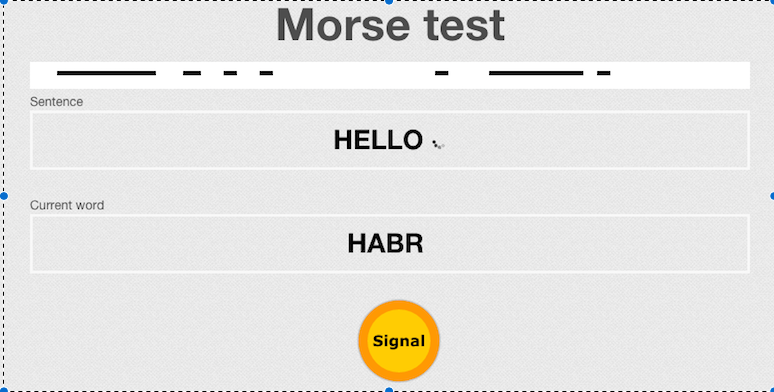
Задача: на входе сигналы с клавиатуры (keyup, keydown) — на выходе буквы и слова декодированные по азбуке Морзе. О том, как декларативно решить данную задачу используя FRP подход, в частности Rx.js — ниже под катом. (Зачем? Because we can)
Для не терпеливых:
- demo — http://alexmost.github.io/morse/
- source — https://github.com/AlexMost/morse
Основная идея
Данная демка предназначена для демонстрации силы

Поэтому я постараюсь более подробно описать одну из функциональных частей приложения (с живыми примерами и схемами).
Логика Морзе
Буква в азбуке Морзе — представляет собой набор длинных и коротких сигналов (точек и тире), разделенных некоторым временным промежутком.
Основные правила (идеальный вариант):
- За единицу времени принимается длительность одной точки.
- Длительность тире равна трём точкам.
- Пауза между элементами одного знака — одна точка.
- Пауза между знаками в слове — 3 точки.
- Пауза между словами — 7 точек.
Забегая вперед, хочу предупредить, что не сильно заморачивался над размерностъю и «на глаз» взял продолжительность точки в 400 мс. Данный проект не претендует на 100% соответствие с реальной морзянкой (не пытайтесь использовать в военных условиях), но принцип действия остается тем же. Относительно 400 мс вычисляются остальные временные интервалы (размер тире, пауза между буквами и словами). Интерфейс построен так, что дает понять когда он ожидает символ(точку, тире) из буквы, новую букву, или следующее слово.
— Что? Да я на коленке такое за 5 минут и без Rx сделаю
В чем основная сложность?
Основная сложность заключается в том, что мы имеем дело с асинхронной логикой. Кол-во сигналов в букве недетерминированно. Например, буква 'A' состоит из двух символов — точка и тире (.-), в то время, как '0' это пять тире (-----). Так же, непросто представить, как отсчитывать время от одной буквы до другой. Как между этим всем делом еще понимать, что произошел интервал между словами?.. Данную проблему возможно решить стандартным императивным подходом с кучей callback-ов или promise и setTimeout или новомодным async/await. Я не хочу убеждать вас в том, что это неправильно, просто хочу показать еще один подход, который пришелся мне по душе.
Декомпозиция задачи и разные слои абстракции
— Divide et impera !!!
Для решения сложной задачи необходимо разбить ее на более мелкие и простые подзадачи и решить каждую из них отдельно. В данном случае мы имеем на входе низкоуровневые сигналы (DOM event-ы), а на выходе буквы и слова. Данную задачу можно сравнить с сетевой моделью OSI. Модель представлена разными уровнями, каждый из которых выполняет свою задачу и предоставляет данные для вышестоящего слоя. Основное сходство заключается в том, что каждый из уровней имеет свою четкую логику, но не знает о всей модели вцелом. Давайте выделим основные слои абстракций в нашей задаче:
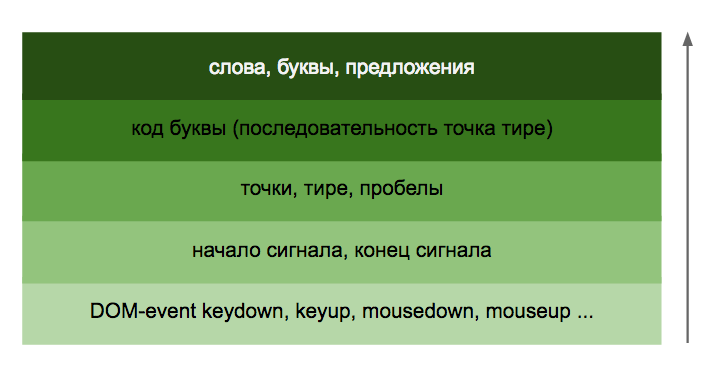
Как видно, каждый cлой оперирует своей логикой, предоставляя данные выше стоящему слою и не знает о всей системе вцелом.
Последовательность событий как объект первого класса
Rx позволяет рассматривать любую асинхронную последовательность как объект первого класса. Это значит мы можем сохранить все возникающие keyup-ы и keydown-ы в некую коллекцию (Observable) и оперировать с ней как с обычным массивом данных.
Разберем задачу «точка или тире»
Далее я постараюсь подробно описать процесс получения стрима, в котором будут приходить точки или тире. Для начала, получим коллекции всех нажатий клавиш:
const keyUps = Rx.Observable.fromEvent(document, 'keyup');
const keyDowns = Rx.Observable.fromEvent(document, 'keydown');
пример на jsfiddle
Получив массивы kyeup и keydown событий, нас интересуют только нажатия по пробелу. Можем получить их c помощью операци filter — это и будет наш первый уровень абстракции с DOM-event-aми:
const spaceKeyUps = keyUps.filter((data) => data.keyCode === 32);
const spaceKeyDowns = keyDowns.filter((data) => data.keyCode === 32);
пример на jsfiddle
Схематически это выглядит так:
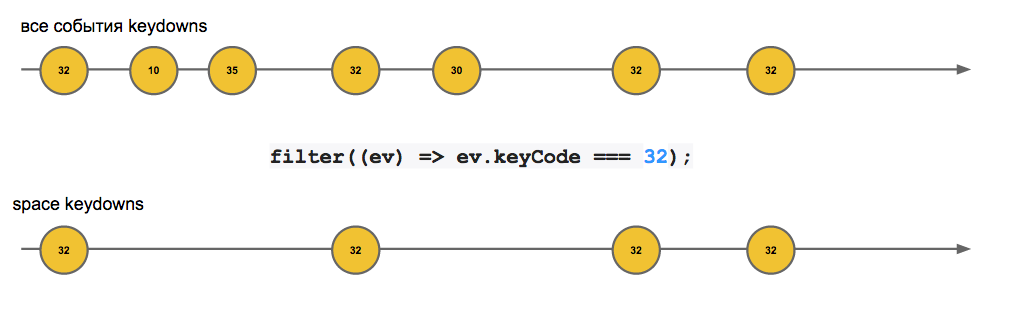
На картинке выше видим 2 стрима. Верхний включает в себя все события keydown. Нижний создан на базе верхнего, но как видим, к нему применили функцию filter, которая фильтрует код нажатой клавиши. В итоге имеем новый стрим с keydown пробела. Вы где нибудь видели событие spaceKeyDown в DOM api? Только что мы создали его на базе существующего DOM event и будем использовать его дальше.
Нас не особо интересует, откуда был получен сигнал (мышь, нажатие клавиши, микрофон, камера), абстрагируемся и передаем дальше просто факт того, что сигнал начался или закончился:
const signalStarts = spaceKeyDowns.map(() => "start");
const signalEnds = spaceKeyUps.map(() => "end");
пример на jsfiddle
Но не все так просто с signalStarts :)
Есть небольшая проблемка с событием keydown. DOM api работает таким образом, что событие keydown срабатывает множество раз при зажатии клавиши. Мы это можем лекго побороть, добавив немного кода:
Давайте разберем что сдесь произошло. Основная проблема заключается в возникновении двух одинаковых последовательных событий. В данном случае можно получить общий стрим из start и end (signalStartsEnds) и применить к нему функцию distinctUntilChanged. Она будет гарантировать, что события не будут повторяться. (подробнее про distinctUntilChanged — тут)
рабочий пример на jsfiddle
const signalStartsRaw = spaceKeyDowns.map(() => "start");
const signalEndsRaw = spaceKeyUps.map(() => "end");
// получаем общий стрим из start и end.
const signalStartsEnds = Rx.Observable.merge(signalStartsRaw, signalEndsRaw).distinctUntilChanged();
// signal star/end with toggle logic
const signalStarts = signalStartsEnds.filter((ev) => ev === "start");
const signalEnds = signalStartsEnds.filter((ev) => ev === "end");
Давайте разберем что сдесь произошло. Основная проблема заключается в возникновении двух одинаковых последовательных событий. В данном случае можно получить общий стрим из start и end (signalStartsEnds) и применить к нему функцию distinctUntilChanged. Она будет гарантировать, что события не будут повторяться. (подробнее про distinctUntilChanged — тут)
рабочий пример на jsfiddle
Далее, нам необходимо высчитывать время между началом и окончанием сигнала, для этого давайте добавим временные метки к нашим коллекциям:
const signalStarts = signalStartsEnds.filter((ev) => ev === "start").timestamp();
const signalEnds = signalStartsEnds.filter((ev) => ev === "end").timestamp();
После этого необходимо возвращать разницу во времени между keydown и keyup. Создадим для этого отдельный стрим. Так как возникновение keyup события не детерменированно. То есть, если рассматривать keydown как stream и засекать время каждого нажатия на клавишу, каждое событие должно возвращать еще один стрим, который вернет первое значение keyup. Очень сложно звучит, проще посмотреть как это выглядит в коде:
const spanStream = signalStarts.flatMap((start) => {
return signalEnds.map((end) => end.timestamp - start.timestamp).first();
});
пример на jsfiddle
Схематически это выглядит так:
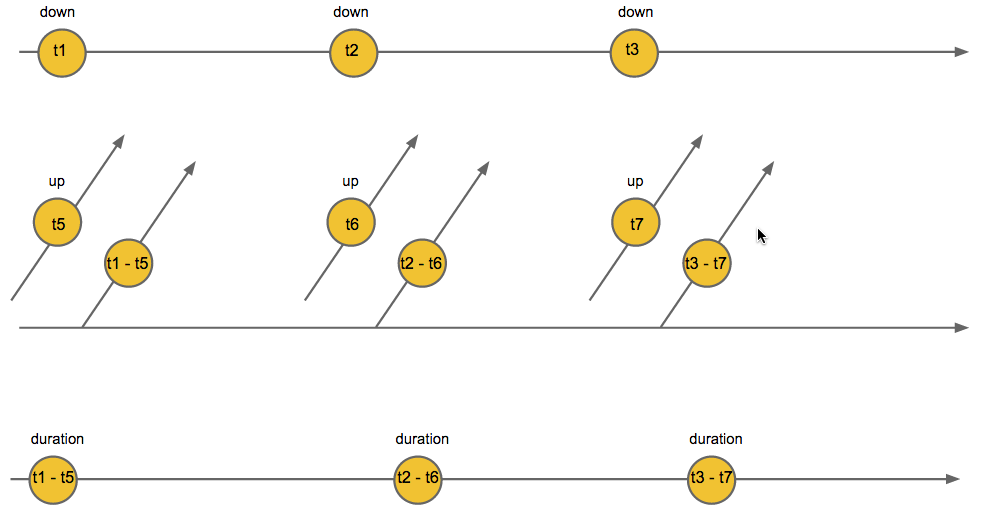
На изображении t1, t2, t3… это время возникновения события. t2 — t1 — разница во времени. Проговорить это можно как: «На каждое начало сигнала, создаем стрим из сигналов окончания сигнала, ждем из него 1й сигнал, далее передаем разницу во времени между началом и окончанием сигналов». Таким образом мы получили стрим из временных интервалов, и по ним можем определить точки и тире:
const SPAN = 400;
const dotsStream = spanStream.filter((v) => v <= SPAN).map(() => ".");
const lineStream = spanStream.filter((v) => v > SPAN).map(() => "-");
Полный код примера выглядит так — пример на jsfiddle. Уберем немного шума и получим более красивый код (субъективное мнение, но если вам не понравилось — у вас нет души).
И вот наш обещаный стрим из точек и тире:
const dotsAndLines = Rx.Observable.merge(dotsStream, lineStream);
Далее мы оперируем уже более высокоуровневыми стримами и создаем из них еще более высокоуровневые. Например, применив несоколько Rx преобразований мы можем получить стрим пробелов между буквами а потом и букву:
const letterCodes = dotsAndLines.buffer(letterWhitespaces) // стрим вида [['.', '.', '-'], ['-', '.', '-'] ... ]
const lettersStream = letterCodes.map((codes) => morse.decode(codes.join(""))).share() // стрим букв ['A', 'B' ...]
Ссылка на исходник
Красиво не так ли? Нет? Тогда вот так мы можем вывести картинку котика, если пользователь набрал кодами слово «CAT»:
const setCatImgStream = wordsStream.filter((word) => word == "CAT").map(setCatImg)
Пруф
Вывод
Таким образом мы видим, что от обычных DOM событий мы пришли к более осмысленным вещам (стримам с буквами и словами). В перспективе это можно компоновать дальше в предложения, абзацы, книги и т. д. Основная идея это то, что Rx дает возможность компоновать ваш существующий функционал для получения нового. Вся ваша логика превращается в некое API для построения новой более сложной и та в свою очередь тоже может быть скомпонована. В этой статье я упустил еще много преимуществ, которые дает вам Rx из коробки (тестирование асинхронных цепочек, чистка ресурсов, обработка ошибок). Надеюсь удалось заинтересовать тех, кто хотел попробовать но никак не решался.
Спасибо за внимание! Всем ФП =)

