Привет, Хабр!
* На самом деле не совсем так. При разработке информационной системы, частью которой является различная обработка конструкторско-технологической документации, у меня возникла проблема, которую вкратце можно описать следующим образом. Сегодня мы имеем один состав изделия, за день приходит несколько изменений по различным частям этого изделия и к вечеру уже неясно, что же изменилось? Изделия порой могут иметь более 10 000 элементов в составе, элементы не уникальны, а реальность такова, что изменения по составу могут активно приходить, хотя изделие уже почти готово. Непонимание объема изменений усложняет планирование.
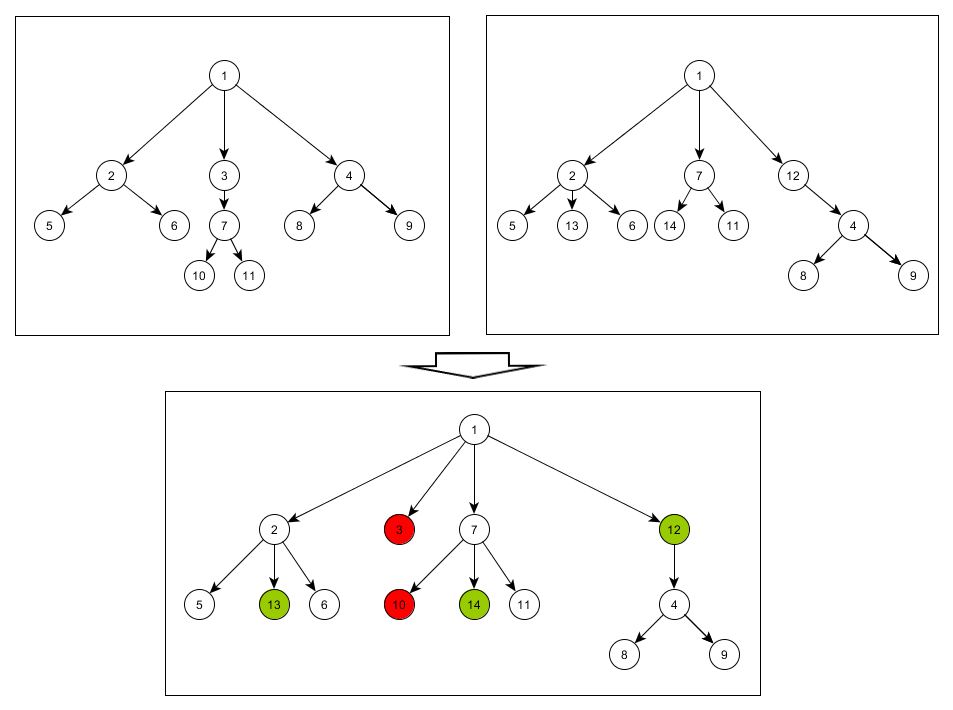
Состав изделия можно представить в виде древовидного графа. Не найдя подходящего способа сравнения двух графов, я решил написать свойвелосипед.
В течение дня различные изменения из конструкторской системы приходят в систему учета. На данных из системы учета строится планирование производства. Условия позволяют принять все изменения за день и пересчитать спецификацию изделия ночью. Но, как я писал выше, непонятно, чем отличается вчерашнее состояние от состояния сегодняшнего.
Хочется видеть что ушло из дерева изделия, а что добавилось. Так же хочется видеть какая деталь или сборка заменила другую деталь или сборку. Например, если в ветке дерева добавился промежуточный узел, то в таком случае неправильно будет считать, что все нижестоящие элементы удалились со старых мест и вставились на новые места. Они остались на своих местах, но произошла вставка промежуточного узла. Кроме того, элемент может «путешествовать» вверх и вниз только внутри одной ветки дерева, это обусловлено спецификой техпроцесса изготовления.
Спецификация изделия пересчитывается PL/SQL-процедурой внутри Oracle. Поэтому я счел логичным сделать и свой поиск изменений на PL/SQL.
Таблица, в которой хранится дерево изделия, назовем ее
Связки
При пересчете спецификации, данные, по изменившимся заказам, полностью удаляются и считаются вновь. Поэтому нужно сохранить состояние дерева до пересчета. Для этого используем аналогичную таблицу
Итог сравнения будет храниться в таблице
Для начала возьмем предыдущее и текущее деревья и скинем их в таблицу
Так же проставим на элементах суммарного дерева их уровень вложенности, чтобы в дальнейшем не вычислять его каждый раз.
Сохраним состояние таблицы
Теперь нужно пройти получившееся дерево по уровням и по узлам в поисках изменений. Для начала определим максимальный уровень:
Теперь в цикле пройдем уровни этого дерева. На каждом уровне, так же в цикле, будем выбирать дочерние элементы каждого узла, и искать элемент с «противоположным знаком». Проще говоря, искать одинаковые
Когда элемент обработан, помещать его в некоторый список обработанных элементов. Я использовал следующую процедуру:
«Обработанность» элемента возвращала функция
которая просматривала ту же коллекцию.
Цикл выглядит следующим образом:
Для
Когда нашелся такой же элемент, то всё просто — нужно просто сравнить их свойства. Для этого используется функция
Но что делать, когда произошла замена одного узла на другой, был вставлен узел в середину или узел из середины был удален?
Для определения описанных ситуаций я не нашел ничего умнее как просто сравнить составы двух узлов с целью определения отношения количества одинаковых
Возможно, таким смелым решением я когда-нибудь выстрелю себе в ногу.
Добавим немного кода в основной
Удалось найти один элемент в этом узле
Перецепим на него содержимое текущего узла без раздумий. При условии, что оба элемента являются сборками. Текущий элемент не удаляется. Почему? Если в узлах вообще нет одинаковых элементов, то в дальнейшем всё будет возвращено на свои места.
Если удалось найти несколько элементов, то берется наиболее похожая сборка. Для определения «похожести» используется процедура
В итоге часть элементов будет перецеплена, и дерево будет иметь следующий вид.
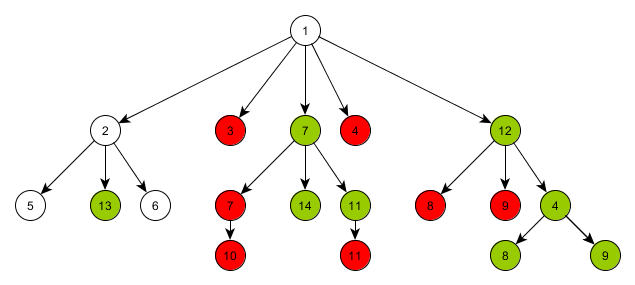
Если дополнительный корневой элемент, который был добавлен в начале, не нужен, то его можно удалить.
Теперь можно взять все оставшиеся элементы со статусом 0 и 1, и начиная с них пройти вверх к корню. Если будет найден такой же элемент с «противоположным статусом», то сравнить их, удалить из дерева элемент с 0, а у элемента с 1 сменить статус.
Теперь пройдемся по оставшимся элементам со статусом 0 и восстановим их прежние
После этого дерево получает искомый вид.
Полагаю, что есть более красивые, быстрые и правильные способы сравнения деревьев. Это мой вариант и надеюсь, что он будет полезен кому-то и покажет, как можно делать или как не надо делать.
* На самом деле не совсем так. При разработке информационной системы, частью которой является различная обработка конструкторско-технологической документации, у меня возникла проблема, которую вкратце можно описать следующим образом. Сегодня мы имеем один состав изделия, за день приходит несколько изменений по различным частям этого изделия и к вечеру уже неясно, что же изменилось? Изделия порой могут иметь более 10 000 элементов в составе, элементы не уникальны, а реальность такова, что изменения по составу могут активно приходить, хотя изделие уже почти готово. Непонимание объема изменений усложняет планирование.
Состав изделия можно представить в виде древовидного графа. Не найдя подходящего способа сравнения двух графов, я решил написать свой
Задача
В течение дня различные изменения из конструкторской системы приходят в систему учета. На данных из системы учета строится планирование производства. Условия позволяют принять все изменения за день и пересчитать спецификацию изделия ночью. Но, как я писал выше, непонятно, чем отличается вчерашнее состояние от состояния сегодняшнего.
Хочется видеть что ушло из дерева изделия, а что добавилось. Так же хочется видеть какая деталь или сборка заменила другую деталь или сборку. Например, если в ветке дерева добавился промежуточный узел, то в таком случае неправильно будет считать, что все нижестоящие элементы удалились со старых мест и вставились на новые места. Они остались на своих местах, но произошла вставка промежуточного узла. Кроме того, элемент может «путешествовать» вверх и вниз только внутри одной ветки дерева, это обусловлено спецификой техпроцесса изготовления.
Подготовка
Спецификация изделия пересчитывается PL/SQL-процедурой внутри Oracle. Поэтому я счел логичным сделать и свой поиск изменений на PL/SQL.
Таблица, в которой хранится дерево изделия, назовем ее
MR_ORDER_TREE, имеет следующий вид:order_id |
ID заказа, на котором закреплено дерево |
item_id |
ID элемента в дереве, вместе с order_id формирует первичный ключ и уникален в рамках заказа |
item_ref |
ID элемента в который входит выбранный элемент |
kts_item_id |
ID из справочника деталей и узлов |
item_qty |
Количество |
is_item_buy |
Покупное ли изделие |
item_position |
Номер позиции в сборке |
Связки
(item_ref, kts_item_id) уникальны. Кроме покупки, позиции и количества имеются и другие атрибуты конкретного элемента, но речь не о них.При пересчете спецификации, данные, по изменившимся заказам, полностью удаляются и считаются вновь. Поэтому нужно сохранить состояние дерева до пересчета. Для этого используем аналогичную таблицу
MR_ORDER_TREE_PREV.Итог сравнения будет храниться в таблице
MR_ORDER_TREE_COMP, которая дополнительно будет иметь два столбца:stat |
Столбец для отметки состояния элементов: -1 – дополнительный корневой элемент (об этом ниже) 0 – элемент удален 1 – элемент добавлен 2 – свойства элемента изменились 3 – неизвестное состояние (на случай если что-то пошло не так) 4 – элемент не изменился |
comm |
Комментарий, дающий дополнительные данные по состоянию |
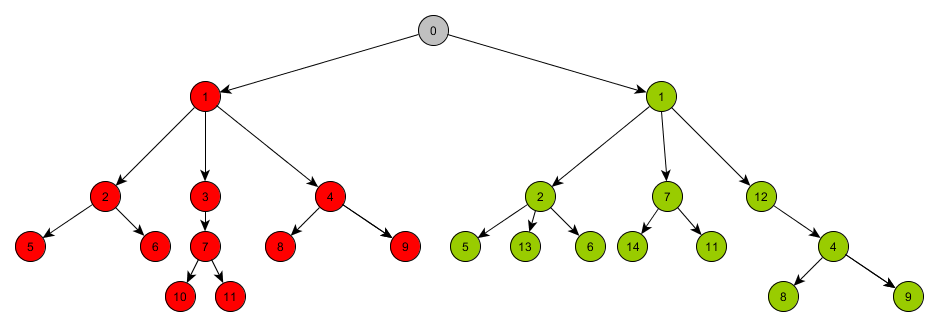
Для начала возьмем предыдущее и текущее деревья и скинем их в таблицу
MR_ORDER_TREE_COMP. При этом добавим к ним общий корень, item_id у текущего дерева увеличим на (максимальное значение + 1) item_id дерева с предыдущим состоянием. Все элементы старого дерева будем считать удалением, а все элементы нового вставкой.select nvl(max(item_id), 0) + 1 into v_id from mr_order_tree_prev t where t.order_id = p_order_id; insert into MR_ORDER_TREE_COMP (ORDER_ID, ITEM_ID, KTS_ITEM_ID, ITEM_QTY, IS_ITEM_BUY, IS_ADD_WORK, ITEM_POSITION, N_GROUP, T_LEVEL, STAT, COMM) values (p_order_id, -1, null, 0, 0, 0, 0, 0, 0, -1, 'Дополнительная голова для расчета'); insert into MR_ORDER_TREE_COMP (ORDER_ID, ITEM_ID, ITEM_REF, KTS_ITEM_ID, KTS_ITEM_REF, ITEM_QTY, IS_ITEM_BUY, IS_ADD_WORK, ITEM_POSITION, N_GROUP, STAT, COMM) select p.order_id, p.item_id, nvl(p.item_ref, -1), p.kts_item_id, p.kts_item_ref, p.item_qty, p.is_item_buy, p.is_add_work, p.item_position, p.n_group, 0, 'удаление' from mr_order_tree_prev p where p.order_id = p_order_id; insert into MR_ORDER_TREE_COMP (ORDER_ID, ITEM_ID, ITEM_REF, KTS_ITEM_ID, KTS_ITEM_REF, ITEM_QTY, IS_ITEM_BUY, IS_ADD_WORK, ITEM_POSITION, N_GROUP, STAT, COMM) select p.order_id, p.item_id + v_id, case when p.item_ref is null then -1 else p.item_ref + v_id end, p.kts_item_id, p.kts_item_ref, p.item_qty, p.is_item_buy, p.is_add_work, p.item_position, p.n_group, 1, 'вставка' from mr_order_tree p where p.order_id = p_order_id;
Так же проставим на элементах суммарного дерева их уровень вложенности, чтобы в дальнейшем не вычислять его каждый раз.
for rec in (select item_id, level lev from (select * from mr_order_tree_comp where order_id = p_order_id) connect by prior item_id = item_ref start with item_id = -1) loop update mr_order_tree_comp c set c.t_level = rec.lev where c.order_id = p_order_id and c.item_id = rec.item_id; end loop;
Сохраним состояние таблицы
mr_order_tree_comp для пересчитываемого заказа, это понадобится в будущем. Я использовал коллекцию, но думаю, что можно применить и временную таблицу.procedure save_tree_stat(p_order in number) is begin select TREE_BC_STAT_ROW(c.order_id, c.item_id, c.item_ref, c.kts_item_id, c.kts_item_ref) bulk collect into tree_before_calc from mr_order_tree_comp c where c.order_id = p_order; end save_tree_stat;
«Сложение» деревьев
Теперь нужно пройти получившееся дерево по уровням и по узлам в поисках изменений. Для начала определим максимальный уровень:
select max(t_level) into v_max_lvl from mr_order_tree_comp where order_id = p_order_id;
Теперь в цикле пройдем уровни этого дерева. На каждом уровне, так же в цикле, будем выбирать дочерние элементы каждого узла, и искать элемент с «противоположным знаком». Проще говоря, искать одинаковые
kts_item_id с одинаковым item_ref, но состоянием 1 для 0 и 0 для 1. После этого один из них удалять, а входящие элементы перецеплять на оставшийся узел.Когда элемент обработан, помещать его в некоторый список обработанных элементов. Я использовал следующую процедуру:
procedure add_to_rdy (p_item in number, p_order in number) is begin item_ready_list.extend; item_ready_list(item_ready_list.last) := tree_rdy_list_row(p_order, p_item); end add_to_rdy;
«Обработанность» элемента возвращала функция
function item_rdy(p_item in number, p_order in number) return number
которая просматривала ту же коллекцию.
Цикл выглядит следующим образом:
<<lvls>> for i in 1..v_max_lvl loop <<heads>> for rh in (select c.* from mr_order_tree_comp c where c.order_id = p_order_id and c.t_level = i) loop <<leafs>> for rl in (select c.* from mr_order_tree_comp c where c.order_id = p_order_id and c.item_ref = rh.item_id and c.stat in (0, 1) order by c.stat) loop if (item_rdy(rl.item_id, rl.order_id) = 0) then if (rl.stat = 0) then select count(*) into v_cnt from mr_order_tree_comp c where c.order_id = p_order_id and c.item_ref = rh.item_id and c.kts_item_id = rl.kts_item_id and c.stat = 1; case when (v_cnt = 1) then select c.item_id into v_item from mr_order_tree_comp c where c.order_id = p_order_id and c.item_ref = rh.item_id and c.kts_item_id = rl.kts_item_id and c.stat = 1; update mr_order_tree_comp c set c.item_ref = v_item where c.item_ref = rl.item_id and c.order_id = p_order_id; update mr_order_tree_comp c set c.stat = 4 where c.item_id = v_item and c.order_id = p_order_id; diff_items(p_order_id, rl.item_id, v_item); delete mr_order_tree_comp c where c.item_id = rl.item_id and c.order_id = p_order_id; add_to_rdy(rl.item_id, rl.order_id); add_to_rdy(v_item, rl.order_id); end case; end if;
Для
(rl.stat = 1) логика аналогична.Когда нашелся такой же элемент, то всё просто — нужно просто сравнить их свойства. Для этого используется функция
diff_items. Ситуация, когда найдено более одного элемента, является скорее исключением и говорит о том, что с деревом состава что-то не так.Поиск «похожих» элементов
Но что делать, когда произошла замена одного узла на другой, был вставлен узел в середину или узел из середины был удален?
Для определения описанных ситуаций я не нашел ничего умнее как просто сравнить составы двух узлов с целью определения отношения количества одинаковых
kts_item_id к общему количеству элементов. Если значение данного отношения больше определенного значения, то узлы взаимозаменяемы. Если на текущей итерации цикла у узла есть несколько вариантов замены, то берется вариант с наибольшим «коэффициентом похожести».Возможно, таким смелым решением я когда-нибудь выстрелю себе в ногу.
Добавим немного кода в основной
CASE.when (v_cnt = 0) then select count(*) into v_cnt from mr_order_tree_comp c where c.order_id = p_order_id and c.item_ref = rh.item_id and c.stat = 1 and not exists (select 1 from table(item_ready_list) a where a.order_id = c.order_id and a.item_id = c.item_id);
Удалось найти один элемент в этом узле
if (v_cnt = 1) then select c.item_id, c.kts_item_id into v_item, v_kts from mr_order_tree_comp c where c.order_id = p_order_id and c.item_ref = rh.item_id and c.stat = 1 and not exists (select 1 from table(item_ready_list) a where a.order_id = c.order_id and a.item_id = c.item_id);
Перецепим на него содержимое текущего узла без раздумий. При условии, что оба элемента являются сборками. Текущий элемент не удаляется. Почему? Если в узлах вообще нет одинаковых элементов, то в дальнейшем всё будет возвращено на свои места.
if (is_item_comp(v_item, p_order_id) = is_item_comp(rl.item_id, p_order_id)) then update mr_order_tree_comp c set c.item_ref = v_item where c.item_ref = rl.item_id and c.order_id = p_order_id; add_to_rdy(rl.item_id, rl.order_id); add_to_rdy(v_item, rl.order_id); end if; end if;
Если удалось найти несколько элементов, то берется наиболее похожая сборка. Для определения «похожести» используется процедура
like_degree, значение коэффициента для сравнения содержится в переменной lperc.if (v_cnt > 1) then begin select item_id, kts_item_id, max_lperc into v_item, v_kts, v_perc from (select c.item_id, c.kts_item_id, max(like_degree(rl.item_id, c.item_id, c.order_id)) max_lperc from mr_order_tree_comp c where c.order_id = p_order_id and c.item_ref = rh.item_id and c.stat = 1 and not exists (select 1 from table(item_ready_list) a where a.order_id = c.order_id and a.item_id = c.item_id) and is_item_comp(c.item_id, p_order_id) = (select is_item_comp(rl.item_id, p_order_id) from dual) group by c.item_id, c.kts_item_id order by max_lperc desc) where rownum < 2; if (v_perc >= lperc) then update mr_order_tree_comp c set c.item_ref = v_item where c.item_ref = rl.item_id and c.order_id = p_order_id; update mr_order_tree_comp c set c.comm = 'Удаление. Заменилось на ' || kts_pack.item_code(v_kts) || ' (' || to_char(v_perc) || '%)' where c.item_id = rl.item_id and c.order_id = p_order_id; add_to_rdy(rl.item_id, rl.order_id); add_to_rdy(v_item, rl.order_id); end if; end; end if;
В итоге часть элементов будет перецеплена, и дерево будет иметь следующий вид.
Если дополнительный корневой элемент, который был добавлен в начале, не нужен, то его можно удалить.
Теперь можно взять все оставшиеся элементы со статусом 0 и 1, и начиная с них пройти вверх к корню. Если будет найден такой же элемент с «противоположным статусом», то сравнить их, удалить из дерева элемент с 0, а у элемента с 1 сменить статус.
<<items>> for rs in (select * from mr_order_tree_comp c where c.order_id = p_order_id and c.stat in (0,1)) loop <<branch>> for rb in (select * from (select * from mr_order_tree_comp c where c.order_id = p_order_id) t connect by prior t.item_ref = t.item_id start with t.item_id = rs.item_id) loop select count(*) into v_cnt from mr_order_tree_comp c where c.item_ref = rb.item_id and c.kts_item_id = rs.kts_item_id and c.stat in (1,0) and c.stat != rs.stat; if (v_cnt = 1) then select c.item_id into v_item from mr_order_tree_comp c where c.item_ref = rb.item_id and c.kts_item_id = rs.kts_item_id and c.stat in (1,0) and c.stat != rs.stat; if (rs.stat = 0) then update mr_order_tree_comp c set c.stat = 4 where c.order_id = p_order_id and c.item_id = v_item; diff_items(p_order_id, rs.item_id, v_item); update mr_order_tree_comp c set c.item_ref = v_item where c.order_id = p_order_id and c.item_ref = rs.item_id; delete mr_order_tree_comp where order_id = p_order_id and item_id = rs.item_id; end if; if (rs.stat = 1) then update mr_order_tree_comp c set c.stat = 4 where c.order_id = p_order_id and c.item_id = rs.item_id; diff_items(p_order_id, rs.item_id, v_item); update mr_order_tree_comp c set c.item_ref = rs.item_id where c.order_id = p_order_id and c.item_ref = v_item; delete mr_order_tree_comp where order_id = p_order_id and item_id = v_item; end if; continue items; end if; end loop branch; end loop items;
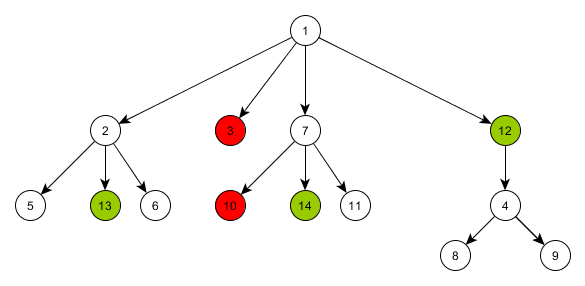
Теперь пройдемся по оставшимся элементам со статусом 0 и восстановим их прежние
item_ref. Для этого используется коллекция tree_before_calc, в которую было сохранено начальное состояние дерева mr_order_tree_comp.После этого дерево получает искомый вид.
Полагаю, что есть более красивые, быстрые и правильные способы сравнения деревьев. Это мой вариант и надеюсь, что он будет полезен кому-то и покажет, как можно делать или как не надо делать.

