Написал Стивен Тови в 2:29 утра по программированию (шутка юмора Google Translate)
Вступление от себя: эта заметка, прорекламированная Алёной C++, предназначена в основном разработчикам игр для консолей, но будет, наверное, полезна и всем, кому приходится сталкиваться с экстремальным аллоцированием динамической памяти. Возможно, любители посравнивать управление памятью в C++ и Java тоже найдут над чем задуматься.
Оригинал с небезынтересной дискуссией в комментариях: altdevblogaday.org/2011/02/12/alternatives-to-malloc-and-new
Обязательная вступительная басня
Мне очень нравятся суши. Это вкусно и удобно. Мне нравится, что можно с бухты-барахты, не тратя целый обеденный час, зайти в суши-ресторан с конвейером, занять место и взять что-то свежее и вкусное с ленты. Но при всём при этом, чего мне реально не хотелось бы, так это быть официантом в суши-ресторане, особенно если бы моей обязанностью было бы рассаживать посетителей по местам.
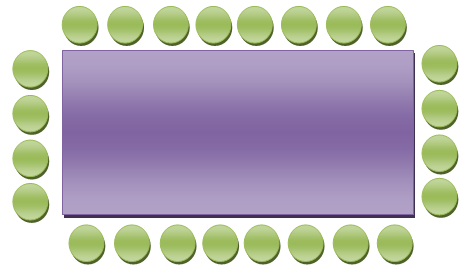
Заходит компания их трёх человек и просит показать им места. Довольный приходом посетителей, ты любезно их усаживаешь. Не успевают они присесть и положить себе немного вкусных Текка Маки, как дверь снова открывается, и заходят ещё четверо! Тебе сегодня везёт, как утопленнику, парень! Ресторан теперь выглядит так…
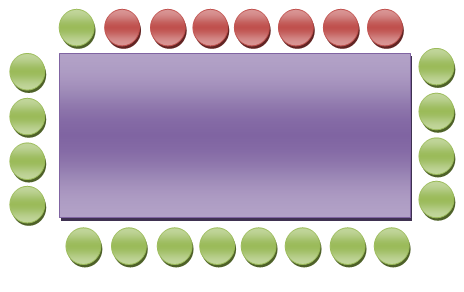
Так как время обеденное, ресторан быстро заполняется до отказа. Наконец, поглотив всё что смогла, и оплатив счёт, первая компашка (те которых трое) уходит, а взамен заходит парочка и ты предлагаешь новым посетителям вновь освободившиеся места. Так случается несколько раз и наконец ресторан выглядит так…
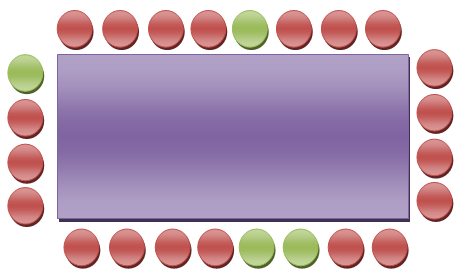
И тут приходят четыре человека и просят усадить их. Прагматичный по натуре, ты тщательно отслеживал, сколько осталось свободных мест, и смотри, сегодня твой день, четыре места есть! Есть одно «но»: эти четверо жутко социальные и ходят сидеть рядом. Ты отчаянно оглядываешься, но хоть у тебя и есть четыре свободных места, усадить эту компанию рядом ты не можешь! Просить уже имеющихся посетителей подвинуться посреди обеда было бы грубовато, поэтому, к сожалению, у тебя нет другого выбора, кроме как дать новым от ворот поворот, и они, возможно, никогда не вернутся. Всё это ужасно печально. Если вы там гадаете, как эта басня относится к разработке игр, читайте дальше. В наших программах мы должны управлять памятью. Память — это драгоценный ресурс, которым нужно тщательно управлять, как и местами в нашем метафорическом суши-ресторане. Каждый раз, когда мы динамически выделяем память, мы резервируем место в штуке, называемой «кучей». В C и C++, обычно это делается, соответственно, при помощи функции malloc и оператора new. Продолжая нашу тухловатую аналогию (больше не буду, обещаю!) это похоже на то, как наши бесстрашные компашки едоков просят показать им их места. Но вот что по-настоящему фигово, так это то, что наш гипотетический сценарий случается и при работе с памятью, и последствия его гораздо хуже, чем пара пустых животиков. Это называется фрагментацией, и это кошмар!
Что же не так с malloc и new?
К сожалению, на этом рыбацкие басни заканчиваются и дальнейший текст будет о malloc и new, и о том, почему они имеют очень ограниченное применение в контексте встроенных систем (таких как игровые консоли). Несмотря на то, что фрагментация является лишь одним аспектом проблем, связанных с динамическим выделением памяти, она является, пожалуй, самым серьезным. Но прежде, чем мы придумаем альтернативные варианты, мы должны взглянуть на все проблемы:
- malloc и new пытаются быть всем в одном флаконе для всех программистов...
Они выделят вам несколько байтов ровно тем же способом, что и несколько мегабайтов. Они не имеют понятия о том, что это за данные, место для которых они вам выделяют и какой у данных будет цикл жизни. Иными словами, у них нет той более широкой картины, которая есть у программистов. - Относительно плохая производительность...
Выделение памяти при помощи стандартных библиотечных функций или операторов обычно требует звонков в ядро. Это может оказывать на производительность вашего приложения всякого рода неприятные побочные воздействия, включая очистку буферов ассоциативной трансляции, копирование блоков памяти, и т.д. Уже этой причины достаточно для того, чтоб использование динамического распределения памяти стало очень дорогим с точки зрения производительности. Стоимость операций free или delete в некоторых схемах выделения памяти также может быть высокой, так как во многих случаях делается много дополнительной работы для того, чтобы попытаться улучшить состояние кучи перед последующими размещениями. «Дополнительная работа» является довольно расплывчатым термином, но она может означать объединение блоков памяти, а в некоторых случаях может означать проход всего списка областей памяти, выделенной вашему приложению! Это точно не то, на что вы хотели бы быть тратить драгоценные циклы процессора, если есть возможность этого избежать! - Они являются причиной фрагментации кучи...
Если вы никогда не работали над проектом, страдающим от проблем, связанных с фрагментацией, то считайте что вам очень повезло, но остальные-то мужики знают, что фрагментация кучи может быть полным и абсолютным кошмаром. - Отслеживание динамически выделенной памяти может быть непростой задачей...
Вместе с динамическим выделением в подарок приходит неизбежный риск утечки памяти. Я уверен, что мы все знаем, что такое утечки памяти, но если нет, то почитайте тут. Большинство студий строят инфраструктуру поверх своих динамических размещений, чтобы отслеживать, какая память и где используется. - Плохая локальность ссылок...
В сущности, нет никакого способа узнать, где та память, которую вернёт вам malloc или new, будет находиться по отношению к другим областям памяти в вашем приложении. Это может привести к тому, что у нас будет больше дорогостоящих промахов в кеше, чем нам нужно, и мы в концов будем танцевать в памяти как на углях. Так какая же есть альтернатива? Цель этой заметки — дать вам информацию (и чуток кода!) о нескольких различных альтернативах, которые можно использовать вместо malloc и new, дабы побороться с только что оглашёнными проблемами.
Скромный линейный аллокатор
Название этого раздела как бы намекает, что этот аллокатор, безусловно, самый простой из всех тех, которые я собираюсь представить, хотя по правде говоря, все они простые (и это делает их прекрасными). Линейный аллокатор, по существу, предполагает отсутствие мелочного освобождения выделенных ресурсов памяти и линейным способом выделяет куски памяти один за другим из фиксированного пула. Смотрите на картинку.
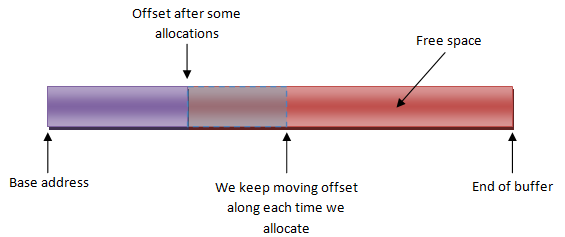
Хороший пример, где линейный аллокатор оказывается чрезвычайно полезным, можно найти практически везде при программировании синергетического процессора. Постоянность локальных данных за рамками текущей выполняемой задачи не важна, и во многих случаях количество данных, приходящих в локальное хранилище (по крайней мере данных, несколько варьирующихся в размерах) является достаточно ограниченным. Однако, не обманывайтесь, это далеко единственное его применение. Вот пример того, как можно было бы реализовать простой линейный аллокатор в С.
/** Header structure for linear buffer. */ typedef struct _LinearBuffer { uint8_t *mem; /*!< Pointer to buffer memory. */ uint32_t totalSize; /*!< Total size in bytes. */ uint32_t offset; /*!< Offset. */ } LinearBuffer; /* non-aligned allocation from linear buffer. */ void* linearBufferAlloc(LinearBuffer* buf, uint32_t size) { if(!buf || !size) return NULL; uint32_t newOffset = buf->offset + size; if(newOffset <= buf->totalSize) { void* ptr = buf->mem + buf->offset; buf->offset = newOffset; return ptr; } return NULL; /* out of memory */ }
Применяя битовые операции к значению смещения во время выделения памяти можно поддержать выровненное аллоцирование. Оно может быть очень полезным, но знайте, что в зависимости от размера данных, которые вы размещаете в вашем буфере (а в некоторых случаях от порядка, в котором сделаны размещения), вы можете заполучить неиспользуемое пространство между выделенной памятью в буфере. Для выравниваний разумного размера это, как правило, приемлемо, но может стать чрезмерно расточительным, если вы выделяете память, с гораздо большим выравниванием, например по 1 Мб. В таких ситуациях порядок размещения объектов в линейном аллокаторе может оказать радикальное влияние на количество неиспользуемой памяти. Всё, что нужно сделать для сброса аллокатора (возможно, в конце уровня), это установить значение смещения в ноль. Как и всегда при работе с динамической памятью, клиенты аллокатора должны быть уверены в том, что у них нет указателей на память, которую вы таким способом деаллоцируете, иначе вы рискуете аллокатор сломать. У всех C++ объектов, которые вы разместили в буфере, нужно будет вручную вызвать деструктор.
Стек
Несколько оговорок прежде чем начать рассказывать об этом аллокаторе. Когда я говорю о «стековом аллокаторе» в данном конкретном случае, я не говорю о стеке вызовов, однако, как мы увидим позже, тот стек играет важную роль в избавлении от динамического выделения памяти из кучи. Так о чем тогда я говорю? Описанный выше линейный аллокатор является отличным решением для многих задач выделения памяти, но что, если вы хотите немного больше контроля над тем, как вы освобождаете свои ресурсы? Его вам даст стековый аллокатор. Ближе к концу описания линейного аллокатора я отметил, что для его сброса вы можете просто установить смещение в ноль, что освободит все ресурсы аллокатора. Принцип установки конкретного значения смещения является базовым, используемым в реализации стекового аллокатора. Если вы не знакомы с понятием стека, как структуры данных, то, вероятно, сейчас самое время, чтобы это сделать, например здесь. Сделали? Прекрасно. С каждым куском памяти, выделенным нашим стековым аллокатором будет опционально проассоциирован указатель на состояние стекового аллокатора непосредственно перед аллоцированием. Это означает, что если мы восстановим это состояние аллокатора (путем изменения его смещения) мы фактически 'освободим' память, которую можно будет повторно использовать. Это показано на диаграмме ниже.
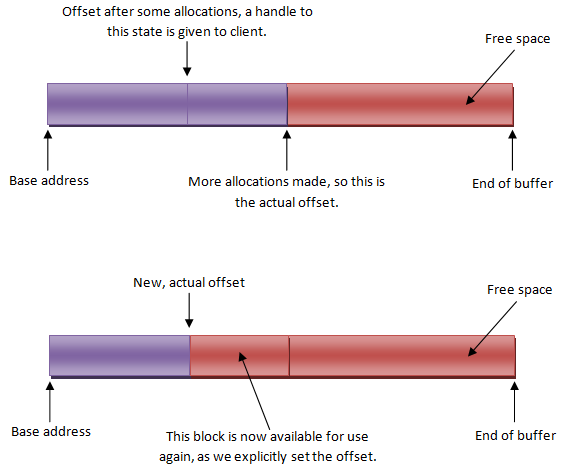
Это может быть очень полезно, если вы хотите временно выделить память для данных с ограниченным временем жизни. Например, ограниченным временем жизни конкретной функции или подсистемы. Эта стратегия может быть также полезна для таких вещей как ресурсы уровня, у которых чётко определен порядок освобождения (обратный порядку размещения). Вот небольшой пример на C, иллюстрирующий только что сказанное
typedef uint32_t StackHandle; void* stackBufferAlloc(StackBuffer* buf, uint32_t size, StackHandle* handle) { if(!buf || !size) return NULL; const uint32_t currOffset = buf->offset; if(currOffset + size <= buf->totalSize) { uint8_t* ptr = buf->mem + currOffset; buf->offset += size; if(handle) *handle = currOffset; /* set the handle to old offset */ return (void*)ptr; } return NULL; } void stackBufferSet(StackBuffer* buf, StackHandle handle) { buf->offset = handle; return; }
Двусторонний стек
Если вы осилили описанную выше концепцию стека, то мы можем перейти к двустороннему стеку. Он похож на стековый аллокатор, за исключением того, что в нём два стека, из которых один растёт из нижней части буфера вверх, а другой растёт из верхней части буфера вниз. Смотрите картинку:
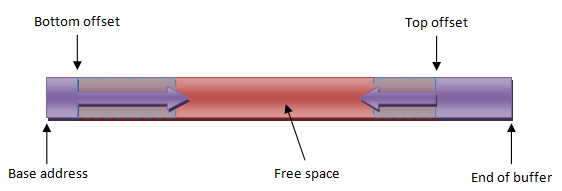
Где это можно использовать? Хорошим примером была бы любая ситуация, где у вас есть данные схожего типа, но с совершенно разным временем жизни, или если бы у вас были данные, которые были бы тесно связаны и должны быть размещены в одной и той же области памяти, но имеют разный размер. Следует отметить, что место, где встретятся смещения двух стеков, не фиксировано. В частности, стеки не должны обязательно занимать половину буфера каждый. Нижний стек может вырастать до очень больших размеров, а верхний быть меньше, и наоборот. Для того, чтоб использовать буфер памяти наилучшим образом, эта дополнительная гибкость может быть иногда необходима. Думаю, вы не нуждаетесь в советах Капитана О., и не буду приводить тут примеры кода для аллокатора с двусторонним стеком, так как он, естественно, похож на уже обсуждённый односторонний стековый аллокатор.
Пул
Мы сейчас немного сместим фокус с семьи описанных выше аллокаторов, основанных на линейных перемещениях указателей или смещений и перейдём к несколько иным вещам. Пуловый аллокатор, про который я сейчас буду рассказывать, предназначен для работы с данными одинакового типа или размера. Он делит подконтрольный ему буфер памяти на сегменты одинакового размера, а затем позволяет клиенту по его желанию выделять и освобождать эти куски (см. диаграмму ниже). Для этого он должен постоянно отслеживать свободные сегменты, и мне известны несколько способов реализации этого. Я лично избегаю реализаций, использующих стек индексов (или указателей) на свободные сегменты, из-за того что им нужно дополнительное место, что часто может быть непозволительно, но они вообще есть. Реализация, про которую я здесь расскажу, не требует дополнительного места для управления свободными сегментами в пуле. На самом деле, в служебной структуре данных этого аллокатора есть всего два поля, что делает его самым маленьким из всех аллокаторов, описанных в этой заметке.
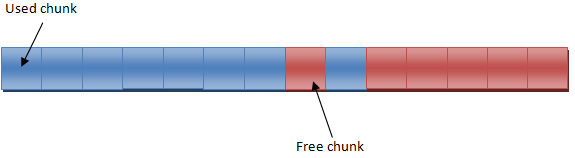
Так как же это работает? Для управления свободными сегментами мы будем использовать структуру данных, известную как связанный список. Опять же, если вы с этой структурой данных не знакомы, то попробуйте прочитать это. Имея опыт с PlayStation3 и Xbox360, где доступ к памяти дорог я в общем считаю структуры данных, основанные на узлах (например, связанный список) довольно мрачными, но я думаю, что это, пожалуй, одно из тех их применений, которые я одобряю. По сути в служебной структуре аллокатора будет находиться указатель на связанный список. Сам же связанный список размазан по всему пулу, занимая то же пространство, что и свободные сегменты в буфере памяти. Когда мы инициализируем аллокатор, мы проходим через сегменты буфера и записываем в первых четырёх (или восьми) байтах каждого сегмента указатель с адресом следующего свободного сегмента. Заголовок же указывает на первый элемент в этом списке. Некоторым ограничением, накладываемым хранением указателей в свободных сегментах пула является то, что размер сегмента должен быть не меньше размера указателя на целевом железе. См. диаграмму ниже.
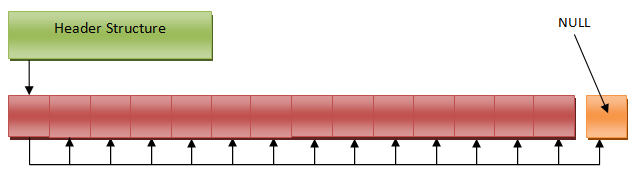
При выделении памяти из пула нужно просто передвинуть указатель на голову связанного списка в заголовке на второй элемент списка, а затем вернуть указатель на первый элемент. Это очень просто, при выделении памяти мы всегда возвращаем первый элемент в связанном списке. Аналогичным образом, когда мы освобождаем сегмент и возвращаем его в пул, мы просто вставляем его в голову связанного списка. Вставка освобождаемого сегмента в голову, а не в хвост, имеет несколько преимуществ: в первую очередь мы не должны проходить связанный список (или хранить дополнительный указатель на хвост в заголовке) и во-вторых (и это более важно), у узла, только что освобождённого, больше шансов остаться в кеше при последующих размещениях. После нескольких выделений и освобождений памяти ваш пул может стать похожим на такой:
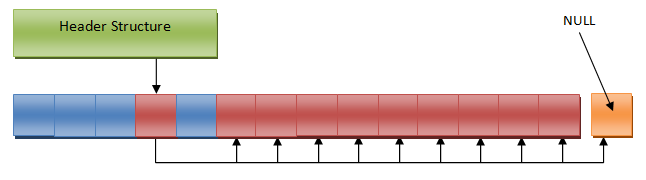
Вот чуток кода на C для инициализации аллокатора и операций выделения и освобождения памяти.
/* allocate a chunk from the pool. */ void* poolAlloc(Pool* buf) { if(!buf) return NULL; if(!buf->head) return NULL; /* out of memory */ uint8_t* currPtr = buf->head; buf->head = (*((uint8_t**)(buf->head))); return currPtr; } /* return a chunk to the pool. */ void poolFree(Pool* buf, void* ptr) { if(!buf || !ptr) return; *((uint8_t**)ptr) = buf->head; buf->head = (uint8_t*)ptr; return; } /* initialise the pool header structure, and set all chunks in the pool as empty. */ void poolInit(Pool* buf, uint8_t* mem, uint32_t size, uint32_t chunkSize) { if(!buf || !mem || !size || !chunkSize) return; const uint32_t chunkCount = (size / chunkSize) - 1; for(uint32_t chunkIndex=0; chunkIndex<chunkCount; ++chunkIndex) { uint8_t* currChunk = mem + (chunkIndex * chunkSize); *((uint8_t**)currChunk) = currChunk + chunkSize; } *((uint8_t**)&mem[chunkCount * chunkSize]) = NULL; /* terminating NULL */ buf->mem = buf->head = mem; return; }
Пара слов о стековых размещениях (alloca вам в помощь)
Если вы помните, ранее я сказал, что упомяну о стековых размещениях в контексте стека вызовов. Я уверен, что вы видели код, который концептуально выглядит примерно так:
myFunction() { myTemporaryMemoryBuffer = malloc(myMemorySize); /* обработка, не выходящая за пределы этой функции */ free (myTemporaryMemoryBuffer); }
Большинство компиляторов C поддерживает функцию, которая должна означать (в зависимости от размера выделяемой памяти), что вам не придется прибегать к выделениям памяти в куче на временные буферы такого рода. Эта функция alloca. Внутреннее устройство alloca зависит от архитектуры, но по сути она выполняет выделение памяти путем настройки стекового кадра вашей функции, что позволяет вам записывать данные в область стека вызовов. Это может быть просто перемещение указателя стека (совсем как в линейном аллокаторе, упомянутом в начале). Память, выделенная вам функцией alloca, освобождается при выходе из функции. Есть, однако, несколько подводных камней, о которых надо знать при использовании alloca. Не забывайте проверять размер запрашиваемой памяти, чтоб быть уверенным в том, что вы не просите стек сумасшедшего размера. Если ваш стек переполнится, последствия будут неприятными. По этой же причине, если вы думаете над тем, чтоб выделить большой кусок памяти при помощи alloca, лучше знать все места, откуда ваша функция будет вызываться в контексте общего потока программы. Использование alloca может повлиять на переносимость в некоторых ограниченных случаях (очевидно), но я еще не сталкивался с компилятором, который бы её не поддерживал.
Дальнейшие подробности вы можете найти в вашем любимом поисковике.
И напоследок...
Часто память, выделяемая в ходе выполнения задачи является временной и сохраняется только на время жизни одного кадра. Для борьбы с неприятными последствиями фрагментации в системах с ограниченной памятью важно использовать эту информацию и размещать память такого рода в отдельных буферах. Сработает любая из вышеперечисленных схем аллоцирования, но я бы, наверное, предложил попробовать одну из линейных, так как их гораздо легче сбрасывать, чем пул. Noel Llopis рассказал больше подробностей на эту тему в этой отличной заметке. То, какой аллокатор лучше всего подходит именно вам, зависит от многих факторов, и от того, что требует та задача, которую вы пытаетесь решить. Я бы посоветовал тщательно подумать о шаблонах выделения и освобождения памяти, которые вы планируете делать в вашей системе, подумать о размерах и времени жизни выделяемой памяти и попытаться управлять ею аллокаторами, имеющими смысл в заданном контексте. Иногда помогает нарисовать распределение памяти на бумаге (да, карандашом и всё такое) или набросать график того, какую зависимость использования памяти от времени вы ожидаете. Хотите верите, хотите нет, но это действительно может помочь вам понять, как система производит и получает данные. Если вы это сделаете, то вам будет легче понять, как разделить выделения памяти так, чтоб сделать управление памятью настолько легким, быстрым и нефрагментированным, насколько возможно.
Учтите, что я рассказал тут о всего лишь небольшой подборке простейших стратегий, которые я, как правило, предпочитаю при программировании игр для консольных приставок. Надеюсь, что если вы дочитали аж до сюда и до сих пор такими вещами не занимались, то ваш мозг живёт теперь идеями о написанном в прошлом коде, который мог бы использовать эти методы для смягчения существенных недостатков, связанных с динамическим распределением памяти, или о других стратегиях, которые вы могли бы использовать для решения задач управления ограниченной памятью без динамического распределения.
Заканчивая, я считаю, что программисты должны учитывать последствия динамического выделения памяти, особенно в консольных играх и дважды обдумать использование функции malloc или оператора new. Легко убедить себя, что вы не делаете так уж много аллокаций, а значит большого значения это не имеет, но такой тип мышления распространяется лавиной по всей команде, и приводит к медленной мучительной смерти. Фрагментация и потери в производительности, связанные с использованием динамической памяти, не будучи пресечёнными в зародыше, могут иметь катастрофические трудноразрешаемые последствия в вашем дальнейшем цикле разработки. Проекты, где управление и распределение памяти не продумано надлежащим образом, часто страдают от случайных сбоев после длительной игровой сессии из-за нехватки памяти (которые, кстати, практически невозможно воспроизвести) и стоят сотни часов работы программистов, пытающихся освободить память и реорганизовать её выделение.
Помните: никогда не рано начать задумываться о памяти и когда бы вы ни начали это делать, вы будете жалеть о том что не сделали этого ещё раньше!
Дополнительная информация...
Вот несколько ссылок на схожие темы, или на темы, которые я не смог охватить:
gamesfromwithin.com/start-pre-allocating-and-stop-worrying
en.wikipedia.org/wiki/Circular_buffer
en.wikipedia.org/wiki/Buddy_memory_allocation
www.memorymanagement.org/articles/alloc.html
Спасибо Саре, Джеймин, Ричарду и Дат за вычитку этой бредятины.
Ещё от переводчика: я не разработчик игр, поэтому переводы специфических терминов могут быть не очень правильными. Например, я понятия не имею, что такое синергетический процессор :) Переводить игру английских слов тоже было непросто, но надеюсь, что получился не самый плохой вариант.

