 Как JVM создает новые объекты? Что именно происходит, когда вы пишете
Как JVM создает новые объекты? Что именно происходит, когда вы пишете new Object()?
На конференциях периодически рассказывают, что для аллокации объектов используются TLAB'ы (thread-local allocation buffer): области памяти, выделенные эксклюзивно каждому потоку, создание объектов в которых очень быстрое за счет отсутствия синхронизации.
Но как правильно подобрать размер TLAB'а? Что делать, если нужно выделить 10% от размера TLAB'а, а свободно только 9%? Может ли объект быть аллоцирован вне TLAB'а? Когда (если) обнуляется выделенная память?
Задавшись этими вопросами и не найдя всех ответов, я решил написать статью, чтобы исправить ситуацию.
Перед прочтением полезно вспомнить как работает какой-нибудь сборщик мусора (например, прочитав этот цикл статей).
Введение
Какие шаги необходимы для создания нового объекта?
Прежде всего, необходимо найти незанятую область памяти нужного размера, потом объект нужно иницализировать: обнулить память, инициализировать какие-то внутренние структуры (информация, которая используется при вызове getClass() и при синхронизации на объекте etc.) и в конце нужно вызвать конструктор.
Статья устроена примерно так: сначала попробуем понять, что должно происходить в теории, потом как-нибудь залезем во внутренности JVM и посмотрим, как все происходит на самом деле, а в конце напишем какие-нибудь бенчмарки, чтоб удостовериться наверняка.
Disclaimer: некоторые части сознательно упрощены без потери общности. Говоря о сборке мусора я подразумеваю любой compacting-коллектор, а говоря об адресном пространстве — eden молодого поколения. Для других [стандартных или широко-известных] сборщиков мусора детали могут меняться, но не слишком значительно.
TLAB 101
Первая часть — выделить свободную память под наш объект.
В общем случае эффективная аллокация памяти — задача нетривиальная, полная боли, страданий и драконов. Например, заводятся связные списки для размеров, кратных степени двойки, в них осуществляется поиск и, если нужно, области памяти разрезаются и переезжают из одного списка в другой (aka buddy allocator).
К счастью, в Java-машине есть сборщик мусора, который берет сложную часть работы на себя. В процессе сборки young generation все живые объекты перемещаются в survivor space, оставляя в eden'е один большой непрерывный регион свободной памяти.
Так как память в JVM освобождает GC, то аллокатору нужно лишь знать, где эту свободную память искать, фактически управлять доступом к одному указателю на эту самую свободную память. То есть, аллокация должна быть очень простой и состоять из пони и радуг: нужно прибавить к указателю на свободный eden размер объекта, и память наша (такая техника называется bump-the-pointer).
Память при этом могут выделять несколько потоков, поэтому нужна какая-то форма синхронизации. Если сделать её самым простым способом (блокировка на регион кучи или атомарный инкремент указателя), то выделение памяти запросто может стать узким местом, поэтому разработчики JVM развили предыдущую идею с bump-the-pointer: каждому потоку выделяется большой кусок памяти, который принадлежит только ему. Аллокации внутри такого буфера происходят всё тем же инкрементом указателя (но уже локальным, без синхронизации) пока это возможно, а новая область запрашивается каждый раз, когда текущая заканчивается. Такая область и называется thread-local allocation buffer. Получается эдакий иерархический bump-the-pointer, где на первом уровне находится регион кучи, а на втором TLAB текущего потока. Некоторые на этом остановиться не могут и идут еще дальше, иерархически укладывая буферы в буферы.

Получается, что в большинстве случаев аллокация должна быть очень быстрой, выполняться всего за пару инструкций и выглядеть примерно так:
start = currentThread.tlabTop; end = start + sizeof(Object.class); if (end > currentThread.tlabEnd) { goto slow_path; } currentThread.setTlabTop(end); callConstructor(start, end);
Выглядит слишком хорошо, чтобы быть правдой, поэтому воспользуемся PrintAssembly и посмотрим, во что компилируется метод, который создает java.lang.Object:
; Hotspot machinery skipped mov 0x60(%r15),%rax ; start = tlabTop lea 0x10(%rax),%rdi ; end = start + sizeof(Object) cmp 0x70(%r15),%rdi ; if (end > tlabEnd) ja 0x00000001032b22b5 ; goto slow_path mov %rdi,0x60(%r15) ; tlabTop = end ; Object initialization skipped
Обладая тайным знанием о том, что в регистре %r15 всегда находится указатель на VM-ный поток (лирическое отступление: за счет такого инварианта thread-local'ы и Thread.currentThread() работают очень быстро), понимаем, что это именно тот код, который мы и ожидали увидеть. Заодно заметим, что JIT-компилятор заинлайнил аллокацию прямо в вызывающий метод.
Таким способом JVM почти бесплатно (не вспоминая про сборку мусора) создает новые объекты за десяток инструкций, перекладывая ответственность за очистку памяти и дефрагментацию на GC. Приятным бонусом идет локальность аллоцируемых подряд данных, чего могут не гарантировать классические аллокаторы. Есть целое исследование про влияние такой локальности на производительность типичных приложений. Spoiler alert: делает все немного быстрее даже несмотря на повышенную нагрузку на GC.
Влияние размера TLAB на происходящее
Каким должен быть размер TLAB'а? В первом приближении разумно предположить, что чем меньше размер буфера, тем чаще выделение памяти будет проходить через медленную ветку, а, значит, и TLAB нужно делать побольше: реже ходим в относительно медленную общую кучу за памятью и быстрее создаем новые объекты.
Но существует и другая проблема: внутренняя фрагментация.
Рассмотрим ситуацию, когда TLAB имеет размер 2 мегабайта, eden регион (из которого и выделяются TLAB'ы) занимает 500 мегабайт, а у приложения 50 потоков. Как только место под новые TLAB'ы в куче закончится, первый же поток, у которого кончится свой TLAB, спровоцирует сборку мусора. Если предположить, что TLAB'ы заполняются ± равномерно (в реальных приложениях это может быть не так), то в среднем оставшиеся TLAB'ы будут заполнены примерно наполовину. То есть, при наличии еще 0.5 * 50 * 2 == 50 мегабайт незанятой памяти (аж 10%), начинается сборка мусора. Получается не очень хорошо: существенная часть памяти еще свободна, а GC все равно вызывается.

Если продолжить увеличивать размер TLAB'а или количество потоков, то потери памяти будут расти линейно, и получится, что TLAB ускоряет аллокации, но замедляет приложение в целом, лишний раз напрягая сборщик мусора.
А если место в TLAB'е еще есть, но новый объект слишком большой? Если выбрасывать старый буфер и выделять новый, то фрагментация лишь увеличится, а если в таких ситуациях всегда создавать объект прямо в eden, то приложение начнет работать медленнее, чем могло бы?
В общем, что делать — не очень понятно. Можно захардкодить мистическую константу (как это сделано для эвристик инлайнинга), можно отдать размер на откуп разработчика и тюнить его для каждого приложения индивидуально (невероятно удобно), можно научить JVM как-то отгадывать правильный ответ.
Что делать-то?
Выбирать какую-нибудь константу — занятие неблагодарное, но инженеры Sun не отчаялись и пошли другим путем: вместо указания размера указывается процент фрагментации — часть кучи, которой мы готовы пожертвовать ради быстрых аллокаций, а JVM дальше как-нибудь разберется. Отвечает за это параметр TLABWasteTargetPercent и по умолчанию имеет значение 1%.
Используя всю ту же гипотезу о равномерности выделения памяти потоками, получаем простое уравнение: tlab_size * threads_count * 1/2 = eden_size * waste_percent.
Если мы готовы пожертвовать 10% eden'а, у нас 50 потоков, а eden занимает 500 мегабайт, то в начале сборки мусора 50 мегабайт может быть свободно в полупустых TLAB'ах, то есть в нашем примере размер TLAB'а будет 2 мегабайта.
В таком подходе есть серьезное упущение: используется предположение, что все потоки аллоцируют одинаково, что почти всегда неправда. Подгонять число к скорости аллокации самых интенсивных потоков нежелательно, обижать их менее быстрых коллег (например, scheduled-воркеров) тоже не хочется. Более того, в типичном приложении существуют сотни потоков (например в тредпулах вашего любимого app-сервера), а создавать новые объекты без серьезной нагрузки будут лишь несколько, это тоже нужно как-то учесть. А если вспомнить вопрос "Что делать, если нужно выделить 10% от размера TLAB'а, а свободно только 9%?", то становится совсем неочевидно.
Деталей становится слишком много, чтоб просто их угадать или подсмотреть в каком-нибудь блоге, поэтому пришло время выяснить, как же все устроено на самом деле™: заглянем в исходники хотспота.
Я пользовался мастером jdk9, вот CMakeLists.txt, с которым CLion начинает работать, если захотите повторить путешествие.
Tumbling down the rabbit hole
Интересующий нас файл находится с первого грепа и называется threadLocalAllocBuffer.cpp, который описывает структуру буфера. Несмотря на то, что класс описывает буфер, он создается один раз для каждого потока и переиспользуется при аллокации новых TLAB'ов, заодно в нем же хранятся различные статистики использования TLAB'ов.
Чтоб понять JIT-компилятор, нужно думать как JIT-компилятор. Поэтому сразу пропустим первичную инициализацию, создание буфера для нового потока и вычисление значений по умолчанию и будем смотреть на метод resize, который вызывается для всех потоков в конце каждой сборки:
void ThreadLocalAllocBuffer::resize() { // ... size_t alloc =_allocation_fraction.average() * (Universe::heap()->tlab_capacity(myThread()) / HeapWordSize); size_t new_size = alloc / _target_refills; // ... }
Ага! Для каждого потока отслеживается интенсивность его аллокаций и в зависимости от нее и константы _target_refills (которая заботливо подписана как "количество TLAB'ов, которые хотелось бы, чтоб поток запросил между двумя сборками") высчитывается новый размер.
_target_refills инициализируется один раз:
// Assuming each thread's active tlab is, on average, 1/2 full at a GC _target_refills = 100 / (2 * TLABWasteTargetPercent);
Это ровно та гипотеза, которую мы предполагали выше, только вместо размера TLAB'а вычисляется количество запросов нового TLAB для потока. Чтобы на момент сборки у всех потоков было не более x% свободной памяти, необходимо, чтоб размер TLAB'а каждого потока был 2x% от всей памяти, что он обычно аллоцирует между сборками. Поделив 1 на 2x получается как раз желаемое количество запросов.
Долю аллокаций потока нужно когда-то обновлять. В начале каждой сборки мусора происходит обновление статистики всех потоков, которое находится в методе accumulate_statistics:
- Проверяем, обновил ли поток свой TLAB хотя бы один раз. Незачем пересчитывать размер для потока, который ничего не делает (или, по крайней мере, не аллоцирует).
- Проверяем, была ли использована половина eden'а, чтоб избежать влияния full GC или патологических случаев (например, явный вызов
System.gc()) на расчеты. - В конце концов, считаем, какой процент eden'а потратил поток, и обновляем его долю аллокаций.
- Обновляем статистику того, как поток использовал свои TLAB'ы, как и сколько аллоцировал и сколько памяти потратил впустую.
Чтоб избежать различных нестабильных эффектов из-за частоты сборок и разных паттернов аллокации, связанных с непостоянностью сборщика мусора и желаниями потока, доля аллокаций — не просто число, а экспоненциально взвешенное скользящее среднее, которое поддерживает среднее значение за последние N сборок. В JVM для всего есть свой ключ, и это место не исключение, флаг TLABAllocationWeight контролирует, как быстро среднее "забывает" старые значения (не то, чтоб кто-то хотел менять значение этого флага).
Результат
Полученной информации хватает, чтоб ответить на интересующий нас вопрос про размер TLAB'а:
- JVM знает, сколько памяти она может потратить на фрагментацию. Из этого значения вычисляется число TLAB'ов, которые поток должен запросить между сборками мусора.
- JVM следит за тем, сколько памяти использует каждый поток и сглаживает эти значения.
- Каждый поток получает размер TLAB'а пропорционально используемой им памяти. Тем самым решается проблема неравномерной аллокации между потоками и в среднем все аллоцируют быстро, а тратят памяти впустую мало.

Если у приложения сто потоков, 3 из которых вовсю обслуживают запросы пользователей, 2 по таймеру занимаются какой-то вспомогательной деятельностью, а все остальные простаивают, то первая группа потоков получит большие TLAB'ы, вторая совсем маленькие, а все остальные — значения по умолчанию. И что самое приятное — количество "медленных" аллокаций (запросов TLAB'а) у всех потоков будет одинаковое.
Аллокация в C1
С размерами TLAB'ов разобрались. Чтоб далеко не ходить, поковыряем исходники дальше и посмотрим, как именно выделяются TLAB'ы, когда это быстро, когда медленно, а когда очень медленно.
Тут уже одним классом не обойдешься и надо смотреть, во что оператор new компилируется. Во избежание черепно-мозговых травм смотреть будем код клиентского компилятора (C1): он гораздо проще и понятнее, чем серверный компилятор, хорошо описывает общую картину мира, а так как new штука в Java довольно популярная, то и интересных нам оптимизаций в нем хватает.
Нас интересует два метода: C1_MacroAssembler::allocate_object, в котором описано аллоцирование объекта в TLAB'е и инициализация и Runtime1::generate_code_for, который исполняется, когда быстро выделить память не удалось.
Интересно посмотреть, всегда ли объект может быть создан быстро, и цепочка "find usages" приводит нас к такому вот комментарию в instanceKlass.hpp:
// This bit is initialized in classFileParser.cpp. // It is false under any of the following conditions: // - the class is abstract (including any interface) // - the class has a finalizer (if !RegisterFinalizersAtInit) // - the class size is larger than FastAllocateSizeLimit // - the class is java/lang/Class, which cannot be allocated directly bool can_be_fastpath_allocated() const { return !layout_helper_needs_slow_path(layout_helper()); }
Из него становится понятно, что очень большие объекты (больше 128 килобайт по умолчанию) и finalizeable-классы всегда идут через медленный вызов в JVM. (Загадка — причем тут абстрактные классы?)
Возьмем это на заметку и вернемся обратно к процессу аллокации:
tlab_allocate — попытка быстро аллоцировать объект, ровно тот код, что мы уже видели, когда смотрели на PrintAssembly. Если получилось, то на этом заканчиваем аллокацию и переходим к инициализации объекта.
tlab_refill — попытка выделить новый TLAB. С помощью интересной проверки метод решает, выделять ли новый TLAB (выкинув старый) или аллоцировать объект прямо в eden'е, оставив старый TLAB:
// Retain tlab and allocate object in shared space if // the amount free in the tlab is too large to discard. cmpptr(t1, Address(thread_reg, in_bytes(JavaThread::tlab_refill_waste_limit_offset()))); jcc(Assembler::lessEqual, discard_tlab);
tlab_refill_waste_limitкак раз отвечает за размер TLAB'а, которым мы не готовы пожертвовать ради аллокации одного объекта. По умолчанию имеет значение в1.5%от текущего размера TLAB (для этого конечно же есть параметр —TLABRefillWasteFraction, который внезапно имеет значение 64, а само значение считается как текущий размер TLAB'а, деленный на значение этого параметр). Этот лимит поднимается при каждой медленной аллокации, чтобы избежать деградации в неудачных случаях, и сбрасывается в конце каждого цикла GC. Еще одним вопросом меньше.
- eden_allocate — попытка выделить память (объект или TLAB) в eden'е. Это место очень похоже на аллокацию в TLAB'е: проверяем, есть ли место, и если да, то атомарно, используя инструкцию
lock cmpxchg, забираем себе память, а если нет, то уходим в slow path. Выделение в eden'е не является wait-free: если два потока попробуют аллоцировать что-то в eden'е одновременно, то с некоторой вероятностью у одного из них ничего не выйдет и придется повторять все заново.
JVM upcall
Если не получилось выделить память в eden'е, то происходит вызов в JVM, который приводит нас к методу InstanceKlass::allocate_instance. Перед самим вызовом проводится много вспомогательной работы — выставляются специальные структуры для GC и создаются нужные фреймы, чтобы соответствовать calling conventions, так что операция это небыстрая.
Кода там много и одним поверхностным описанием не обойдешься, поэтому чтобы никого не утомлять, приведу лишь примерную схему работы:
- Сначала JVM пытается выделить память через специфичный для текущего сборщика мусора интерфейс. Там происходит та же цепочка вызовов, что и была выше: сначала попытка аллоцировать из TLAB'а, потом попытка аллоцировать TLAB из кучи и создание объекта.
- В случае неудачи вызывается сборка мусора. Там же где-то замешана ошибка GC overhead limit exceeded, всевозможные нотификации о GC, логи и другие проверки, не имеющие отношения к аллокации.
- Если не помогла сборка мусора, то происходит попытка аллокации прямо в Old Generation (здесь поведение зависит от выбранного алгоритма GC), а в случае неудачи происходит еще одна сборка и попытка создания объекта, и, если не получилось и тут, то в конце концов кидается
OutOfMemoryError. - Когда объект успешно создался, проверяется, не является ли он, часом, finalizable и если да, то происходит его регистрация, которая заключается в вызове метода
Finalizer#register(вас ведь тоже всегда интересовало, почему этот класс есть в стандартной библиотеке, но никогда никем не используется явно?). Сам метод явно написан очень давно: создается объект Finalizer и под глобальным (sic!) локом добавляется в связный список (с помощью которого объекты потом будут финализироваться и собираться). Это вполне себе оправдывает безусловный вызов в JVM и (частично) совет "не пользуйтесь методом finalize, даже если очень хочется".
В итоге мы теперь знаем про аллокации почти всё: объекты аллоцируются быстро, TLAB'ы заполняются быстро, объекты в некоторых случаях выделяются сразу в eden'е, а в некоторых идут через неспешные вызовы в JVM.
Мониторинг медленных аллокаций
Как память выделяется мы выяснили, а вот что с этой информацией делать — пока нет.
Где-то выше я писал, что вся статистика (медленные аллокации, среднее количество refill'ов, количество аллоцирующих потоков, потери на внутреннюю фрагментацию) куда-то записывается.
 Это куда-то — perf data, которая в конечном счете попадает в файл hsperfdata, и посмотреть на которую можно с помощью jcmd или программно с помощью
Это куда-то — perf data, которая в конечном счете попадает в файл hsperfdata, и посмотреть на которую можно с помощью jcmd или программно с помощью sun.jvmstat.monitor API.
Другого способа для получения хотя бы части этой информации нет, но если вы пользуетесь Oracle JDK, то JFR умеет её показывать (пользуясь приватным API, недоступным в OpenJDK), причем сразу в срезе стек-трейсов.
Важно ли это? В большинстве случаев скорее всего нет, но вот например есть отличный доклад от Twitter JVM team, где замониторив медленные аллокации и покрутив нужные параметры, они смогли уменьшить время ответа своего сервиса на несколько процентов.
Prefetch
Пока мы ходили по коду, там периодически всплывали какие-то выравнивания и дополнительные проверки для prefetch'а, которые я коварно игнорировал.
Prefetch — техника для увеличения производительности, при которой данные, к которым мы, вероятно, скоро (но не прямо сейчас) обратимся, загружаются в кэш процессора. Prefetch бывает хардварный, когда процессор сам догадывается, что итерация по памяти последовательная и начинает подгружать её, и программный, когда программист (компилятор, виртуальная машина) генерирует специальные инструкции, которые дают подсказку процессору, что неплохо бы начать подтягивать в кэш память по выданному адресу.
В хотспоте prefetch является C2-специфичной оптимизацией, поэтому мы не видели её упоминаний в коде C1. Заключается оптимизация в следующем: при аллокациях в TLAB генерируется инструкция, загружающая в кэш память, которая находится прямо за аллоцированный объектом. В среднем Java-приложения аллоцируют много или очень много, поэтому заранее подгружать память для последующих аллокаций кажется очень хорошей идеей: при следующем создании объекта нам не придется её ждать, потому что она уже будет в кэше.
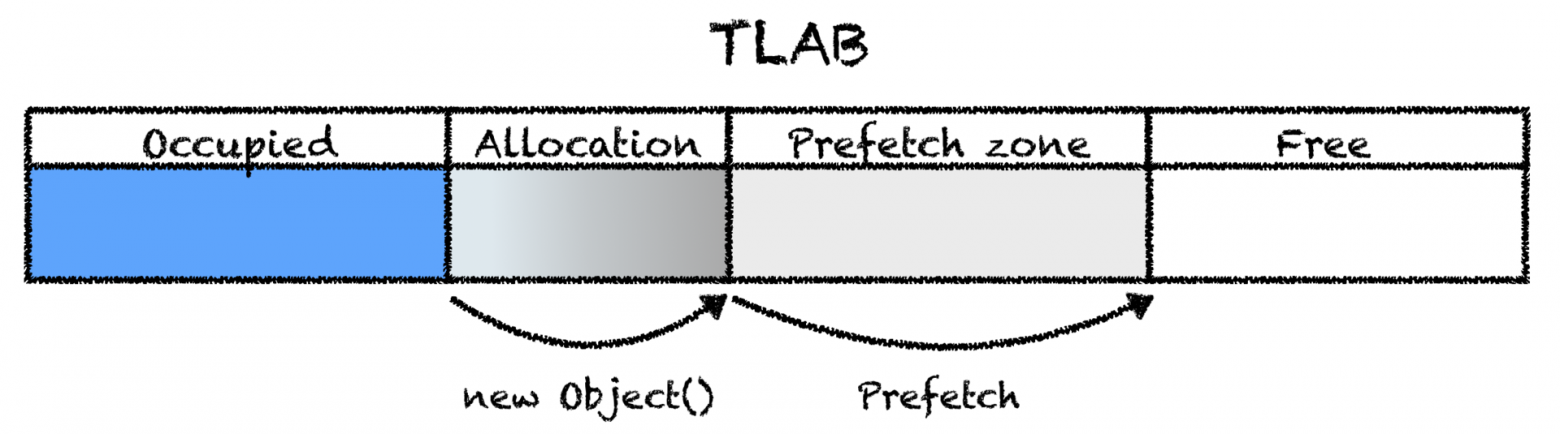
У prefetch'а есть несколько режимов, которые контролируются флагом AllocatePrefetchStyle: можно делать prefetch после каждой аллокации, можно иногда, можно после каждой аллокации, да еще и несколько раз. Вдобавок флагом AllocatePrefetchInstr можно менять инструкцию, которой этот prefetch осуществляется: можно загружать данные только в L1-кэш (например, когда вы что-то аллоцируете и сразу выбрасываете), только в L3 или во все сразу: список вариантов зависит от архитектуры процессора, а соответствие значений флага и инструкций можно посмотреть в .ad файле для нужной архитектуры.
Почти всегда эти флаги в вашем продакшне трогать не рекомендуется, разве что вы вдруг JVM-инженер, который пытается обогнать конкурентов на SPECjbb-бенчмарке пишете на Java что-то крайне высокопроизводительное, и все ваши изменения подтверждены воспроизводимыми замерами (тогда вы, наверное, не дочитали до этого места, потому что и так всё знаете).
Иницализация
С выделением памяти все прояснилось, осталось только узнать, из чего состоит инициализация объекта до вызова конструктора. Смотреть будем все в тот же C1-компилятор, но в этот раз на ARM — там более простой код, и есть интересные моменты.
Нужный метод называется
C1_MacroAssembler::initialize_object и не отличается большой сложностью: Сначала объекту устанавливается заголовок. Заголовок состоит из двух частей — mark word,
который содержит в себе информацию о блокировках, identity hashcode (или biased locking) и сборке мусора, и klass pointer, который указывает на класс объекта — на то самое нативное представление класса, которое находится в metaspace, и из которого можно получитьjava.lang.Class.
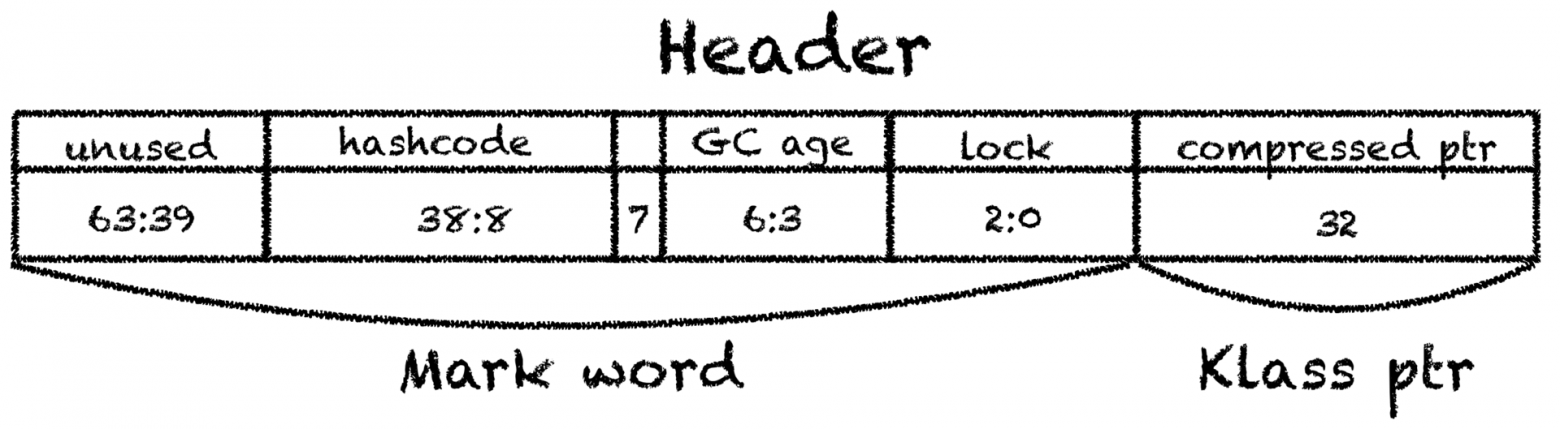
Указатель на класс обычно сжат и занимает 32 бита вместо 64. Получается, что минимально возможный размер объекта это 12 байт (плюс существует обязательное выравнивание, которое увеличивает это число до 16).
Обнуляется вся память, если не включен флаг
ZeroTLAB. По умолчанию он всегда выключен:
зануление большого региона памяти приводит к вымыванию кэшей, более эффективно занулять память маленькими частями, которые вскоре будут перезаписаны. К тому же хитрый C2-компилятор может не делать ненужную работу и не занулять память, в которую тут же запишутся аругменты конструктора. Вот и еще один ответ.
- В конце ставится StoreStore барьер (подробнее про барьеры можно прочитать в статье gvsmirnov), запрещающий (ну, почти) процессору дальнейшие записи, пока не закончатся текущие.
// StoreStore barrier required after complete initialization // (headers + content zeroing), before the object may escape. membar(MacroAssembler::StoreStore, tmp1);
Это необходимо для небезопасной публикации объекта: если в коде есть ошибка, и где-то объекты публикуются через гонку, то вы все еще ожидаете увидеть (и спецификация языка вам это гарантирует) в его полях либо значения по умолчанию, либо то, что проставил конструктор, но никак не случайные (out of thin air) значения, а виртуальная машина ожидает увидеть корректный заголовок. На x86 более сильная модель памяти, и эта инструкция там не нужна, поэтому мы и смотрели на ARM.
Проверяем на практике
Beware of bugs in the above code; I have only proved it correct, not tried it.
Пока что все выглядит прекрасно: погадали на исходниках, нашли пару забавных моментов, но мало ли, что там компилятор делает на самом деле, может мы вообще не туда смотрели и все было зря.
Проверим это вернувшись к PrintAssembly и полностью посмотрев на сгенерированный код для вызова new Long(1023):
0x0000000105eb7b3e: mov 0x60(%r15),%rax 0x0000000105eb7b42: mov %rax,%r10 0x0000000105eb7b45: add $0x18,%r10 ; Аллоцируем 24 байта: 8 байт заголовок, ; 4 байта указатель на класс, ; 4 байта на выравнивание, ; 8 байт на long поле 0x0000000105eb7b49: cmp 0x70(%r15),%r10 0x0000000105eb7b4d: jae 0x0000000105eb7bb5 0x0000000105eb7b4f: mov %r10,0x60(%r15) 0x0000000105eb7b53: prefetchnta 0xc0(%r10) ; prefetch 0x0000000105eb7b5b: movq $0x1,(%rax) ; Устанавливаем заголовок 0x0000000105eb7b62: movl $0xf80022ab,0x8(%rax) ; Устанавливаем указатель на класс Long 0x0000000105eb7b69: mov %r12d,0xc(%rax) 0x0000000105eb7b6d: movq $0x3ff,0x10(%rax) ; Кладем 1023 в поле объекта
Выглядит все ровно так, как мы и ожидали, что довольно таки неплохо.
Подводя итог, процесс создания нового объекта построен следующим образом:
- Происходит попытка аллокации объекта в TLAB'е.
- Если места в TLAB'е нет, то либо из eden'а выделяется новый TLAB, либо объект создается прямо в eden'е, в этот раз используя атомарные инструкции.
- Если и в eden'е нету места, то происходит сборка мусора.
- Если и после этого недостаточно места, то происходит попытка аллокации в старом поколении.
- Если не получилось, то кидается OOM.
- Объекту устанавливается заголовок и вызывается конструктор.
На этом теоретическую часть можно закончить и перейти к практике: сильно ли становится быстрее, нужен ли prefetch и влияет ли размер TLAB'а на что-нибудь.
Эксперименты
Теперь мы знаем, как создаются объекты и какими флагами можно этот процесс контролировать, самое время проверить это на практике. Напишем тривиальный бенчмарк, который просто создает java.lang.Object в несколько потоков, и покрутим опции JVM.
Эксперименты запускались на Java 1.8.0_121, Debian 3.16, Intel Xeon X5675. По оси абсцисс — количество потоков, по оси ординат — количество аллокаций в микросекунду.

Получается вполне ожидаемо:
- По умолчанию скорость аллокаций растет почти линейно в зависимости от количества потоков, и это как раз то, чего мы ожидаем от
new. С ростом количества потоков становится чуть хуже, но это и неудивительно: если между аллокациями делать хоть какую-нибудь полезную работу (например, пользуясьBlackhole#consumeCPU), то нахлест аллокаций между потоками уменьшится, и скорость роста вернется к линейной. - Выключенный prefetch делает аллокации немного медленнее. В нашем бенчмарке мы просто перегружаем JVM аллокациями, и в реальных приложениях все может быть совсем по-другому, поэтому никаких выводов о пользе этой оптимизации делать не будем. Рецептов тут никаких нет, в конце концов всегда можно эту оптимизацию отключить и замерить для вашего конкретного приложения.
- При выключенных аллокациях из TLAB'а все становится очень плохо: разница в два с половиной раза для одного потока — это цена вызова JIT -> JVM, а с увеличением количества потоков конкуренция за один единственный указатель лишь усиливается, и ни о какой масштабируемости речи не идет.
Ну и напоследок о пользе finalize, сравним аллокации из eden'а с аллокациями finalizable-объектов:
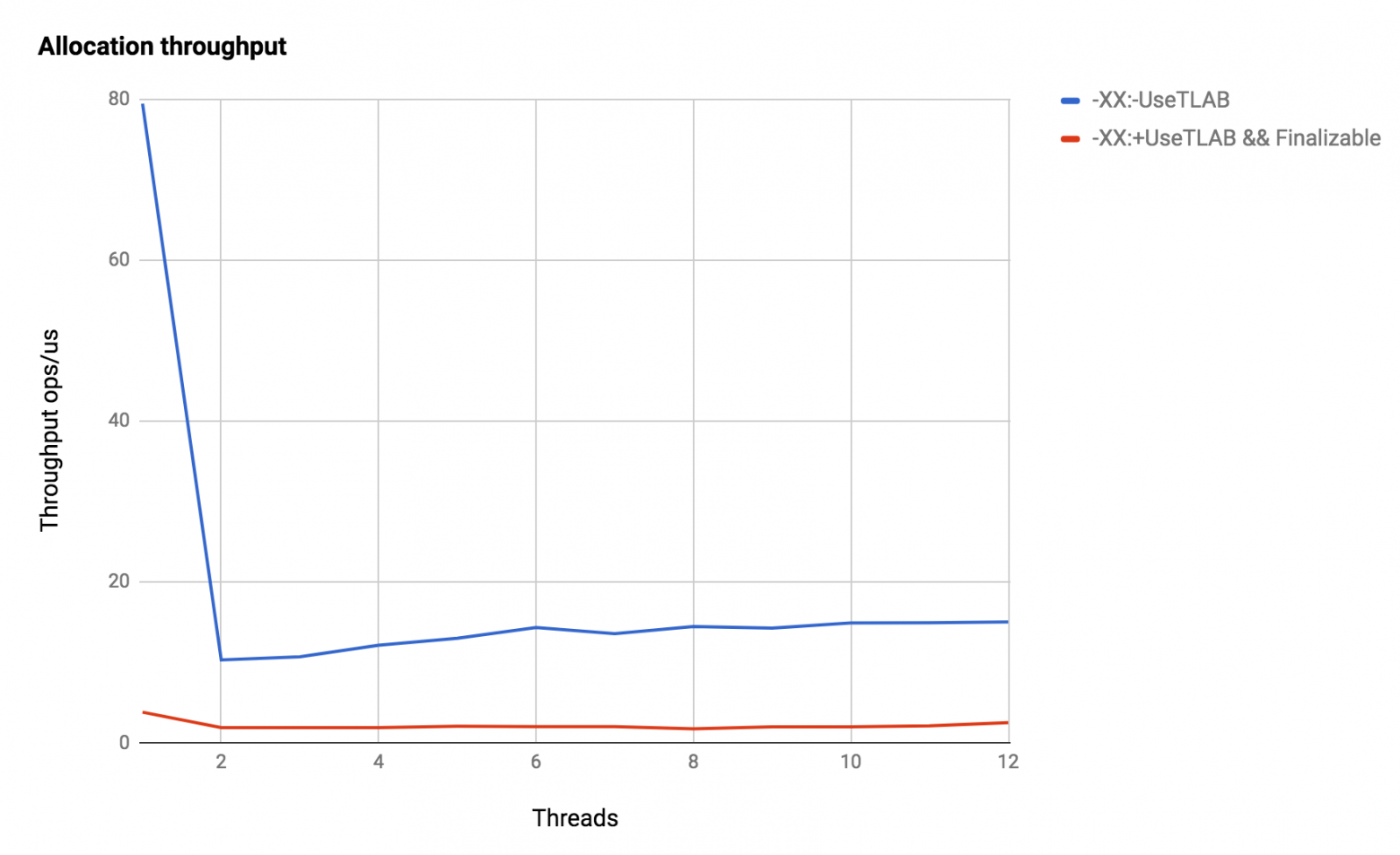
Падение производительности на порядок и на два порядка по сравнению с быстрой аллокацией!
Заключение
JVM делает очень много вещей для того, чтобы создание новых объектов было как можно более быстрым и безболезненным, а TLAB'ы — основной механизм, которым она это обеспечивает. Сами же TLAB'ы возможны только благодаря тесной кооперации со сборщиком мусора: переложив ответственность за освобождение памяти на него, аллокации стали почти бесплатными.
Применимо ли это знание? Может быть, но в любом случае всегда полезно понимать, как [ваш] инструмент устроен внутри и какими идеями он пользуется.
Отдельное спасибо apangin и gvsmirnov за ревью, без которого вы бы умерли от скуки, не дойдя и до середины статьи, наполненной неясными формулировками, листингами кода и очепятками.


{kind=link}