Большинство людей значительную часть времени каждый день проводят за клавиатурой на мобильном устройстве: составляя письма, сообщения в чатах, социальных сетях и т. д. Однако мобильные клавиатуры всё ещё довольно нескладные. Средний пользователь печатает с мобильной клавиатуры примерно на 35% медленнее, чем с физической. Чтобы изменить это, мы недавно представили много замечательных улучшений в Gboard for Android. Мы стремимся создать умный механизм, который позволяет быстрее вводить текст, в то же время предлагая подсказки и исправляя ошибки, на любом языке на ваш выбор.
Учитывая факт, что мобильная клавиатура преобразует прикосновения в текст примерно так же, как система распознавания речи транслирует голос в текст, мы применили систему Speech Recognition. Сначала мы создали надёжные пространственные модели, которые сопоставляют нечёткие последовательности прикосновений к таскрину с клавишами клавиатуры, точно как акустические модели сопоставляют последовательности звуковых фрагментов с фонетическими единицами. Затем мы создали мощный движок декодирования, основанный на конечных преобразователях (FST) для определения самой вероятной фразы для данной последовательности прикосновений. Мы знали, что с его математическим формализмом и широким успехом в голосовых приложениях FST-декодер обеспечит необходимую гибкость для поддержки всего разнообразия сложных вариантов ввода, а также языковые функции. В данной статье мы расскажем подробно, что входило в разработку обеих этих систем.
Ввод с мобильной клавиатуры подвержен ошибкам, которые обычно называют «толстый палец» (или трассировка пространственно похожих слов в скользящем наборе, как показано ниже), а также ошибкам моторики и когнитивным ошибкам (что проявляется в опечатках, вставке лишних символов, пропущенных символах или перемене символов местами). Умная клавиатура должна учитывать эти ошибки и предсказывать подразумеваемое слово быстро и точно. По существу, мы создали пространственную модель для Gboard, которая устраняет эти ошибки на уровне символов, сопоставляя точки прикосновения на экране с реальными клавишами.
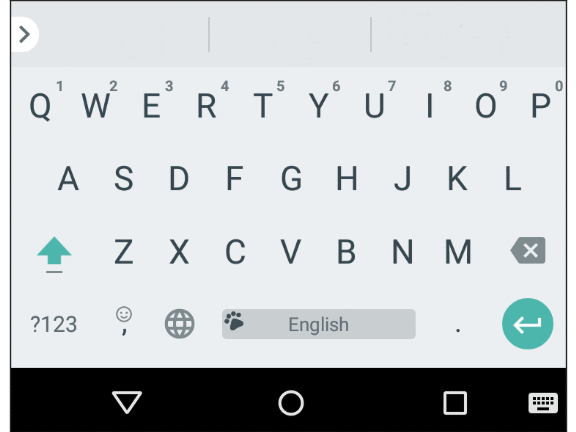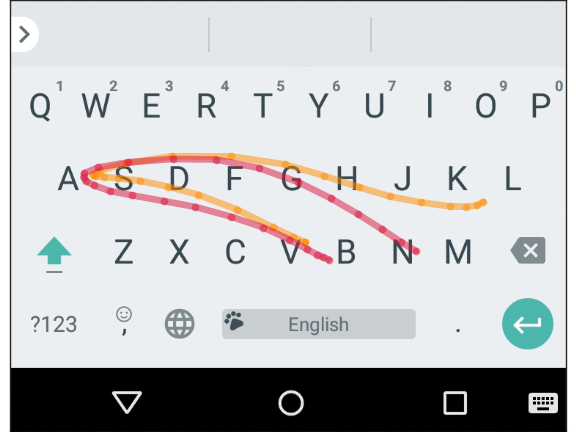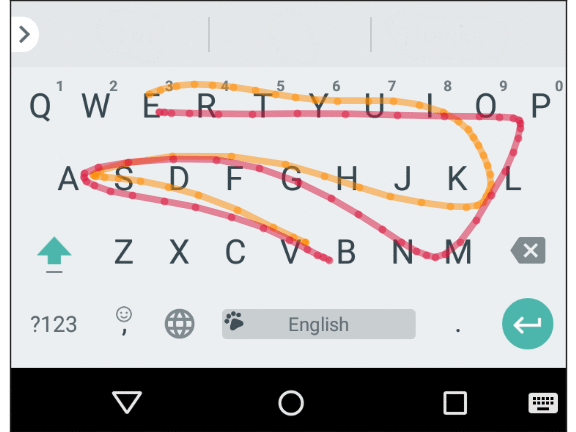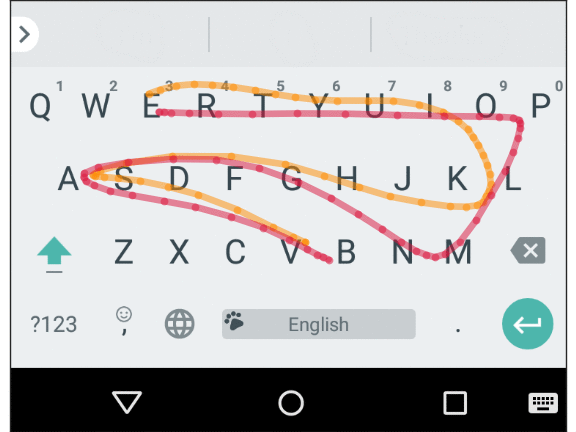
Средняя траектория для двух пространственно похожих слов: “Vampire” и “Value”
До недавнего времени в Gboard использовались 1) гауссовская модель для определения вероятности нажатия соседних клавиш; 2) основанная на правилах модель для представления ошибок моторики и когнитивных ошибок. Эти модели были простыми и интуитивными, но не позволяли напрямую оптимизировать метрики, которые коррелируют с лучшим качеством набора. Опираясь на наш опыт с акустическими моделями Voice Search, мы заменили и гауссовую модель, и основанную на правилах модель на единственную высокоэффективную модель долгой краткосрочной памяти (LSTM), обученную с критерием ассоциативной скоротечной классификации (connectionist temporal classification, CTC).
Однако обучение этой модели оказалось гораздо сложнее, чем мы предполагали. В то время как акустические модели обучались на аудиоданных с сопроводительным текстом, подготовленным человеком, было сложно подготовить сопроводительный текст для миллионов последовательностей нажатий на тачскрин и траекторий движения пальцев по клавиатуре. Так что разработчики использовали сигналы взаимодействия от самих пользователей — исправленные автокоррекции и выборы подсказок — как негативные и положительные сигналы в обучении с частичным привлечением учителя (semi-supervised learning). Так были сформированы обширные наборы данных для обучения и тестирования.
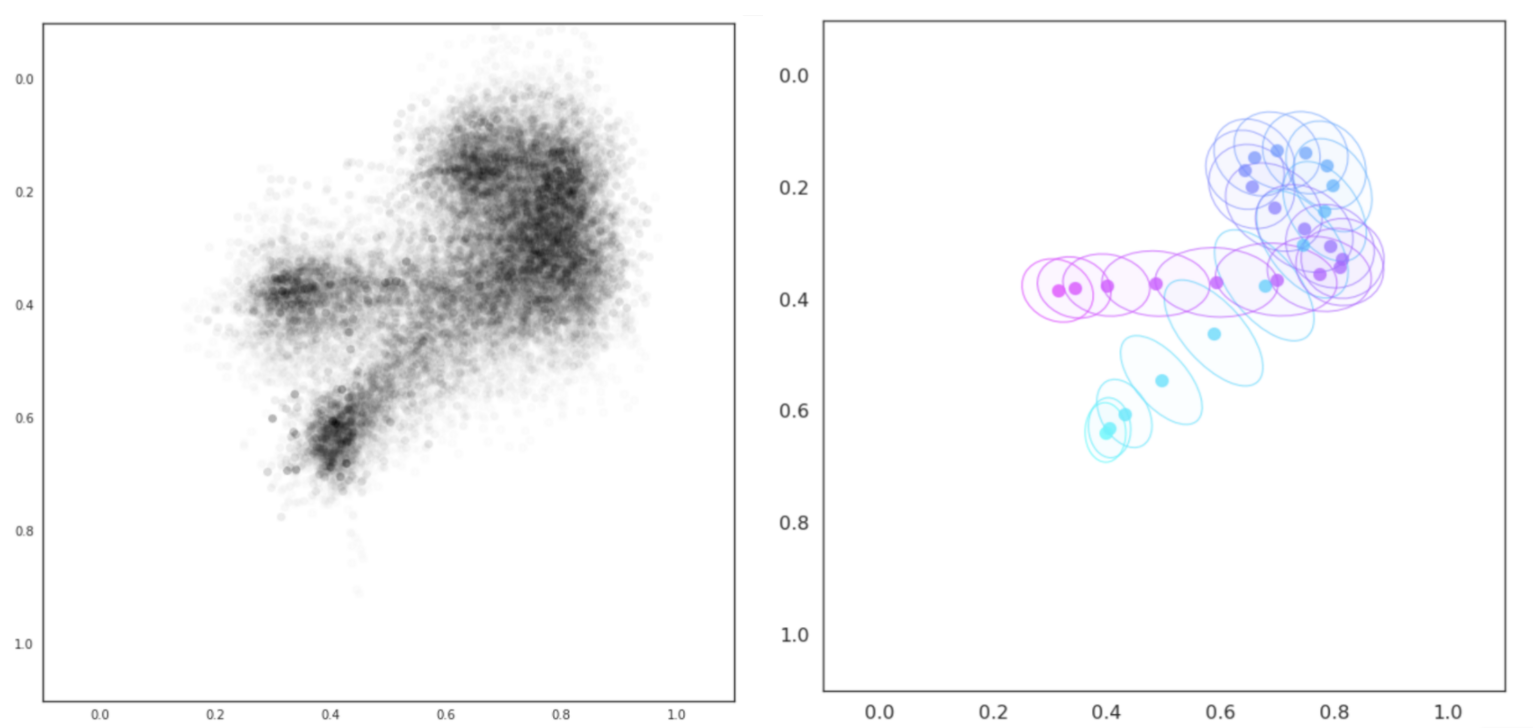
Исходные точки данных, соответствующие слову “could” (слева) и нормализованные отобранные траектории с отклонениями по выборке (справа)
Методом перебора было испробовано множество техник из литературы по распознаванию речи на нейронных пространственных моделях (NSM), чтобы сделать их достаточно компактными и быстрыми для работы на любом устройстве. Сотни моделей обучались на инфраструктуре TensorFlow, оптимизируя различные сигналы с клавиатуры: автодополнения, подсказки, скольжения по тачскрину и др. После более года работы готовые модели стали примерно в 6 раз быстрее и в 10 раз компактнее, чем исходные версии. У них также примерно на 15% сократилось количество неправильных автоисправлений и на 10% уменьшилось количество неправильно распознанных жестов на офлайновых наборах данных.
В то время как NSM используют пространственную информацию для помощи в определении нажатий клавиш или траекторий движения по клавиатуре, существуют и дополнительные ограничения языка — лексические и грамматические — которые можно использовать. Лексикон говорит нам, какие слова существуют в языке, а вероятностная грамматика — какие слова могут последовать за какими другими. Для кодирования этой информации мы использовали конечные преобразователи (FST). Они давно были ключевым компонентом систем распознавания и синтеза речи Google. FST обеспечивают принципиальный способ представления различных вероятностных моделей (лексиконы, грамматики, нормализаторы и др.) из обработки естественного языка, а также математический фреймворк, необходимый для воздействия, оптимизации, комбинирования и поиска моделей*.
В Gboard преобразователь символов в слова компактно представляет собой лексикон клавиатуры, как показано на иллюстрации внизу. Он кодирует способы преобразования последовательностей клавиш в слова, допуская альтернативные последовательности клавиш и произвольные пробелы.
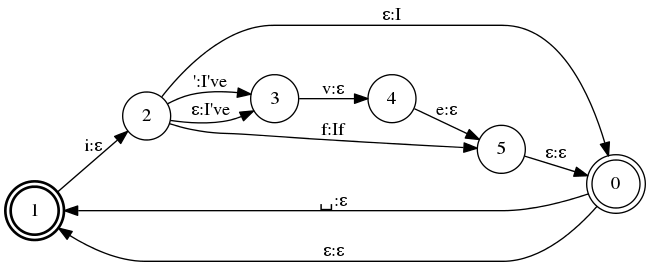
Преобразователь кодирует “I”, “I’ve”, “If” вдоль траекторий от начального состояния (жирный круг с обозначением «1») до конечных состояний (круги в двойном контуре с обозначениями «0» и «1»). Каждая дуга помечена входным значением клавиши (перед двоеточием) и соответствующим результирующим словом (после двоеточия), где ε обозначает пустой символ. Апостроф в “I’ve” может быть опущен. Пользователь иногда может упустить простановку пробела. Чтобы учитывать это, в преобразователе пробел между словами является необязательным. Символ ε и обратные дуги допускают более одного слова.
Вероятностный преобразователь n-грамм используется для представления языковой модели для клавиатуры. Состояние в модели представляет (до) n-1 словарный контекст. Выходящая из этого состояния дуга помечена словом-победителем и вероятностью, с которой оно следует за этим контекстом (исходя из текстовых данных). В сочетании с пространственной моделью, которая выдаёт вероятности последовательностей нажатий по клавишам (дискретные значения в случае отдельных нажатий или непрерывные жесты в скользящем наборе), такая модель используется в алгоритме лучевого поиска.
Общие принципы FST — стриминг, поддержка динамических моделей и прочие — позволили далеко продвинуться в разработке нового декодера клавиатуры. Но необходимо было добавить несколько дополнительных функций. Когда вы говорите вслух, вам не требуется декодер, чтобы догадаться об окончании слова или следующем слове — и сэкономить несколько слогов в речи; но когда вы печатаете, то помощь в автодополнениях и предсказаниях окажется весьма кстати. Также мы хотели, чтобы клавиатура обеспечивала органичную многоязыковую поддержку, как показано ниже.

Трёхъязычный набор в Gboard.
Понадобились сложные усилия, чтобы новый декодер заработал, но принципиальная природа конечных преобразователей имеет много преимуществ. Например, поддержка транслитераций для языков вроде хинди — это простое расширение к базовому декодеру.
Во многих языках со сложными алфавитами были разработаны системы романизации для отображения символов в латинском алфавите, часто в соответствии с их фонетическими произношениями. Например, пиньиньское “xièxiè” соответствует китайским символам “谢谢”(«спасибо»). Пиньиньская клавиатура позволяет удобно набирать слова в раскладке QWERTY и автоматически «переводить» их на нужный алфавит. Таким же способом клавиатура хинди позволяет набрать “daanth” для слова “दांत” («зуб»). В то время как у пиньиня есть общепринятая система романизации, транслитерация хинди не такая ясная. Например, “daant” тоже будет допустимой альтернативой для “दांत”.
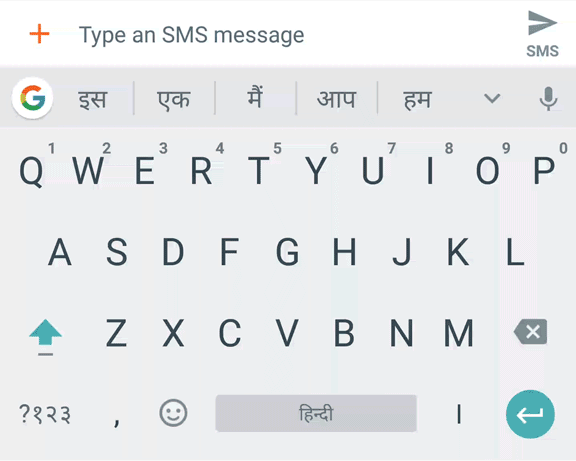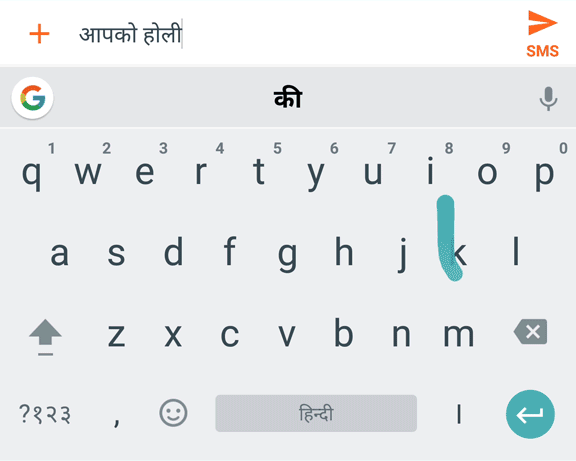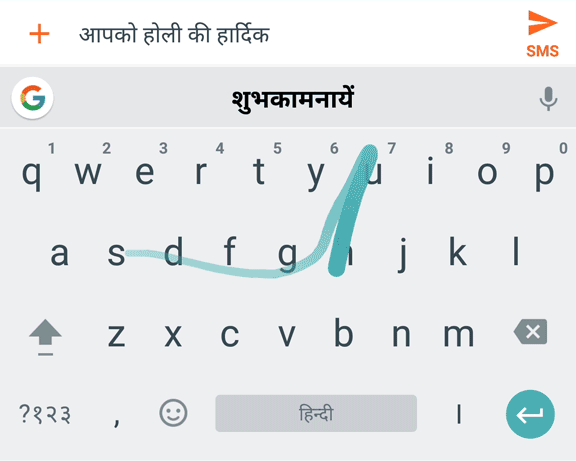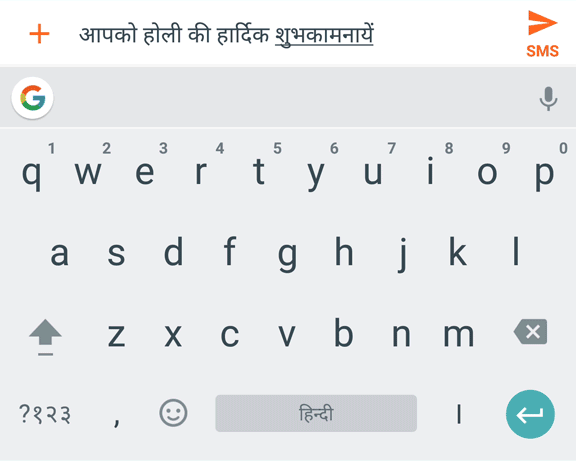
Транслитерация скользящего ввода на хинди
Когда у нас был преобразователь, который преобразует последовательности букв в слова (лексикон) и автоматическая взвешенная языковая модель для последовательностей слов, мы разработали взвешенный преобразователь для преобразования между латинскими последовательностями символов и алфавитами 22 индийских языков. В некоторых языках есть несколько письменностей (например, язык бодо можно записывать бенгальским письмом или на девангари), так что между транслитерацией и нативным написанием мы создали 57 методов ввода всего за несколько месяцев.
Универсальная природа декодера FST позволила нам использовать всю работу, проделанную ранее, для поддержки автодополнений, предсказаний, скользящего набора и многих функций UI без каких-либо дополнительных усилий, так что наши индийские пользователи с самого начала получили отличное качество программы.
В целом, наша последняя работа позволила сократить задержку декодирования на 50%, уменьшила долю слов, которые пользователям приходилось исправлять вручную, на 10%, позволила запустить транслитерацию для 22 официальных языков Индии и привела к появлению многих новых функций, которые вы могли заметить.
Надеемся, что последние изменения помогут вам набирать текст на клавиатуре мобильного устройства. Но мы понимаем, что эта задача ни в коем случае не решена. Gboard по-прежнему может делать предположения, которые кажутся странными или малополезными, а жесты могут распознаваться в слова, которые человек никогда бы не набрал. Однако наш переход к мощным алгоритмам машинного интеллекта открывает новые возможности, которые мы активно изучаем, чтобы создавать более полезные инструменты и продукты для наших пользователей по всему миру.
Эту работу проделали Кирилл Аллаузен, Уайс Альшариф, Ларс Хеллстен, Том Оуян, Брайан Роарк и Дэвид Рыбач, при содействии группы Speech Data Operation. Особая благодарность Йохану Шалквику и Коринне Кортес за их помощь.
* Набор соответствующих алгоритмов доступен в свободной библиотеке OpenFst. ↑
Учитывая факт, что мобильная клавиатура преобразует прикосновения в текст примерно так же, как система распознавания речи транслирует голос в текст, мы применили систему Speech Recognition. Сначала мы создали надёжные пространственные модели, которые сопоставляют нечёткие последовательности прикосновений к таскрину с клавишами клавиатуры, точно как акустические модели сопоставляют последовательности звуковых фрагментов с фонетическими единицами. Затем мы создали мощный движок декодирования, основанный на конечных преобразователях (FST) для определения самой вероятной фразы для данной последовательности прикосновений. Мы знали, что с его математическим формализмом и широким успехом в голосовых приложениях FST-декодер обеспечит необходимую гибкость для поддержки всего разнообразия сложных вариантов ввода, а также языковые функции. В данной статье мы расскажем подробно, что входило в разработку обеих этих систем.
Нейронные пространственные модели
Ввод с мобильной клавиатуры подвержен ошибкам, которые обычно называют «толстый палец» (или трассировка пространственно похожих слов в скользящем наборе, как показано ниже), а также ошибкам моторики и когнитивным ошибкам (что проявляется в опечатках, вставке лишних символов, пропущенных символах или перемене символов местами). Умная клавиатура должна учитывать эти ошибки и предсказывать подразумеваемое слово быстро и точно. По существу, мы создали пространственную модель для Gboard, которая устраняет эти ошибки на уровне символов, сопоставляя точки прикосновения на экране с реальными клавишами.
Средняя траектория для двух пространственно похожих слов: “Vampire” и “Value”
До недавнего времени в Gboard использовались 1) гауссовская модель для определения вероятности нажатия соседних клавиш; 2) основанная на правилах модель для представления ошибок моторики и когнитивных ошибок. Эти модели были простыми и интуитивными, но не позволяли напрямую оптимизировать метрики, которые коррелируют с лучшим качеством набора. Опираясь на наш опыт с акустическими моделями Voice Search, мы заменили и гауссовую модель, и основанную на правилах модель на единственную высокоэффективную модель долгой краткосрочной памяти (LSTM), обученную с критерием ассоциативной скоротечной классификации (connectionist temporal classification, CTC).
Однако обучение этой модели оказалось гораздо сложнее, чем мы предполагали. В то время как акустические модели обучались на аудиоданных с сопроводительным текстом, подготовленным человеком, было сложно подготовить сопроводительный текст для миллионов последовательностей нажатий на тачскрин и траекторий движения пальцев по клавиатуре. Так что разработчики использовали сигналы взаимодействия от самих пользователей — исправленные автокоррекции и выборы подсказок — как негативные и положительные сигналы в обучении с частичным привлечением учителя (semi-supervised learning). Так были сформированы обширные наборы данных для обучения и тестирования.
Исходные точки данных, соответствующие слову “could” (слева) и нормализованные отобранные траектории с отклонениями по выборке (справа)
Методом перебора было испробовано множество техник из литературы по распознаванию речи на нейронных пространственных моделях (NSM), чтобы сделать их достаточно компактными и быстрыми для работы на любом устройстве. Сотни моделей обучались на инфраструктуре TensorFlow, оптимизируя различные сигналы с клавиатуры: автодополнения, подсказки, скольжения по тачскрину и др. После более года работы готовые модели стали примерно в 6 раз быстрее и в 10 раз компактнее, чем исходные версии. У них также примерно на 15% сократилось количество неправильных автоисправлений и на 10% уменьшилось количество неправильно распознанных жестов на офлайновых наборах данных.
Конечные преобразователи
В то время как NSM используют пространственную информацию для помощи в определении нажатий клавиш или траекторий движения по клавиатуре, существуют и дополнительные ограничения языка — лексические и грамматические — которые можно использовать. Лексикон говорит нам, какие слова существуют в языке, а вероятностная грамматика — какие слова могут последовать за какими другими. Для кодирования этой информации мы использовали конечные преобразователи (FST). Они давно были ключевым компонентом систем распознавания и синтеза речи Google. FST обеспечивают принципиальный способ представления различных вероятностных моделей (лексиконы, грамматики, нормализаторы и др.) из обработки естественного языка, а также математический фреймворк, необходимый для воздействия, оптимизации, комбинирования и поиска моделей*.
В Gboard преобразователь символов в слова компактно представляет собой лексикон клавиатуры, как показано на иллюстрации внизу. Он кодирует способы преобразования последовательностей клавиш в слова, допуская альтернативные последовательности клавиш и произвольные пробелы.
Преобразователь кодирует “I”, “I’ve”, “If” вдоль траекторий от начального состояния (жирный круг с обозначением «1») до конечных состояний (круги в двойном контуре с обозначениями «0» и «1»). Каждая дуга помечена входным значением клавиши (перед двоеточием) и соответствующим результирующим словом (после двоеточия), где ε обозначает пустой символ. Апостроф в “I’ve” может быть опущен. Пользователь иногда может упустить простановку пробела. Чтобы учитывать это, в преобразователе пробел между словами является необязательным. Символ ε и обратные дуги допускают более одного слова.
Вероятностный преобразователь n-грамм используется для представления языковой модели для клавиатуры. Состояние в модели представляет (до) n-1 словарный контекст. Выходящая из этого состояния дуга помечена словом-победителем и вероятностью, с которой оно следует за этим контекстом (исходя из текстовых данных). В сочетании с пространственной моделью, которая выдаёт вероятности последовательностей нажатий по клавишам (дискретные значения в случае отдельных нажатий или непрерывные жесты в скользящем наборе), такая модель используется в алгоритме лучевого поиска.
Общие принципы FST — стриминг, поддержка динамических моделей и прочие — позволили далеко продвинуться в разработке нового декодера клавиатуры. Но необходимо было добавить несколько дополнительных функций. Когда вы говорите вслух, вам не требуется декодер, чтобы догадаться об окончании слова или следующем слове — и сэкономить несколько слогов в речи; но когда вы печатаете, то помощь в автодополнениях и предсказаниях окажется весьма кстати. Также мы хотели, чтобы клавиатура обеспечивала органичную многоязыковую поддержку, как показано ниже.
Трёхъязычный набор в Gboard.
Понадобились сложные усилия, чтобы новый декодер заработал, но принципиальная природа конечных преобразователей имеет много преимуществ. Например, поддержка транслитераций для языков вроде хинди — это простое расширение к базовому декодеру.
Модели транслитерации
Во многих языках со сложными алфавитами были разработаны системы романизации для отображения символов в латинском алфавите, часто в соответствии с их фонетическими произношениями. Например, пиньиньское “xièxiè” соответствует китайским символам “谢谢”(«спасибо»). Пиньиньская клавиатура позволяет удобно набирать слова в раскладке QWERTY и автоматически «переводить» их на нужный алфавит. Таким же способом клавиатура хинди позволяет набрать “daanth” для слова “दांत” («зуб»). В то время как у пиньиня есть общепринятая система романизации, транслитерация хинди не такая ясная. Например, “daant” тоже будет допустимой альтернативой для “दांत”.
Транслитерация скользящего ввода на хинди
Когда у нас был преобразователь, который преобразует последовательности букв в слова (лексикон) и автоматическая взвешенная языковая модель для последовательностей слов, мы разработали взвешенный преобразователь для преобразования между латинскими последовательностями символов и алфавитами 22 индийских языков. В некоторых языках есть несколько письменностей (например, язык бодо можно записывать бенгальским письмом или на девангари), так что между транслитерацией и нативным написанием мы создали 57 методов ввода всего за несколько месяцев.
Универсальная природа декодера FST позволила нам использовать всю работу, проделанную ранее, для поддержки автодополнений, предсказаний, скользящего набора и многих функций UI без каких-либо дополнительных усилий, так что наши индийские пользователи с самого начала получили отличное качество программы.
Более умная клавиатура
В целом, наша последняя работа позволила сократить задержку декодирования на 50%, уменьшила долю слов, которые пользователям приходилось исправлять вручную, на 10%, позволила запустить транслитерацию для 22 официальных языков Индии и привела к появлению многих новых функций, которые вы могли заметить.
Надеемся, что последние изменения помогут вам набирать текст на клавиатуре мобильного устройства. Но мы понимаем, что эта задача ни в коем случае не решена. Gboard по-прежнему может делать предположения, которые кажутся странными или малополезными, а жесты могут распознаваться в слова, которые человек никогда бы не набрал. Однако наш переход к мощным алгоритмам машинного интеллекта открывает новые возможности, которые мы активно изучаем, чтобы создавать более полезные инструменты и продукты для наших пользователей по всему миру.
Благодарности
Эту работу проделали Кирилл Аллаузен, Уайс Альшариф, Ларс Хеллстен, Том Оуян, Брайан Роарк и Дэвид Рыбач, при содействии группы Speech Data Operation. Особая благодарность Йохану Шалквику и Коринне Кортес за их помощь.
* Набор соответствующих алгоритмов доступен в свободной библиотеке OpenFst. ↑

