Необходимое предисловие: я решил попробовать современный формат несения света в массы и пробую стримить на YouTube про deep learning.
В частности, в какой-то момент меня попросили рассказать про attention, а для этого нужно рассказать и про машинный перевод, и про sequence to sequence, и про применение к картинкам, итд итп. В итоге получился вот такой стрим на час:
Я так понял по другим постам, что c видео принято постить его транскрипт. Давайте я лучше вместо этого расскажу про то, чего в видео нет — про новую архитектуру нейросетей для работы с последовательностями, основанную на attention. А если нужен будет дополнительный бэкграунд про машинный перевод, текущие подходы, откуда вообще взялся attention, итд итп, вы посмотрите видео, хорошо?
Новая архитектура называется Transformer, была разработана в Гугле, описана в статье Attention Is All You Need (arxiv) и про нее есть пост на Google Research Blog (не очень детальный, зато с картинками).
Поехали.
Сверх-краткое содержание предыдущих серий
Задача машинного перевода в deep learning сводится к работе с последовательностями (как и много других задач): мы тренируем модель, которая может получить на вход предложение как последовательность слов и выдать последовательность слов на другом языке. В текущих подходах внутри модели обычно есть энкодер и декодер — энкодер преобразует слова входного предложения в один или больше векторов в неком пространстве, декодер — генерирует из этих векторов последовательность слов на другом языке.
Стандартные архитектуры для энкодера — RNN или CNN, для декодера — чаще всего RNN. Дальнейшее развитие навернуло на эту схему механизм attention и про это уже лучше посмотреть стрим.
И вот предлагается новая архитектура для решения этой задачи, которая не является ни RNN, ни CNN.
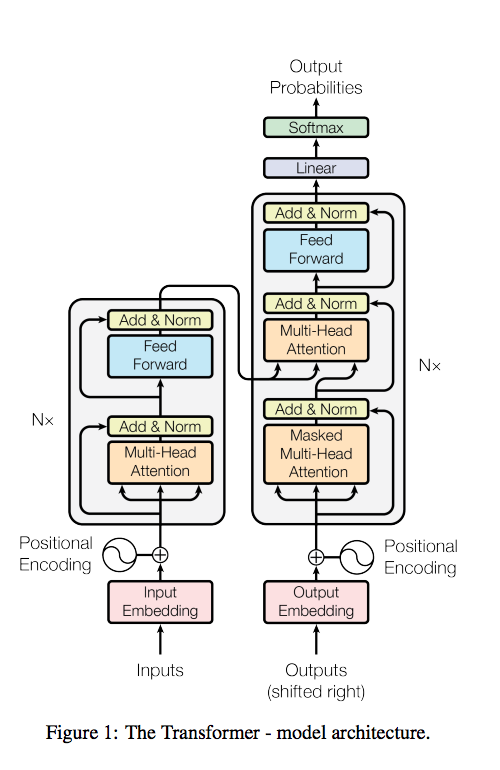
Вот основная картинка. Что в ней что!
Энкодер и Multi-head attention layer
Рассмотрим для начала энкодер, то есть часть сети, которая получает на вход слова и выдает некие эмбеддинги, соответствующие словам, которые будут использоваться декодером.
Вот он конкретно:
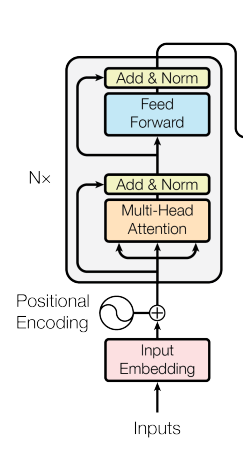
Идея в том, что каждое слово параллельно проходит через слои, изображенные на картинке.
Некоторые из них — это стандартные fully-connected layers, некоторые — shortcut connections как в ResNet (там, где на картинке Add).
Но новая интересная вещь в этих слоях — это Multi-head attention. Это специальный новый слой, который дает возможность каждому входному вектору взаимодействовать с другими словами через attention mechanism, вместо передачи hidden state как в RNN или соседних слов как в CNN.
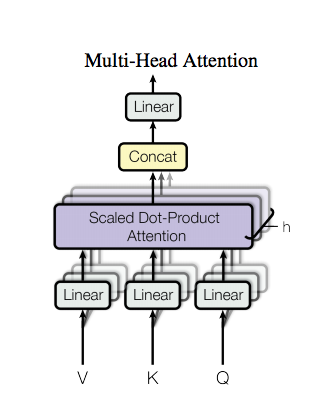
Ему на вход даются вектора Query, и несколько пар Key и Value (на практике, Key и Value это всегда один и тот же вектор). Каждый из них преобразуется обучаемым линейным преобразованием, а потом вычисляется скалярное произведение Q со всеми K по очереди, прогоняется результат этих скалярных произведений через softmax, и с полученными весами все вектора V суммируются в единый вектор. Эта формулировка attention очень близка к предыдущим работам, где используется attention.
Единственное, что они к нему дополняют — что таких attention'ов параллельно тренируется несколько (их количество на картинке обозначено через h), т.е. несколько линейных преобразований и параллельных скалярных произведений/взвешенных сумм. И потом результат всех этих параллельных attention'ов конкатенируется, еще раз прогоняется через обучаемое линейное преобразование и идет на выход.
Но в целом, каждый такой модуль получает на вход вектор Query и набор векторов для Key и Value, и выдает один вектор того же размера, что и каждый из входов.
Непонятно, что это дает. В стандартном attention "интуиция" ясна — сеть attention пытается выдать соответствие одного слова другому в предложении, если они близки чем-то. И это одна сеть. Здесь тоже самое, но куча сетей параллельно? И делают они тоже самое, а выход конкантенируется? Но в чем тогда смысл, не обучатся ли они в точности одному и тому же?
Нет. Если есть необходимость обращать внимание на несколько аспектов слов, то это дает сети возможность это сделать.
Такой трюк используется довольно часто — оказывается, что тупо разных начальных случайных весов хватает, чтобы толкать разные слои в разные стороны.
Что такое несколько аспектов слов?.
Например, у слова есть фичи про его смысловое значение и про грамматическое.
Хочется получить вектора, соответствующие соседям с точки зрения смысловой составляющей и с грамматической.
Так как на выход такой блок выдает вектор того же размера, что и был на входе, то этот блок можно вставлять в сеть несколько раз, добавляя сети глубину. На практике, они используют комбинацию из Multi-head attention, residual layer и fully-connected layer 6 раз, то это есть это такая достаточно глубокая сеть.
Последнее, что нужно сказать — это что одной из фич каждого слова является positional encoding — т.е. его позиция в предложении. Например, от этого в процессе обработки слова легко "обращать внимание" на соседние слова, если они важны.
Они используют в качестве такой фичи вектор того же размера, что и вектор слова, и который содержит синус и косинус от позиции с разными периодами, чтобы мол было просто обращать внимание по относительным оффсетам выбирая координату с нужным периодом.
Пробовали вместо этого эмбеддинги позиций тоже учить и получилось тоже самое, что с синусами.
Еще у них воткнут LayerNormalization (arxiv). Это процедура нормализации, которая нормализует выходы от всех нейронов в леере внутри каждого сэмпла (в отличие от каждого нейрона отдельно внутри батча, как в Batch Normalization, видимо потому что BN им не нравился).
Говорят, BN в рекуррентных сетях не работает, так как статистика нормализации для разных предложений одного батча только портит всё, а не помогает, так как предложения все разной длины и все такое. В этой архитектуре тоже такой эффект ожидается и BN вреден?
Почему они не взяли BN — интересный вопрос, в статье особо не комментируется. Вроде бы были удачные попытки использовать с RNN например в speech recognition. Deep Speech 2 от Baidu (arxiv), AFAIR
Попробуем резюмировать работу энкодера по пунктам.
Работа энкодера:
- Делаются эмбеддинги для всех слов предложения (вектора одинаковой размерности). Для примера пусть это будет предложение
I am stupid. В эмбеддинг добавляется еще позиция слова в предложении. - Берется вектор первого слова и вектор второго слова (
I,am), подаются на однослойную сеть с одним выходом, которая выдает степень их похожести (скалярная величина). Эта скалярная величина умножается на вектор второго слова, получая его некоторую "ослабленную" на величину похожести копию. - Вместо второго слова подается третье слово и делается тоже самое что в п.2. с той же самой сетью с теми же весами (для векторов
I,stupid). - Делая тоже самое для всех оставшихся слов предложения получаются их "ослабленные" (взвешенные) копии, которые выражают степень их похожести на первое слово. Далее эти все взвешенные вектора складываются друг с другом, получая один результирующий вектор размерности одного эмбединга:
output=am * weight(I, am) + stupid * weight(I, stupid)
Это механизм "обычного" attention. - Так как оценка похожести слов всего одним способом (по одному критерию) считается недостаточной, тоже самое (п.2-4) повторяется несколько раз с другими весами. Типа одна один attention может определять похожесть слов по смысловой нагрузке, другой по грамматической, остальные еще как-то и т.п.
- На выходе п.5. получается несколько векторов, каждый из которых является взвешенной суммой всех остальных слов предложения относительно их похожести на первое слово (
I). Конкантенируем этот вректор в один. - Дальше ставится еще один слой линейного преобразования, уменьшающий размерность результата п.6. до размерности вектора одного эмбединга. Получается некое представление первого слова предложения, составленное из взвешенных векторов всех остальных слов предложения.
Такой же процесс производится для всех других слов в предложении.
- Так как размерность выхода та же, то можно проделать все тоже самое еще раз (п.2-8), но вместо оригинальных эмбеддингов слов взять то, что получается после прохода через этот Multi-head attention, а нейросети аттеншенов внутри взять с другими весами (веса между слоями не общие). И таких слоев можно сделать много (у гугла 6). Однако между первым и вторым слоем добавляется еще полносвязный слой и residual соединения, чтобы добавить сети выразительности.
В блоге у них про этот процесс визуализируется красивой гифкой — пока смотреть только на часть про encoding:

И в результате для каждого слова получается финальный выход — embedding, на которой будет смотреть декодер.
Переходим к декодеру
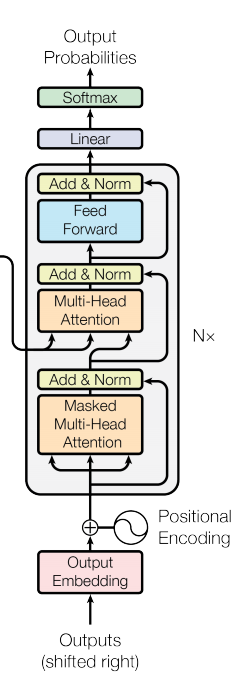
Декодер тоже запускается по слову за раз, получает на вход прошлое слово и должен выдать следующее (на первой итерации получает специальный токен <start>).
В декодере есть два разных типа использования Multi-head attention:
- Первый — это возможность обратиться к векторам прошлых декодированных слов, также как и было в процессе encoding (но можно обращаться не ко всем, а только к уже декодированным).
- Второй — возможность обратиться к выходу энкодера. B этом случае Query — это вектор входа в декодере, а пары Key/Value — это финальные эмбеддинги энкодера, где опять же один и тот же вектор идет и как key, и как value (но линейные преобразования внутри attention module для них разные)
В середине еще просто FC layer, опять те же residual connections и layer normalization.
И все это снова повторяется 6 раз, где выход предыдущего блока идет на вход следующему.
Наконец, в конце сети стоит обычный softmax, который выдает вероятности слов. Сэмплирование из него и есть результат, то есть следующее слово в предложении. Мы его даем на вход следующему запуску декодера и процесс повторяется, пока декодер не выдаст токен <end of sentence>.
Разумеется, это все end-to-end дифференцируемо, как обычно.
Теперь на гифку можно посмотреть целиком.
Во время энкодинга каждый вектор взаимодействует со всеми другими. Во время декодинга каждое следующее слово взаимодействует с предыдущими и с векторами энкодера.
Результаты
И вот это добро прилично улучшает state of the art на machine translation.
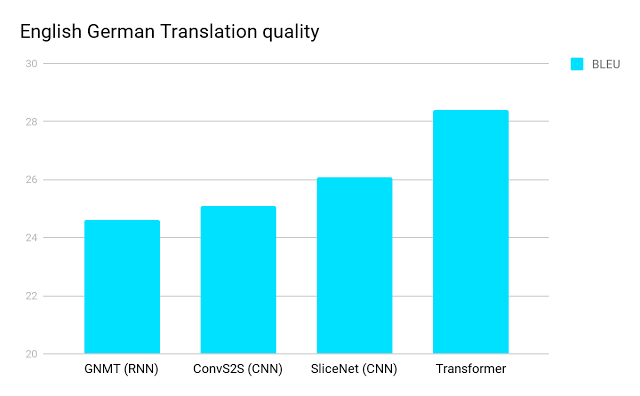
2 пункта BLEU — это достаточно серьезно, тем более, что на этих значениях BLEU все хуже коррелирует с тем, насколько перевод нравится человеку.
В целом, основное нововведение — это использование механизма self-attention чтобы взаимодействовать с другими словами в предложении вместо механизмов RNN или CNN.
Они теоретизируют, что это помогает, потому что сеть может с одинаковой легкостью обратиться к любой информации вне зависимости от длины контекста — обратиться к прошлому слову или к слову за 10 шагов назад одинаково просто.
От этого и проще обучаться, и можно проводить вычисления параллельно, в отличие от RNN, где нужно каждый шаг делать по очереди.
Еще они попробовали ту же архитектуру для Constituency Parsing, то есть грамматического разбора, и тоже все получилось.
Я пока не видел подтверждения, что Transformer уже используется в продакшене Google Translate (хотя надо думать используется), а вот использование в Яндекс.Переводчике было упомянуто в интервью с Антоном Фроловым из Яндекса (на всякий случай, таймстемп 32:40).
Что сказать — молодцы и Гугл, и Яндекс! Очень клево, что появляются новые архитектуры, и что attention — уже не просто стандартная часть для улучшения RNN, а дает возможность по новому взглянуть на проблему. Так глядишь и до памяти как стандартного куска доберемся.

