
Меня зовут Максим, и я
На волне про соискателей скажу, что регулярно провожу собеседования мобильных разработчиков для компаний.
Среди кандидатов попадаются кадры, которые курят кальян прямо на Skype собеседовании, пытаются гуглить вопросы на ходу, хотят ЗП 180к за 3 месяца опыта, ведут себя так, как будто гоп-стопнули меня на улице (с соответствующей терминологией) и так далее.
Но в большинстве случаев, даже у адекватных middle специалистов, есть общий пробел: непонимание принципов асинхронного выполнения задач и работы аппаратного ускорения в iOS.
В этой статье я решил простыми словами рассказать про применение многопоточности в iOS, чтобы уже после первого прочтения можно было легко и с полным пониманием использовать полученные знания на практике.
(Если лень читать, то прилагается видео)
Материала будет два, один посвященный многопоточности (вот этот), а второй по аппаратному ускорению: как равномерно распределять нагрузку между CPU и GPU, чтобы получить идеально-плавный интерфейс.
Для тех, кому интересно не только научиться применять методики, но еще и постичь дзен, есть отличная статья. Она, правда, еще для Swift 3, но суть за это время не изменилась.
ШОК! Истинные причины лагов!
Как мне сказал один эксперт на собеседовании: приложение тормозит из-за того, что сигнал от сервера не может идти быстрее скорости света. И в этот промежуток все лагает.
Так что, физика, бессердечная ты сволочь. Тайна раскрыта, расходимся.
Так что, физика, бессердечная ты сволочь. Тайна раскрыта, расходимся.
Краткая практическая теория
Практическая теория — это такая теория, без которой ты не нацеленный на результат практик, а просто необразованный дикарь.
И перед тем как начать фантазировать на тему асинхронности, потоков и прочих премудростей, надо ответить на вопрос: зачем нужно что-то параллелить? Вот есть главный поток, почему бы все на нем не крутить? Надеюсь, для многих очевидный ответ: потому что все будет тормозить, але.
И чем главный поток такой особенный тогда? Его исключительность в том, что на нем происходит все взаимодействие с приложением извне: обработка касаний, уведомления, системные сообщения и прочее.
А основное в нашем случае это то, что на main thread висит весь responder chain:
UIApplication -> UIWindow -> UIViewController -> UIView.
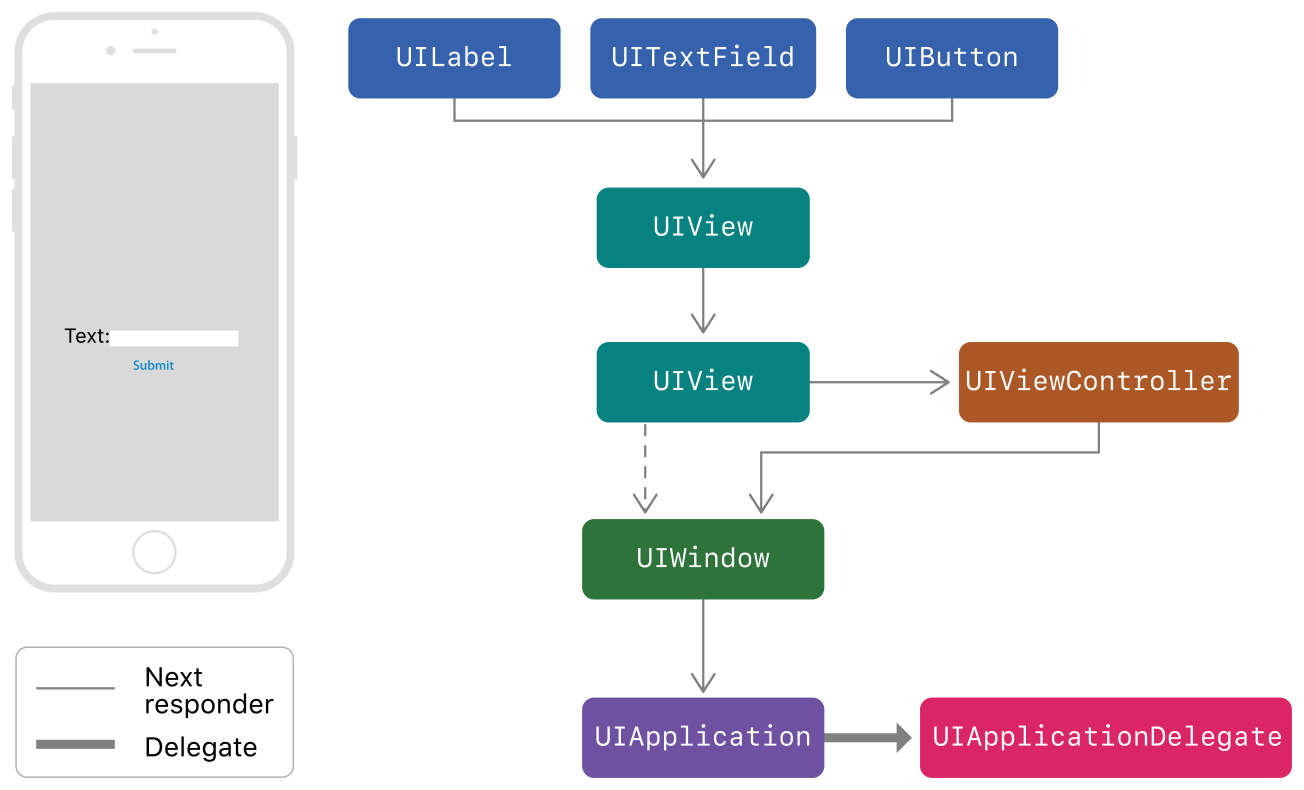
Все нажатия на экран, все взаимодействие с пользователем, приходят именно туда.
Но ладно, пускай нажатия обрабатывается на главном потоке, но, черт побери, Apple, почему я не могу, как Клинт Иствуд, рисовать с двух рук-то?
Да потому что для общения нескольких потоков придется обмазаться толстым слоем штуковин для синхронизации, а это все ненужное барахло и давление на без того куцые ресурсы. Apple даже ввел Main Thread Checker, чтобы помочь избежать всяких экзотичных багов, вызванных негуманным обращением с главным потоком.
В общем, первое правило — это оставьте main thread для UI, а UI для main thread.
Ладно, а где же тогда делать все остальное?
В iOS есть полно инструментов для этих целей: треды, posix треды, gcd, operation queue.
У каждого есть свое применение, но в повседневной жизни, состоящей из банальных задач по типу: сходи на сервер, принеси, сохрани и выведи на экран, достаточно gcd и operation queue.
GCD — это библиотека Apple для параллельного выполнения задач. Состоит из выполняемых операций (задач) и очередей, которые содержат эти самые операции. Самая банальная FIFO коллекция с тасками. Конечно, там есть еще куча опций, но они нам пока не нужны.
NSOperationQueue — та же очередь, только высокоуровневая и ООП ориентированная. А по сути, просто красивая обертка над gcd, никаких функциональных преимуществ не имеет, хотя раньше и давала.
Выбор между тем и другим, в большинстве случаев зависит от вкуса, за редким исключением. Работайте с тем, с чем вам удобнее. Лично я предпочитаю gcd из-за лучшей управляемости и отсутствия дополнительного оверхеда.
Кстати, среди разработчиков зачастило такое мракобесие, что якобы NSOperationQueue больше не базируется на GCD, а специально переработан для iOS и потому быстрее/выше/сильнее. Но это отнюдь не так, процитирую яблоко:Apple:

Так что специальных преимуществ у NSOperationQueue перед GCD нет.
Приоритеты GCD & NSOperationQueue
Пробежимся по основным компонентам.
У каждой очереди есть такое понятие как приоритет, с которой она получает ресурсы. Называется это — quality of service, чаще всего употребляется аббревиатурой 'qos' или качество услуг.
Чем выше приоритет, тем быстрее и больше процессорного времени выделяется под задачи на этой очереди. Да-да, именно еще и быстрее, вы не ослышались. Система может оптимизировать пробуждение процессора, тем самым экономя энергию. Это полезно помнить, если работаете с low power mode, когда у пользователя садится батарейка.
Так хочется, чтобы это узнали авторы Яндекс.Такси. Ведь можно экономить батарейку таким простым способом, а не устраивать «майнинг биткоинов» у меня на айфоне.
Какие же есть приоритеты? Их несколько и надо все запомнить, чтобы не было бесконечно больно. А то многие говорят, что это якобы нигде не освящается, и типа вовсе не нужно.
И так приоритеты: userInteractive, userInitiated, default, utility и background.
Main не считаем, потому что это не приоритет, а отдельная очередь для главного потока. У нее, кстати, тоже есть приоритет: userInteractive. Так что, например, запустив шаманство с картинками в отдельной queue с приоритетом userInteractive вы получите неиллюзорные лаги, потому что начнется гонка за ресурсы. Меньшие проблемы, чем если просто запустить в main, но зато сложнее отлаживаемые, потому как лаги будут непостоянны.
(есть еще unspecified, но это вообще дикость, с которой Вы вряд ли когда-нибудь столкнетесь)
Если хочется понять, как именно происходит перекидывания операций между очередями — выше приводил ссылку на статью.
Так когда какую задействовать?
- userInteractive — не надо применять вообще. Она негласно зарезервирована главным потоком, как я уже писал выше. Apple определяет спектр ее применения как: операции, критические для взаимодействия с пользователем, занимающие не более доли секунды. Звучит как штучка для UI, не правда ли? На практике у меня была только одна задача, которая должна была конкурировать с интерфейсом по скорости и требующая хирургической точности, но она решалась не через gcd. Короче, userInteractive — это для богов из Apple, а не простых работяг как мы.
- userInitiated — локальные операции, требующие мгновенного результата. Например, сохранение чего-либо в базу перед переходом на следующий экран. Но, при этом, не блокирующее UI. Особо акцентируюсь на том, что именно локальные операции. Сеть сюда не входит.
Допустим, крутите вы индикатор загрузки посреди экрана и надо срочно что-то сделать, чтобы показать контент. На главном потоке, очевидно, это делать нельзя, потому что начнет сбоить gui, но и слишком в глубоко в фон закидывать нет смысла, потому что из всего интерфейса одна единственная крутилочка крутится. В этом случае используется userInitiated. - default — дефолтный приоритет. Apple расходится во мнениях сама с собой, в документации говоря, что не надо его юзать, а на WWDC наоборот, заявляет, что это наилучший приоритет для загрузки картинок и прочих сетевых коммуникаций. Поигравшийся с разными QoS могу сказать, что default лучше всего подходит для загрузки изображений или небольших файлов, которые влияют на восприятие приложения пользователем. Разница между utlity (следующий уровень) и default реально ощущается при работе с изображениями, особенно при пре-рендеринге. Default отрабатывает значительно быстрее, но при этом не конкурирует с интерфейсом за ресурсы. Моя рекомендация — всю сетевую бизнес логику и изображения оставлять в дефолт.
- utility — что-то не слишком приоритетное, но все таки нужное в ближайшее время. Например, обработка громоздких файлов или сложные манипуляции с базой, конвертация медиа и так далее. Проще говоря, когда надо сделать насущную задачу для приложения, но где пара лишних секунд ожидания роли не сыграют. Кстати, такие операции — первый кандидат на перенос в background режим при работе с lower power mode.
- background — самый овощной режим из всех. Как говорится, для тех, кто познал жизнь и никуда не торопится. Применять стоит при экономии энергии, либо для сверх-тяжелых операций. Типа загрузки толстенных файлов, бэкапы и прочее. А если вдруг пользователь включил lower power mode, а ваша операция и так была в background приоритете, то может ну ее нафиг сразу, а?
Практика в реальном мире
Говоря о применении, если вы используете для какой-то задачи third-party фреймворк, то большинство инструментов делают работу на той очереди с которой были вызваны, либо поддерживают явное ее упоминание. Если не получилось за 5 минут найти способа явно указать приоритет, то проще значит просто оборачивать операцию в dispatch_async и не переживать.
Главное, обратите внимание, что часто callback-и вызываются на главном потоке по неким исторически сложившимся причинам. Бывает делаешь запрос с default qos, а потом дернул в completion блоке сохранение в базу, забыв, что ты уже дома. И чешешь репу, почему это приложение еле едет.
Так что если нет уверенности, то ставим брейкпоинт в блоке и смотрим по стеку вызовов. В таких моментах лучше перепроверить, чем потом искать лаги через профайлер. Обожаю на собеседованиях спрашивать про профайлер.
Главный поток:

Любой другой:
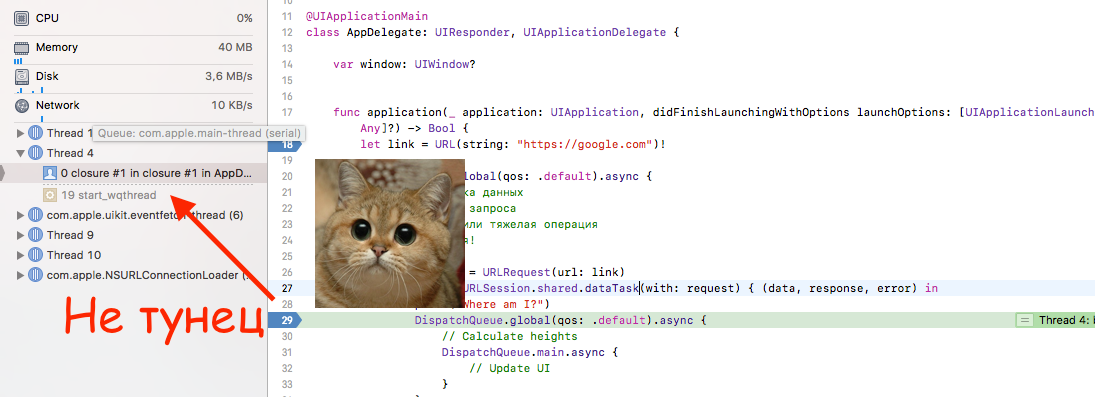
В общем, обязательно надо обращать внимание на каком потоке идет действие. Сохранит много нервов и времени потом.
Еще один нюанс, который возникает, когда упарываешься по асинхронности: а как много надо выносить в отдельные операции? Где граница? Каковы последствия?
Философски, если что-то асинхронится, то это можно асинхронить. Но будем подходить более прагматично: если ваше приложение слагается из множества долесекундных операций, то сначала следует подумать, можно ли эти мелочи заведомо объединить в некой более крупной задаче? Если плодить отдельную операцию на каждый чих, то лагов станет только больше.
For example: есть у нас некая таблица с продуктами в магазине. Каждая ячейка — это цены, аватар, многострочное описание. Цена локализованная (символ рубля + форматирование), описание тоже (имеет некий префикс словесный). Как правило, составление локализованной строки делается прямо в момент установки значений в соответствующие лейблы.
Но ведь можно асинхронно это сделать? Сначала локализуем в фоне, а потом ставим в лейбл.
Так вот, хреновое это решение. Наилучшим вариантом будет для каждого объекта товара составить локализованные значения сразу после запроса на сервер, записав данные в соответствующие поля у сущности.
Особенно полезно будет еще и размеры этих самых полей заранее посчитать, записав в модель. Да, это нормально, несмотря на то, что выглядит непривычно.
В нашей команде уже давно принята такая практика — подсчитывать высоты ячеек заведомо при получении данных с сервера, сохраняя их в базу. Или в массив, если не используете БД, лишь бы это происходило предварительно и в фоне. Лучше пусть ваш пользователь будет лишнюю долю секунды лицезреть крутящуюся крутилочку, чем потом любоваться фризами.
И не нужно беспокоиться за объем хранилища. В текущей действительности любая память на айфоне — это дешевый ресурс, а процессорное время — дорогой. Стоит это помнить.
Вывод: подготавливайте данные для интерфейса заранее. Так дешевле и красивее.
И так как вы уже половину забыли, то вот вопросы, которые стоит себе задавать, чтобы перестать писать ерунду:
- Можно ли операцию сделать заранее в фоне и закешировать результат?
- Какой приоритет лучше подойдет для задачи?
- userInitiated: мелкие и срочные действия
- utility или default: сетевые задачи, рендеринг
- background: длительные процессы
- На каком потоке вызываются коллбэки? Нет ли лишней нагрузки на главный поток? (можно легко проверить через стек вызовов на брейкпоинте)
В следующей серии обсудим аппаратное ускорение. Звучит страшно, но будет легко.
P.S. Буду благодарен любому фидбеку по видео. Первый опыт, на каждую минуту уходило по часу буквально.

