Существуют различные мнения относительно производительности С++ и C#.
Например, сложно поспорить с тем, что код C# может работать быстрее за счет оптимизации под платформу во время JIT компиляции. Или например с тем, что ядро .Net Framework само по себе очень хорошо оптимизировано.
С другой стороны, весомым аргументом является то, что С++ компилируется непосредственно в машинный код и работает с минимально возможным количеством хелперов и прослоек.
Встречаются и мнения о том, что производительность кода измерять не правильно, ибо микро уровень не характеризует производительность на макро уровне. (я конечно соглашусь с тем что на макроуровне можно испортить производительность, но вряд ли соглашусь с тем что производительность на макро-уровне не складывается из производительности на микро-уровне)
Попадались и утверждения о том, что код на С++ примерно в десять раз быстрее кода на С#.
Все это многообразие противоречивых мнений приводит к мысли о том, что нужно самому попробовать написать максимально идентичный и простой код на одном и другом языке, и сравнить время его выполнения. Что и было мною сделано.
Тест, который выполнен в этой статье
Мне хотелось выполнить самый примитивный тест, который покажет разницу между языками на микро-уровне. В тесте пройдем полный цикл операций с данными, создание контейнера, заполнение, обработка и удаление, т.е. как обычно и бывает в приложениях.
Работать будем с данными типа int, дабы сделать их обработку максимально идентичной. Сравнивать будем только релизные билды дефолтной конфигурации используя Visual Studio 2010.
Код будет выполнять следующие действия:
1. Аллоцирование массива\контейнера
2. Заполнение массива\контейнера числами по возрастанию
3. Сортировка массива\контейнера методом пузырька по убыванию (метод выбран самый простой, по скольку мы не сравниваем методы сортировки, а средства реализации)
4. Удаление массива\контейнера
Код была написан несколькими альтернативными методами, отличающимися различными типами контейнеров и методами их аллокации. В самой статье приведу лишь примеры кода, которые как правило, работали максимально быстро для каждого из языков. Остальные же примеры, со вставками для подсчета скорости выполнения,- полностью можно увидеть тут.
Код теста
Как вы можете убедиться, код достаточно простой и почти идентичный. Поскольку в C# нельзя явно выполнить удаление, время выполнения которого мы хотим измерить, вместо удаления будем использовать items = null; GC.Collect(); при условии что ничего кроме контейнера мы (во всем нашем примере) не создавали, GC.Collect удалить должен бы тоже только контейнер, поэтому думаю это достаточно адекватная замена delete[] items.
Объявление int tmp; за циклом в случае C# экономит время, поэтому рассмотрена именно такая вариация теста для случая C#.
На разных машинах получались разные результаты данного теста (видимо в силу разницы архитектур), однако разницу в производительности кода результаты измерений позволяют оценить.
В измерениях, для подсчета времени выполнения кода, был использован QueryPerformanceCounter, измерялось «время» создания, заполнения, сортировки и удаления на тестовых платформах формах получились следующие результаты:
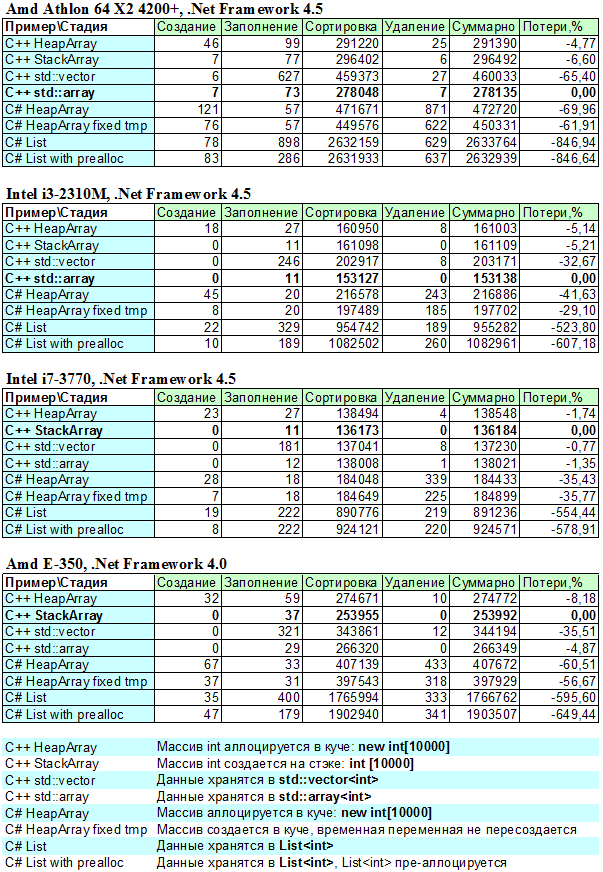
Из таблиц видно что:
1. Cамая быстрая С# реализация работает медленнее самой быстрой C++ реализации на 30-60% (в зависимости от платформы)
2. Разброс между самой быстрой и самой медленной С++ реализацией 1-65% (в зависимости от платформы)
3. Самая медленная(из рассмотренных конечно) реализация на С#, медленнее самой медленной С++ реализации примерно в 4 раза
4. Больше всего времени занимает этап сортировки (по сему, в дальнейшем рассмотрим его более детально)
Еще стоит обратить внимание на то, что std::vector является медленным контейнером на старых платформах, однако вполне быстрым на современных. А также на то, что время «удаления» в случае первого .Net теста несколько выше, видимо из-за того что кроме тестовых данных удаляются еще какие-то сущности.
Причина разницы производительности С++ и С# кода
Давайте посмотрим на код, который выполняется процессором в каждом случае. Для этого возьмем код сортировки из самых быстрых примеров и посмотрим во что он компилируется, смотреть будем используя отладчик Visual Studio 2010 и режим disassembly, в результате для сортировки увидим следующий код:
Что мы тут можем увидеть?
19 инструкций C++ против 23 на С#, разница не большая, но в купе с прочей оптимизацией, думаю она может объяснить причину большего времени выполнения C# кода.
В C# реализации также некоторые вопросы вызывает
jae 000001C2, который выполняет переход
на 000001c2 call 731661B1
Который видимо также и влияет на разницу во времени выполнения, внося дополнительные задержки.
Другие сравнения производительности
Стоит отметить что есть и другие статьи, где измеряли производительность С++ и С#. Из тех, что попадались мне, самой содержательной показалась Head-to-head benchmark: C++ vs .NET
Автор этой статьи, в некоторых тестах «подыграл» C# запретив использовать SSE2 для С++, поэтому некоторые результаты С++ тестов с плавающей стали примерно в два раза медленнее чем были бы с включенным SSE2. В статье можно найти и другую критику методологии автора, среди которой очень субъективный выбор контейнера для теста в С++.
Однако не принимая в расчет тесты с плавающей точкой без SSE2, и делая поправку на ряд других особенностей методики тестирования, результаты, полученные в статье, стоит рассмотреть.
По результатам измерений можно сделать ряд интересных выводов:
1. Дебажный билд С++ заметно медленнее релизного, при том что разница дебажного и релизного билда С# менее существенна
2. Производительность C# под .Net Framework заметно(более 2х раз) выше чем производительность под Mono
3. Для С++ вполне можно найти контейнер который будет работать медленнее подобного контейнера для C#, и никакая оптимизация не поможет это побороть кроме как использование другого контейнера
4. Некоторые операции работы с файлом в С++ заметно медленнее аналогов в С#, однако их альтернативы столь же заметно быстрее аналогов С#.
Если подводить итоги и говорить о Windows, то статья приходит примерно к похожим результатам: код С# медленнее С++ кода, примерно на 10-80%
Много ли это -10..-80%?
Допустим при разработке на С# мы всегда будем использовать наиболее оптимальное решение, что потребует от нас очень неплохих навыков. И предположим мы будем укладываться в суммарные 10..80% потерь производительности производительности. Чем это нам грозит? Попробуем сравнить эти проценты с другими показателями характеризующими производительность.
Например, в 1990-2000 годах, одно-поточная производительность процессора росла за год примерно на 50%. А начиная с 2004 года темпы роста производительности процессоров упали, и составляли лишь 21% в год, по крайней мере до 2011 года.
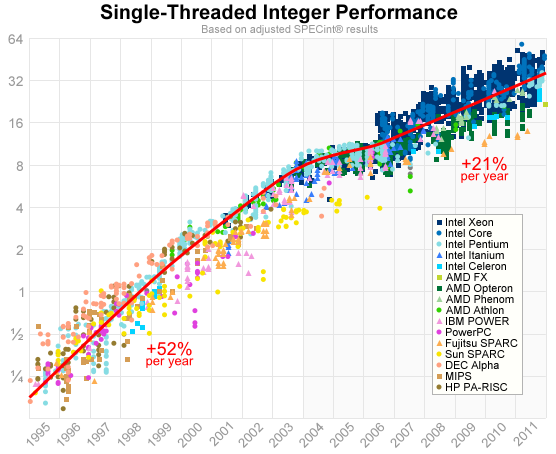
A Look Back at Single-Threaded CPU Performance
Ожидаемые показатели роста производительности весьма туманны. Вряд ли в 2013 и 2014 годах был показан рост выше 21%, более того, вполне вероятно что в будущем рост ожидается еще ниже. По крайней мере, планы Intel по осваиванию новых технологий с каждым годом все скромнее…
Другое направление для оценки,- это энергоэффективность и дешевизна железа. Например тут можно увидеть, что говоря о топовом железе +50% одно-поточной производительности может в 2-3 раза удорожать стоимость процессора.
C точки же зрения энергоэфективности и шума — сейчас вполне реально собрать экономичный PC на пассивном охлаждении, однако придется пожертвовать производительностью, и эта жертва вполне может быть около 50% и более производительности относительно прожорливого и горячего, но производительного железа.
Как будет расти производительность процессоров точно не известно, однако по оценкам видно что в случае 21% роста производительности в год, приложение на С#, может отставать по производительности на 0.5-4 года относительно приложения на С++. В случае, например 10% роста, — отставание уже будет 1-8 лет. Однако, реальное приложение может отставать намного меньше, ниже рассмотрим почему.
Я пока не берусь оценивать рентабельность жертвы 10..80% производительности ради получения экономии на разработке. Очевидно, что эта рентабельность зависит от стоимости получения этих 10..80% другими способами (т.е. за счет железа). Однако наметившаяся тенденция показывает, что каждый следующий процент производительности железа будет дороже предыдущего, что, вполне вероятно, рано или поздно приведет к ситуации, когда дешевле будет получить дополнительную производительность оптимизируя код.
Какая же все-таки реальная оценка?
С одной стороны вы вряд-ли будете писать столь оптимальный чтобы всегда показывать максимальную производительность.
Но с другой стороны, что более важно: сколько runtime (времени выполнения) вашей программы будет занимать ваш код, а сколько код системы?
Например если код занимает 1% времени выполнения приложения или сервиса, то даже 10-ти кратное падение производительности этого кода, не очень сильно повлияло бы на скорость работы приложения, и удар по производительности был бы лишь около 10%.
Но совсем другое дело когда около 100% времени выполнения приложения занимает выполнение вашего кода, а не кода ОС. В этом случае вы легко можете получить и -80% и большие потери производительности.
Выводы
Конечно из всего выше написанного не следует что нужно срочно переходить с С# на С++. Во первых разработка на C# дешевле, а во вторых для ряда задач производительность современных процессоров избыточна, и даже оптимизация в рамках C# не является нужной. Но мне кажется важным обратить внимание на накладные расходы т.е плату за использование managedсреды, и оценку этих расходов. Очевидно что в зависимости от рыночных условий и возникающих задач, эта плата может оказаться значимой. Другие аспекты сравнения С# и С++, можно найти в моей предыдущей статье Выбор между C++ и C#.
Например, сложно поспорить с тем, что код C# может работать быстрее за счет оптимизации под платформу во время JIT компиляции. Или например с тем, что ядро .Net Framework само по себе очень хорошо оптимизировано.
С другой стороны, весомым аргументом является то, что С++ компилируется непосредственно в машинный код и работает с минимально возможным количеством хелперов и прослоек.
Встречаются и мнения о том, что производительность кода измерять не правильно, ибо микро уровень не характеризует производительность на макро уровне. (я конечно соглашусь с тем что на макроуровне можно испортить производительность, но вряд ли соглашусь с тем что производительность на макро-уровне не складывается из производительности на микро-уровне)
Попадались и утверждения о том, что код на С++ примерно в десять раз быстрее кода на С#.
Все это многообразие противоречивых мнений приводит к мысли о том, что нужно самому попробовать написать максимально идентичный и простой код на одном и другом языке, и сравнить время его выполнения. Что и было мною сделано.
Тест, который выполнен в этой статье
Мне хотелось выполнить самый примитивный тест, который покажет разницу между языками на микро-уровне. В тесте пройдем полный цикл операций с данными, создание контейнера, заполнение, обработка и удаление, т.е. как обычно и бывает в приложениях.
Работать будем с данными типа int, дабы сделать их обработку максимально идентичной. Сравнивать будем только релизные билды дефолтной конфигурации используя Visual Studio 2010.
Код будет выполнять следующие действия:
1. Аллоцирование массива\контейнера
2. Заполнение массива\контейнера числами по возрастанию
3. Сортировка массива\контейнера методом пузырька по убыванию (метод выбран самый простой, по скольку мы не сравниваем методы сортировки, а средства реализации)
4. Удаление массива\контейнера
Код была написан несколькими альтернативными методами, отличающимися различными типами контейнеров и методами их аллокации. В самой статье приведу лишь примеры кода, которые как правило, работали максимально быстро для каждого из языков. Остальные же примеры, со вставками для подсчета скорости выполнения,- полностью можно увидеть тут.
Код теста
| С++ HeapArray | С# HeapArray fixed tmp |
 |
 |
Как вы можете убедиться, код достаточно простой и почти идентичный. Поскольку в C# нельзя явно выполнить удаление, время выполнения которого мы хотим измерить, вместо удаления будем использовать items = null; GC.Collect(); при условии что ничего кроме контейнера мы (во всем нашем примере) не создавали, GC.Collect удалить должен бы тоже только контейнер, поэтому думаю это достаточно адекватная замена delete[] items.
Объявление int tmp; за циклом в случае C# экономит время, поэтому рассмотрена именно такая вариация теста для случая C#.
На разных машинах получались разные результаты данного теста (видимо в силу разницы архитектур), однако разницу в производительности кода результаты измерений позволяют оценить.
В измерениях, для подсчета времени выполнения кода, был использован QueryPerformanceCounter, измерялось «время» создания, заполнения, сортировки и удаления на тестовых платформах формах получились следующие результаты:
Из таблиц видно что:
1. Cамая быстрая С# реализация работает медленнее самой быстрой C++ реализации на 30-60% (в зависимости от платформы)
2. Разброс между самой быстрой и самой медленной С++ реализацией 1-65% (в зависимости от платформы)
3. Самая медленная(из рассмотренных конечно) реализация на С#, медленнее самой медленной С++ реализации примерно в 4 раза
4. Больше всего времени занимает этап сортировки (по сему, в дальнейшем рассмотрим его более детально)
Еще стоит обратить внимание на то, что std::vector является медленным контейнером на старых платформах, однако вполне быстрым на современных. А также на то, что время «удаления» в случае первого .Net теста несколько выше, видимо из-за того что кроме тестовых данных удаляются еще какие-то сущности.
Причина разницы производительности С++ и С# кода
Давайте посмотрим на код, который выполняется процессором в каждом случае. Для этого возьмем код сортировки из самых быстрых примеров и посмотрим во что он компилируется, смотреть будем используя отладчик Visual Studio 2010 и режим disassembly, в результате для сортировки увидим следующий код:
| С++ | С# |
| for(int i=0;i<10000;i++) 00F71051 xor ebx,ebx 00F71053 mov esi,edi for(int j=i;j<10000;j++) 00F71055 mov eax,ebx 00F71057 cmp ebx,2710h 00F7105D jge HeapArray+76h (0F71076h) 00F7105F nop { if(items[i] < items[j]) 00F71060 mov ecx,dword ptr [edi+eax*4] 00F71063 mov edx,dword ptr [esi] 00F71065 cmp edx,ecx 00F71067 jge HeapArray+6Eh (0F7106Eh) { int tmp = items[j]; items[j] = items[i]; 00F71069 mov dword ptr [edi+eax*4],edx items[i] = tmp; 00F7106C mov dword ptr [esi],ecx for(int j=i;j<10000;j++) 00F7106E inc eax 00F7106F cmp eax,2710h 00F71074 jl HeapArray+60h (0F71060h) for(int i=0;i<10000;i++) 00F71076 inc ebx 00F71077 add esi,4 00F7107A cmp ebx,2710h 00F71080 jl HeapArray+55h (0F71055h) } } |
int tmp; for (int i = 0; i < 10000; i++) 00000076 xor edx,edx 00000078 mov dword ptr [ebp-38h],edx for (int j = i; j < 10000; j++) 0000007b mov ebx,dword ptr [ebp-38h] 0000007e cmp ebx,2710h 00000084 jge 000000BB 00000086 mov esi,dword ptr [edi+4] { if (items[i] < items[j]) 00000089 mov eax,dword ptr [ebp-38h] 0000008c cmp eax,esi 0000008e jae 000001C2 00000094 mov edx,dword ptr [edi+eax*4+8] 00000098 cmp ebx,esi 0000009a jae 000001C2 000000a0 mov ecx,dword ptr [edi+ebx*4+8] 000000a4 cmp edx,ecx 000000a6 jge 000000B0 000000a8 mov dword ptr [edi+ebx*4+8],edx items[i] = tmp; 000000ac mov dword ptr [edi+eax*4+8],ecx for (int j = i; j < 10000; j++) 000000b0 add ebx,1 000000b3 cmp ebx,2710h 000000b9 jl 00000089 for (int i = 0; i < 10000; i++) 000000bb inc dword ptr [ebp-38h] 000000be cmp dword ptr [ebp-38h],2710h 000000c5 jl 0000007B } } |
Что мы тут можем увидеть?
19 инструкций C++ против 23 на С#, разница не большая, но в купе с прочей оптимизацией, думаю она может объяснить причину большего времени выполнения C# кода.
В C# реализации также некоторые вопросы вызывает
jae 000001C2, который выполняет переход
на 000001c2 call 731661B1
Который видимо также и влияет на разницу во времени выполнения, внося дополнительные задержки.
Другие сравнения производительности
Стоит отметить что есть и другие статьи, где измеряли производительность С++ и С#. Из тех, что попадались мне, самой содержательной показалась Head-to-head benchmark: C++ vs .NET
Автор этой статьи, в некоторых тестах «подыграл» C# запретив использовать SSE2 для С++, поэтому некоторые результаты С++ тестов с плавающей стали примерно в два раза медленнее чем были бы с включенным SSE2. В статье можно найти и другую критику методологии автора, среди которой очень субъективный выбор контейнера для теста в С++.
Однако не принимая в расчет тесты с плавающей точкой без SSE2, и делая поправку на ряд других особенностей методики тестирования, результаты, полученные в статье, стоит рассмотреть.
По результатам измерений можно сделать ряд интересных выводов:
1. Дебажный билд С++ заметно медленнее релизного, при том что разница дебажного и релизного билда С# менее существенна
2. Производительность C# под .Net Framework заметно(более 2х раз) выше чем производительность под Mono
3. Для С++ вполне можно найти контейнер который будет работать медленнее подобного контейнера для C#, и никакая оптимизация не поможет это побороть кроме как использование другого контейнера
4. Некоторые операции работы с файлом в С++ заметно медленнее аналогов в С#, однако их альтернативы столь же заметно быстрее аналогов С#.
Если подводить итоги и говорить о Windows, то статья приходит примерно к похожим результатам: код С# медленнее С++ кода, примерно на 10-80%
Много ли это -10..-80%?
Допустим при разработке на С# мы всегда будем использовать наиболее оптимальное решение, что потребует от нас очень неплохих навыков. И предположим мы будем укладываться в суммарные 10..80% потерь производительности производительности. Чем это нам грозит? Попробуем сравнить эти проценты с другими показателями характеризующими производительность.
Например, в 1990-2000 годах, одно-поточная производительность процессора росла за год примерно на 50%. А начиная с 2004 года темпы роста производительности процессоров упали, и составляли лишь 21% в год, по крайней мере до 2011 года.
A Look Back at Single-Threaded CPU Performance
Ожидаемые показатели роста производительности весьма туманны. Вряд ли в 2013 и 2014 годах был показан рост выше 21%, более того, вполне вероятно что в будущем рост ожидается еще ниже. По крайней мере, планы Intel по осваиванию новых технологий с каждым годом все скромнее…
Другое направление для оценки,- это энергоэффективность и дешевизна железа. Например тут можно увидеть, что говоря о топовом железе +50% одно-поточной производительности может в 2-3 раза удорожать стоимость процессора.
C точки же зрения энергоэфективности и шума — сейчас вполне реально собрать экономичный PC на пассивном охлаждении, однако придется пожертвовать производительностью, и эта жертва вполне может быть около 50% и более производительности относительно прожорливого и горячего, но производительного железа.
Как будет расти производительность процессоров точно не известно, однако по оценкам видно что в случае 21% роста производительности в год, приложение на С#, может отставать по производительности на 0.5-4 года относительно приложения на С++. В случае, например 10% роста, — отставание уже будет 1-8 лет. Однако, реальное приложение может отставать намного меньше, ниже рассмотрим почему.
Я пока не берусь оценивать рентабельность жертвы 10..80% производительности ради получения экономии на разработке. Очевидно, что эта рентабельность зависит от стоимости получения этих 10..80% другими способами (т.е. за счет железа). Однако наметившаяся тенденция показывает, что каждый следующий процент производительности железа будет дороже предыдущего, что, вполне вероятно, рано или поздно приведет к ситуации, когда дешевле будет получить дополнительную производительность оптимизируя код.
Какая же все-таки реальная оценка?
С одной стороны вы вряд-ли будете писать столь оптимальный чтобы всегда показывать максимальную производительность.
Но с другой стороны, что более важно: сколько runtime (времени выполнения) вашей программы будет занимать ваш код, а сколько код системы?
Например если код занимает 1% времени выполнения приложения или сервиса, то даже 10-ти кратное падение производительности этого кода, не очень сильно повлияло бы на скорость работы приложения, и удар по производительности был бы лишь около 10%.
Но совсем другое дело когда около 100% времени выполнения приложения занимает выполнение вашего кода, а не кода ОС. В этом случае вы легко можете получить и -80% и большие потери производительности.
Выводы
Конечно из всего выше написанного не следует что нужно срочно переходить с С# на С++. Во первых разработка на C# дешевле, а во вторых для ряда задач производительность современных процессоров избыточна, и даже оптимизация в рамках C# не является нужной. Но мне кажется важным обратить внимание на накладные расходы т.е плату за использование managedсреды, и оценку этих расходов. Очевидно что в зависимости от рыночных условий и возникающих задач, эта плата может оказаться значимой. Другие аспекты сравнения С# и С++, можно найти в моей предыдущей статье Выбор между C++ и C#.

