, что действительная плотность лежит в диапазоне 30+-5%. Будем работать над уменьшением ошибки в следующих сериях.
Дополнительные данные
Помимо перебора всех статей по id (за указанный период) также были собраны следующие данные:
- Лучшее за всё время
- Лучшее за месяц
- Лучшее за неделю
Для сбора фактически использовался алгоритм описанный выше, который обходил ссылки:
habrahabr.ru/posts/top/alltime/page$i
habrahabr.ru/posts/top/monthly/page$i
habrahabr.ru/posts/top/weekly/page$i
для $i от 1 до 100
Хабра-данные
Собранные данные хранятся в формате csv (comma separated values) и имеют следующий вид:

Всего вместе со статьей доступны датасеты (скачано 7го апреля 2014):
- Все статьи: all.csv
- Лучшее за всё время: dataset_top_all_time.csv
- Лучшее за месяц: habra_dataset_monthly.csv
- Лучшее за неделю: habra_dataset_weekly.csv
- Лог живых страниц по id: alive_test_id.csv
Все представленные в статье графики и результаты основаны на выше приведенных данных. Преимущественно мы будем работать с файлом all.csv.
Исследуем tutorials
Рассмотрим распределение статей по основным собранным параметрам раздельно для двух классов: tutorial и обычный пост (не-tutorial). По оси Y доля статей имеющих значения соответствующего параметра на оси X. Основных параметров у нас три: просмотры, избранное и количество записей в избранном.
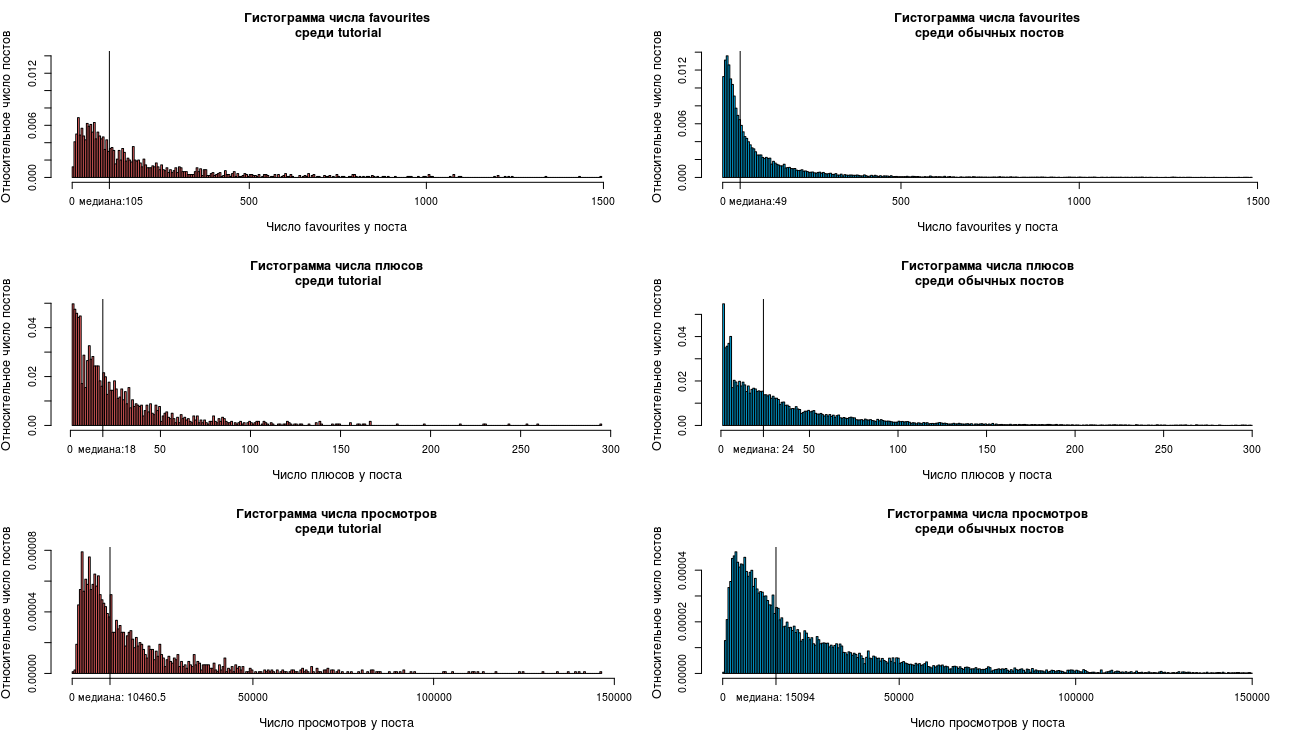
(получено с помощью скрипта histograms_tutorial_vs_normal.R на all.csv)
Если вы всегда ждали удобный момент, чтобы прочитать про Закон Ципфа, то он настал. Справа, мы видим что-то хорошо напоминающее это распределение (и думаю мы еще не раз его увидим в будущем).
В целом мы видим, что распределение голосов (плюсов) и просмотров у tutorial сдвинуто влево — относительно распределений обычных постов и так же напоминает закон Ципфа, хотя заметно, что соответствие здесь уже не такое явное. Значит в среднем, обычные посты набирают больше плюсов и просмотров. А распределение favourites уже существенно сдвинуто вправо у tutorial и совершенно не напоминает закон Ципфа. В среднем мы видим, что читатели намного активнее добавляют tutorial в избранное. Практически на всем распределении tutorial доминируют над обычными постами в два раза, приведем короткую таблицу квантилей двух распределений:

Таблица читается следующим образом: если 20%-квантиль обычного поста равен 16, это значит, что 20% всех постов обычных постов набирает не более 16 записей в избранное. Медиана — это 50%-ый квантиль, у tutorial он 109, а у обычных постов 49.
Так же стоит рассмотреть распределения параметров вместе. Из графиков выше мы видим, что favourites играют особую роль для обучающего материала и поэтому мы уделим им особое внимание в статье.
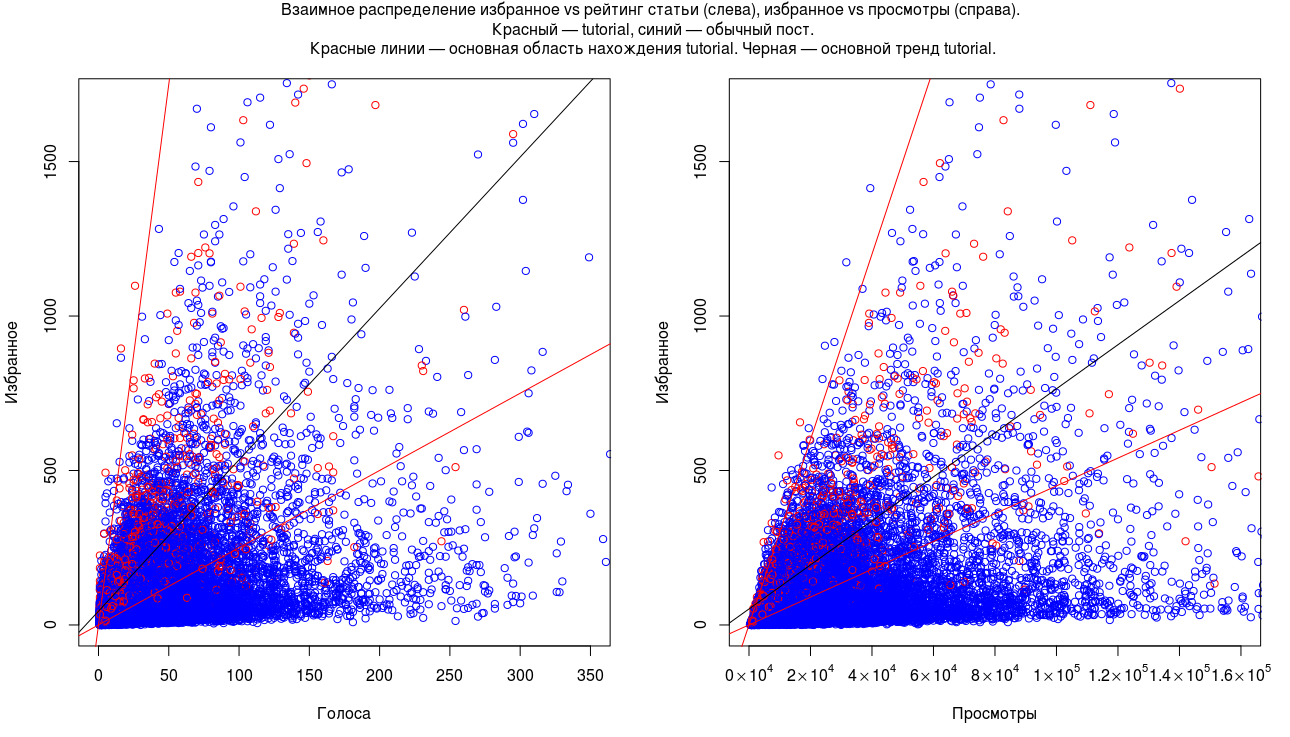
(Получено с помощью скрипта joint_favours_score_view.R на all.csv)
Из графика выше видно общий тренд в данных среди tutorial, на один плюс приходится в среднем несколько favourites, медиана отношения для tutorial'ов в 2.6 раза выше обычного поста, а на один просмотров приходится в среднем (по медиане) 2.7 раза больше favourites, чем у обычного поста.
Это позволяет очертить интересующую нас область, где скорее всего находится большинство обучающего материала без меток — синие точки в верхней границе красной области. Мы можем сформировать запросы к нашим данным и проверить эту догадку. А возможно и вывести некоторые правила, которые позволят нам автоматически «исправлять» или напоминать об этой метке авторам.
(У графиков обрезаны хвосты распределений; очень небольшое число точек попадает за указанные границы. Но включение этих точек увеличило бы масштаб и сделало бы остальные точки фактически неотличимыми и нечитаемыми.)
Разбираем интересные примеры
В этой части мы поговорим о некоторых характерных примерах, которые встречаются в данных и которые помогут нам лучше понять имеющиеся потенциальные закономерности в статьях и их свойствах.
Много favourites — плюсов мало
Запрос:
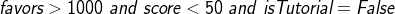
Запрос на языке R
query1 <- subset(data, favors > 1000 & score < 50 & isTutorial == FALSE)
Результат:

Как мы можем видеть первая статья — это чистый обучающий материал без метки, вторая так же может претендовать на роль обучающего материала. Мы можем заметить следующую тенденцию из графиков выше: все распределения показывают, что в среднем tutorial набирает меньше плюсов и намного больше favourites, чем обычная статья. Вкупе с тем фактом, что большое число tutorial по какой-то причине не имеют метки, мы предполагаем, что статья набравшая небольшое число плюсов и большое число записей в избранное, согласно общим трендам данных имеет хорошие шансы на то, чтобы быть обучающим материалом.
Favourites в 10 раз больше, чем плюсов (и плюсов хотя бы 25)
Запрос:
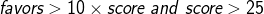
Запрос на языке R
query2 <- subset(data, favors > 10*score & score > 25)
Результат:
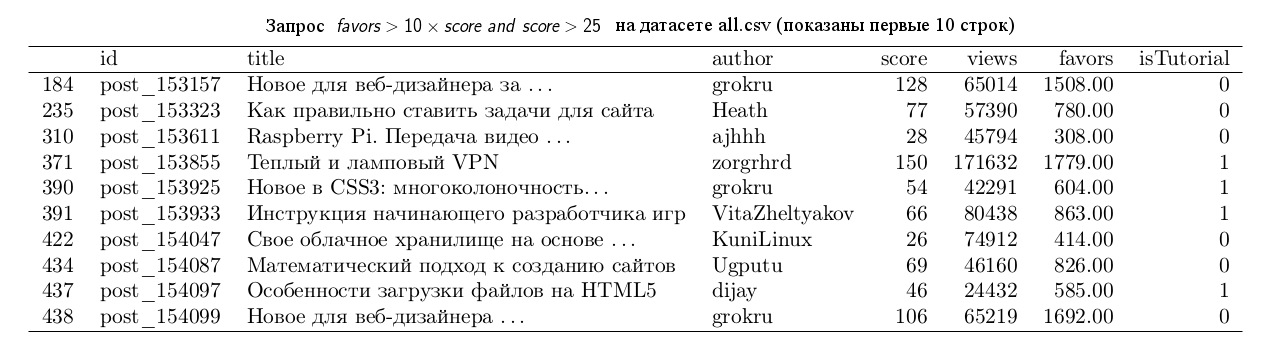
Немного усложнённая версия предыдущего запроса, мы ищем статьи, где favourites в десять раз больше, чем плюсов и при этом число плюсов по крайней мере 25. В таких условиях мы находим статьи, которые сохранило большие число людей, что может служить некоторым индикатором того, что статья будет полезна в будущем, а значит — это хороший кандидат на обучающий материал.
Минус данного запроса в том, что половина tutorial набирает 18 и менее плюсов, а значит данное правило отсекает большое число потенциальных статей tutorial.
Скрипт с запросами queries.R, датасет all.csv.
Предсказываем метку tutorial
Метке tutorial в статье соответствует бинарный атрибут isTutorial. Значит мы можем сформулировать задачу определения метки tutorial по параметрам score, view и favourites, как поиск некоторого предиката (функции, которая возвращает 1 или 0) f такого что для всего набора данных верно что
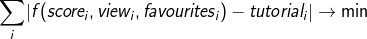
(автор признает, что он сейчас всё существенно упрощает и вообще активно машет руками — но это должно дать общую читателю о том, что нужно сделать)
На самом деле классические методы машинного обучения (такие как SVM, Random Forest, Recursive Trees, etc) не покажут на собранных данных качественных результатов по следующим причинам:
- Невероятно бедное пространство фич т.е. всего три параметра, которые недостаточно хорошо отличают tutorial от обычного поста — об этом написано внизу
- Существенное количество статей не помеченных как tutorial, но на деле ими являющихся — см. первый запрос и статью: «Настройка Nginx + LAMP сервера в домашних условиях» — это классический tutorial, но он помечен как обычный пост!
- Субъективность самой метки, наличие и\или её отсутствует во многом определяется исключительно авторским мнением
Что мы можем сделать в данной ситуации? По существующим данным мы можем попробовать вывести некоторые достаточные условия и посмотреть их выполнимость на существующих данных. Если правила соответствуют данным, то по индукции мы можем создать некоторое правило, которое бы позволило нам найти и разметить tutorial без метки. Просто, интерпретируемо и со вкусом.
Например следующее правило неплохо согласуется с данными и позволит пересмотреть некоторые метки (приводится исключительно ради примера):
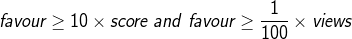
и первые записи в ответе:

Запрос на языке R
query3 <- subset(data, favors >= 10*score, favors >= views/100)
Как можно заметить, несмотря на то, что большинство записей не имеют метки tutorial, статьи в действительности ими являются (несмотря на небольшие значения score в первых 6 записях; хотя более половины tutorial имеют меньше 18 плюсов). Таким образом, мы можем провести так называемый co-training, то есть по небольшому числу данных с метками вывести правила, которые позволяют разметить оставшиеся данные и создать условия для применения классических методов машинного обучения.
Но какие бы умные алгоритмы обучения мы не применяли, самая главная проблема в классификации tutorial состоит в правильном построении пространства атрибутов, т.е. отображении статьи в некоторый вектор численных или номинативных (имеющий ряд конечных значений, например, цвет может быть синим, красным или зеленым) переменных.
Как сделать набор данных лучше
Собранный набор данных далеко не идеален, поэтому лучше всего начать критиковать его самому, пока это не сделали другие. Безусловно по одним только параметрам просмотры, рейтинг, favourites нельзя однозначно предсказать является ли данная статья tutorial'ом или нет. Однако, нам нужно получить правило, а точнее классификатор, который бы работал достаточно точно. Для этого рассмотрим еще несколько типичных черт статей, которые могут пригодиться.
Рассмотрим первый пример:
Что бросается в глаза — это во многих tutorial, присутствуют изображения, причем часто в больших количествах — да, в обычных постах они тоже могут встречаться, но это может быть ценный атрибут в совокупности с другими параметрами. Так же не стоит сбрасывать со счетов тот факт, что многие хабы тематически намного лучше подходят для обучающего материала, чем другие — возможно это тоже стоит учесть.
Рассмотрим второй пример:
Здесь наиболее важным является наличие кода и структуры, естественно предположить, что данные факторы могут хорошо дискриминировать классы между собой и значит в принципе их можно учесть в модели. Так же мы можем ввести такой параметр, как наличие обучающих материалов среди похожих постов.
Гипотетически, это дало бы нам новый датасет (и новое пространство параметров для классификации), который бы мог лучше различать классы статей между собой.

Пространство фич для классификации на самом деле может быть огромно: количество комментариев, наличие видео, ключевые слова в заголовке и многие другие. Выбор пространства является ключевым для построения успешного классификатора.
Почему стоит использовать текущий срез статей
Почему для оценки не использовать все доступные статьи с хабра? Разве это не увеличит точность классификатора? Почему мы берем только текущий срез? Ширину окна тоже на самом деле стоит подбирать разумно и это может потребовать дополнительного анализа.
Но нельзя брать выборку из вообще всех статей за весь период существования ресурса по следующей причине: ресурс постоянно развивается и характеристики статей меняются соответственно: если мы рассмотрим самые первые статьи e.g. 171, 2120, 18709 — мы увидим, что их характеристики существенно изменяются и они уже не должны входить в репрезентативную выборку современных статей, потому что в среднем мы не ожидаем таких параметров у новых статей. Во многом потому что поменялась аудитория, поменялись сами статьи и поменялись каналы распространения статей в интернете.
Заключение
Мы рассмотрели и проанализировали самые основные параметры хабра статей. Идея о том, что метку «tutorial» можно автоматически предсказывать, привела нас к тому, мы поняли, каким образом можно расширить наборы данных и в каком направлении стоит смотреть. Мы так же рассмотрели основные различия между обычными постами и обучающим материалом в терминах: просмотров, избранного и рейтинга. Выявили, что основным отличием является наличие существенно больших записей в избранном и установили численные оценки этого отличия.
Только 2.8% в топе имеют метку «обучающий материал», при доли общей в 9.1% за все время с момента её введения (27 сентября 2012), — возможно это связано с тем, что достаточное количество материала пришло в топ до появления метки или само использование метки «tutorial» еще не вошло в обиход сразу после её введения. В пользу этой гипотезы говорит, что общая доля tutorial в лучшем за неделю и месяц практически не отличается от доли среди всех постов (8.1% за месяц и 7.8% за неделю; relativeFractionOfTutorials.R).
Возможно используя расширенный набор данных, мы сможем достаточно эффективно предсказывать (с помощью различных методов машинного обучения) и сообщать автору: «Возможно, вы забыли метку tutorial». Данная задача будет прежде всего интересна потому, что это позволит составить полноценный список с подборкой интересного обучающего материала, который можно отсортировать или оценивать по параметрам отличных от плюсов, e.g. количеству людей добавивших статью в избранное.
Дальнейшее чтение
Если тема анализа данных показалась интересной, то ниже список полезного материала
- Udacity — Exploratory Data Analysis и Data Science
- Caltech — Learning from Data
- Coursera — Data Science Track (только началось!)
- Если вы живете в Санкт-Петербурге, то можно пройти курсы у DMLabs
- Если вы живете в Москве, то вы уже наверняка слышали про ШАД

