Так вышло, что для получение автомата по программированию бедным первокурам задали одну интересную задачу: написать программу, которая ищет по дереву методом Монте-Карло.
Конечно, всё началось с поиска информации в интернете. На великом и могучем русском языке было всего-лишь пара статей с Хабра, словесно объясняющие суть алгоритма, и статья из Википедии, перенаправляющая на проблему игры Го и компьютера. По мне — уже неплохое начало. Гуглю на английском языке для полноты и натыкаюсь на английскую статью с Википедии, в которой алгоритм так же словесно объясняется.
Немного теории
Метод Монте-Карло для поиска по дереву достаточно давно применяется в играх для искусственного интеллекта. Задача алгоритма — выбрать наиболее выигрышный вариант развития событий. Дерево представляет из себя структуру, в которой помимо хода и указателей есть количество сыгранных и количество выигранных партий. На основе этих двух параметров метод выбирает следующий шаг. Следующее изображение наглядно продемонстрирует работу алгоритма:
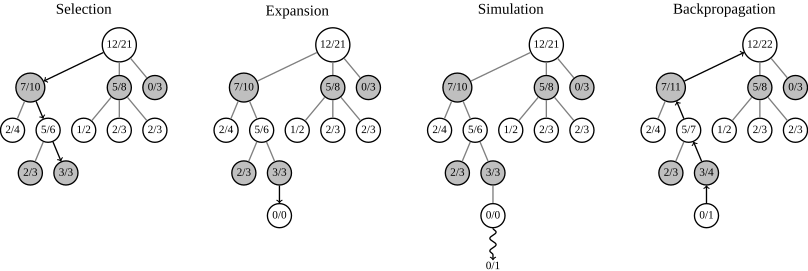
Шаг 1: Выбор — Selection. На этом шаге алгоритм выбирает ход своего противника. Если такой ход существует — мы его выберем, если нет — добавим.
Шаг 2: Расширение — Expansion. К выбранному узлу с ходом противника мы добавим узел со своим ходом и с нулевыми результатами.
Шаг 3: Симуляция — Simulation. Отыграем партию от текущего состояния игрового поля до чей-либо победы. Отсюда мы возьмём только первый ход (т.е. свой ход) и результаты.
Шаг 4: Обратное распространение — Backpropagation. Результаты из симуляции мы будем распространять от текущего до корня. Ко всем родительским узлам мы добавим единицу в количество сыгранных партий, а если мы наткнёмся на узел победителя — то в такой узел мы добавим единицу в количество выигранных партий.
В результате, бот с таким алгоритмом будет делать выигрышные для него ходы.
Собственно, алгоритм не такой сложный. Скорее, объёмный.
Реализация
Алгоритм я решил реализовать в качестве бота для игры Крестики-нолики. Игра простая и для примера подойдёт отлично. Но дьявол кроется в деталях...
Проблема в том, что мы должны отыграть игру на шаге симуляции без реального игрока. Можно было, конечно, заставить алгоритм делать рандомные ходы в таких симуляциях, но мне хотелось какое-нибудь осмысленное поведение.
Тогда был написан простейший бот, который умел только две вещи — мешать игроку и делать рандомные ходы. Для симуляции этого было более чем достаточно.
Как и все, бот с алгоритмом располагал информацией о текущим состоянием поля, состоянием поля с прошлого хода, своим деревом ходов и текущим выбранным узлом в этом дереве. Начну с того, что я найду новый ход оппонента.
// 0. add node with new move. bool exist = false; int enemyx = -1, enemyy = -1; this->FindNewStep ( __field, enemyx, enemyy ); for ( MCBTreeNode * node : this->mCurrent->Nodes ) { if ( node->MoveX == enemyx && node->MoveY == enemyy ) { exist = true; this->mCurrent = node; } } if ( !exist ) { MCBTreeNode * enemymove = new MCBTreeNode; enemymove->Parent = this->mCurrent; enemymove->MoveX = enemyx; enemymove->MoveY = enemyy; enemymove->Player = (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS; this->mCurrent->Nodes.push_back ( enemymove ); this->mCurrent = enemymove; }
Как видно, если есть такой ход противника в дереве, то мы выберем его. Если нет — добавим.
// 1. selection // select node with more wins. MCBTreeNode * bestnode = this->mCurrent; for ( MCBTreeNode * node : this->mCurrent->Nodes ) { if ( node->Wins > bestnode->Wins ) bestnode = node; }
Здесь мы произведем выбор.
// 2. expanding // create new node. MCBTreeNode * newnode = new MCBTreeNode; newnode->Parent = bestnode; newnode->Player = this->mFigure; this->mCurrent->Nodes.push_back ( newnode );
Расширим дерево.
// 3. simulation // simulate game. TTTGame::Field field; for ( int y = 0; y < TTT_FIELDSIZE; y++ ) for ( int x = 0; x < TTT_FIELDSIZE; x++ ) field[y][x] = __field[y][x]; Player * bot1 = new Bot (); bot1->SetFigure ( (this->mFigure == TTT_CROSS) ? TTT_CIRCLE : TTT_CROSS ); Player * bot2 = new Bot (); bot2->SetFigure ( this->mFigure ); Player * current = bot2; while ( TTTGame::IsPlayable ( field ) ) { current->MakeMove ( field ); if ( newnode->MoveX == -1 && newnode->MoveY == -1 ) this->FindNewStep ( field, newnode->MoveX, newnode->MoveY ); if ( current == bot1 ) current = bot2; else current = bot1; }
Сыграем игру между ботами. Думаю, здесь надо немного объясниться: текущее состояние поле копируется и боты доигрывают на этой копии, первым ходит второй бот и его первый ход мы запомним.
// 4. backpropagation. int winner = TTTGame::CheckWin ( field ); MCBTreeNode * currentnode = newnode; while ( currentnode != nullptr ) { currentnode->Attempts++; if ( currentnode->Player == winner ) currentnode->Wins++; currentnode = currentnode->Parent; }
И последнее: получим результат и распространим его вверх по дереву.
// make move... this->mCurrent = newnode; TTTGame::MakeMove ( __field, this->mFigure, mCurrent->MoveX, mCurrent->MoveY );
И в конце мы просто делаем ход и текущим узлом ставим наш новый узел из второго шага.
Заключение
Как видно, алгоритм не такой страшный и сложный. Конечно, моя реализация далека от идеала, но суть и некоторое практическое применение она показывает.
Полный код доступен на моём GitHub.
Всем добра.

