Доброго времени суток, уважаемые хабровчане! Сегодня я хотел бы поговорить о том, как не имея особого опыта в машинном обучении, можно попробовать свои силы в соревнованиях, проводимых Kaggle.

Как вам уже, наверное, известно, Kaggle – это платформа для исследователей разных уровней, где они могут опробовать свои модели анализа данных на серьезных и актуальных задачах. Суть такого ресурса – не только в возможности получить неплохой денежный приз в случае, если именно ваша модель окажется лучшей, но и в том (а, это, пожалуй, гораздо важнее), чтобы набраться опыта и стать специалистом в области анализа данных и машинного обучения. Ведь самый важный вопрос, зачастую стоящий перед такого рода специалистами – где найти реальные задачи? Здесь их достаточно.
Мы попробуем поучаствовать в обучающем соревновании, не предусматривающем каких-либо поощрений, кроме опыта.
Для этого мною была выбрана задача распознавания рукописных цифр из выборки MNIST. Немного сведений из вики. MNIST (Mixed National Institute of Standards and Technology database) является основной базой при тестировании систем распознавания образов, а также широко используемой для обучения и тестирования алгоритмов машинного обучения. Она была создана перегруппировкой образов из оригинальной базы NIST, которая являлась достаточно сложной для распознавания. Кроме этого, были выполнены определенные преобразования (образы были нормализованы и сглажены для получения градаций серого цвета).
База MNIST состоит из 60000 образов для обучения и 10000 образов для тестирования. Написано большое количество статей, посвященных задаче распознавания MNIST, например (в данном случае авторы использовали иерархическую систему из сверточных нейронных сетей).
Оригинальная выборка представлена на сайте.
На Kaggle представлена полная выборка MNIST, организованная немного по-другому. Здесь обучающая выборка включает в себя 42000 образов, а выборка тестирования – 28000. Тем не менее, по содержанию они эквивалентны. Каждый образ MNIST представлен картинкой 28Х28 пикселей с 256 градациями серого цвета. Пример нескольких неоднозначных в идентификации цифр представлен на картинке ниже.

Для создания своей модели нейронной сети для распознавания цифр воспользуемся интерпретатором Рython c установленным пакетом nolearn 0.4, а также numpy и scipy (для удовлетворения всех зависимостей).
Здесь мне очень помогла вводная статья, написанная Adrian Rosebrock в своем блоге. В ней даются вводные сведения о нейронных сетях глубокого доверия и их обучении, хотя сам автор при тестировании использует обычный многослойный персептрон архитектуры 784-300-10 без какого-либо предобучения. Так поступим и мы. Кстати, весьма подробно и на примере разных классических выборок рассматривается процесс использования пакета на страничке nolearn.
Итак, следуя указаниям, которые даются в названных выше статьях, создадим свой многослойный персептрон, обучим его на загруженных и обработанных данных, а затем проведем тестирование.
Для начала создадим свой двухслойный персептрон архитектуры 784-300-10:
Здесь требуются некоторые пояснения. Первый параметр конструктора нейронной сети – список, содержащий количество входов и нейронов в каждом слое, learn_rates – скорость обучения, learn_rate_decays – множитель, задающий изменение скорости обучения после каждой эпохи, epochs – количество эпох обучения, verbose – флаг вывода подробного отчета процесса обучения.
После выполнения этой инструкции, необходимая модель будет создана и нам останется только загрузить данные. Kaggle предоставляет нам два файла: train.csv и test.csv, содержащие соответственно выборки для обучения и тестирования. Структура файлов простая – в первой строке содержится заголовок, далее следуют данные. Для train.csv каждая строка с данными предваряется соответствующей меткой – цифрой от 0 до 9, определяющей образ. В test.csv метка отсутствует.
Следующим этапом загрузим данные в массивы, воспользовавшись пакетом для работы с csv-файлами. Не забываем произвести нормировку:
После этого обучаем нашу нейронную сеть на подготовленных данных:
Сам процесс занимает некоторое время, определяемое количеством эпох обучения, заданным при конструировании нейронной сети. На каждой эпохе обучения на экран будут выводиться (при заданном параметре verbose) значения loss и err (значение функции потерь и ошибка).
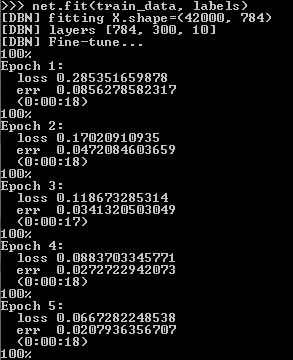
После обучения все, что нам остается сделать – загрузить данные тестирования и сохранить предсказания для каждого образа из выборки тестирования в файл с расширением csv:
Дальше загружаем полученный файл в систему тестирования (см. рисунок) и ждем.
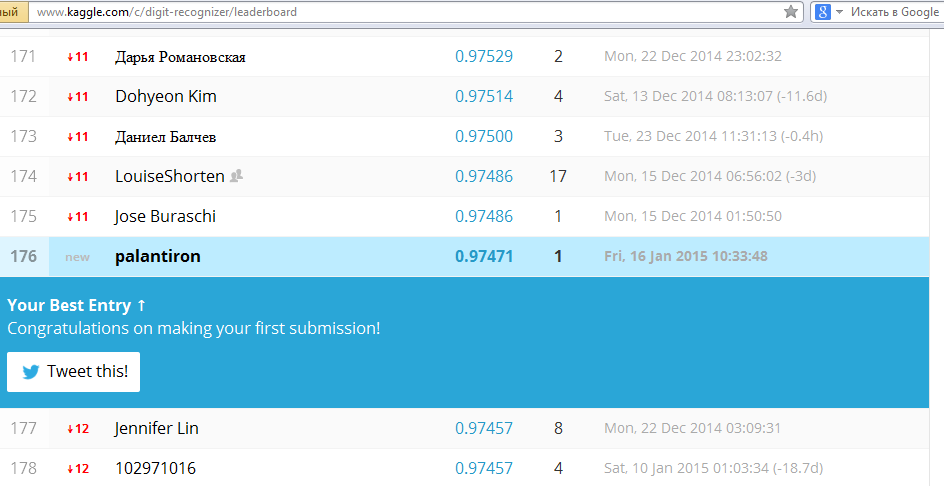
Готово! 176 место из более чем 500 участников. Для начала вполне неплохо. Теперь полученный результат можно попытаться улучшить, например, применив собственные разработки или модифицируя и подбирая параметры в nolearn. Благо времени достаточно: соревнование по MNIST’у неоднократно продлевали и теперь оно будет проходить до 31.12.2015. Удачи и спасибо, что прочитали эту статью.
Как вам уже, наверное, известно, Kaggle – это платформа для исследователей разных уровней, где они могут опробовать свои модели анализа данных на серьезных и актуальных задачах. Суть такого ресурса – не только в возможности получить неплохой денежный приз в случае, если именно ваша модель окажется лучшей, но и в том (а, это, пожалуй, гораздо важнее), чтобы набраться опыта и стать специалистом в области анализа данных и машинного обучения. Ведь самый важный вопрос, зачастую стоящий перед такого рода специалистами – где найти реальные задачи? Здесь их достаточно.
Мы попробуем поучаствовать в обучающем соревновании, не предусматривающем каких-либо поощрений, кроме опыта.
Для этого мною была выбрана задача распознавания рукописных цифр из выборки MNIST. Немного сведений из вики. MNIST (Mixed National Institute of Standards and Technology database) является основной базой при тестировании систем распознавания образов, а также широко используемой для обучения и тестирования алгоритмов машинного обучения. Она была создана перегруппировкой образов из оригинальной базы NIST, которая являлась достаточно сложной для распознавания. Кроме этого, были выполнены определенные преобразования (образы были нормализованы и сглажены для получения градаций серого цвета).
База MNIST состоит из 60000 образов для обучения и 10000 образов для тестирования. Написано большое количество статей, посвященных задаче распознавания MNIST, например (в данном случае авторы использовали иерархическую систему из сверточных нейронных сетей).
Оригинальная выборка представлена на сайте.
На Kaggle представлена полная выборка MNIST, организованная немного по-другому. Здесь обучающая выборка включает в себя 42000 образов, а выборка тестирования – 28000. Тем не менее, по содержанию они эквивалентны. Каждый образ MNIST представлен картинкой 28Х28 пикселей с 256 градациями серого цвета. Пример нескольких неоднозначных в идентификации цифр представлен на картинке ниже.
Для создания своей модели нейронной сети для распознавания цифр воспользуемся интерпретатором Рython c установленным пакетом nolearn 0.4, а также numpy и scipy (для удовлетворения всех зависимостей).
Здесь мне очень помогла вводная статья, написанная Adrian Rosebrock в своем блоге. В ней даются вводные сведения о нейронных сетях глубокого доверия и их обучении, хотя сам автор при тестировании использует обычный многослойный персептрон архитектуры 784-300-10 без какого-либо предобучения. Так поступим и мы. Кстати, весьма подробно и на примере разных классических выборок рассматривается процесс использования пакета на страничке nolearn.
Итак, следуя указаниям, которые даются в названных выше статьях, создадим свой многослойный персептрон, обучим его на загруженных и обработанных данных, а затем проведем тестирование.
Для начала создадим свой двухслойный персептрон архитектуры 784-300-10:
from nolearn.dbn import DBN net = DBN( [784, 300, 10], learn_rates=0.3, learn_rate_decays=0.9, epochs=10, verbose=1, )
Здесь требуются некоторые пояснения. Первый параметр конструктора нейронной сети – список, содержащий количество входов и нейронов в каждом слое, learn_rates – скорость обучения, learn_rate_decays – множитель, задающий изменение скорости обучения после каждой эпохи, epochs – количество эпох обучения, verbose – флаг вывода подробного отчета процесса обучения.
После выполнения этой инструкции, необходимая модель будет создана и нам останется только загрузить данные. Kaggle предоставляет нам два файла: train.csv и test.csv, содержащие соответственно выборки для обучения и тестирования. Структура файлов простая – в первой строке содержится заголовок, далее следуют данные. Для train.csv каждая строка с данными предваряется соответствующей меткой – цифрой от 0 до 9, определяющей образ. В test.csv метка отсутствует.
Следующим этапом загрузим данные в массивы, воспользовавшись пакетом для работы с csv-файлами. Не забываем произвести нормировку:
import csv import numpy as np with open('D:\\train.csv', 'rb') as f: data = list(csv.reader(f)) train_data = np.array(data[1:]) labels = train_data[:, 0].astype('float') train_data = train_data[:, 1:].astype('float') / 255.0
После этого обучаем нашу нейронную сеть на подготовленных данных:
net.fit(train_data, labels)
Сам процесс занимает некоторое время, определяемое количеством эпох обучения, заданным при конструировании нейронной сети. На каждой эпохе обучения на экран будут выводиться (при заданном параметре verbose) значения loss и err (значение функции потерь и ошибка).
После обучения все, что нам остается сделать – загрузить данные тестирования и сохранить предсказания для каждого образа из выборки тестирования в файл с расширением csv:
with open('D:\\test.csv', 'rb') as f: data = list(csv.reader(f)) test_data = np.array(data[1:]).astype('float') / 255.0 preds = net.predict(test_data) with open('D:\\submission.csv', 'wb') as f: fieldnames = ['ImageId', 'Label'] writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() i = 1 for elem in preds: writer.writerow({'ImageId': i, 'Label': elem}) i += 1
Дальше загружаем полученный файл в систему тестирования (см. рисунок) и ждем.
Готово! 176 место из более чем 500 участников. Для начала вполне неплохо. Теперь полученный результат можно попытаться улучшить, например, применив собственные разработки или модифицируя и подбирая параметры в nolearn. Благо времени достаточно: соревнование по MNIST’у неоднократно продлевали и теперь оно будет проходить до 31.12.2015. Удачи и спасибо, что прочитали эту статью.

