
Этот мануал написан для желающих попробовать гибкость и удобство распределенного файлового хранилища Ceph в виртуальной среде на домашнем ПК. Сразу поясню, что 10 минут — это время на разворачивание самого кластера (установка и настройка Ceph на виртуальных машинах). Но на создание и клонирование виртуальных машин и на установку ОС потребуется отдельное время.
К концу статьи у нас будет виртуальный кластер из трех машин, и сам ПК с Windows в качестве клиента хранилища. Следом мы скинем туда фотографии котиков, уроним одну ноду, потом поднимем, уроним другую, скачаем обратно фотографии котиков, обрадуемся.
Кто еще не в теме Ceph, можно прочитать вводную статью Знакомство с Ceph в картинках и посмотреть модное промо от производителя.
Мой стенд был таким:
Параметры ПК
Процессор: i5-6500
Память: 16 GB (но в теории должно хватить и 8 GB)
Диск: обычный домашний HDD с 100 GB свободного места
ОС: Windows 7 x64
Параметры виртуальных машин (все три одинаковые)
Процессор: 1 ядро
Память: 1024 MB
Подсеть: 192.168.1.0/24
Диски: 4 виртуальных диска по 10 GB (1 под ОС, 3 под хранилище)
ОС: Ubuntu Server 16.04.2 x64
Хочу напомнить, что цель эксперимента — попробовать возможности и создать платформу для дальнейших ритуалов. Но в виду того, что 9 виртуальных дисков (системные диски не считаем) находятся на одном физическом, не стоит ожидать какой-то приемлемой производительности от этой системы. Производительность будет крайне низкая, но вполне себе достаточная для тестов.
План
— Создаем виртуальную машину cn1 (ceph-node-1)
— Устанавливаем ОС, настраиваем
— Делаем два клона (cn2 и cn3), меняем IP-адреса
— Поднимаем кластер Ceph
— Настраиваем iSCSI-target на одной из машин
— Подключаем Windows в качестве клиента
— Пробуем заливать/скачивать/удалять файлы, ронять ноды
Создаем виртуальную машину
Параметры виртуальной машины указаны выше. Для хранилища я создавал preallocated диски без сплитов. VMWare подсеть можно взять NAT с DHCP. В дальнейшем у нас должно получиться так:
192.168.1.11 — cn1 (тут будет еще iSCSI-target)
192.168.1.12 — cn2
192.168.1.13 — cn3
192.168.1.1 — Клиент (iSCSI-initiator)
Шлюз/маска: 192.168.1.2 / 255.255.255.0
Установка и настройка ОС
Этот мануал должен работать на Ubuntu Server 16.04.2, на других версиях или дистрибутивах некоторые настройки будут отличаться.
Все настройки я буду производить от рута с простым паролем. И тут я обязательно должен погрозить пальцем и упомянуть, что в целях безопасности на боевом кластере так лучше не делать.
Устанавливаем ОС:
Монтаж
Теперь когда ОС установлена, загружаемся в нее и проверяем выданный адрес:
ip -4 addr | grep inet
У меня выдался 192.168.1.128. Подключаемся на него по SSH. Зададим пароль для root:
sudo su passwd root
Настроим сетевой интерфейс (на этом моменте нас выкинет с SSH, ибо IP сменился):
cd /etc/network cp interfaces interfaces.BAK IFACE=ens32 ADDR=192.168.1.11 MASK=255.255.255.0 GW=192.168.1.2 sed -i "s/iface $IFACE inet dhcp/iface $IFACE inet static\naddress $ADDR\nnetmask $MASK\ngateway $GW\ndns-nameservers $GW/g" interfaces ip addr flush to 192.168.1.0/24 && ip addr add $ADDR/24 dev $IFACE
Как мне теперь это развидеть?
По мере чтения листингов вы можете сталкиваться с не особо читаемыми однострочниками, которые призваны сократить количество ручных правок, дабы больше пользоваться прямым копипастом из статьи в терминал. Но я буду приводить расшифровки.
Кроме того, я до конца не разобрался в проблеме, но в 16 убунте имеется некий конфуз с настройкой сетевых интерфейсов (хотя на 14 замечательно работает). Призываю взрослых админов осветить эту тему в комментариях. Отсюда танцы с ip addr flush/add.
Суть проблемы в том, что при рестарте демона добавляется новый secondary адрес, а старый не удаляется, при этом ip addr delete вместо удаления конкретного, удаляет все адреса (в 14 убунте удаляет один). Никто с этим не заморачивается, потому как старый адрес никого не беспокоит, но в нашем случае с клонами старый адрес нужно удалять обязательно, иначе чуда не произойдет. Ребут машины помогает, но это плохой выход.
Кроме того, я до конца не разобрался в проблеме, но в 16 убунте имеется некий конфуз с настройкой сетевых интерфейсов (хотя на 14 замечательно работает). Призываю взрослых админов осветить эту тему в комментариях. Отсюда танцы с ip addr flush/add.
Суть проблемы в том, что при рестарте демона добавляется новый secondary адрес, а старый не удаляется, при этом ip addr delete вместо удаления конкретного, удаляет все адреса (в 14 убунте удаляет один). Никто с этим не заморачивается, потому как старый адрес никого не беспокоит, но в нашем случае с клонами старый адрес нужно удалять обязательно, иначе чуда не произойдет. Ребут машины помогает, но это плохой выход.
Подключаемся по новому адресу (192.168.1.11) и разрешаем подключаться к машине с рутом:
su cd /etc/ssh/ cp sshd_config sshd_config.BAK sed -i "s/PermitRootLogin.*/PermitRootLogin yes/g" sshd_config
Расшифровка
В файле /etc/ssh/sshd_config ищем директиву PermitRootLogin и выставляем ей yes
Выставляем имя хоста и имена хостов-соседей:
HOSTNAME=cn1 echo $HOSTNAME > /etc/hostname sed -i "s/127.0.1.1.*/127.0.1.1\t$HOSTNAME/g" /etc/hosts echo " # Ceph-nodes 192.168.1.11 cn1 192.168.1.12 cn2 192.168.1.13 cn3" >> /etc/hosts
Расшифровка
В файле /etc/hostname прописываем имя хоста cn1.
В файле /etc/hosts меняем имя к записи 127.0.1.1 на cn1, если при установке операционки было указано иное. Также добавляем имена ко всем нодам кластера в конец файла.
В файле /etc/hosts меняем имя к записи 127.0.1.1 на cn1, если при установке операционки было указано иное. Также добавляем имена ко всем нодам кластера в конец файла.
После смены адреса возможно потребуется default-маршрут, без которого мы не сможем поставить нужные пакеты. Из пакетов обязательно нужно поставить ntp, чтобы синхронизировать время на всех нодах. В htop удобно смотреть глазами на демонов Ceph и их потоки.
ip route add default via 192.168.1.2 dev ens32 apt update apt install mc htop ntp -y
Все готово, первая машина получила ось, необходимые пакеты и настройки, которые по наследству достанутся клонам. Выключаем машину:
shutdown -h now
Делаем клонов, настраиваем сеть
На этом месте делаем снапшот машины и создаем два полных клона с указанием этого снапшота. Так выглядит рождение машин cn2 и cn3. Поскольку клоны полностью унаследовали настройки ноды cn1, мы имеем три машины с одинаковыми IP-адресами. Посему включаем их по очереди в обратном порядке, попутно меняя IP-адреса на правильные.
Включаем cn3
Запускаем машину, подключаемся с рутом по SSH на 192.168.1.11, меняем настройки интерфейса на 192.168.1.13, после чего отвалится SSH-сессия по старому адресу:
HOST_ID=3 echo cn$HOST_ID > /etc/hostname sed -i "s/127.0.1.1.*/127.0.1.1\tcn$HOST_ID/g" /etc/hosts sed -i "s/address.*/address 192.168.1.1$HOST_ID/g" /etc/network/interfaces ip addr flush to 192.168.1.0/24 && ip addr add 192.168.1.1$HOST_ID/24 dev ens32
Расшифровка
Меняем имя хоста в файле /etc/hostname, меняем имя к записи 127.0.1.1 в файле /etc/hosts, снимаем все адреса вида 192.168.1.0/24 с интерфейсов и навешиваем правильный.
Включаем cn2
На cn3 к этому моменту уже правильный адрес, а на cn2 все еще 192.168.1.11, подключаемся на него и делаем аналогичную настройку для адреса 192.168.1.12:
HOST_ID=2 echo cn$HOST_ID > /etc/hostname sed -i "s/127.0.1.1.*/127.0.1.1\tcn$HOST_ID/g" /etc/hosts sed -i "s/address.*/address 192.168.1.1$HOST_ID/g" /etc/network/interfaces ip addr flush to 192.168.1.0/24 && ip addr add 192.168.1.1$HOST_ID/24 dev ens32
Расшифровка
Листинг отличается от предыдущего лишь первой строкой
Теперь когда не осталось конфликтующих адресов, а сессия с cn2 отвалилась,
Включаем cn1.
Подключаемся на 192.168.1.11, и впредь всю работу мы будем делать на этой ноде (включая управление остальными нодами). Для этого мы сгенерируем SSH-ключи и разложим их по всем нодам (это не мой каприз, к этому призывает сам Ceph). В процессе нужно будет вводить пароли и кивать головой на его вопросы:
# генерируем ключ cn1 с параметрами по умолчанию, включая все секретные фразы ssh-keygen # раскладываем ключ cn1 на все ноды for node_id in 1 2 3; do ssh-copy-id cn$node_id; done # подключаемся с cn1 на cn2, генерируем ключ, раскладываем ключ cn2 на все ноды ssh cn2 ssh-keygen for node_id in 1 2 3; do ssh-copy-id cn$node_id; done exit # возвращаемся на cn1 # идем на cn3 ssh cn3 # подключаемся с cn1 на cn3, генерируем ключ, раскладываем ключ cn3 на все ноды ssh-keygen for node_id in 1 2 3; do ssh-copy-id cn$node_id; done exit # возвращаемся на cn1
Таким образом мы привели подсеть кластера к тому состоянию, которое было описано в начале статьи. Все узлы имеют root-доступ на своих соседей без пароля *грозит пальцем*
Кластер еще как бы не кластер, но уже готов к кластеризации, так сказать. Однако, прежде чем выстрелить
Поднимаем кластер Ceph
10 минут пошли…
Запускаем все машины и подключаемся к cn1 по SSH. Для начала установим на все ноды ceph-deploy, который призван упростить установку и настройку некоторых компонентов кластера. Затем создадим кластер, установим дистрибутив Ceph на все ноды, добавим в кластер три монитора (можно и один, но тогда падение монитора будет равнозначно падению всего кластера) и наполним хранилище дисками.
# устанавливаем ceph-deploy на все ноды: for node_id in 1 2 3; do ssh cn$node_id apt install ceph-deploy -y; done # создаем каталог для конфигов Ceph: mkdir /etc/ceph cd /etc/ceph # Создаем новый кластер: ceph-deploy new cn1 cn2 cn3 # Устанавливаем дистрибутив Ceph на машины: ceph-deploy install cn1 cn2 cn3 # Создаем мониторы, указанные при создании кластера: ceph-deploy mon create-initial # После перехода Ubuntu на systemd # именно демоны мониторов почему-то автоматически не добавляются в автостарт, # поэтому добавляем их в systemd руками: for node_id in 1 2 3; do ssh cn$node_id systemctl enable ceph-mon; done # Очищаем и готовим диски к добавлению в кластер: ceph-deploy disk zap {cn1,cn2,cn3}:{sdb,sdc,sdd} # без магии это выглядит так: # ceph-deploy disk zap cn1:sdb cn1:sdc cn1:sdd cn2:sdb cn2:sdc cn2:sdd cn3:sdb cn3:sdc cn3:sdd # Превращаем диски в OSD и создаем соответствующие демоны: ceph-deploy osd create {cn1,cn2,cn3}:{sdb,sdc,sdd}
Кластер почти готов, проверяем его состояние командой ceph -s или ceph status:
root@cn1:/etc/ceph# ceph -s cluster 0cb14335-e366-48df-b361-3c97550d6ef4 health HEALTH_WARN too few PGs per OSD (21 < min 30) monmap e1: 3 mons at {cn1=192.168.1.11:6789/0,cn2=192.168.1.12:6789/0,cn3=192.168.1.13:6789/0} election epoch 6, quorum 0,1,2 cn1,cn2,cn3 osdmap e43: 9 osds: 9 up, 9 in flags sortbitwise,require_jewel_osds pgmap v107: 64 pgs, 1 pools, 0 bytes data, 0 objects 308 MB used, 45672 MB / 45980 MB avail 64 active+clean
Ключевая строка в этом отчете — это health, и оно находится в состоянии HEALTH_WARN. Это лучше, чем HEALTH_ERR, потому что так у нас хотя бы кластер работает, хотя и не очень. А сразу под HEALTH_WARN написано, почему же оно _WARN, а именно: «too few PGs per OSD (21 < min 30)», что говорит нам о необходимости увеличить количество плейсмент-групп так, чтобы на один OSD приходилось минимум 21 PG. Тогда умножаем 9 OSD на 21 и получаем 189, затем округляем до ближайшей степени двойки и получаем 256. В то время как текущее количество PG=64, что ясно видно в строке pgmap. Все это описано в документации Ceph.
В таком случае удовлетворяем требование кластера и делаем это:
PG_NUM=256 ceph osd pool set rbd pg_num $PG_NUM ceph osd pool set rbd pgp_num $PG_NUM
Даем системе несколько секунд на перестроение карты и проверяем состояние кластера вновь:
root@cn1:/etc/ceph# ceph -s cluster 0cb14335-e366-48df-b361-3c97550d6ef4 health HEALTH_OK monmap e1: 3 mons at {cn1=192.168.1.11:6789/0,cn2=192.168.1.12:6789/0,cn3=192.168.1.13:6789/0} election epoch 6, quorum 0,1,2 cn1,cn2,cn3 osdmap e50: 9 osds: 9 up, 9 in flags sortbitwise,require_jewel_osds pgmap v151: 256 pgs, 1 pools, 0 bytes data, 0 objects 319 MB used, 45661 MB / 45980 MB avail 256 active+clean
Видим заветное HEALTH_OK, что говорит нам о том, что кластер здоров и готов к работе.
По умолчанию фактор репликации пула равен 3 (прочитать про переменные size и min_size можно в вводной статье). Это значит, что каждый объект хранится в трех экземплярах на разных дисках. Давайте на это посмотреть глазами:
root@cn1:/etc/ceph# ceph osd pool get rbd size size: 3 root@cn1:/etc/ceph# ceph osd pool get rbd min_size min_size: 2
Теперь снизим size до 2, а min_size до 1 (в продакшене так настоятельно рекомендуется не делать! Но в рамках виртуального стенда это должно повысить производительность)
ceph osd pool set rbd size 2 ceph osd pool set rbd min_size 1
Что дальше? Дальше нужно испробовать кластер в работе.
Совершить акт файлообмена с кластером можно одним из трех всем известных способов (блочное устройство, файловая система и объектное хранилище). Windows 7 из коробки предпочитает традиционный iSCSI, а стало быть наш способ — блочное устройство. В таком случае нам нужно установить iSCSI-target на какую-нибудь ноду (пускай это будет cn1).
Установка и настройка iSCSI-target
Нам нужен не простой target, а с поддержкой RBD (Rados Block Device). Сгодится пакет tgt-rbd, поэтому устанавливаем оный на cn1:
apt install tgt-rbd -y # проверяем наличие поддержки rbd: tgtadm --lld iscsi --mode system --op show | grep rbd rbd (bsoflags sync:direct) # видим, что поддерживается
Ceph по умолчанию создает пул rbd для блочных устройств, в нем мы и создадим rbd-образ:
rbd create -p rbd rbd1 --size 4096 --name client.admin --image-feature layering # где rbd - имя пула, rbd1 - имя образа, 4096 - размер в мегабайтах
Теперь попросим таргет отдать образ rbd1 для любого IP-адреса, записав это в конфиг:
echo '<target virtual-ceph:iscsi> driver iscsi bs-type rbd backing-store rbd/rbd1 # Format: <pool_name>/<rbd_image_name> initiator-address ALL </target>' > /etc/tgt/conf.d/ceph.conf # сразу рестартуем таргет: systemctl restart tgt
Смотрим на секундомер: 8 минут. Уложились.
Подключаем ПК с Windows по iSCSI
Винда снабжена встроенной утилитой iscsicpl.exe, которая поможет нам подключить образ rbd1 в качестве локального диска. Запускаем и идем на вкладку «Конечные объекты». Вводим в поле «Объект» IP-адрес ноды cn1 (192.168.1.11) и нажимаем «Быстрое подключение». Если мы все настроили правильно, то в списке будет наш iSCSI-target. Выбираем его и подключаемся.
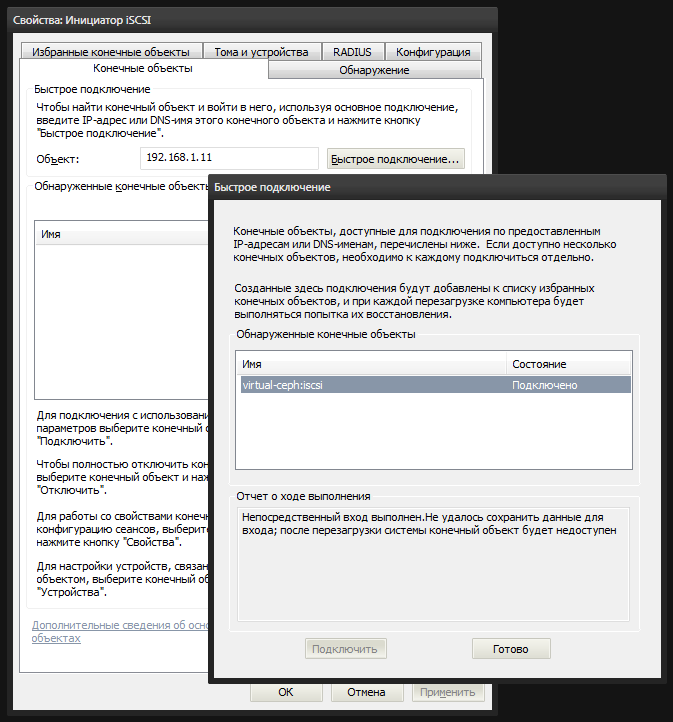
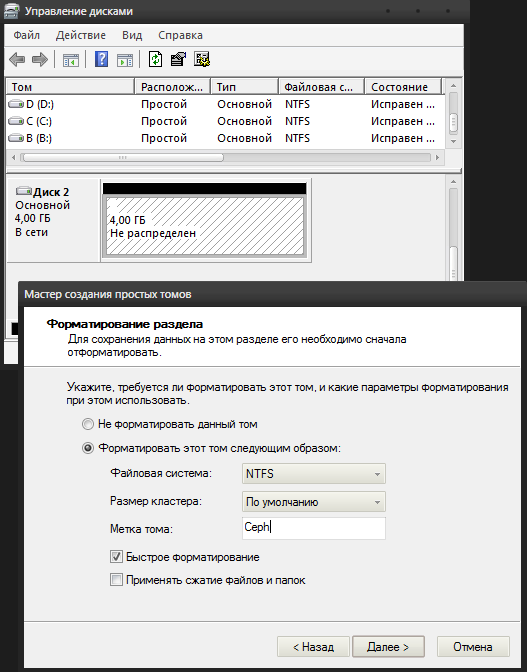
После чего в системе появится неразмеченный диск. В консоли управления дисками diskmgmt.msc мы видим новое 4-гиговое устройство. Нужно создать на нем раздел и отформатировать, пометив его как Ceph.
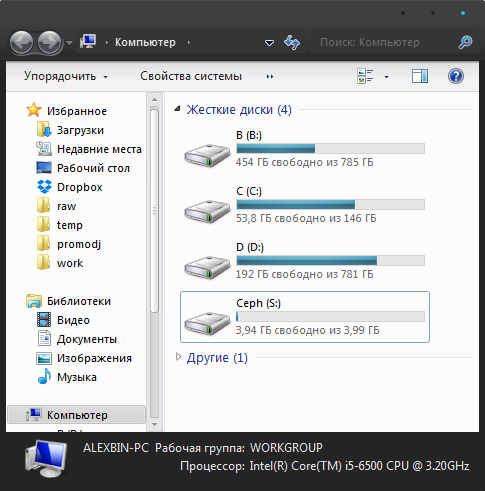
Теперь можно зайти в мой компьютер и возрадоваться на результат.
Испытания
Пришло время наполнить кластер фотографиями котиков. В качестве фотографий котиков я буду использовать 4 образа дистрибутивов убунты разных версий, которые попались под руку, общим объемом 2.8 гигабайта.
Пробуем залить их на наш новый локальный диск. Как можно сначала ошибочно заметить, что файлы заливаются быстро, однако это всего лишь заполнение буферов, из которых данные постепенно будут записываться на физические диски кластера. В моем случае первые 3 файла по 700-800 мегабайт улетели быстро, а последний приуныл, и скорость упала до ожидаемой.
Если на ноде кластера выполнить команду ceph -w, то можно следить за состоянием кластера в реальном времени. Чтение/запись данных, отвал диска, ноды или мониторов, все это отображается в этом логе в реальном времени.
Можете ронять и поднимать ноды по очереди, главное не ронять cn1 (потому что на нем единственный iSCSI-target без мультипассинга) и не ронять две ноды сразу. Но если повысить обратно size до 3, то и это можно будет себе позволить.
Настало время вандализма: попробуйте уронить ноду cn3, нажав кнопку стоп в VMWare, наблюдая в ceph -w на cn1. Сначала мы увидим, как кластер забеспокоится о том, что некоторые OSD уже долго не отвечают:
osd.6 192.168.1.13:6800/6812 failed (2 reporters from different host after 21.000229 >= grace 20.000000) osd.7 192.168.1.13:6804/7724 failed (2 reporters from different host after 21.000356 >= grace 20.000000) osd.8 192.168.1.13:6808/8766 failed (2 reporters from different host after 21.000715 >= grace 20.000000) osdmap e53: 9 osds: 6 up, 9 in
В течение 5 минут кластер будет пребывать в состоянии надежды, что диски все же одумаются и вернутся. Но через 5 минут (таково значение по умолчанию), кластер смирится с утратой и начнет ребалансировку данных с дохлых OSD, размазывая недостающие объекты по другим дискам, предварительно пометив не отвечающие OSD как отвалившиеся (out) и поправив карту плейсмент-групп:
osd.6 out (down for 300.042041) osd.7 out (down for 300.042041) osd.8 out (down for 300.042041)
Пока ребалансировка не завершена, ceph -s будет показывать состояние HEALTH_WARN, однако файлы будут доступны, но не без потери в производительности, да. В причине HEALTH_WARN будет написано это:
health HEALTH_WARN 102 pgs degraded 102 pgs stuck unclean recovery 677/1420 objects degraded (47.676%) 1 mons down, quorum 0,1 cn1,cn2
Дальше продолжайте без меня.

