История о том, как NASA, ESA, Датский Технологический Университет, нейронные сети, деревья решений и прочие хорошие люди помогли найти мне лучший бесплатный гектар на Дальнем Востоке, а также в Африке, Южной Америке и других “так себе” местах.

Кажется, года два назад, а может быть уже и три, объявили о программе раздачи бесплатных гектаров на Дальнем Востоке России. Быстренько посмотрев на карту, стало понятно, что просто так выбрать правильный гектар не так уж и просто, а лучшие и очевидные места около городов, наверняка отойдут или уже отошли местным. Наверное, именно в этот момент у меня и возникла идея, что можно как-то автоматизировать поиск наилучшего места.
Начав романтично размышлять дальше, я подумал, что не обязательно смотреть на Дальний Восток. Сейчас полно земли, которая никому нигде не нужна, но это может измениться, лет эдак через 50, когда ископаемое топливо начнет подходить к концу. И люди пойдут искать новые источники энергии. Тогда я и начал смотреть на возобновляемые источники энергии. И очень быстро понял, что карта ресурсов и территорий, где эту новую энергию можно будет добывать, сильно изменится. Найдя сейчас такие места, можно их приобрести заранее и быть богатеем потом. Прикинув ещё, мне представилось что за пару выходных это можно запросто сделать… Сейчас оглядываясь назад, я понимаю, что на это у меня ушло около года. Хочу сразу отметить, что тогда я не сильно разбирался ни в энергетике, ни в возобновляемых источниках, ни в машинном обучении. Ниже краткий пересказ моего годовалого проекта.
Определившись с идеей, я быстренько пошел смотреть, а какие вообще бывают возобновляемые источники энергии и какой из них самые энергетический. Вот неполные, но самые распространенный список:
Но как определить какой из них самые лучший и победит в будущем всех остальных? Почитав еще немного интересных статей из журналов “Наука и жизнь” и ”Юный техник”. Я вышел на методику LCOE (levelized cost of electricity) у которой принцип простой: умные дядьки пытаются оценить совокупную стоимость киловатт-часа энергии, учитывая производство, материалы, обслуживание и т.д. Ниже картинка по данным от 2016 с некоторой проекцией на 2022. Я взял картинку посвежее отсюда, ниже скучная табличка из этого документа.

Вообще таких картинок у меня тьма для разных стран, сделанные разными организациями и всё выглядит примерно одинаково:
Геотермальная и гидро мне не понравились, так как на мой взгляд, мест, где можно было бы добывать эту энергию можно пересчитать по пальцам. Ветер и Солнце — это другое дело, так как ставить их можно чуть ли не на каждую крышу и балкон. Солнце оказалось дороже, а три года назад разница была больше еще процентов на 30, я выбрал Ветер.
Кстати, уже в середине проекта, я начал наталкиваться на документы с похожими размышлениями государства США, а именно организаций NREL, Департамента Энергетики США и прочими, которые делали прогнозы и ставки на разные источники энергетики для того, чтобы уже сейчас понять каким образом модернизировать энергетическую систему страны. К примеру, в одном из таких документов все сводилось к нескольким вариантам: доля ветровой энергии будет большой или очень большой.
Идея как это провернуть была довольна проста и выглядела так:
В графическом виде этот план, как оказалось позднее, был похож вот на эту известную картинку:

Первый этап был довольно лёгким. Я просто выгрузил все записи о точках из OpenStreetMaps.
Кстати, хочу заметить, что OSM — это просто кладезь информации об объектах по всему миру с их координатами, там есть практически все. Поэтому на заметку любителям данных, OSM — это крутейший Big Data источник.
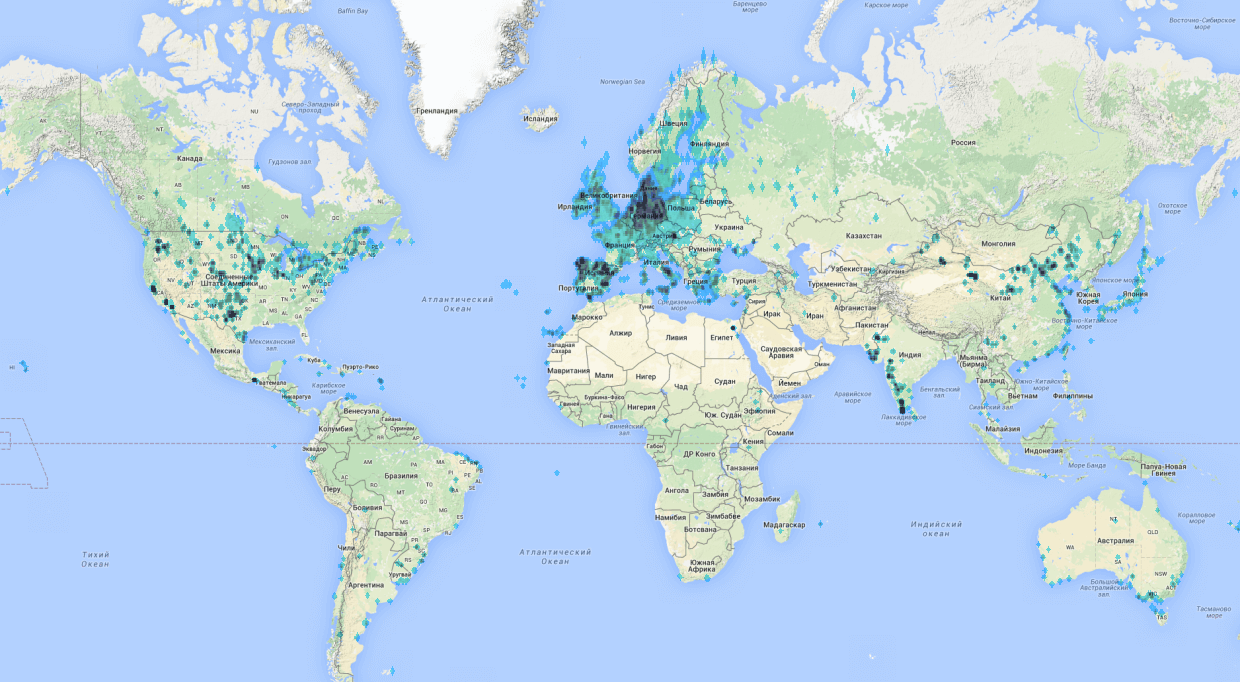
Сделать это было не очень трудно.Сначала я попытался с помощью онлайн-утилит, кажется здесь overpass-turbo.eu, кстати очень крутая штука, но не вышло из-за ограничений по количеству точек и не очень быстрой работе на большом количестве данных. Поэтому пришлось разобраться с утилитами, которые выгружали данные из слепка OSM данных локально. Выкачать всегда актуальный слепок можно вот тут? В сжатом виде он занимает порядка 40ГБ. Данные из него можно выгружать запросами с помощью вот этой утилиты Osmosis. В итоге у меня был дата сет на 140 тысяч точек по миру с координатами и heatmap. Он выглядел примерно вот так:
Все проблемы начались во втором этапе, так как я не очень понимал какую информацию нужно было собрать. Поэтому на пару дней я ушел в чтение принципов работы ветряков и рекомендаций по их размещению, ограничений и т.д. У меня даже в заметках остались вот такие забавные схемы про размещение, градиенты ветров, розы ветров и прочие другие полезные термины.

В итоге у меня получился вот такой список параметров, которые, по моему мнению, важны при выборе места:
ВЕТЕР. Собственно, как 90% всех проектов по big data ломаются на стадии “так теперь давайте глянем на ваши данные про которые вы так много говорили”, дал трещину и мой. Побежав искать данные по скорости ветра в России, я наткнулся на это:

И еще с десяток похожих и бесполезных картинок. Тут я начал догадываться, что возможно в России и правда нет ветровой энергетики, так как у нас просто не дует ветер в достаточной силе и где-то в этот момент послышался смех Сечина. Но я же отчетливо помню, что в Самарской области одни степи и очень часто выходя за хлебом в детстве меня сдувало обратно в подъезд.
Начав искать данные по России и то что, я понял, что это не было похоже на те данные, с которыми можно было сделать что-то полезное. Поэтому я двинулся к зарубежным источникам и тут же нашел прекрасные ветровые карты от Tier3 (Vaisala). На вид разрешение было достаточным и покрытие всего мира было просто отличным. Дальше я понял, что такие данные стоят неплохих денег около ~$1000 за 10 квадратных км (данные трех годовалой давности). Провал, подумал я.
Погрустив неделю, я решил написать Vaisala, Tier3 и другие консалтинговые зарубежные агентства по работе с ветрами и прочими ветровыми генераторами, и попросить данные. Я подумал, что, рассказав какую классную идею я собираюсь сделать, все сразу мне всё сгрузят.. Ответил только один — из компании Sander-Partner. Сам Sander дал некоторые советы, а также дал ссылки на то, что мне нужно: данные программы MERRA, который ведет NASA. Стоит обратить внимание, что у меня ушла примерно неделя вечеров, чтобы разобраться что такое Reanalysis, WRF и примерно понять, что как вообще происходит: сбор, агрегация, симулирование и предсказание погоды, ветров и прочих вещей.
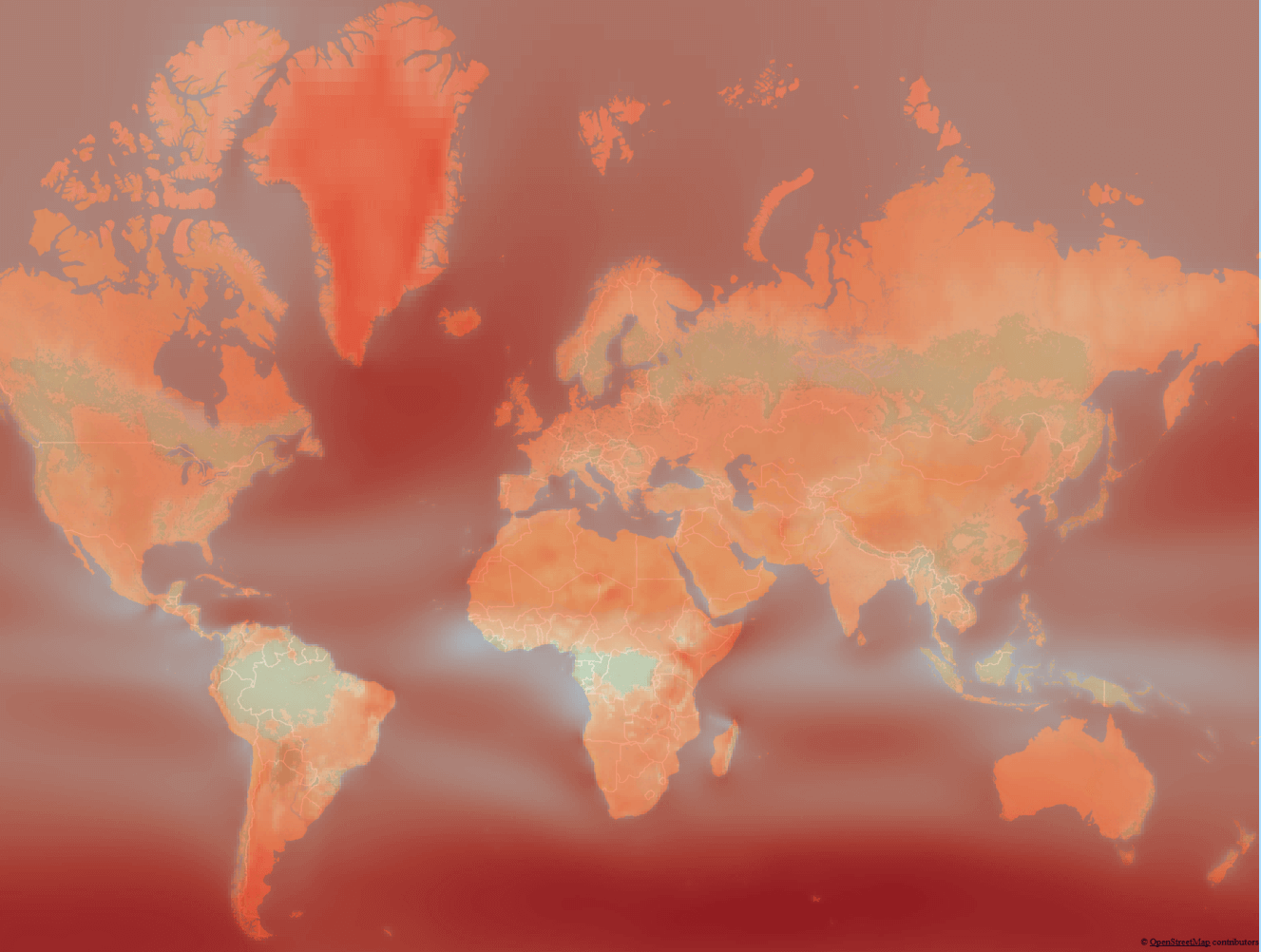
Если кратко, то человечество насобирало кучу данных о погоде, нарисована куча карт со средними температурами и скоростью ветра, но собрать все эти данные в каждой точке земного шара как было было, так и остаётся невозможно, поэтому белые пятна заполнили результатами симуляции погоды на прошлые годы и назвали это Reanalysis. К примеру, вот сайт с визуализацией таких симуляций ветра а вот как это выглядит:

Эти данные представляли из себя по сути .csv файл сетки координат со средней скоростью ветра с большим шагом, я сделал вот такую карту с помощью наикрутейшего бесплатного пакета QGIS и метода интерполяции сетки данных.
А затем с помощью него же вытащил из этой карты данные по скорости ветра по каждой паре координат. По сути у меня получилась карта, и слой данных для каждого пикселя на ней.
Поняв принцип работы с QGIS примерно за пару недель, я начал строить такие же карты для остальных источников данных и вытаскивать по координатам значения. Для температуры, влажности, давления и прочих вещей. Тут нужно заметить, что сами массивы данных в основном я брал у NASA, NOAA, ESA, WorldClim и т.д. Все они в свободном доступе. C помощью QGIS делал расчеты и поиск расстояния до ближайших точек, от городов, аэропортов и прочих инфраструктурных объектов. Каждая карта по одному параметру считалась у меня порядка 6-8 часов. И если что-то было неправильно приходилось делать это снова и снова. Домашний компьютер шелестел у меня по ночам где-то пару недель, но после этого даже соседям надоело слушать разболтанный кулер на нем и я переполз в облако, где поднял небольшую виртуалку для расчета.
Уже по прошествии нескольких месяцев я натолкнулся вот на этот сайт, сделанный кафедрой ветровой энергетики Дании (DTU Wind Energy). Стало быстро понятно, что разрешение у них в разы лучше моей карты, я списался с ними и они с удовольствием выгрузили мне данные по всему миру, так как через сайт можно получить только небольшие слепки по территории. Кстати, они так же сделали эту карту используя симуляцию движения слоев ветра моделями WRF, WAsP и добились разрешения данных до 50-100 метров, как у меня было примерно 1-10км.
РЕЛЬЕФ. Помните я писал, что рельеф очень важен, так вот я решил так же использовать и этот параметр, но с ним оказалось тоже все не просто. Сначала я написал утилиту, которая выкачивала данные из Google Elevation API. Она отлично справилась и качала данные по всем моим точкам всего мира с шагом в 10 км, потребовалась всего-то порядка 12 часов работы. Но у меня также были параметры гладкости рельефа или среднее значение перепада на территории вокруг потенциальной точки размещения ветряка. То есть мне нужны были данные с шагом метров в 100-200 всего мира, с помощью которых я бы уже смог посчитать среднее значения перепада.

Для того, чтобы посчитать перепады, потребовалось бы пару месяцев на выкачивание данных из Google Elevation. Поэтому я пошел искать другие варианты.
Первое, что я нашёл — Wolfram cloud, у которых уже были необходимые данные. Просто написав формулу, эта штука начинала считать, используя данные из облака Wolfram. Но там меня тоже ждал провал, так как я наткнулся в какие-то лимиты, которые нигде не были указаны и получив смешную переписку с поддержкой этого сервиса я пошел искать другой вариант.
Тут мне опять помогли источники данных в NASA и данные с космической программы STRM (NASA Shuttle Radar Topography Mission Global). Я честно их пытался выкачать с сайта, но там данные были только по небольшим территориям. Набравшись смелости, я написал в NASA письмо и примерно через неделю переписки, они выгрузили мне необходимые данные, за что им огромное спасибо. Там правда данные оказались в каком хитром спутниковом бинарном формате, который я, наверное, неделю разгребал.
Все закончилось хорошо, и я посчитал нужные мне метрики по перепадам высот для всего мира с шагом в 10 км. Кстати, побочно я сделал свой сервис API, который возвращает высоту над уровнем моря по координатам и опубликовал его тут algorithmia.com/algorithms/Gaploid/Elevation. Он работает на Azure Tables, куда я хитро уместил данные и буквально за центры храню их там. Кстати, даже кто-то пару раз купил доступ к API, так как он получается дешевле, чем от Google.
ИТОГО. Потратив примерно около 4 месяцев поиска, очистки, калькуляций в QGIS, я получил дата сет данных, которые мог использовать в моделях машинного обучения. И который содержал примерно 20 различных параметров по следующим категориям: Климат, Рельеф, Инфраструктура, Необходимость или Потребители.
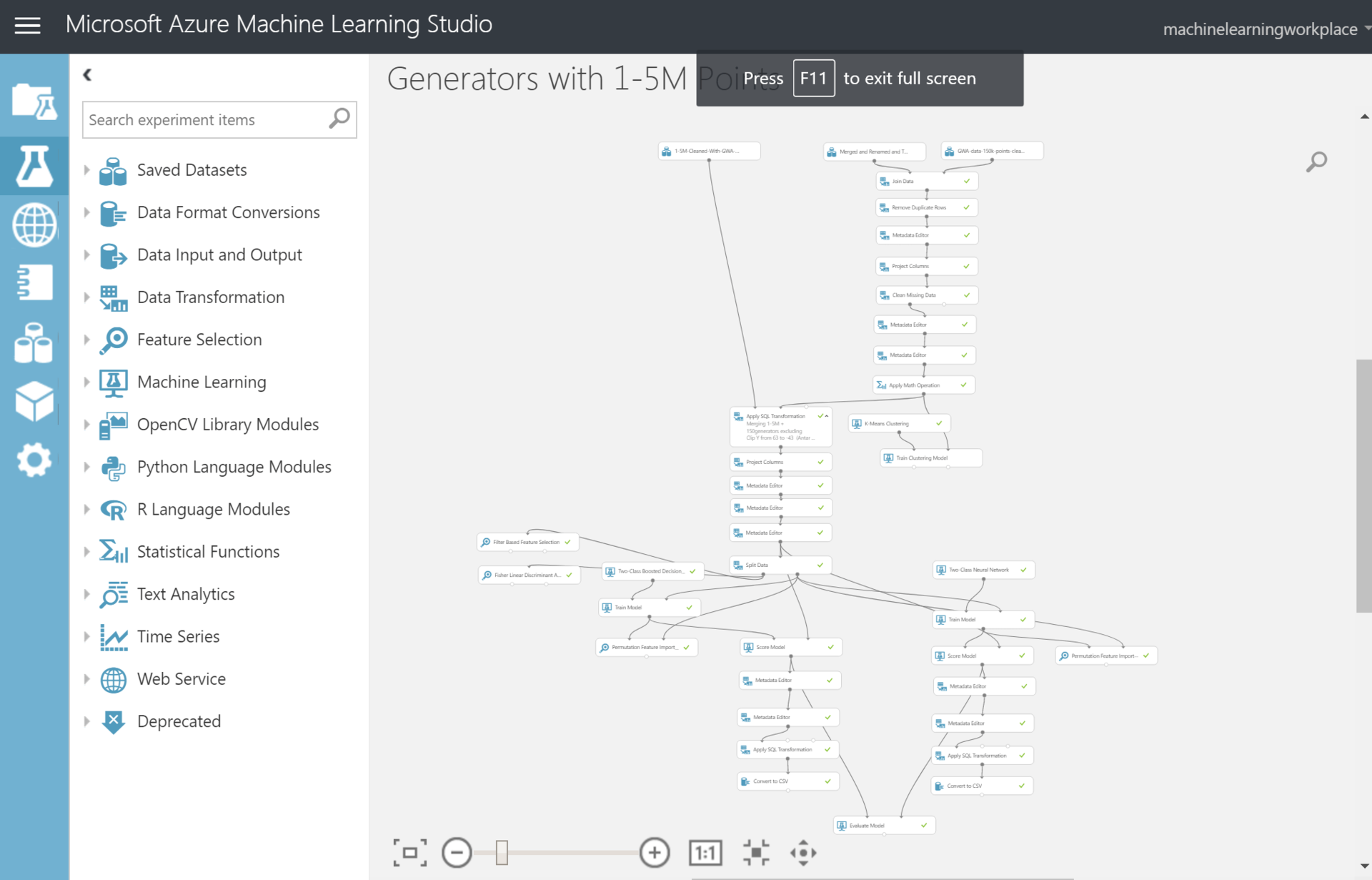
На тот момент у меня уже были некоторые знания и понимание как работают алгоритмы машинного обучения, но разворачивать все эти Питоны и Анаконды не сильно хотелось. Поэтому я воспользовался онлайн-сервисом для чайников без смс от Microsoft Azure ML Studio. Подкупило, что он бесплатен и все можно сделать мышкой в браузере. Тут по идее должно быть описание, как я потратил еще месяц на создании модели, кластеризации данных и прочих вещей. Особенно сложно давались все эти кластеризации так как QGIS их очень долго делал на моем старом домашнем PC. В итоге эксперимент выглядит, вот так.

Итоговое количество точек, которые нужно было оценить, вышло около 1,5 млн. Каждая такая точка — это территория 10 на 10 км и так весь мир. Я убрал клетки, в которых уже стоят ветряки в радиусе 100 км, а также некоторые районы, и получил дата сет в ~1 500 000 записей. Модель давала оценку пригодности каждому такому квадратику на планете Земля. Использовал в основном нейронные сети и boosted decision trees. Точность на тех точках, где уже стоят ветряки и то что предсказала моя модель вышла такая: Accuracy – ~0,9; Precision -~0,9. Что как, мне кажется, довольно точно ну или где-то прошло переобучение. Из этого упражнения я получил:
В общей сложности я нашел порядка 30 000 самых подходящих мест (это новые места, где рядом на расстоянии 100 км не стоят ветряки).
Получив 30 000 точек с новыми местоположениями, я их визуализировал и выглядит это в виде heatmap.

Я сделал небольшой веб сайт, используя cartodb для визуализации карты и выложил всю карту мира – windcat.ch. Также я посчитал для каждой точки примерную выработку энергии c одного ветряка промышленного размера (50 м). Точки здесь раскрашены по объёму энергии, а не по оценке Probability из модели. На каждую точку можно нажать и там покажется “уверенность” модели в данной точке, я его назвал Goodness.
Еще я попытался проверить правдивость всего этого экспертным путем.
Визуальный осмотр: модель предсказывает точки, которые стелются по берегу, что похоже на правду, так как там будет хороший ровный ветер с водной глади.
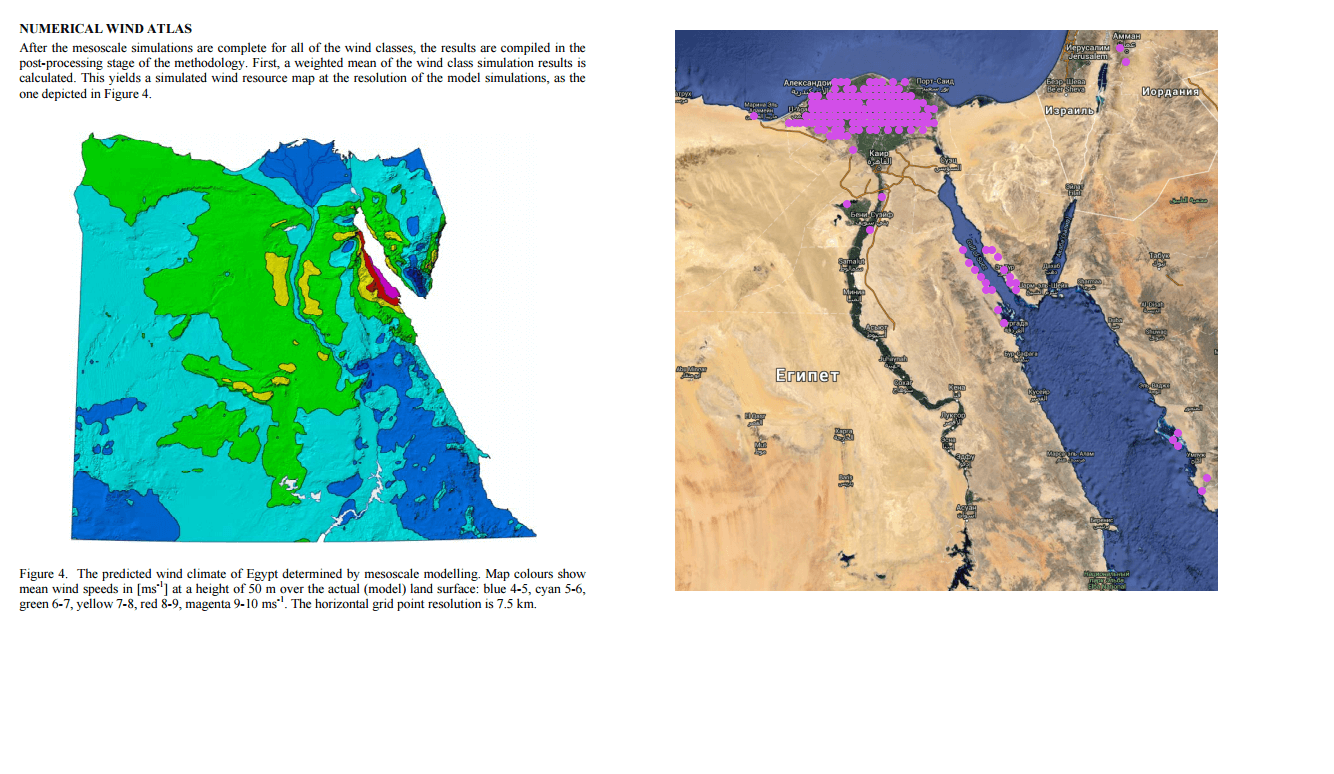
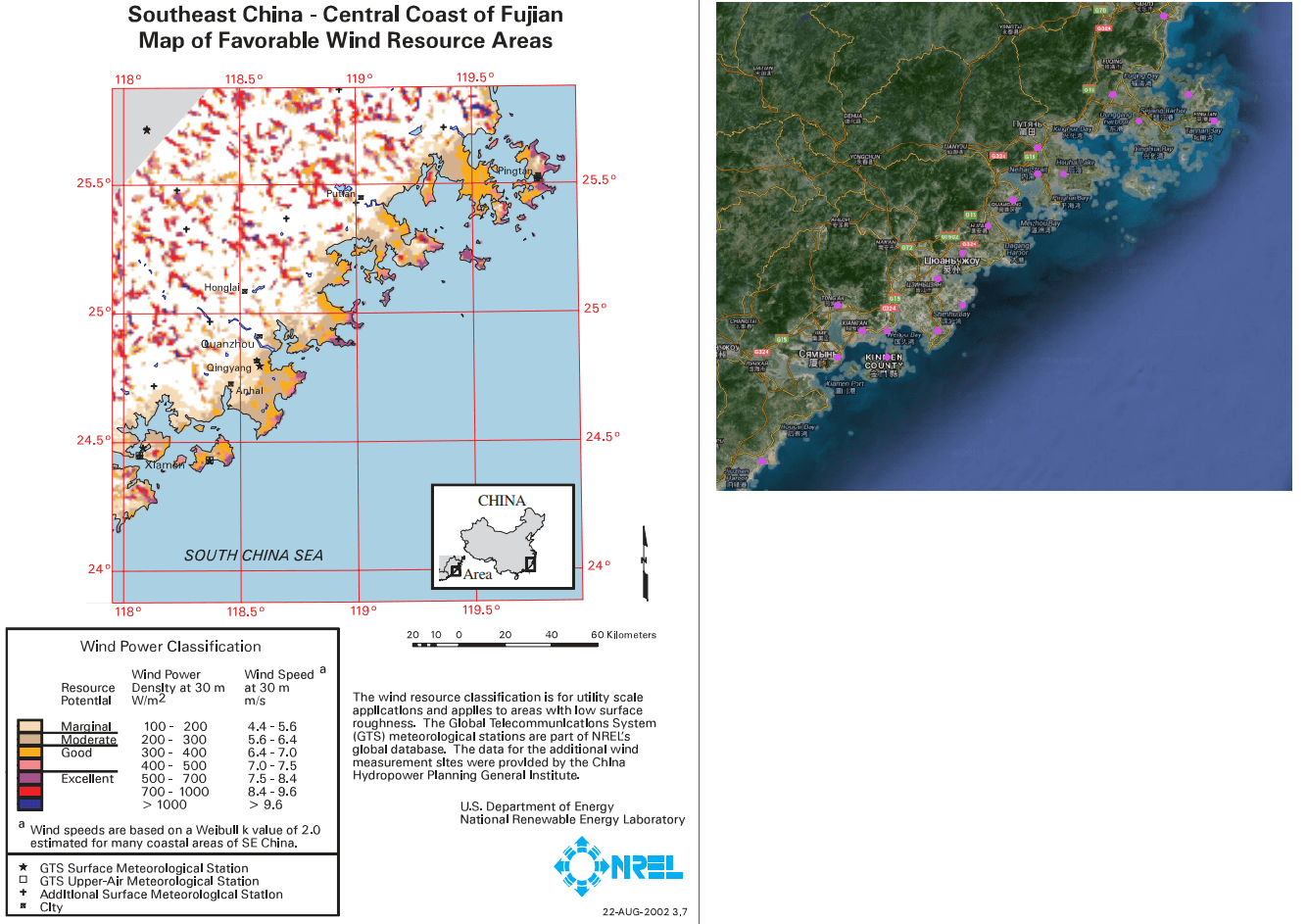
Визуальный осмотр: скопление точек в большей части совпадает с местами хорошей и отличной скорости и плотности воздуха, если сравнивать с картами ветров. К примеру вот Египет и Китай:

Мне иногда пишут и просят выслать более детальные карты мест или пояснить какие-то вещи на карте, но ничего большего пока из этого не вышло. Теоретически можно пересчитать данные не с шагом в 10 км, а в 100 метров и по идее картинка может сильно измениться, и по идее она сможет предсказывать не только район, но и конкретную точку размещения. Но для этого нужно несколько больше вычислительных мощностей, которых у меня пока нет. Если есть идеи применения буду рад их услышать.
Предыстория
Кажется, года два назад, а может быть уже и три, объявили о программе раздачи бесплатных гектаров на Дальнем Востоке России. Быстренько посмотрев на карту, стало понятно, что просто так выбрать правильный гектар не так уж и просто, а лучшие и очевидные места около городов, наверняка отойдут или уже отошли местным. Наверное, именно в этот момент у меня и возникла идея, что можно как-то автоматизировать поиск наилучшего места.
Начав романтично размышлять дальше, я подумал, что не обязательно смотреть на Дальний Восток. Сейчас полно земли, которая никому нигде не нужна, но это может измениться, лет эдак через 50, когда ископаемое топливо начнет подходить к концу. И люди пойдут искать новые источники энергии. Тогда я и начал смотреть на возобновляемые источники энергии. И очень быстро понял, что карта ресурсов и территорий, где эту новую энергию можно будет добывать, сильно изменится. Найдя сейчас такие места, можно их приобрести заранее и быть богатеем потом. Прикинув ещё, мне представилось что за пару выходных это можно запросто сделать… Сейчас оглядываясь назад, я понимаю, что на это у меня ушло около года. Хочу сразу отметить, что тогда я не сильно разбирался ни в энергетике, ни в возобновляемых источниках, ни в машинном обучении. Ниже краткий пересказ моего годовалого проекта.
Выбор типа возобновляемого источника энергии
Определившись с идеей, я быстренько пошел смотреть, а какие вообще бывают возобновляемые источники энергии и какой из них самые энергетический. Вот неполные, но самые распространенный список:
- солнечное излучение (гелиоэнергетика);
- энергия ветра (ветроэнергетика);
- энергия рек и водотоков (гидроэнергетика);
- энергия приливов и отливов;
- энергия волн;
- геотермальная энергия;
- рассеянная тепловая энергия: тепло воздуха, воды, океанов, морей и водоемов;
- энергия биомассы,
Но как определить какой из них самые лучший и победит в будущем всех остальных? Почитав еще немного интересных статей из журналов “Наука и жизнь” и ”Юный техник”. Я вышел на методику LCOE (levelized cost of electricity) у которой принцип простой: умные дядьки пытаются оценить совокупную стоимость киловатт-часа энергии, учитывая производство, материалы, обслуживание и т.д. Ниже картинка по данным от 2016 с некоторой проекцией на 2022. Я взял картинку посвежее отсюда, ниже скучная табличка из этого документа.
Вообще таких картинок у меня тьма для разных стран, сделанные разными организациями и всё выглядит примерно одинаково:
- На первом месте Геотермальная энергия.
- Дальше Гидроэлектроэнергия, но это зависит уже сильно от страны.
- На третьем месте Ветер.
Геотермальная и гидро мне не понравились, так как на мой взгляд, мест, где можно было бы добывать эту энергию можно пересчитать по пальцам. Ветер и Солнце — это другое дело, так как ставить их можно чуть ли не на каждую крышу и балкон. Солнце оказалось дороже, а три года назад разница была больше еще процентов на 30, я выбрал Ветер.
Кстати, уже в середине проекта, я начал наталкиваться на документы с похожими размышлениями государства США, а именно организаций NREL, Департамента Энергетики США и прочими, которые делали прогнозы и ставки на разные источники энергетики для того, чтобы уже сейчас понять каким образом модернизировать энергетическую систему страны. К примеру, в одном из таких документов все сводилось к нескольким вариантам: доля ветровой энергии будет большой или очень большой.
Как я всё хотел провернуть
Идея как это провернуть была довольна проста и выглядела так:
- Найти места, где находятся ветряки по миру.
- Собрать информацию в этих точках:
a. Скорость ветра.
b. Направление.
c. Температуру.
d. Рельеф.
e. Что любят на обед местные рыбаки.
f. И т.д.
- Отдать эту информацию в модель машинного обучения, которая обучалась бы и нашла закономерности, какие параметры лучше всего влияют на выбор места строительства человеком.
- Отдать обученной модели, все точки оставшиеся точки по миру с такой же информацией по ней.
- Получить на выходе список тех точек, которые отлично подходят для размещения ветряка.
В графическом виде этот план, как оказалось позднее, был похож вот на эту известную картинку:
Как всё было на самом деле
Первый этап был довольно лёгким. Я просто выгрузил все записи о точках из OpenStreetMaps.
Кстати, хочу заметить, что OSM — это просто кладезь информации об объектах по всему миру с их координатами, там есть практически все. Поэтому на заметку любителям данных, OSM — это крутейший Big Data источник.
Сделать это было не очень трудно.Сначала я попытался с помощью онлайн-утилит, кажется здесь overpass-turbo.eu, кстати очень крутая штука, но не вышло из-за ограничений по количеству точек и не очень быстрой работе на большом количестве данных. Поэтому пришлось разобраться с утилитами, которые выгружали данные из слепка OSM данных локально. Выкачать всегда актуальный слепок можно вот тут? В сжатом виде он занимает порядка 40ГБ. Данные из него можно выгружать запросами с помощью вот этой утилиты Osmosis. В итоге у меня был дата сет на 140 тысяч точек по миру с координатами и heatmap. Он выглядел примерно вот так:
Все проблемы начались во втором этапе, так как я не очень понимал какую информацию нужно было собрать. Поэтому на пару дней я ушел в чтение принципов работы ветряков и рекомендаций по их размещению, ограничений и т.д. У меня даже в заметках остались вот такие забавные схемы про размещение, градиенты ветров, розы ветров и прочие другие полезные термины.
В итоге у меня получился вот такой список параметров, которые, по моему мнению, важны при выборе места:
- Средняя скорость ветра в год (идеально 10-11м/c).
- Направление ветра (Господствующее направление-роза ветров).
- Минимальная скорость ветра.
- Максимальная скорость ветра .
- Power density.
- Средняя температура.
- Средняя влажность.
- Среднее давление.
- Высота над уровнем моря.
- Расстояние до воды.
- Перепад высоты.
- Гладкость перепадов высоты.
- Максимальный перепад на площади 5-10км.
- Процент деревьев или насаждений на площади (шереховатость).
- Расстояние до населенного пункта.
- Расстояние до промышленного объекта.
- Среднее количество жителей на площади.
- Расстояние до дороги (морской, авиа).
- Расстояние до сети электроэнергии.
- Визуальный и звуковые неудобства.
- Охранные территория: заповедники и тд.
- Обледенение.
Большие данные
ВЕТЕР. Собственно, как 90% всех проектов по big data ломаются на стадии “так теперь давайте глянем на ваши данные про которые вы так много говорили”, дал трещину и мой. Побежав искать данные по скорости ветра в России, я наткнулся на это:
И еще с десяток похожих и бесполезных картинок. Тут я начал догадываться, что возможно в России и правда нет ветровой энергетики, так как у нас просто не дует ветер в достаточной силе и где-то в этот момент послышался смех Сечина. Но я же отчетливо помню, что в Самарской области одни степи и очень часто выходя за хлебом в детстве меня сдувало обратно в подъезд.
Начав искать данные по России и то что, я понял, что это не было похоже на те данные, с которыми можно было сделать что-то полезное. Поэтому я двинулся к зарубежным источникам и тут же нашел прекрасные ветровые карты от Tier3 (Vaisala). На вид разрешение было достаточным и покрытие всего мира было просто отличным. Дальше я понял, что такие данные стоят неплохих денег около ~$1000 за 10 квадратных км (данные трех годовалой давности). Провал, подумал я.
Погрустив неделю, я решил написать Vaisala, Tier3 и другие консалтинговые зарубежные агентства по работе с ветрами и прочими ветровыми генераторами, и попросить данные. Я подумал, что, рассказав какую классную идею я собираюсь сделать, все сразу мне всё сгрузят.. Ответил только один — из компании Sander-Partner. Сам Sander дал некоторые советы, а также дал ссылки на то, что мне нужно: данные программы MERRA, который ведет NASA. Стоит обратить внимание, что у меня ушла примерно неделя вечеров, чтобы разобраться что такое Reanalysis, WRF и примерно понять, что как вообще происходит: сбор, агрегация, симулирование и предсказание погоды, ветров и прочих вещей.
Если кратко, то человечество насобирало кучу данных о погоде, нарисована куча карт со средними температурами и скоростью ветра, но собрать все эти данные в каждой точке земного шара как было было, так и остаётся невозможно, поэтому белые пятна заполнили результатами симуляции погоды на прошлые годы и назвали это Reanalysis. К примеру, вот сайт с визуализацией таких симуляций ветра а вот как это выглядит:
Эти данные представляли из себя по сути .csv файл сетки координат со средней скоростью ветра с большим шагом, я сделал вот такую карту с помощью наикрутейшего бесплатного пакета QGIS и метода интерполяции сетки данных.
А затем с помощью него же вытащил из этой карты данные по скорости ветра по каждой паре координат. По сути у меня получилась карта, и слой данных для каждого пикселя на ней.
Поняв принцип работы с QGIS примерно за пару недель, я начал строить такие же карты для остальных источников данных и вытаскивать по координатам значения. Для температуры, влажности, давления и прочих вещей. Тут нужно заметить, что сами массивы данных в основном я брал у NASA, NOAA, ESA, WorldClim и т.д. Все они в свободном доступе. C помощью QGIS делал расчеты и поиск расстояния до ближайших точек, от городов, аэропортов и прочих инфраструктурных объектов. Каждая карта по одному параметру считалась у меня порядка 6-8 часов. И если что-то было неправильно приходилось делать это снова и снова. Домашний компьютер шелестел у меня по ночам где-то пару недель, но после этого даже соседям надоело слушать разболтанный кулер на нем и я переполз в облако, где поднял небольшую виртуалку для расчета.
Уже по прошествии нескольких месяцев я натолкнулся вот на этот сайт, сделанный кафедрой ветровой энергетики Дании (DTU Wind Energy). Стало быстро понятно, что разрешение у них в разы лучше моей карты, я списался с ними и они с удовольствием выгрузили мне данные по всему миру, так как через сайт можно получить только небольшие слепки по территории. Кстати, они так же сделали эту карту используя симуляцию движения слоев ветра моделями WRF, WAsP и добились разрешения данных до 50-100 метров, как у меня было примерно 1-10км.
РЕЛЬЕФ. Помните я писал, что рельеф очень важен, так вот я решил так же использовать и этот параметр, но с ним оказалось тоже все не просто. Сначала я написал утилиту, которая выкачивала данные из Google Elevation API. Она отлично справилась и качала данные по всем моим точкам всего мира с шагом в 10 км, потребовалась всего-то порядка 12 часов работы. Но у меня также были параметры гладкости рельефа или среднее значение перепада на территории вокруг потенциальной точки размещения ветряка. То есть мне нужны были данные с шагом метров в 100-200 всего мира, с помощью которых я бы уже смог посчитать среднее значения перепада.
Для того, чтобы посчитать перепады, потребовалось бы пару месяцев на выкачивание данных из Google Elevation. Поэтому я пошел искать другие варианты.
Первое, что я нашёл — Wolfram cloud, у которых уже были необходимые данные. Просто написав формулу, эта штука начинала считать, используя данные из облака Wolfram. Но там меня тоже ждал провал, так как я наткнулся в какие-то лимиты, которые нигде не были указаны и получив смешную переписку с поддержкой этого сервиса я пошел искать другой вариант.
Тут мне опять помогли источники данных в NASA и данные с космической программы STRM (NASA Shuttle Radar Topography Mission Global). Я честно их пытался выкачать с сайта, но там данные были только по небольшим территориям. Набравшись смелости, я написал в NASA письмо и примерно через неделю переписки, они выгрузили мне необходимые данные, за что им огромное спасибо. Там правда данные оказались в каком хитром спутниковом бинарном формате, который я, наверное, неделю разгребал.
Все закончилось хорошо, и я посчитал нужные мне метрики по перепадам высот для всего мира с шагом в 10 км. Кстати, побочно я сделал свой сервис API, который возвращает высоту над уровнем моря по координатам и опубликовал его тут algorithmia.com/algorithms/Gaploid/Elevation. Он работает на Azure Tables, куда я хитро уместил данные и буквально за центры храню их там. Кстати, даже кто-то пару раз купил доступ к API, так как он получается дешевле, чем от Google.
ИТОГО. Потратив примерно около 4 месяцев поиска, очистки, калькуляций в QGIS, я получил дата сет данных, которые мог использовать в моделях машинного обучения. И который содержал примерно 20 различных параметров по следующим категориям: Климат, Рельеф, Инфраструктура, Необходимость или Потребители.
Машинное обучение и предсказания
На тот момент у меня уже были некоторые знания и понимание как работают алгоритмы машинного обучения, но разворачивать все эти Питоны и Анаконды не сильно хотелось. Поэтому я воспользовался онлайн-сервисом для чайников без смс от Microsoft Azure ML Studio. Подкупило, что он бесплатен и все можно сделать мышкой в браузере. Тут по идее должно быть описание, как я потратил еще месяц на создании модели, кластеризации данных и прочих вещей. Особенно сложно давались все эти кластеризации так как QGIS их очень долго делал на моем старом домашнем PC. В итоге эксперимент выглядит, вот так.
Итоговое количество точек, которые нужно было оценить, вышло около 1,5 млн. Каждая такая точка — это территория 10 на 10 км и так весь мир. Я убрал клетки, в которых уже стоят ветряки в радиусе 100 км, а также некоторые районы, и получил дата сет в ~1 500 000 записей. Модель давала оценку пригодности каждому такому квадратику на планете Земля. Использовал в основном нейронные сети и boosted decision trees. Точность на тех точках, где уже стоят ветряки и то что предсказала моя модель вышла такая: Accuracy – ~0,9; Precision -~0,9. Что как, мне кажется, довольно точно ну или где-то прошло переобучение. Из этого упражнения я получил:
- Во-первых точки, в которых модель сказала, что это отличное новое место для ветряка.
- Во-вторых, точки, в которых модель сказала, где места не очень хорошие.
В общей сложности я нашел порядка 30 000 самых подходящих мест (это новые места, где рядом на расстоянии 100 км не стоят ветряки).
Результат и проверка достоверности
Получив 30 000 точек с новыми местоположениями, я их визуализировал и выглядит это в виде heatmap.
Я сделал небольшой веб сайт, используя cartodb для визуализации карты и выложил всю карту мира – windcat.ch. Также я посчитал для каждой точки примерную выработку энергии c одного ветряка промышленного размера (50 м). Точки здесь раскрашены по объёму энергии, а не по оценке Probability из модели. На каждую точку можно нажать и там покажется “уверенность” модели в данной точке, я его назвал Goodness.
Еще я попытался проверить правдивость всего этого экспертным путем.
Визуальный осмотр: модель предсказывает точки, которые стелются по берегу, что похоже на правду, так как там будет хороший ровный ветер с водной глади.
Визуальный осмотр: скопление точек в большей части совпадает с местами хорошей и отличной скорости и плотности воздуха, если сравнивать с картами ветров. К примеру вот Египет и Китай:

Что дальше
Мне иногда пишут и просят выслать более детальные карты мест или пояснить какие-то вещи на карте, но ничего большего пока из этого не вышло. Теоретически можно пересчитать данные не с шагом в 10 км, а в 100 метров и по идее картинка может сильно измениться, и по идее она сможет предсказывать не только район, но и конкретную точку размещения. Но для этого нужно несколько больше вычислительных мощностей, которых у меня пока нет. Если есть идеи применения буду рад их услышать.


{kind=link}