
За последние полгода интернет просто наводнила «буква» «й». Я встречал ее на новостных сайтах, в мессенджерах, на хабрахабре и geektimes. «О чем вообще речь?» — спросите вы — «Я вижу обычную букву й!». Вам повезло. Я вижу ее так:
 |
 |
 |
 |
 |
Как же так получается?
Графемы, глифы, code points, компоновка и байты
Очень краткое введение:Графема — то, что мы привыкли называть буквой в смысле единицы текста. Глиф является единицей графики, и может графически представлять саму графему или же ее часть (например, различные диакритические знаки: ударения, умляуты, надстрочное двоеточие у буквы ё и т.д.).
Code Point — то, как записывается текст в представлении Unicode. Одна графема может записываться разными code points.
Code Points кодируются различным байтовым представлением в зависимости от стандарта: UTF-8, UTF-16, UTF-32, BE, LE…
Языки программирования, как правило, работают с code points; для нас, людей, привычно мыслить глифами.
Давайте же наконец разберемся с нашей буквой й. Что же в ней такого особенного?
Эта буква представляет из себя одну графему («и» краткое), но записана она двумя code points:
U+000438 CYRILLIC SMALL LETTER I U+000306 COMBINING BREVE
Если вы проделали фокус с нажатием backspace, вы как раз и стерли COMBINING BREVE, или, говоря полиграфическим языком, значок краткости над гласной.
Обычная буква «и» краткое, которую мы все с вами привыкли набирать клавиатурой, представляет из себя композитный символ, который записывается одним code point:
U+000439 CYRILLIC SMALL LETTER SHORT I
Отображение диакритических знаков зависит от шрифта и рендерера. Например, в окне редактирования данного поста символ выглядит правильно, а вот при просмотре едет. Некоторые шрифты могут отображать диактрические знаки раздельно даже в композитных символах.
Чем это плохо?
Не все программы, а сайты и подавно, умеют приводить code points к такому виду, который позволяет сравнивать одинаковые глифы, записанные с разными code points. Иными словами, не каждая программа и сайт распознает «й» и «й» за один символ, из-за чего становится невозможно, например, производить поиск по таким буквам.За примером далеко ходить не нужно: относительно свежая статья с обзором мыши на geektimes, скриншот из которой приведен выше в статье. Давайте выполним поиск в Google по следующей фразе, которая, вроде как, есть в статье:
никто не мешает создать «пустой» профиль
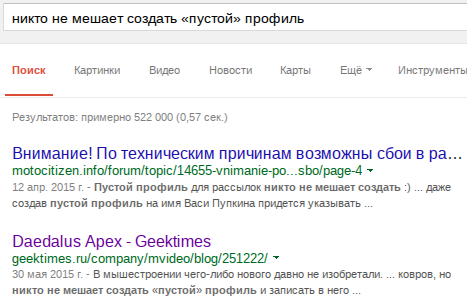
Пост выдается вторым результатом, и, как видно по выделенной жирным части, у нас полное текстовое совпадение. Отлично, открываем его и пытаемся найти на странице этот же текст и видим, что Firefox ничего не нашел:

Поиск по Geektimes также не выдает подходящего результата:
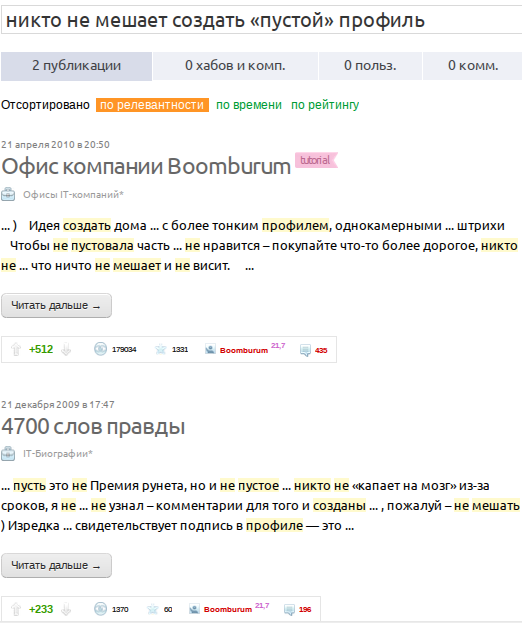
Но стоит заменить композитную «й» на ее декомпозитного собрата «й», как все встает на свои места:
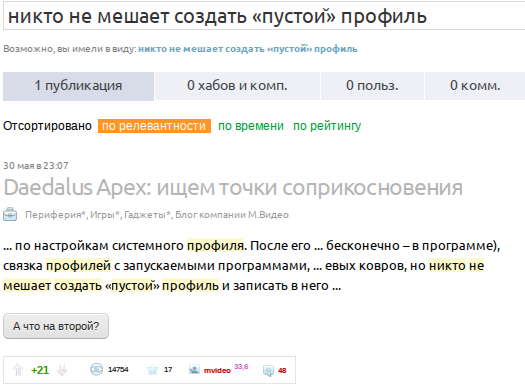
Очевидно, что Google как-то преобразовывает запрос поиска, позволяя искать по глифам, а не по их code points.
Как это работает?
Нормализация
Стандарт нормализации Unicode описывает две эквиваленции символов: Canonical и Compatibility. Первая как раз позволяет сравнивать одинаковые глифы с разными code points, а вторая позволяет их сравнивать с упрощенными аналогами — ½ с 1/2, ℌ c H и т.д.Также существует 4 типа нормализации:
- Normalization Form D (NFD) — canonical-декомпозиция. Разложит cześć (привет по-польски) на с, z, e, c + ´, s + ´.
- Normalization Form C (NFC) — соберет то, что разложил предыдущий вариант.
- Normalization Form KD (NFKD) — compatibility-декомпозиция. Сделает 1/2 из ½, 25 из 2⁵.
- Normalization Form KC (NFKC) — попытается собрать то, что разложила предыдущая.
Если говорить о сайте типа хабрахабра, то имеет смысл производить NFC-нормализацию всех постов до их публикации, а поисковой запрос подвергать NFKD-обработке.
В Python, например, это можно сделать модулем unicodedata.
Скрытый текст
import sys
import unicodedata
print(unicodedata.normalize('NFKD', sys.argv[1]))
% python unicode.py cześć | hexdump -C
00000000 63 7a 65 73 cc 81 63 cc 81 0a |czes..c...|
% echo 'cześć' | hexdump -C
00000000 63 7a 65 c5 9b c4 87 0a |cze.....|
import unicodedata
print(unicodedata.normalize('NFKD', sys.argv[1]))
% python unicode.py cześć | hexdump -C
00000000 63 7a 65 73 cc 81 63 cc 81 0a |czes..c...|
% echo 'cześć' | hexdump -C
00000000 63 7a 65 c5 9b c4 87 0a |cze.....|
Заключение
Не могу сказать с полной уверенностью, кто виноват в появлении «й» в рунете, но подозрение падает на Google Docs. К счастью, похоже, баг починили, т.к. уже 3 недели мне не приходилось смотреть на уползшую кратку.Проблемы с глифами случаются и в оффлайне. Вот фотография реального паспорта с буквой, вероятно, «ё» (CYRILLIC SMALL LETTER IE + COMBINING DIAERESIS)


