
К добавлению внешнего сервера рано или поздно приходит любой сложный проект. Причины, при этом, бывают совершенно различные. Одни, загружают дополнительные сведения из сети, другие, синхронизируют данные между клиентскими устройствами, третьи- переносят логику выполнения приложения на сторону сервера. Как правило, к последним относятся большинство «деловых» приложений. По мере отхода от парадигмы «песочницы», в которой все действия выполняются только в рамках исходной системы, логика выполнения процессов переплетается, сплетается, завязывается узлами настолько, что становится трудно понять, что является исходной точкой входа в процесс приложения. В этом момент, на первое место выходит уже не функциональные свойства самого приложения, а его архитектура, и, как следствие, возможности к масштабированию.
Заложенный фундамент позволяет либо создать величественный архитектурный ансамбль, либо «накурнож» — избушку на куриных ножках, которая рассыпается от одного толчка «доброго молодца» коих, за время своего существования повидала видимо — невидимо, потому что, глядя на множественные строительные дефекты заказчик склонен менять не исходный проект, а команду строителей.
Планирование — ключ к успеху проекта, но, именно на него выделяется заказчиком минимальный объем времени. Строительные паттерны — туз в рукаве разработчика, который покрывает неблагоприятные комбинации где время — оказывается решающим фактором. Взятые за основу работающие решения позволяют сделать быстрый старт, чтоб перейти к задачам, кажущиеся заказчику наиболее актуальными (как-то покраска дымоходной трубы, на еще не возведенной крыше).
В этой статье я постараюсь изложить принцип построение масштабируемой системы для мобильных устройств, покрывающей 90-95% клиент-серверных приложений, и обеспечивающей максимальное отдаление от сакраментального «накурножа».
Пока занимался доработкой данной статьи, на хабре вышла аналогичная статья (http://habrahabr.ru/company/redmadrobot/blog/246551/). Не со всеми акцентами автора я согласен, но в целом, мое видение не противоречит и не пересекается с материалом изложенным там. Читатель же, сможет определить, какой из подходов более гибкий, и более актуальный.
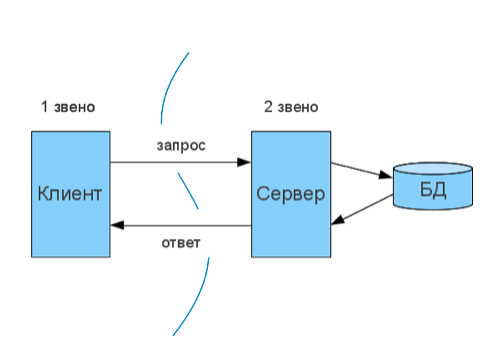
Общая структура клиент-серверного взаимодействия со стороны сервера представлена здесь: www.4stud.info/networking/lecture5.html Однако, нас больше интересует этот же взгляд со стороны клиента, и в этой связи, нет никакой разницы между двузвенной и трезвенной архитектурой:
Здесь важно понимание двух вещей:
- Может быть множество клиентов, использующих один аккаунт для общения с севером.
- Каждый клиент, как правило, имеет свое собственное локальное хранилище. *
*В ряде случаев, локальное хранилище может быть синхронизировано с облаком, и, соотвественно, с каждым из клиентов. Поскольку это частный случай и, по больше части, не влияющий на архитектуру приложения, мы его опускаем.
Следует отметить, что поскольку, некоторые разработчики стремятся избавится от «серверной части» некоторые приложения построены вокруг синхронизации их хранилищ в «облаке». Т. е. фактически, имеют так же, двузвенную систему, но с переносом архитектуры её развертывания на уровень операционной системы. В некоторых случаях такая структура оправдана, но такая система не так легко масштабируется, и её возможности весьма ограничены.
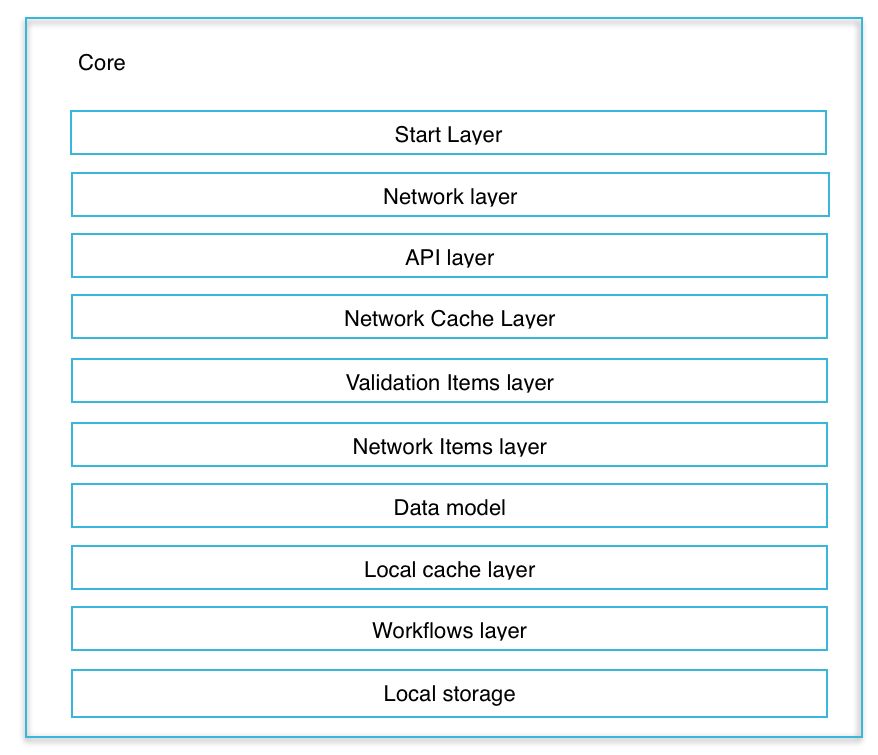
Общая структура приложения
На самом примитивном уровне абстракции приложение, ориентированное на работу с сервером состоит из следующих архитектурных слоев:
- Ядро приложения, которое включает в себя компоненты системы, не доступные для взаимодействия с пользователем.
- Графический пользователь интерфейс
- Компоненты повторного использования: библиотеки, визуальные компоненты и другое.
- Файлы окружения: AppDelegate, .plist и т. д.
- Ресурсы приложения: графические файлы, звуки, необходимые бинарные файлы.
Наиважнейшим условием построение стрессоустойчивой архитектуры является отделение ядра системы от GUI, настолько, что б одно, могло успешно функционировать без другого. Между тем, большинство RAD систем исходят из противоположного посыла — формочки образуют скелет системы, а функции наращивают ей мышцы. Как правило, это оборачивается тем, что не приложение становится ограниченным своим интерфейсом. И, интерфейс приобретает однозначное толкование как с точки зрения пользователя, так и с точки зрения иерархии классов.

Ядро
Ядро приложения, состоит из следующих слоев:
- (Start layer) Стартовый слой, определяющий рабочий процесс, начала исполнения программы.
- (Network layer) Сетевой слой, обеспечивающий механизм транспортного взаимодействия.
- (API layer) Слой API, обеспечивающий единую систему команд взаимодействия между клиентом и сервером.
- (Network Cache Layer) Слой сетевого кэширования, обеспечивающий ускорения сетевого взаимодействия клиента и сервера.
- (Validation Items Layer) Слой валидации данных полученных из сети
- (Network Items Layer) Слой сущности данных передаваемых по сети
- (Data Model) Модель данных, обеспечивающая взаимодействие сущностей данных.
- (Local cache layer) Слой локального кеширования, обеспечивающий локальный доступ к уже полученным сетевым ресурсам.
- (Workflow layer) Слой рабочих процессов, включающий классы и алгоритмы специфичные для данного приложения.
- (Local storage) Локальное хранилище
Одна из основных задач стоящие перед разработчиками системы заключается в том чтобы обеспечить взаимно независимое функционирование указанных слоев. Каждый слой должным обеспечивать только выполнение возложенных на него функций. Как правило, слой находящийся на более высоком уровне иерархии не должен иметь представление о специфике реализации других слоев.
Рассмотрим процесс решения задачи с токи зрения Junior и Senior разработчиков.
Задача: написать программу «калькулятор валют» которая получала бы данные из сети, и строила график изменения курсов.
Junior:
1) Исходя из постановки задачи, нам известно, что приложение будет состоять из следующих частей:
- Форма для математических операций (сложение, вычитание)
- Форма для отображения графика
- Дополнительные формы: сплеш-скрин, about.
2) Зависимость форм делаем следующей: форма вычислений является главной в нашем приложении. Она запускает из себя сплэш форму, которая скрывается через определенный промежуток времени, форму графиков и about по нажатию на определенную кнопку.
3) Время отображения сплешскрина — эквивалентно времени загрузки данных из сети.
4) Поскольку загрузка из сети выполняется только во время показа сплэш-формы, то код загрузки данных размещается внутри формы, а по завершению формы, удаляется из памяти вместе с формой.
Насколько работоспособное данное приложение? Думаю, что ни у кого нет сомнения, что используя Delphi или Visual Studio можно в момент решить эту задачу. Используя Xcode сделать это несколько сложнее, но тоже можно не сильно напрягаясь. Однако, вслед за появлением прототипа, начинают появляться вопросы масштабируемости. Становится очевидным, что для отображения графика необходимо хранить данные за предыдущий период. Не проблема, можно добавить хранилище данных внутрь формы графиков. Однако, данные могут приходить от разных провайдеров и в разных форматах. Кроме того, арифметические операции могут осуществляться с разными валютам, а значит, необходимо обеспечить их выбор. Делать такой выбор на форме графиков — несколько нелогично, хотя и возможно, однако, от таких настроек зависит что именно мы будем отображать на графике. Это означает, что если мы выносим дополнительные параметры в окно настроек, то нам придется как-то их передавать через главную форму в окно графиков. В этом случае логично будет сделать локальную переменную, в которой и хранить передаваемые параметры, и обеспечить доступ из одной форме к другой форме через главную форму. Ну и так далее. Цепочку рассуждений можно строить весьма долго, и сложность взаимодействий будет возрастать.
Senior:
Постановка задачи позволяет выделить несколько подзадач, которые могут быть описаны отдельными классами:
1) Загрузка данных из сети.
- Проверка полученных данных
- Сохранение данных в постоянном хранилище.
- Вычисление данных.
- операция сложения
- операция вычитания
- Фильтрация данных по указанным критериям (настройки приложения)
- Класс старта приложения.
2) Обеспечить связанную работу интерфейса, который состоит из следующих основных форм:
- Главный контроллер (может быть невидимым)
- Форма вычисления
- Форма графиков
- Сплеш и About
- Опционально форма настроек.
3) После запуска приложения на выполнения, производится создание (инстанциирование) объекта отвечающего за загрузку данных (в подавляющем большинстве случае асинхронную) и начинает процесс. Главный контроллер приложения отображает сплеш-скрин, и в это время, формирует форму, которая займет его место по сокрытию сплэш-формы.
4) По окончании загрузки данных, создается объект-валидатор и объект-провайдер локального хранилища. В случае если данные прошли необходимую валидацию, они могут быть переданы провайдеру локального хранилища.
5) Для отображения графика, создается объект локального хранилища и объект настроек данных. Настройки данных передаются в провайдер локального хранилища для извлечения данных с установленными фильтрами.
6) Для проведения вычислений создается объект-калькулятор, и объекты операций. В объект калькулятор передаются данные полученные с формы, и один из двух объектов операций, которы знают как именно осуществить вычисления.
Конечно, данный подход требует больше усилий по программированию, и соотвественно, изначально предполагает больше времени. Однако, исходя из подзадач ясно, что во-первых, работу над ним легко распараллелить — в то время как один разработчик занят формированием ядра — другой, создает и отлаживает UI. Ядро может благополучно работать в рамках консоли, UI прощелкиваться в девайсе и, ко всему прочему, к обеим частям можно прикрутить независимые юнит-тесты. Другим несомненным достоинством является то, что второй подход значительно более масштабируем. В случае пересмотра функциональности проекта, любые изменения будут вносится многократно быстрее, потому что попросту не существует ограничительных рамок визуальных представлений. Сами визуальные формы (GUI) отображают необходимый минимум основанный на существующих в ядре задачах.
Start layer:
В iOS приложение начинает функционирование с запуска объекта делегатного класса. Его назаначение — принять и передать вызовы системы приложению, а так же, осуществить первоначальную конфигурацию GUI приложения. Все алгоритмы и механизмы, которые не относятся к старту приложения, или получения сообщений от системы должны быть вынесены в отдельные классы. Сразу после завершения первоначальной конфигурации управление должно быть передано классу, который осуществляет остальные операции настройки приложения: авторизацию, реконфигурирование интерфейса в зависимости от условий, первоначальную загрузку данных, получения необходимых токенов и так далее. Типичной ошибкой разработчиков является монстроузный спегетти-код размещенный в AppDelegate. Оно и понятно- практически все примеры внешних фреймворков для простоты понимания именно здесь располагают свой код. Незадачливые программисты не тратят время на рефакторинг, и просто копируют «как там». Ситуация совершенно типичная для тех, кто использует встроенный шаблон создания CoreData.
Часто там можно увидеть реализацию следующих функций:
- Настройка и обслуживание сессий Facebook
- Настройка менеджера вкладок если приложение поддерживает UITabbarController.
- Очистка CoreData и сохранение данных при входе в Background.
- Проверка и инициализация обновлений
- Уведомление внешних серверов статистики
- Синхронизация Модели данных
Network Layer:
Обеспечивает базовые алгоритмы транспортного уровня передачи сообщений от клиента к серверу, и получению от него необходимой информации. Как правило, сообщения могут передаваться в форматах JSON и Multipart, хотя, в некоторых экзотических случаях это может быть XML или вообще бинарный поток. Кроме того, каждое сообщение может иметь заголовок со служебной информацией. Например, там может быть описана длительность хранения запроса / ответа в кеше приложения.
Network Layer не имеет никакого представления об используемых приложением серверах, или о его системе команд. Обработка ошибок сетевого соединения осуществляется виртуальными методами на следующих уровнях приложения. Задача этого слоя только осуществить вызов метода обработки и передать в него полученную из сети информацию.
Кроме того, перед непосредственным запросом информации из сети, network layer опрашивает локальный кеш, и в случае присутствия там ответа сразу же возвращает его пользователю.
Содержание этого слоя во многом зависит от того, какая технология транспорта Вам наиболее близка. В арсенале разработчика наиболее востребованы следующие варианты:
- Socket — наиболее низкоуровневый подход, включающий в себя синхронные и асинхронные запросы, и имеющий возможность работать как с TCP так и с UDP подключениями. Позволяет делать практически все что угодно, но требует высокой степени концентрации на задаче, не дюжей усидчивости, и большого объема кода.
- WebSocket — подход опирающийся на использование заголовков поверх TCP. Подробности можно прочесть здесь: habrahabr.ru/post/79038 При мобильной разработке применяется не часто, так как недостаточно гибок, и по прежнему требует довольно большого количества кода для своей поддержки.
- WCF — наверное самый совершенный механизм, но имеющий столь серьезный минус, который перевешивает все плюсы. Подход изобретенный в недрах Microsoft опирается на создании прокси-класса, который опосредует взаимоотношение между логикой приложения, и удаленным севером. Работает «на ура» в том случае, если удается сгенерировать прокси класс на основе WSDL схем ( en.wikipedia.org/wiki/Web_Services_Description_Language ), что, является задачей, мягко говоря, не тривиальной. К тому же этот класс необходимо перегенерировать после каждого обновления серверного API. И если для разработчиков Visual Studio это делается с легкостью Зефира, то для разработчиков iOS — задача совершенно неподъемная, даже тех кто использует MonoTouch в разработке.
- REST — надежный, проверенный временем компромис всех перечисленных выше подходов ( ru.wikipedia.org/wiki/REST). Конечно, от части возможностей каждого из подхода приходится отказываться, зато делается это быстро, и чрезвычайно эффективно с минимумом усилий.
GitHub содержит множество библиотек, позволяющих использовать REST соединения, для iOS, наиболее востребованной является AFNetworking.
REST опирается на использование GET, POST, PUT, HEAD, PATCH и DELETE запросов. Такой зоопарк называют RESTFul ( habrahabr.ru/post/144011 ) и, как правило, он применяется только тогда, когда пишется универсальный API для работы мобильных приложений, веб-сайтов, десктопов и космических станций в одной связке.
Подавляющее большинство приложений ограничивает систему команд двумя типами, GET и POST, хотя, достаточно только одного — POST.
GET запрос передается в виде строки, которую Вы используете в браузере, а параметры для запроса передаются разделенные знаками ‘&’. POST запрос так же использует «браузерную строку» но, параметры скрывает внутри невидимого тела сообщения. Последние два утверждения повергают в уныние тех, кто с запросами ранее не сталкивался, в действительности же, технология отработана настолько, что она совершенно прозрачна для разработчика, и не приходится вникать в такие нюансы.
Выше, было описано что отправляется серверу. А вот то, что приходит от сервера — куда интересней. Если Вы используете AFNetworking, то со стороны сервера Вы получите Как правило, iOS разработчики называют JSON- оном сериализированный словарь, но это не совсем так. Истинный JSON имеет чуть более сложный формат, но в чистом виде им практически никогда пользоваться не приходится. Однако, о том, что имеется отличие знать нужно — бывают нюансы.
Если Вы работаете с сервисом, установленным на Microsoft Windows Server, то вероятнее всего, там будет использован WCF. Однако, начиная с Windows Framework 4, имеется возможность для клиентов поддерживающих только REST протокол, сделать доступ совершенно прозрачно, декларативным образом. Вы даже сможете не тратить время на получении пояснений об API — документация о системе команд генерируется автоматически IIS (майкрософтовским веб-сервером).
Ниже приводится минимальный код, для реализации Network Layer при помощи AFNetworking 2 на Objective-C.
Листинг 1
ClientBase.h
ClientBase.m
#import "AFHTTPRequestOperationManager.h" NS_ENUM(NSInteger, REQUEST_METHOD) { GET, HEAD, POST, PUT, PATCH, DELETE }; @interface ClientBase : AFHTTPRequestOperationManager @property (nonatomic, strong) NSString *shortEndpoint; - (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail; @end
ClientBase.m
#import "ClientBase.h" @implementation ClientBase - (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail { self.requestSerializer = [AFJSONRequestSerializer serializer]; if(data == nil) data = @{}; AFHTTPRequestOperation *operation = [self requestWithMethod:method path:endpoint parameters:data success:success fail:fail]; [operation start]; } - (AFHTTPRequestOperation *)requestWithMethod:(enum REQUEST_METHOD)method path:endpoint parameters:data success:(void(^)(id response))success fail:(void(^)(id response))fail{ switch (method) { case GET: return [self requestGETMethod:data andEndpoint:endpoint success:success fail:fail]; case POST: return [self requestPOSTMethod:data andEndpoint:endpoint success:success fail:fail]; default: return nil; } } - (AFHTTPRequestOperation *)requestGETMethod:(NSDictionary *)data andEndpoint:(NSString *)endpoint success:(void(^)(id response))success fail:(void(^)(id response))fail { return [self GET:endpoint parameters:data success:^(AFHTTPRequestOperation *operation, id responseObject) { [self callingSuccesses:GET withResponse:responseObject endpoint:endpoint data:data success:success fail:fail]; [KNZHttpCache cacheResponse:responseObject httpResponse:operation.response]; } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"\n\n--- ERROR: %@", operation); NSLog(@"\n--- DATA: %@", data); [self callingFail:fail error:error]; }]; } - (AFHTTPRequestOperation *)requestPOSTMethod:(NSDictionary *)data andEndpoint:(NSString *)endpoint success:(void(^)(id response))success fail:(void(^)(id response))fail { return [self POST:endpoint parameters:data success:^(AFHTTPRequestOperation *operation, id responseObject) { [self callingSuccesses:POST withResponse:responseObject endpoint:endpoint data:data success:success fail:fail]; } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"\n\n--- ERROR: %@", operation); NSLog(@"\n--- DATA: %@", data); [self callingFail:fail error:error]; }]; } - (void)callingSuccesses:(enum REQUEST_METHOD)requestMethod withResponse:(id)responseObject endpoint:(NSString *)endpoint data:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { if(success!=nil) success(responseObject); } - (void)callingFail:(void(^)(id response))fail error:(NSError *)error { if(fail!=nil) fail(error); } @end
Этого вполне достаточно чтоб передавать сетевые GET и POST сообщения. В большинстве своем, Вам не потребуется больше корректировать эти файлы.
API Layer:
Описывает команды REST и осуществляет выбор хоста. API Layer полностью отделен от знания реализации сетевых протоколов и любых других особенностей функционирования приложения. Технически, он может быть полностью заменен, без каких-либо изменений в остальных частях приложения.
Класс унаследован от ClientBase. Код класса настолько просто, что нет необходимость даже приводить его целиком — он состоит их единообразного описания API:
Листинг 2
#define LOGIN_FACEBOOK_ENDPOINT @"/api/v1/member/login/facebook/" #define LOGIN_EMAIL_ENDPOINT @"/api/v1/member/login/email/" - (void)loginFacebook:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { [self request:data andEndpoint:LOGIN_FACEBOOK_ENDPOINT andMethod:POST success:success fail:fail]; } - (void)loginEmail:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { [self request:data andEndpoint:LOGIN_EMAIL_ENDPOINT andMethod:POST success:success fail:fail]; }
Как говорится: «Ничего лишнего».
Network Cache Layer:
Данный слой кеширования задействуется для ускорения сетевого обмена между клиентом и сервером на уровне iOS SDK. Выбор ответов осуществляется стороной лежащей за пределами контроля системы, и не гарантирует снижение сетевого трафика, но ускоряет его. Доступа к данным или механизмам реализации нет ни со стороны приложения, ни со стороны системы. При этом используется SQLite хранилище.
Код необходимый для этого слишком прост, чтоб не использовать его в любом проекте, который имеет доступ к сети:
Листинг 3
#define memoCache 4 * 1024 * 1024 #define diskCache 20 * 1024 * 1024 #define DISK_CACHES_FILEPATH @"%@/Library/Caches/httpCache" - (void)start { NSURLCache *URLCache = [[NSURLCache alloc] initWithMemoryCapacity:memoCache diskCapacity:diskCache diskPath:nil]; [NSURLCache setSharedURLCache:URLCache]; }
Вызвать нужно из любого места приложения однократно. Например из стартового слоя.
Validation Items layer:
Формат получаемых данных из сети в большей степени зависит от разработчиков сервера. Приложение физически не может контролировать использование изначально заданного формата. Для сложно-структурированных данных, коррекция ошибок сравнима по сложности с разработкой самого приложения. Наличие ошибок, в свою очередь, чревато крешем приложения. Использование механизма валидации данных существенно снижает угрозу некорректного поведения. Слой валидации состоит из схем JSON для большинства запросов к серверу, и класса, который осуществляет проверку полученных данных на соответствие загруженной схемы. Если полученный пакет не соотвествует схеме, он отклоняется приложением. Вызывающий код получит уведомление об ошибке. Аналогичное уведомление будет записано в лог консоли. Кроме того, может быть вызвана вызвана команда сервера для передачи на сторону сервера отчета, о возникшей ошибке. Главное, предусмотреть выход из рекурсии, если команда отправки такого сообщения тоже вызывает какую-нибудь ошибку (4xx или 5xx).
Имеет смысл на сервер отправлять следующие данные:
- Для какого аккаунта произошла ошибка.
- Какая команда вызвала ошибку.
- Какие данные были переданы серверу.
- Какой ответ был получен от сервера.
- Время UTC*
- Статус код команды. Для ошибок валидации он всегда 200.
- Схема, которой не удовлетворяет ответ сервера.
*Время UTC — это время, когда команды была вызвана, а не когда ответ был возвращен серверу. Как правило, они совпадают, но поскольку у приложения может имеется механизм очереди запросов, то теоретически, между вызовом сбойной команды, и регистрацией записи сервером могут проходить месяцы.
Предполагается, что схемы JSON запросов предоставляют серверные разработчики после реализации новых команд API.
Каждая схема, как и каждая команда, обязана удовлетворять определенным оговоренным ранее критериям. В приведенном примере ответ сервера должен содержать два основных и одно опциональное поле.
«status» обязательное. Содержит идентификатор OK или ERROR (или код HTTP типа «200»).
«reason» обязательное Содержит текстовое описание причины ошибки, если она возникла. В противном случае — это поле пустое.
«data» опциональное. Содержит результат выполнения команды. В случае ошибки отсутствует.
Пример схемы:
Листинг 4
{ "title": "updateconfig", "description": "/api/v1/member/updateconfig/", "type":"object", "properties": { "reason": { "type":"string", "required": true }, "status": { "type":"string", "required": true }, "data": { "type":"object" } }, "required": ["reason", "status"] }
Благодаря библиотеке разработанной Максимом Луниным сделать это стало очень просто. ( habrahabr.ru/post/180923 )
Код класса валидации приводится ниже
Листинг 5
ResponseValidator.h
#import "ResponseValidator.h" #import "SVJsonSchema.h" @implementation ResponseValidator + (instancetype)sharedInstance { static ResponseValidator *sharedInstance; static dispatch_once_t onceToken; dispatch_once(&onceToken, ^{ sharedInstance = [[ResponseValidator alloc] init]; }); return sharedInstance; } #pragma mark - Methods of class + (void)validate:(id)response endpoint:(NSString *)endpoint success:(void(^)())success fail:(void(^)(NSString *error))fail { [[м sharedInstance] validate:response endpoint:endpoint success:success fail:fail]; } + (NSDictionary *)schemeForEndpoint:(NSString *)endpoint { NSString *cmd = [[ResponseValidator sharedInstance] extractCommand:endpoint]; return [[ResponseValidator sharedInstance] validatorByName:cmd]; } #pragma mark - Methods of instance - (void)validate:(id)response endpoint:(NSString *)endpoint success:(void(^)())success fail:(void(^)(NSString *error))fail { NSString *cmd = [self extractCommand:endpoint]; NSDictionary *schema = [self validatorByName:cmd]; SVType *validator = [SVType schemaWithDictionary:schema]; NSError *error; [validator validateJson:response error:&error]; if(error==nil) { if(success!=nil) success(); } else { NSString *result = [NSString stringWithFormat:@"%@ : %@", cmd, error.description]; if(fail!=nil) fail(result); } } - (NSString *)extractCommand:(NSString *)endpoint { NSString *cmd = [endpoint.stringByDeletingLastPathComponent lastPathComponent]; return cmd; } - (NSDictionary *)validatorByName:(NSString *)name { static NSString *ext = @"json"; NSString *filePath = [[NSBundle mainBundle] pathForResource:name ofType:ext]; NSString *schema = [NSString stringWithContentsOfFile:filePath encoding:NSUTF8StringEncoding error:nil]; if(schema == nil) return nil; NSData *data = [schema dataUsingEncoding:NSUTF8StringEncoding]; NSError *error; NSDictionary *result = [NSJSONSerialization JSONObjectWithData:data options:0 error:&error]; return result; } @end
Вызов валидации довольно прост:
Листинг 6
[ResponseValidator validate:responseObject endpoint:endpoint success:^{ /* Валидация прошла успешно, вызываем конвейер обработки команды */ } fail:^(NSString *error) { /* Валидация провалена. Можем что-то сделать, а можем просто игнорировать результат. Зависит от религиозных предпочтений. */ }];
Network Items layer:
Именно на этот слое лежит ответственность за маппинг данных из JSON в десериализированное представление. Данный слой используется для описания классов, осуществляющих объектное или объектно-реляционное преобразование. В сети существует большое количество библиотек, осуществляющих объектно-релационные преобразования. Например JSON Model ( github.com/icanzilb/JSONModel ) или все та же библиотека Максима Лунина. Однако, не все так радужно. От проблем маппинга они не избавляют.
Поясним что такое маппинг:
Предположим существуют два запроса, которые возвращают одинаковые по структуре данные. Например, пользователей приложения и друзей пользователя, которые обладают таким полями как «идентификатор» и «имя пользователя». Беда в том, что серверные разработчики в одном запросе могут передвать поля: «id», «username», а во втором «ident», «user_name». Такое разночтение может иметь целый набор неприятностей:
- Десериализированный объект данных в Objective-C не может иметь поля «id» при использовании CoreData
- Сериализированные данные в поле «id» и «ident» могут содержать как строку, так и NSNumber. При выводе их на консоль, разницы между двумя числами не будет, но. хешкод у них будет разный, и словарь будет по разному воспринимать значение этих полей.
- Отличия между именами полей являются ответственностью сервера, и серверные разработчики могут просто не идти на контакт, в том, чтоб заменить их имена на единообразные, удобные клиентским разработчикам.
Универсального решения этих проблем нет, но они не настолько сложны, чтоб это требовало значительных интеллектуальных усилий.
Local cache layer:
К задачам данного слоя относятся:
- Кеширование загружаемых из сети изображений.
- Кеширование запросов / ответов сервера
- Формирование очереди запросов в случае отсутствия сети и работы пользователя оффлан.
- Мониторинг кешированных данных и очистка данных, срок жизни которых истек.
- Уведомление приложения о невозможности получить информацию о заданном объекте из сети.
Вообще, этот слой — тема отдельной большой статьи. Но есть определенное количество нюансов, которые следует учитывать разработчикам.
Для кеширования запросов можно немного модернизировать процедуры из листинга 1. Я настоятельно рекомендую использовать виртуальные методы для этого, но, для простоты будет продемонстрирован непосредственный вызов метода класса:
Листинг 7
- (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail queueAvailable:(BOOL)queueAvailable { self.requestSerializer = [AFJSONRequestSerializer serializer]; if(data == nil) data = @{}; // Returning cache response. NSDictionary *cachedResponse = [HttpCache request:endpoint]; if(cachedResponse !=nil) { [self callingSuccesses:method withResponse:cachedResponse endpoint:endpoint data:data success:success fail:fail]; return; } AFHTTPRequestOperation *operation = [self requestWithMethod:method path:endpoint parameters:data success:success fail:fail]; [self consoleLogRequest:data operation:operation]; [operation start]; } - (AFHTTPRequestOperation *)requestPOSTMethod:(NSDictionary *)data andEndpoint:(NSString *)endpoint success:(void(^)(id response))success fail:(void(^)(id response))fail { return [self POST:endpoint parameters:data success:^(AFHTTPRequestOperation *operation, id responseObject) { [self callingSuccesses:POST withResponse:responseObject endpoint:endpoint data:data success:success fail:fail]; [HttpCache cacheResponse:responseObject httpResponse:operation.response]; } failure:^(AFHTTPRequestOperation *operation, NSError *error) { NSLog(@"\n\n--- ERROR: %@", operation); NSLog(@"\n--- DATA: %@", data); [self callingFail:fail error:error]; }]; }
В классе HttpCache по-мимо методов сохранения результатов запроса имеется еще один, интересный метод:
Листинг 8
#define CacheControlParam @"Cache-Control" #define kMaxAge @"max-age=" - (NSInteger)timeLife:(NSHTTPURLResponse *)httpResponse { NSString *cacheControl = httpResponse.allHeaderFields[CacheControlParam]; if(cacheControl.length > 0) { NSRange range = [cacheControl rangeOfString:kMaxAge]; if(range.location!=NSNotFound) { cacheControl = [cacheControl substringFromIndex:range.location + range.length]; return cacheControl.integerValue; } } return 0; }
Он позволяет извлечь из заголовка ответа сервера ключевую информацию о том через сколько секунд истечет время жизни полученного пакета (дата проэкспарится). Используя эту информацию можно записать данные в локальное хранилище, и при повторном аналогичном запросе просто прочесть ранее полученные данные. Если же метод возвращает 0, то такие данные можно не записывать.
Таким образом, на сервере можно регулировать что именно должно быть кешировано на клиенте. Стоит отметить, что используются стандартные поля заголовка. Так что, в плане стандарта велосипед не изобретается.
Путем еще одной небольшой модификации листинга 1 легко решается вопрос с очередями:
Листинг 9
- (void)request:(NSDictionary *)data andEndpoint:(NSString *)endpoint andMethod:(enum REQUEST_METHOD)method success:(void(^)(id response))success fail:(void(^)(id response))fail queueAvailable:(BOOL)queueAvailable { self.requestSerializer = [AFJSONRequestSerializer serializer]; if(data == nil) data = @{}; if(queueAvailable) { [HttpQueue request:data endpoint:endpoint method:method]; } AFHTTPRequestOperation *operation = [self requestWithMethod:method path:endpoint parameters:data success:success fail:fail]; [operation start]; }
Класс HttpQueue проверяет, имеется ли в настоящее время подключение к сети и если оно отсутствует, записывает запрос в хранилище с указанием времени производимого запроса с точностью до миллисекунд. Когда же подключение возобновляется, производится вычитывание данных из хранилища и передачи из на сервер, с одновременной очисткой очереди запросов. Это дает возможность обеспечить определенную клиент-серверную работу без непосредственного подключения к сети.
Проверка подключения к сети осуществляется с помощью классов AFNetworkReachabilityManager или Reachability от Apple ( developer.apple.com/library/ios/samplecode/Reachability/Introduction/Intro.html ) совместно с паттерном наблюдатель. Его устройство слишком примитивно, чтоб описывать в рамках статьи.
Однако, не все запросы должны быть отправлены в очередь. Некоторые из них могут не быть актуальными к моменту появления сети. Решить какие из команд дожны быть записаны в кеш очереди, а каки быть актуальны толко в момент вызова можно как на уровне слоя кеширования, так и на уровне слоя API.
В первом случае, в листинг 9, вместо вызова метода сохранения в очередь, необходимо вставить виртуальный метод, и унаследовать от класса ApiLayer унаследовать классы LocalCacheLayerWithQueue и LocalCacheLayerWithoutQueue. После чего в заданном виртуальном методе класса LocalCacheLayerWithQueue сделать вызов [HttpQueue request: endpoint: method:]
Во втором случае немного изменится вызов запроса из класса ApiLayer
Листинг 10
- (void)trackNotification:(NSDictionary *)data success:(void(^)(id response))success fail:(void(^)(id response))fail { [self request:data andEndpoint:TRACKNOTIFICATION_ENDPOINT andMethod:POST success:success fail:fail queueAvailable:YES]; }
В листинге 9 именно для такого случая предусмотрено условие if(queueAvailable).
Так же, отдельным вопросом является вопрос кеширования изображений. В общем-то, вопрос не сложный, и оттого, имеющий бесконечное количество реализаций. К примеру, библиотека SDWebImage делает это весьма успешно: ( github.com/rs/SDWebImage ).
Между тем, есть некоторые вещи, которые она делать не умеет. Например, она не может очищать кеш изображений по заданным критериям (количество изображений, дата их создания и т. д.), логгирование или коррекцию специфических ошибок т. е. разработчику приходится все равно изобретать свои велосипеды для кеширования.
Приведу пример асинхронной загрузки изображения из сети, с коррекцией ошибки MIME (к примеру, Amazon часто отдает неправильный MIME type, в результате чего, их же веб-сервер отправляет изображение, не как двоичный файл с картинкой, а как поток данных).
Листинг 11
#define LOCAL_CACHES_IMAGES_FILEPATH @"%@/Library/Caches/picture%ld.jpg" - (void)loadImage:(NSString*)link success:(void(^)(UIImage *image))success fail:(void(^)(NSError *error))fail { UIImage *image = [ImagesCache imageFromCache:link.hash]; if(image == nil) { dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ __block NSData *data; __block UIImage *remoteImage; __block NSData *dataImage; __block NSString *imgFilePath = [NSString stringWithFormat:LOCAL_CACHES_IMAGES_FILEPATH, NSHomeDirectory(), (unsigned long)link.hash]; data = [NSData dataWithContentsOfURL: [NSURL URLWithString:link]]; // Reading DATA if(data.length > 0) { remoteImage = [[UIImage alloc] initWithData: data]; // TRANSFORM DATA TO IMAGE if(remoteImage!=nil) { dataImage = [NSData dataWithData:UIImageJPEGRepresentation(remoteImage, 1.0)]; // TRANSFORM IMAGE TO JPEG DATA if(dataImage!=nil && dataImage.length > 0) [dataImage writeToFile:imgFilePath atomically:YES]; // Writing JPEG file } else // try to fix BINARY image type (first method) { [dataImage writeToFile:imgFilePath atomically:YES]; remoteImage = [UIImage imageWithContentsOfFile:imgFilePath]; } } else // try to fix BINARY image type (second method) { NSURLRequest *urlRequest = [NSURLRequest requestWithURL:[NSURL URLWithString:link]]; NSURLResponse *response = nil; NSError *error = nil; data = [NSURLConnection sendSynchronousRequest:urlRequest returningResponse:&response error:&error]; if (error == nil) { remoteImage = [[UIImage alloc] initWithData: data]; // TRANSFORM DATA TO IMAGE if(remoteImage!=nil) { dataImage = [NSData dataWithData:UIImageJPEGRepresentation(remoteImage, 1.0)]; // TRANSFORM IMAGE TO JPEG DATA if(dataImage!=nil && dataImage.length > 0) [dataImage writeToFile:imgFilePath atomically:YES]; // Writing JPEG file } NSLog(@"USED SECONDARY METHOD FOR LOAD OF IMAGE"); } else NSLog(@"DATA WASN'T LOAD %@\nLINK %@", error, link); } dispatch_async(dispatch_get_main_queue(), ^{ if(remoteImage!=nil && success!=nil) { success(remoteImage); [ImagesCache update:link.hash]; } else { if(data.length == 0) NSLog(@"%@", @"\n============================\nDETECTED ERRROR OF DOWNLOAD IMAGE\nFILE CAN'T LOAD\nUSED PLACEHOLDER\n============================\n"); else NSLog(@"%@", @"\n============================\nDETECTED ERRROR OF DOWNLOAD IMAGE\nUSED PLACEHOLDER\n============================\n"); NSLog(@"LINK %@", link); UIImage *placeholder = [LoadImage userPlaceholder]; if (success) success(placeholder); // if(fail!=nil) // fail([NSError errorWithDomain:[NSString stringWithFormat:@"%@ not accessible", link] code:-1 userInfo:nil]); } }); }); } else { success(image); } }
Метод может казаться весьма избыточным, но легко модифицируемым к конкретным нуждам разработчика. Из важных моментов следует отметить то, что в качестве ключа для кеширования используется хеш URL изображения. Практически невозможно чтоб при таком подходе случилась коллизия в рамках файловой системы устройства.
При каждом чтении файла из кеша, у него модифицируется дата доступа. Файлы которые не перечитываются долгое время можно спокойно удалить еще на старте приложения.
Когда речи идет о чтении файла из бандла приложения, имеется нюанс, который забывают разработчики: iOS SDK предоставляет нам такие методы как [UIImage imageNamed:] и [UIImage imageWithContentsOfFile:]. Использовать первый проще, но он существенно влияет на загруженность памяти — дело в том, что файл загруженный при помощи него, остается в памяти устройства, до тех пор, пока приложение не будет завершено. Если это файл, который имеет большой объем, то это может стать проблемой. Рекомендуется использовать второй метод, как можно чаще. Кроме того, полезно сделать небольшое усовершенствование в метод загрузки:
Листинг 12
+ (UIImage *)fromBundlePng:(NSString *)name { return [[LoadImage sharedInstance] fromBundlePng:name]; } - (UIImage *)fromBundle:(NSString *)name { return [self downloadFromBundle:name.stringByDeletingPathExtension ext:name.pathExtension]; } - (UIImage *)downloadFromBundle:(NSString *)name ext:(NSString *)ext { NSString *filePath = [[NSBundle mainBundle] pathForResource:name ofType:ext]; if(filePath == nil) { NSString *filename = [NSString stringWithFormat:@"%@@2x", name]; filePath = [[NSBundle mainBundle] pathForResource:filename ofType:ext]; } return [UIImage imageWithContentsOfFile:filePath]; }
Теперь Вам не придется задаваться вопросом, в какой резолюции присутствует файл.
Workflows layer:
Все реализованные алгоритмы, которые не относятся к слоям ядра, и не представляют собой GUI должны быть вынесены в классы специфических последовательностей рабочих процессов. Каждый из этих процессов оформляется в своем стиле, и подключается к основной части приложения путем добавления ссылок на экземпляр соответствующего класса в GUI. В подавляющем большинстве случаев, все эти процессы являются не визуальными. Однако имеются некоторые исключения, например, когда необходимо осуществить длинную последовательность предопределенных кадров анимации, с заданными алгоритмами отображения
Вызывающий код должен иметь минимальные знания об этой функциональности. Все настройки flow должны быть инакапсулированы. Google в качестве примера приводит код для уведомления из сервера аналитики, и предлагает включить его в место, где событие возникает.
Листинг 13
// Analytics [Analytics passedEvent:ANALYTICS_EVENT_PEOPLE_SELECT ForCategory:ANALYTICS_CATEGORY_PEOPLE WithProperties:nil];
Очевидно, что если возникнет необходимость в оповещении другого сервера, рядом с этим кодом необходимо будет добавить еще такой же код со своими настройками. Такой подход не оправдан и недопустим. Вместо этого, необходимо создать класс, который имеет метод класса, для вызова аналитических серверов с заданной функциональностью.
Существуют довольно развитые рабочие процессы, логика функционирования которых зависит от внутренного состояния. Такие процессы должны быть реализованы при помощи паттернов «Стратегия» или «Машина состояний». Как правило, совместно с паттерном «стратегия» используется паттерн «медиатор» который опосредует обращение к тому или иному алгоритму.
Один из часто используемых процессов — процесс авторизации пользователя — очевидный претендент на рефаторинг с использованием паттерна «машины состояний». При этом, именно на этом flow должна лежать ответственность за «автоматическую» авторизацию пользователя, а не рекурсивным образом вызываться из абстрактных слоев (Network Layer, или Validation Items).
Каждый вызов слоев ядра сопровождается передачей объекта обратного вызова (callback), и именно через него должно быть возвращено управление в приложение при успешном выполнении команды или возникновения ошибок. Ни в коем случае не должен допускаться неявный вызов слоев ядра, объектами рабочей последовательности.
Так же, ни в коем случае нельзя допускать, чтоб какие-либо универсальные визуальные контролы зависели бы от состояния рабочих последовательностей. Если это критически необходимо, такие контролы должны быть приватизированы последовательностью. Доступ к состоянию контролов может осуществляться через свойства самих контролов, наследование и переопределение методов, и, в крайнем случае, через реализацию делегатных методов и путем создания категорий. Ключевым в этом витиеватом посыле есть то, что категории — это зло, которого следует избегать. Т. е. я не предлагаю отказываться от категорий, но при прочих равных условиях, код без них легче читается и несомненно более предсказуемый.
Local storage:
Желание разработчиков находится в тренде новых технологий, порой, сталкивается со здравым смыслом, и, последний часто проигрывает. Одно из веяний моды было использование локального хранилища на основе CoreData. Некоторые разработчики настаивали, что его нужно использовать в как можно большем количестве проектов, не смотря на то, что даже сама Apple признавала, что есть определенные трудности.
Существует большое количество способов сохранение временных данных в постоянном хранилище устройства. Использование CoreData оправдано в том случае, когда нам необходимо хранить большое количество редко обновляемых данных. Однако, если в приложении имеется несколько сот записей, и ни постоянно обновляются скопом использование CoreData в этих целях неоправданно дорого. Таким образом, получается, что большую часть времени ресурсов устройство тратит на синхронизацию данных полученных из сети, с теми данными которые уже есть на устройстве, несмотря на то, что весь массив данных, будет обновлён во время следущей сессии.
Использование CoreData ( habrahabr.ru/post/191334 ), кроме того, требует также соблюдение определённых процедур, алгоритмов и архитектурных решений, что ограничивает нас в выборе стратегии разработки, а так же существенно осложняет механизмы отладки нашего приложения.
Как правило использования постоянных хранилищ призвана обеспечить существенное снижение сетевого трафика, за счёт использования уже полученной из сети информации. Однако, в некоторых случаях это не происходит поскольку источником этой информации является сервер, который и принимают решения относительно актуальности данной информации.
Локальное хранилище на основе файловой системы
Использование NSDictionary к качестве формата полученных данных позволяет автоматически решить еще целый ряд архитектурных проблем:
- данные в массивах могут быть представлены точно в той последовательности, в которой они были получены от сервера.
- данные однозначно соответствуют используемому запросу к серверу, с точностью до передаваемых параметров в POST запросе (т. е. легко было отличить объекты полученный от определенной команды, от объекта полученного от той же команды, но с другими данными, переданными в качестве параметров POST пост запроса).
- Атомарность записи объекта данных в постоянное хранилище.
- Мгновенность и атомарность чтение данных из постоянного хранилища.
- Полное соответствие ACID транзактности: en.wikipedia.org/wiki/ACID
- Отсутствие необходимости в нормализации данных.
- Независимость в интерпретации данных.
- Все данные всегда актуальны.
- Объем кода поддержки минимален (1 строка).
Средства чтения / записи iOS SDK делает NSDictionary идеальным форматом сохранения относительно небольших короткоживущих данных, поскольку для этого применяются однопроходные алгоритмы.
Для чтения сериализированных сохраненных данных нет необходимости в том, чтоб задействовать дополнительную логику. Возврат данных может осуществляться той же командой, которая читает данные из сети.
Отрицательной стороной такого подхода считается, что это плохо влияет на производительность устройства, однако, изучение вопроса показывает, что объем таких данных не превышает 5Кбайт, данные загружаются в память мгновенно, единым блоком, и таким же образом освобождаются из памяти, сразу же после того, как в них отпадает необходимость, например, когда ViewController перестает существовать. В то же время чтение данных блоками (построчно) из базы данных SQL порождает большое количество объектов (на уровне выходящем за рамки контроля приложения), которые суммарно превышают указанный объем, к тому же, создают дополнительную нагрузку на процессор. Использование центрального хранилище оправдано тогда, когда данные должны сохраняться долгое время, на протяжении многих сессий работы приложения. При этом, данные из сети загружаются частично.
Локальное хранилище на основе CoreData.
CoreData не предоставляет возможности для использование сериализированных данных. Все данные должны быть подвергнуты объектно-реляционным преобразованиям, до их использования слоем локального хранилища. После получения данных от команды API profile, происходит передача данных в метод категории copyDataFromRemoteJSON, где из словаря извлекаются данные, а затем уже сохраняются в соответствующем управляемом объекте (потомокк класса NSManagedObject).
Вот пример того, как это происходит:
Листинг 14
[[Client client] profile:@{} success:^(id response) { [[Member getCurrentMember] copyDataFromRemoteJSON:[response valueForKey:@"data"]]; } fail:^(id response) { }];
Еще лучшим подходом было бы, если бы callback из API мог бы возвращать валидизированные сериализированные данные, упакованные, к тому же, в управляемый объект.
Общий алгоритм работы с данными следующий:
- Пользователю отображаются данные которые присутствуют в системе сразу после запуска приложения.
- Производится запрос на получение тех же данных с удаленного сервера, так как сервер должен подтвердить их актуальность. Этот запрос подтверждает авторизацию приложения.
- Если данные с сервера получены, то авторизация осуществлена успешно, и производится циклическая загрузка остальных данных.
- Если сервер не подтверждает авторизацию (срок жизни токена истек) все данные локальной системы удаляются. Пользовательский интерфейс обновляется.
- Полученные данные синхронизируются с содержимым локального хранилища. (Т. е. каждый объект частично вычитывается из локального хранилища, проверяется, есть ли идентификатор такого объекта, если такой идентификатор уже есть, данные игнорируются/обновляются, если его нет, данные добавляются).
- После того, как процесс записи осуществлен полностью интерфейс пользователя обновляется
Преимущества данного подхода:
Гипотетически считается, что ленивая загрузка при помощи NSFetchController позволяет существенно ускорить отображение данных из базы данных, когда их количество составляет несколько тысяч записей. Так же, добавление данных в базу уменьшает количество передаваемой информации по сети. Данные добавляются. Те что есть- показываются пользователю. Пользователь может удалить данные которые ему не нужны. Данные добавляются в те, объекты, которые уже существуют, как элементы их массива.
Недостатки такого подхода:
- В первую очередь к надостаткам подхода необходимо отнести все те преимущества, которые были рассмотрены выше (подход на основе файловой системы):
- Последовательность отображения данных на экране не гарантируется, поскольку, данные извлекаются из SQLite базы данных, а там они лежат в «натуральном» порядке. Для создания последовательного отображения требуется вводить атоинкрементный номер, или какой-либо другой механизм, которые не предоставляется, ни CoreData ни SQLite.
- Данные никак не связаны с сетевыми запросами, что сильно осложняет их отладку.
- Сохранение данных в локальном хранилище происходит атомарно для всего контекста. Но, между вызовами записи данные могут быть потеряны, или перезатерты. Кроме того, процедура сохранения в базе может быть не вызвана.
- Большие объемы данных извлекаются из Database с существенно большей скоростью чем чтение плоского файла, однако, для сравнительно небольших файлов, скорость все равно будет выше.
- ACID не применим к SQLite в реализации с CoreData. Одновременная запись разных контекстов из разных потоков легко приводит к крешам приложения. Частично проблема решается путем использования библиотеки MagicRecords.
- Для нормализации данных необходимо применять специальные процедуры. Если некоторые поля заполняются по определенному условию, а объем данных возрастает, то либо данные необходимо дробить на большое количество объектов, либо извлекать из них абстрактные сущности, либо применять специальные процедуры для удаления устаревающих данных.
- Данные в CoreData всегда реляционны. Поэтому этому вопрос независимости рассматриваться может только в том случае, если схема CoreData не содержит связей между элементами.
- Поскольку актуальность данных определяется сервером, а не приложением, то данные которые не были получены из сети, все равно приходится удалять. Таким образом, использование CoreData никак не влияет на сетевой трафик в данной схеме.
- Объем кода многократно превышает тот, который необходим для обслуживания хранилища на основе файловой системы. Так же, использование CoreData налагает определенные ограничения и на пользовательский интерфейс.
Во-вторую очередь к недостаткам подхода необходимо так же отнести то, что:
- CoreData требует определенной дисциплины для работы из различных потоков приложения, и выборе актуального контекста.
- Синхронизация данных может настолько снижать производительность устройства, что вопрос об использовании 4S аппаратов будет весьма актуальным.
- Сильно осложнена отладка приложений. Некоторые операции неочевидные, и для поиска ошибочного поведения приходится изучать библиотеку MagicalRecords (https://github.com/magicalpanda/MagicalRecord) или дописывать свои классы и категории.
Прежде чем делать выбор между CoreData, локальной файловой системой, или любым другим хранилищем стоит уяснить для себя, для чего Ваше локальное хранилище будет использовано. Если для хранения и накопления данных между сессиями — то CoreData идеальный механизм для такой реализации, но, если это временные данные, стоит рассмотреть варианты хранения данных в виде плоских файлов, или иерархического хранилища по типу NoSQL баз данных или XML.
При использовании библиотеки MagicalRecords возникает ситуация, когда для правильного функционирования приложения табличное представление должно быть частью UITableViewController, иначе становится затруднительным использование NSFetchController лежащий в основе загрузки данных CoreData. Таким образом, существует зависимость в использовании пользовательского интерфейса, от локального хранилища. Т. е. имплементация CoreData ограничивает в разработке UI.
Альтернативный взгляд
Не смотря на высказанные возражения, использование CoreData может, действительно, потенциально увеличить производительность при возрастании объема данных, в том случае, если воспользоваться следующими альтернативами:
Альтернатива 1
Произвести нормализацию данных API сервера. Сервер должен возвращать не полный иерархический объект, с множеством вложенных сущностей, а множество мелких объектов, которые легко добавляются в базу данных.
В этом случае:
Загружаться будут небольшие порции свежих данных, что уменьши сетевой трафик.
Приложение сможет сделать запрос к серверу с идентификаторами объектов, чтоб сервер вернул список того, что необходимо удалить.
Отпадает необходимость в синхронизации получаемых данных для каждой загружаемой записи.
Альтернатива 2
Задача может быть решена только средствами клиентского приложения: сформировать таблицу в CoreData в которую записывать JSON объект в чистом виде, сразу после доступа к сети. Дополнительно вписывать туда дату записи, идентификатор пользователя, хеш запроса, и хеш данных.
Это позволит:
- Сериализировать данные «на лету» в двоичные объекты на основе JSON схемы.
- Обеспечить функционирования этого механизма на уровне Слоя Ядра, т. е. прозрачно для разработчика.
- Мгновенно переключаться между контекстами пользователей.
- Удалять неактуальные записи по мере их устаревания, на основе информации заданной сервером в заголовке ответа.
- Не смотря на использование SQLite сервера данные не потребуют нормализации.
- Существенно сократить количество используемого кода.
Заключение:
Статья получилась довольно длинной, и, сомневаюсь, что большинство читателей осилят ее до конца. По этой причине, часть, связанную с GUI я решил отсюда выкинуть. Во-первых, она относилась к построению пользовательского интерфейса через UITabbar, а во-вторых, в одной из скайп групп, состоялась весьма интересная дискуссия относительно использования широко известных паттернов MVC и MVVM. Излагать принципы построения интерфейса не имеет смысл без скурпулезного изложения существущих практик и подходов, которые заводят разработчиков в тупик. Но это тема большой еще одной многостраничной статьи. Здесь же, я постарался рассмотреть лишь вопросы, связанные с функционированием ядра приложения.
Если читатели проявят достаточный интерес к этой тематике, то в ближайшее время постараюсь выложить исходные классы, для использование в качестве шаблона приложения.

