Здравствуй, Хабр! Реализовывая различные алгоритмы для нахождения гамильтонова цикла с наименьшей стоимостью, я наткнулся на публикацию, предлагающую свой вариант. Попробовав в деле, я получил неправильный ответ:

Дальнейшие поиски в Интернете не принесли ожидаемого результата: либо сложное для не-математиков теоретическое описание, либо понятное, но с ошибками.
Под катом вас будет ждать исправленный алгоритм и онлайн-калькулятор.
Сам метод, опубликованный Литтлом, Мерти, Суини, Кэрелом в 1963 г. применим ко многим NP-полным задачам, и представляет собой очень теоритеризованный материал, который без хороших знаний английского языка и математики сразу не применишь к нашей задаче коммивояжера.
Кратко о методе — это полный перебор всех возможных вариантов с отсеиванием явно неоптимальных решений.
Ошибка была одна единственная — следует выбирать для разбиения множество с минимальной границей из всех возможных путей, а не из двух полученных в результате последнего разбиения детей.
А вот решение с исправленным алгоритмом:
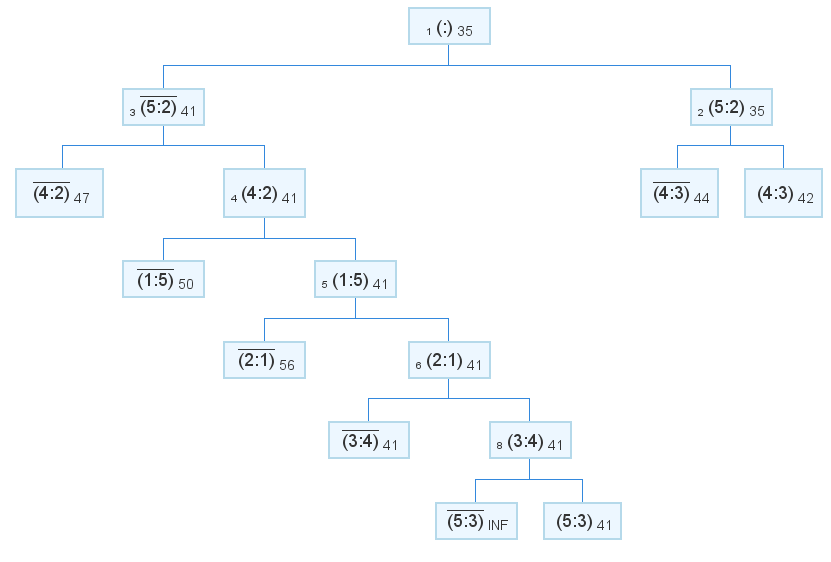
Ответ: путь:3=>4=>2=>1=>5=>3 длина: 41
Как видите, включая ребро 5:2 в решение будет ошибкой. Что и требовалось доказать
График сравнения метода ветвей и границ и потраченного времени для случайной таблицы от 5х5 до 10х10:
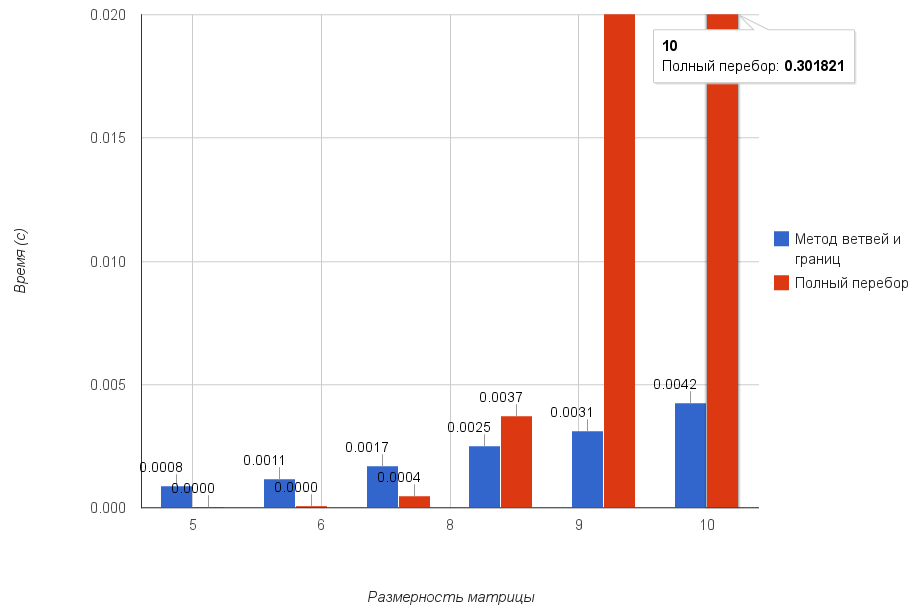
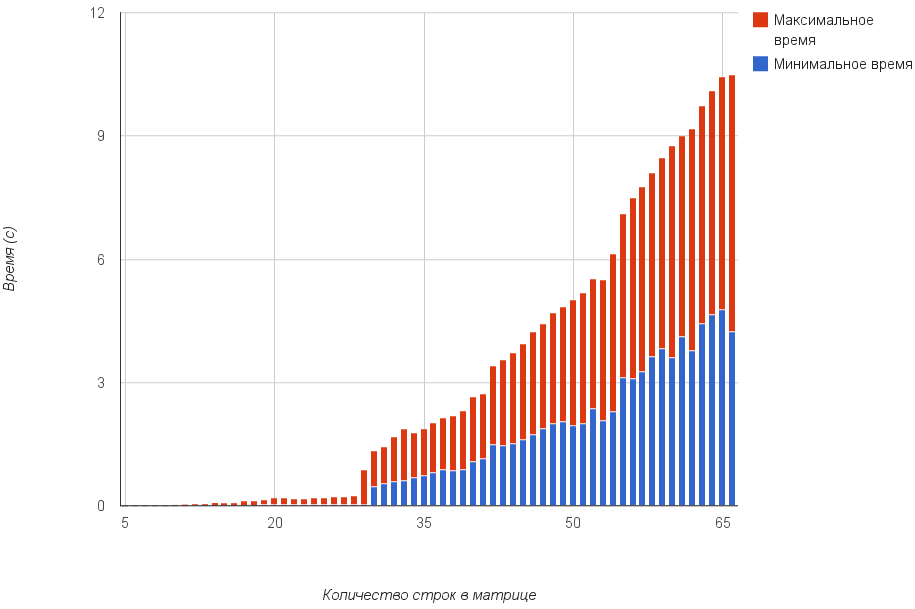
График максимального и минимального потраченного времени для матриц от 5х5 до 66х66.
Попробовать с подробным решением можно тут.
данные измерений были получены по 100 случайным матрицам. не слишком хорошее число, но общее представление обеспечивает.
Исходники на GitHub (обновлены).
Дальнейшие поиски в Интернете не принесли ожидаемого результата: либо сложное для не-математиков теоретическое описание, либо понятное, но с ошибками.
Под катом вас будет ждать исправленный алгоритм и онлайн-калькулятор.
Сам метод, опубликованный Литтлом, Мерти, Суини, Кэрелом в 1963 г. применим ко многим NP-полным задачам, и представляет собой очень теоритеризованный материал, который без хороших знаний английского языка и математики сразу не применишь к нашей задаче коммивояжера.
Кратко о методе — это полный перебор всех возможных вариантов с отсеиванием явно неоптимальных решений.
Исправленный алгоритм, для нахождения действительно минимального маршрута
1. Вычисляем наименьший элемент в каждой строке (константа приведения для строки)
2. Переходим к новой матрице затрат, вычитая из каждой строки ее константу приведения
3. Вычисляем наименьший элемент в каждом столбце (константа приведения для столбца)
4. Переходим к новой матрице затрат, вычитая из каждого столбца его константу приведения.
Как результат имеем матрицу затрат, в которой в каждой строчке и в каждом столбце имеется хотя бы один нулевой элемент.
5. Вычисляем границу на данном этапе как сумму констант приведения для столбцов и строк (данная граница будет являться стоимостью, меньше которой невозможно построить искомый маршрут)
1.Вычисление штрафа за неиспользование для каждого нулевого элемента приведенной матрицы затрат.
Штраф за неиспользование элемента с индексом (h,k) в матрице, означает, что это ребро не включается в наш маршрут, а значит минимальная стоимость «неиспользования» этого ребра равна сумме минимальных элементов в строке h и столбце k.
а) Ищем все нулевые элементы в приведенной матрице
б) Для каждого из них считаем его штраф за неиспользование.
в) Выбираем элемент, которому соответствует максимальный штраф (любой, если их несколько)
2. Теперь наше множество S разбиваем на множества — содержащие ребро с максимальным штрафом(Sw) и не содержащие это ребро(Sw/o).
3. Вычисление оценок затрат для маршрутов, входящих в каждое из этих множеств.
а) Для множества Sw/o все просто: раз мы не берем соответствующее ребро c максимальным штрафом(h,k), то для него оценка затрат равна оценки затрат множества S + штраф за неиспользование ребра (h,k)
б) При вычислении затрат для множества Sw примем во внимание, что раз ребро (h,k) входит в маршрут, то значит ребро (k,h) в маршрут входить не может, поэтому в матрице затрат пишем c(k,h)=infinity, а так как из пункта h мы «уже ушли», а в пункт k мы «уже пришли», то ни одно ребро, выходящее из h, и ни одно ребро, приходящее в k, уже использоваться не могут, поэтому вычеркиваем из матрицы затрат строку h и столбец k. После этого приводим матрицу, и тогда оценка затрат для Sw равна сумме оценки затрат для S и r(h,k), где r(h,k) — сумма констант приведения для измененной матрицы затрат.
4. Из всех неразбитых множеств выбирается то, которое имеет наименьшую оценку.
Так продолжаем, пока в матрице затрат не останется одна не вычеркнутая строка и один не вычеркнутый столбец.
Небольшая оптимизация — подключаем эвристику
Да, правда, почему бы нам не ввести эвристику? Ведь в алгоритме ветвей и границ мы фактически строим дерево, в узлах которого решаем брать ребро (h,k) или нет, и вешаем двух детей — Sw(h,k) и Sw/o(h,k). Но лучший вариант для следующей итерации выбираем только по оценке. Так давайте выбирать лучший не только по оценке, но и по глубине в дереве, т.к. чем глубже выбранный элемент, тем ближе он к концу подсчета. Тем самым мы сможем наконец дождаться ответа.
Алгоритм состоит из двух этапов:
Первый этап
Приведение матрицы затрат и вычисление нижней оценки стоимости маршрута r.
1. Вычисляем наименьший элемент в каждой строке (константа приведения для строки)
2. Переходим к новой матрице затрат, вычитая из каждой строки ее константу приведения
3. Вычисляем наименьший элемент в каждом столбце (константа приведения для столбца)
4. Переходим к новой матрице затрат, вычитая из каждого столбца его константу приведения.
Как результат имеем матрицу затрат, в которой в каждой строчке и в каждом столбце имеется хотя бы один нулевой элемент.
5. Вычисляем границу на данном этапе как сумму констант приведения для столбцов и строк (данная граница будет являться стоимостью, меньше которой невозможно построить искомый маршрут)
Второй (основной) этап
1.Вычисление штрафа за неиспользование для каждого нулевого элемента приведенной матрицы затрат.
Штраф за неиспользование элемента с индексом (h,k) в матрице, означает, что это ребро не включается в наш маршрут, а значит минимальная стоимость «неиспользования» этого ребра равна сумме минимальных элементов в строке h и столбце k.
а) Ищем все нулевые элементы в приведенной матрице
б) Для каждого из них считаем его штраф за неиспользование.
в) Выбираем элемент, которому соответствует максимальный штраф (любой, если их несколько)
2. Теперь наше множество S разбиваем на множества — содержащие ребро с максимальным штрафом(Sw) и не содержащие это ребро(Sw/o).
3. Вычисление оценок затрат для маршрутов, входящих в каждое из этих множеств.
а) Для множества Sw/o все просто: раз мы не берем соответствующее ребро c максимальным штрафом(h,k), то для него оценка затрат равна оценки затрат множества S + штраф за неиспользование ребра (h,k)
б) При вычислении затрат для множества Sw примем во внимание, что раз ребро (h,k) входит в маршрут, то значит ребро (k,h) в маршрут входить не может, поэтому в матрице затрат пишем c(k,h)=infinity, а так как из пункта h мы «уже ушли», а в пункт k мы «уже пришли», то ни одно ребро, выходящее из h, и ни одно ребро, приходящее в k, уже использоваться не могут, поэтому вычеркиваем из матрицы затрат строку h и столбец k. После этого приводим матрицу, и тогда оценка затрат для Sw равна сумме оценки затрат для S и r(h,k), где r(h,k) — сумма констант приведения для измененной матрицы затрат.
4. Из всех неразбитых множеств выбирается то, которое имеет наименьшую оценку.
Так продолжаем, пока в матрице затрат не останется одна не вычеркнутая строка и один не вычеркнутый столбец.
Небольшая оптимизация — подключаем эвристику
Да, правда, почему бы нам не ввести эвристику? Ведь в алгоритме ветвей и границ мы фактически строим дерево, в узлах которого решаем брать ребро (h,k) или нет, и вешаем двух детей — Sw(h,k) и Sw/o(h,k). Но лучший вариант для следующей итерации выбираем только по оценке. Так давайте выбирать лучший не только по оценке, но и по глубине в дереве, т.к. чем глубже выбранный элемент, тем ближе он к концу подсчета. Тем самым мы сможем наконец дождаться ответа.
Теперь, собственно, об ошибках в той публикации
Ошибка была одна единственная — следует выбирать для разбиения множество с минимальной границей из всех возможных путей, а не из двух полученных в результате последнего разбиения детей.
Доказательство
Вернемся к картинке в начале поста:
А вот решение с исправленным алгоритмом:
Ответ: путь:3=>4=>2=>1=>5=>3 длина: 41
Как видите, включая ребро 5:2 в решение будет ошибкой. Что и требовалось доказать
График сравнения метода ветвей и границ и потраченного времени для случайной таблицы от 5х5 до 10х10:
График максимального и минимального потраченного времени для матриц от 5х5 до 66х66.
Попробовать с подробным решением можно тут.
данные измерений были получены по 100 случайным матрицам. не слишком хорошее число, но общее представление обеспечивает.
Исходники на GitHub (обновлены).

