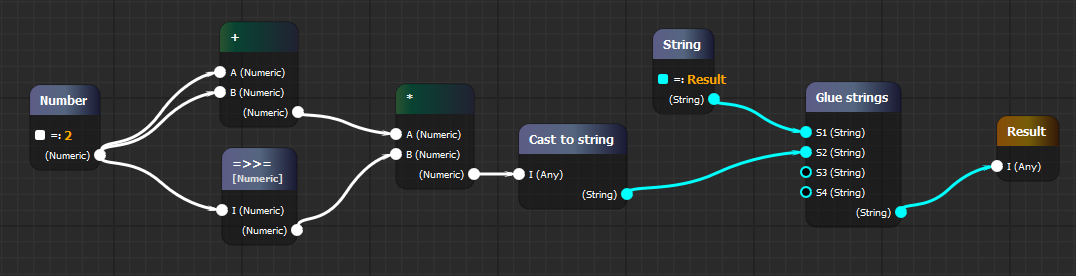
Я хочу рассказать про созданный мною web редактор для «визуального программирования» и его историю создания.
Есть у нас отдел, занимающийся претензионной деятельностью с Почтой России. Ребята ищут потерянные/не оплаченные/не доставленные отправления. В сухом остатке для разработчиков эта задача сводилась к написанию очень большого количества разнообразных и огромных (>150 строк) SQL запросов на диалекте PostgreSQL, которые ОЧЕНЬ часто менялись и дополнялись в силу активного появления новых гипотез, а также поступления новых сведений о заказах.
Естественно, нам, как программистам, это дело очень быстро надоело, и сразу захотелось предложить
И тут, как в фильме «Проблеск гениальности» («Flash of Genius»), у меня перед глазами всплыла картина визуального редактора схем (blueprints) из UE4 (Unreal Engine 4), с помощью которых персонажи запускали файрболы в своих врагов:
Прибежав в тот же вечер домой, я взял первую попавшуюся JavaScript библиотеку, умеющую рисовать красивые прямоугольники и сложные линии — ей оказалась Raphaël от нашего соотечественника DmitryBaranovskiy. Нарисовав пару прямоугольников и подёргав их с помощью библиотечных drag-and-drop, я сразу написал автору библиотеки с вопросом поддерживает ли он её. И не дождавшись ответа (до сих пор), я в ту же ночь наплодил более 1000 строк кода на JavaScript, и моя мечта на глазах почти стала явью! Но предстояло ещё много работы.
В итоге, что же захотелось сделать:
- Красивый и удобный редактор в вебе, который предоставляет средства для манипуляции и связывания «узлов» разных типов, которые описываются в доменной схеме, передающейся редактору при инициализации. Тем самым сделать редактор независимым от предметной области.
- Возможность сериализации ацикличного графа пользователя в древовидную структуру, которую очень легко разбирать (parse) (например JSON) и интерпретировать на любом языке.
- Предоставить удобный формат для описания типов и компонентов предметной области.
- Придумать богатую систему типов и ограничений, которая поможет пользователю создавать графы, корректные с точки зрения предметной области.
- Дать возможность пользователю создавать свои компоненты из комбинаций существующих.
В итоге вот что получилось:
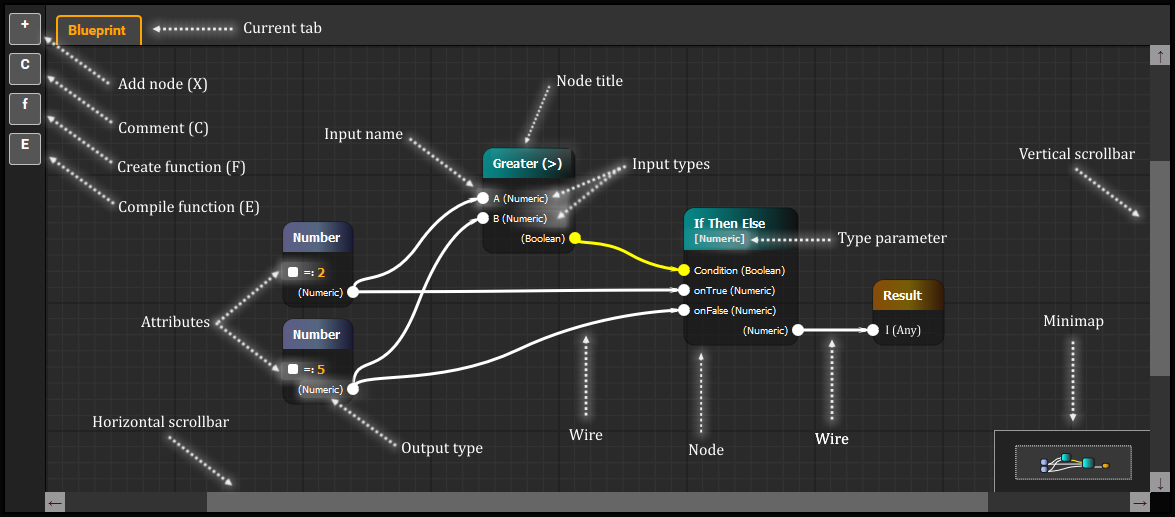
Видно, что чертёж (blueprint) состоит из узлов (nodes), которые являются конкретными экземплярами компонентов (component), описанных в схеме предметной области (schema). Узлы соединяют проводами (wires). Провод всегда идёт от выхода (output) одного узла к входу (input) другого (и наоборот). Из одного выхода может идти много проводов, но на вход можно привязать только один.
Все входы и выходы имеют тип, и соответственно накладывают ограничения на возможные связи. Например, возьмём следующую систему типов:
types: # Всегда есть тип Any, который супер-родитель всех типов Scalar: Numeric: extends: Scalar String: extends: Scalar List: typeParams: [A]
Таким образом можно выход типа Numeric связать с входом типа Scalar, но не наоборот. Для параметризованных типов вроде List подразумевается ковариативность, т.е. List[String] можно передать в List[Scalar], но не наоборот. Плюс всегда присутствует супер тип Any, наследником которого являются все остальные типы.
У узлов также могу присутствовать атрибуты, которые не настраиваются с помощью проводов, а пользователь сам вводит в них значения. Для этого существуют концепция valuePicker-ов, с помощью которых можно задавать свой интерфейс ввода значений атрибутов. Из коробки есть просто текстовый инпут и возможность выбора из заранее определённого набора констант.
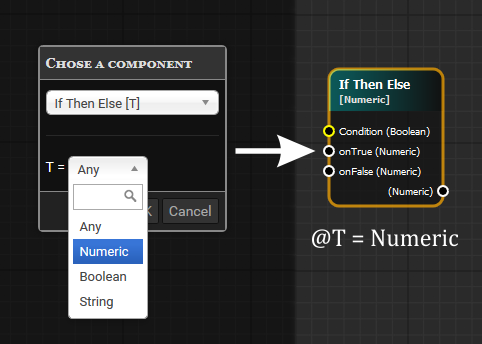
Также узлы бывают параметризованы по типам. Например, дан компонент:
IfThenElse: typeParams: [T] in: C: Boolean out: onTrue: @T onFalse: @T
При создании узла на базе компонента IfThenElse редактор попросит нас указать тип T и подставит его во все места с T:
Типы входов и выходов также помогают пользователю при проектировании. Если вы потянете проводок из выхода с типом Numeric и отпустите мышку, то вылезет окно создания компонентов, отфильтрованных таким образом, что там останутся только те, вход которых совместим (conforms) с типом Numeric. И даже автоматически привяжется проводок.
Заняло всё это примерно чистых тройку человеко-недель, растянутых на добрых 5-6 месяцев. И ещё спустя полгода появились силы что-то задокументировать и заявить об этом миру.
Итак, господа, настало время творить! Возьмём самый нереальный случай, когда вам надо предоставить «не техническому» пользователю возможность визуально программировать процесс складывания чисел. Мы пониманием, что нам нужен всего лишь один тип Numeric и пару компонентов: возможность задать число (Literal) и возможность сложить два таких числа (Plus). Далее приведён пример схемы данной предметной области: (все примеры схем описаны в формате YAML для наглядности, в реальности же вам надо будет передавать нативные javascript объекты):
types: # Всегда есть тип Any, который супер-родитель всех типов Numeric: color: "#fff" components: Literal: # Название компонента attrs: # Атрибуты V: Numeric out: # Исходящие сокеты O: Numeric Plus: in: # Входящие сокеты A: Numeric B: Numeric out: O: Numeric
Пример собранного редактора с данной схемой и простым графом можно посмотреть тут.
Поиграйтесь! Нажмите X для создания нового элемента, удалите элемент двойным кликом. Соедините узлы проводками, выделите их все и скопируйте и вставьте через Ctrl+C и Ctrl+V. Потом выделите все Ctrl+A и удалите с помощью Delete. Ведь всегда можно сделать Undo, прибегнув к Ctrl+Z!
Теперь допустим, наш нехитрый пользователь собрал следующий граф:

Если мы попросим редактор сохранить наш граф в дерево, то получим:
[ { "id": 8, "c": "Plus", "links": { "A": { "id": 2, "c": "Literal", "a": { "V": "2" }, "links": {}, "out": "O" }, "B": { "id": 5, "c": "Literal", "a": { "V": "2" }, "links": {}, "out": "O" } } } ]
Как видим нам тут пришло дерево, которое очень легко рекурсивно обойти и получить какой-то результат. Допустим, языком нашего бэкэнда является тоже JavaScript (хотя может быть любой).
Пишем тривиальный код:
function walk(node) { switch (node.c) { case 'Literal': return parseFloat(node.a.V); case 'Plus': return walk(node.links.A) + walk(node.links.B); default: throw new Error("Unsupported node component: " + node.component); } } walk(tree);
Если мы прогуляемся такой функцией по вышеуказанному дереву, то получим 2+2=4. Вуаля!
Очень приятным бонусом является возможность у пользователя определять свои «функции», объединяя существующие компоненты.
Например, даже имея такую скудную доменную область, где можно просто складывать числа, пользователь может определить свой компонент, который будет умножать заданное число на три:
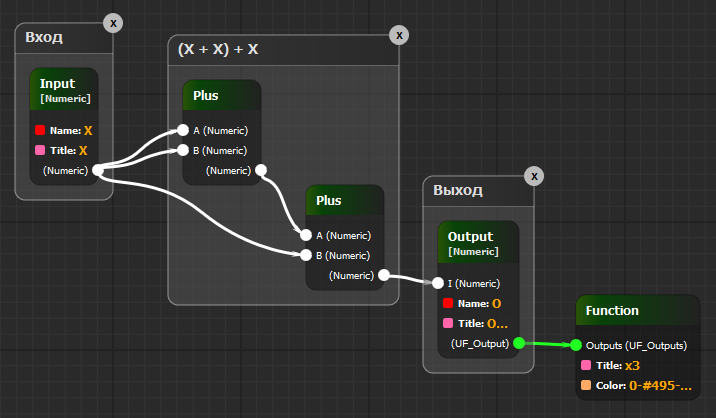
Теперь у нас появилась пользовательская функция x3:
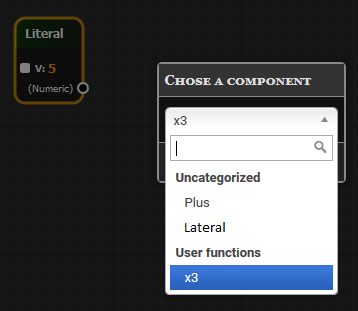
Которой можно воспользоваться, как новым компонентом:
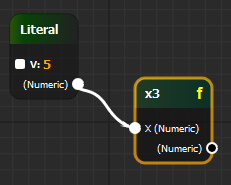
При этом на backend можно послать дерево, где все пользовательские функции развёрнуты (inlined), и разработчик даже не будет знать, что некоторые узлы были в составе пользовательской функции. Получается, что пользователи сами могу обогащать свой язык проектирования при должных фантазии и упорстве.
Вернёмся же к нашему первому примитивному примеру складывания чисел. Не смотря на то, что процессор это интегральное устройство, которое только и делает, что складывает — визуально программировать конечному пользователю на уровне сложения чисел будет не очень весело. Нужны более экспрессивные и богатые конструкции!
Возьмём к примеру замечательный язык SQL. Если присмотреться, то любой SQL запрос на самом деле очень легко раскладывается в дерево (этим и занимается первым делом БД, когда получает ваш запрос). Понаписав достаточное количество типов и компонентов можно получить нечто уже более устрашающее:
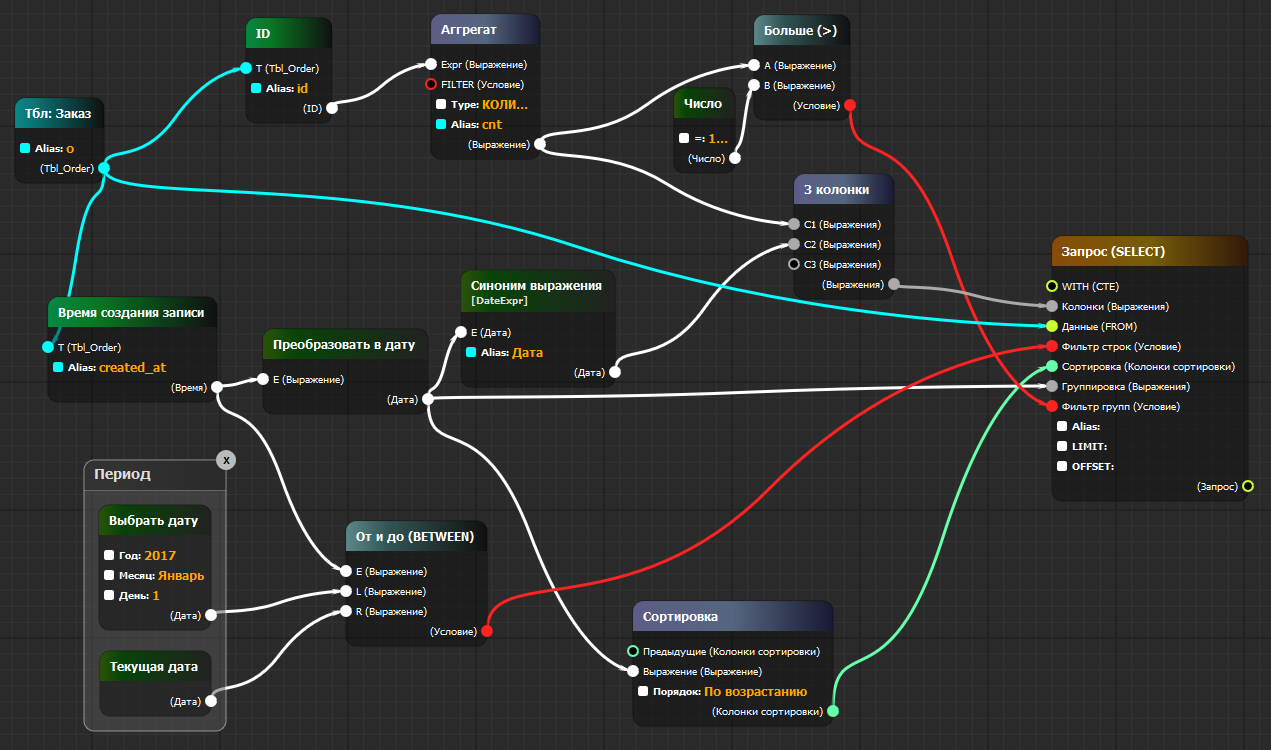
P.S. Если какой-то из примеров не открывается...
Возможно это связано с тем, что вы уже попытались сохранить пользовательскую функцию для одной из схем. А так как по умолчанию (но можно и нужно определять свои обработчики) все пользовательские функции хранятся в localStorage, то может возникнуть ситуация, когда редактор попытается загрузить компоненты или типы, не описанные в текущей схеме.
Для этого просто очистите текущий localStorage с помощью:
Для этого просто очистите текущий localStorage с помощью:
localStorage.clear()
К сожалению, демонстрацию превращения данного графа в реальный SQL провести не получится, т.к. она сильно завязана на наш проект. Но в реальности это собирается в следующий SQL:
SELECT COUNT(o.id) AS cnt , (o.created_at)::DATE AS "Дата" FROM tbl_order AS o WHERE o.created_at BETWEEN '2017-1-1'::DATE AND CURRENT_DATE GROUP BY (o.created_at)::DATE HAVING ( COUNT(o.id) ) > ( 100 ) ORDER BY (o.created_at)::DATE ASC
Который сразу же исполняется и отдаёт готовый отчёт в формате Excel. Переведя данный SQL на человечий, получаем:
Показать количество загруженных заказов за каждую день в хронологическом порядке, начинания с 1 января 2017 года, выкидывания дни, где загрузили меньше чем 100 заказов. Вполне себе реальный отчёт для бизнеса!
Схему в формате JSON для данного примера можно посмотреть тут.
Я не буду в статье приводить полное описание системы типов и компонентов, за этим отправляю в соответствующий раздел документации. Но для подогрева интереса лишь немного «вброшу», что можно писать вот так (немного косячит подсветка вычурного синтаксиса YAML):
Plus: typeParams: [T] typeBounds: {T: {<: Expr}} # Параметризованный тип 'T' ограничен сверху типом 'Expr', # что означает, что нам надо сюда передать наследник типа 'Expr' in: A: @T B: @T out: O: @T
Это как если бы вы в Scala объявили функцию:
def Plus[T <: Expr](A: T, B: T): T = A + B
В итоге, подготовив достаточное количество компонентов, и придумав хорошую систему типов (и написав
Самое главное, что я с радостью передаю этот инструмент в общественное достояние на GitHub под лицензией MIT.
Кому интересно, есть идеи/задачи по дальнейшему развитию инструмента:
- Более удобная навигация по компонентам в схеме + их документация для пользователя
- Сокеты-атрибуты (как в UE4)
- Возможность определять атрибуты в пользовательских функциях.
- Режим read-only для отображения схем
- Узлы кастомной формы (как в UE4), а не только прямоугольники
- Ускорение и оптимизация для работы с большим количеством элементов
- Интернационализация
- Экспорт картинки в SVG/PNG
- You name it!
Будет круто, если кому-то захочется воспользоваться этим инструментом на практике и поделиться своим опытом.
P.S. Ещё круче будет, если кто-то присоединится к разработке инструмента!
P.P.S. Я проводил презентацию инструмента в компании с помощью данного документа.

