В прошлой статье я рассказал о том, каким образом поисковая система может узнать о том, что существует та или иная веб-страница, и сохранить ее себе в хранилище. Но узнать о том, что веб-страница существует, — это только самое начало. Гораздо более важно за доли секунды успеть найти те страницы, которые содержат ключевые слова, введенные пользователем. О том, как это работает, я и расскажу в сегодняшней статье, проиллюстрировав свой рассказ «учебной» реализацией, которая тем не менее спроектирована таким образом, чтобы иметь возможность масштабироваться до размеров индексирования всего Интернета и учитывать современное состояние технологий анализа больших объемов данных.

Заодно у меня получилось рассмотреть основные функции и методы Apache Spark, так что данную статью можно рассматривать еще и как небольшой туториал по спарку.
Формулировка задачи
Более формальная постановка задачи, которую я сегодня разберу: имеется хранилище, содержащее набор веб-страниц, скачанных из Интернета краулером. Необходимо спроектировать механизм, который позволит за доли секунды указывать ссылки на все веб-страницы из этого хранилища, включающие все ключевые слова, содержащиеся в пользовательском запросе. Этот механизм должен быть:
- масштабируемым по количеству данных — потенциально мы должны иметь возможность обработать весь Интернет;
- масштабируемым по количеству запросов в секунду: у «взрослых» поисковых систем, таких как «Яндекс» и Google, количество поисковых запросов может достигать десятков тысяч запросов в секунду.
Несколько важных ограничений разбираемой сегодня задачи:
- В рамках этой статьи я не буду пытаться упорядочить найденные страницы. Движок будет возвращать просто множество. Задача упорядочивания, или, более правильно, ранжирования, — отдельная важная задача, которую я разберу в следующих статьях.
- Моя имплементация будет подразумевать наличие всех слов из поискового запроса. Современные поисковые системы позволяют исправлять опечатки, искать по синонимам и т. д., но в конце концов это все равно сводится к нескольким запросам «по всем» словам и объединению или пересечению их результатов.
Давайте теперь разберем, как решить задачу в рамках поставленных ограничений.
Инвертированный индекс
Рассмотрим следующую структуру данных: словарь, ключами которого будут слова из нашего языка, значениями — множества веб-страниц, на которых это слово встречается:
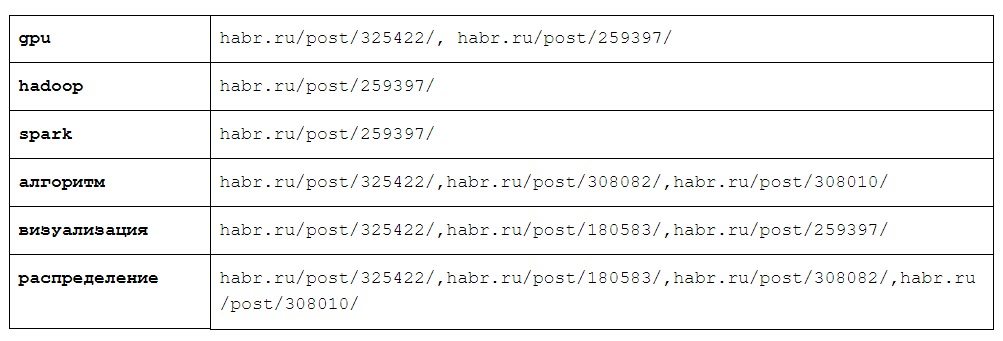
Такая структура данных называется инвертированным индексом, и она является ключевой для работы поисковой системы. Настолько ключевой, что, например, «Яндекс» даже называется в честь нее (yandex — это не что иное, как yet another index).
В реальности этот словарь будет иметь размер намного больший, чем в приведенном примере: количество элементов в нем будет равно количеству разнообразных слов на веб-страницах, а максимальный размер множества для одного элемента — все веб-страницы в индексируемой части Интернета.
Допустим, мы смогли построить такую структуру данных. В этом случае поиск веб-страниц, содержащих слова из запроса, будет происходить следующим образом:
- Разбиваем запрос на слова.
- По каждому слову обращаемся в обратный индекс и извлекаем множество веб-страниц.
- Результат — это пересечение всех множеств, извлеченных в пункте 1.
Например, если мы ищем все веб-страницы по запросу «алгоритм визуализация», а обратный индекс соответствует приведенному в таблице, то результирующее множество будет содержать всего лишь одну веб-страницу — habr.ru/post/325422/, так как только она содержится в пересечении множеств для слов «алгоритм» и «визуализация».
Для того чтобы построить такую структуру данных, можно воспользоваться подходом MapReduce. Об этом подходе у меня есть отдельная статья, но основная идея заключается в следующем:
- На первом этапе (map-шаг) можно исходные объекты (в нашем случае документы) преобразовать в пары ключ-значение (ключами будут слова, а значениями — URL документа).
- Пары ключ-значение автоматически группируются по ключам (шаг shuffle).
- Обработать все значения по заданному ключу (шаг reduce). В нашем случае — сохранить в обратный индекс.
Ниже в разделе с имплементацией я покажу, как реализовать описанный алгоритм, используя популярный open source инструмент для работы с большими данными — apache spark.
Чуть-чуть NLP
Под аббревиатурой NLP в области анализа данных понимают компьютерную обработку естественного языка (Natural Language Processing, не путать с псевдонаучным нейролингвистическим программированием). При работе с поисковой системой не избежать хотя бы отдаленного столкновения с обработкой языка, поэтому нам понадобятся некоторые понятия и инструменты из этой области. В качестве библиотеки работы с естественным языком я буду использовать популярную библиотеку для python NLTK.
Токенизация
Первое понятие из области NLP, которое нам понадобится, — это токенизация. При описании работы с реверсивным индексом я пользовался понятием слово. Однако слово — это не очень хороший термин для разработчика поисковой системы, так как на веб-страницах встречается много разнообразных наборов символов, не являющихся словом в прямом смысле этого слова (например, masha545 или 31337). Поэтому мы будем вместо этого пользоваться токенами. В библиотеке NLTK есть специальный модуль для выделения токенов: nltk.tokenize. Там есть разнообразные способы разбить текст на токены. Мы воспользуемся самым простым способом выделить токены — токенизацией по регекспу:
#code from nltk.tokenize import RegexpTokenizer tokenizer = RegexpTokenizer(r'[а-яёa-z0-9]+') text = "Съешь ещё этих мягких французских булок, да выпей же чаю." tokenizer.tokenize(text.lower()) #result ['съешь', 'ещё', 'этих', 'мягких', 'французских', 'булок', 'да', 'выпей', 'же', 'чаю']
Лемматизация
Многие языки, и русский в особенности, богаты на формы слов. Понятно, что, когда мы ищем слово «компьютер», мы ожидаем, что найдутся страницы, содержащие слово «компьютера», «компьютеров» и так далее. Для этого все токены нужно привести в так называемую «нормальную форму». Это можно сделать при помощи разных инструментов. Например, на github есть библиотека pymystem, являющаяся оберткой над библиотекой, разработанной яндексом. Я для простоты воспользуюсь методом стемминга — отброса незначащего окончания — и использую для этого стеммер русского языка, входящий в библиотеку nltk:
#code from nltk.stem.snowball import RussianStemmer stemmer = RussianStemmer() tokens = ['съешь', 'ещё', 'этих', 'мягких', 'французских', 'булок', 'да', 'выпей', 'же', 'чаю'] stemmed_tokens = [stemmer.stem(token) for token in tokens] print(stemmed_tokens) #result ['съеш', 'ещ', 'эт', 'мягк', 'французск', 'булок', 'да', 'вып', 'же', 'ча']
Отсечение незначимых слов
В обратном индексе для каждого слова мы храним множество URL-страниц, в которых это слово опубликовано. Проблема заключается в том, что некоторые слова (например, предлог «в») встречаются практически на каждой веб-странице. При этом информативность наличия или отсутствия таких слов на странице очень маленькая. Поэтому, для того чтобы не хранить огромные массивы в индексе и не делать лишнюю работу, такие слова мы будем просто игнорировать.
Чтобы определить множество слов, которые будем игнорировать, можно для каждого слова подсчитать долю веб-страниц, на которых это слово встречается, и поставить некоторую границу по этой частоте. Расчет частотности слов — это классическая задача в парадигме map-reduce, подробно об этом можно почитать в моих статьях.

Я для своей реализации вычислял не просто частоту слов, а некоторое ее монотонное преобразование — Inverse Document Frequency (IDF), которое нам в дальнейшем пригодится еще и для ранжирования документов. Методом «пристального взгляда» я определил, что подходящая константа для отсечения слов будет примерно равна 1.12, между словами «за» и «код» (слово «код» очень часто встречается на хабре).
Индексируем

Архитектура моего учебного поискового движка
Apache Spark
Документов, которые я индексирую, довольно много — несколько миллионов. Для их обработки необходим инструментарий для работы с большими данными. Я выбрал apache spark, который является одним из самых популярных фреймворков на сегодняшний день. Так как я использую amazon web services для своей имплементации, я воспользовался дистрибутивом спарка, входящим в состав elastic map reduce. Apache Spark имеет несколько вариантов представления датасетов. Один из основных — так называемый Resilient Distributed Dataset (RDD) — по сути представляет собой распределенный массив данных, которые можно обрабатывать параллельно. Я буду использовать его для своей реализации (хотя есть и другие API для работы со спарком, которые в некоторых случаях могут быть быстрее, см например Dataframe API)
Так как данные в нашем случае у нас хранятся на объектном хранилище амазона (S3), то сначала спарку необходимо сообщить необходимую информацию для работы с этим хранилищем:
#sc-это spark context, он содержит параметры подключения к спарку def init_aws_spark(sc, config): sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", config.AWS_ACCESS_KEY) sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", config.AWS_SECRET_KEY)
Дальше можно создать RDD из данных, хранящихся на S3 (которые туда сохранил краулер), и заодно сразу распарсить документы из json-формата:
rdd = sc.textFile("s3a://minicrawl/habrahabr.ru/*",) jsons_rdd = rdd.map(lambda doc: json.loads(doc))
Тут мы применили одну из базовых функций спарка — map, которая применяет функцию ко всем элементам массива, делая это параллельно на всех узлах кластера.
Далее мы несколько раз применим эту функцию для предварительной обработки текста:
Очистка от HTML-разметки
Тут ничего особо интересного, использую библиотеку lxml для парсинга html-а и удаления разметки:
import copy import lxml.etree as etree def stringify_children(node): if str(node.tag).lower() in {'script', 'style'}: return [] from lxml.etree import tostring parts = [node.text] for element in node.getchildren(): parts += stringify_children(element) return ''.join(filter(None, parts)).lower() def get_tree(html): parser = etree.HTMLParser() tree = etree.parse(StringIO(html), parser) return tree.getroot() def remove_tags(html): tree = get_tree(html) return stringify_children(tree) def get_text(doc): res = copy.deepcopy(doc) res['html'] = res['text'] res['text'] = remove_tags(res['html']) return res clean_text_rdd = jsons_rdd.map(get_text).cache()
Токенизация и стемминг
from nltk.tokenize import RegexpTokenizer from nltk.stem.snowball import RussianStemmer def tokenize(doc): tokenizer = RegexpTokenizer(r'[а-яёa-z0-9]+') res = copy.deepcopy(doc) tokens = tokenizer.tokenize(res['text']) res['tokens'] = list(filter(lambda x: len(x) < 15, tokens)) return res def stem(doc): stemmer = RussianStemmer() res = copy.deepcopy(doc) res['stemmed'] = [stemmer.stem(token) for token in res['tokens']] return res stemmed_docs = clean_text_rdd.map(tokenize).map(stem).cache()
Функция cache(), вызванная после функции map(), подсказывает, что этот датасет необходимо закешировать. Если этого не сделать, при многократном использовании спарк будет его рассчитывать заново.
Фильтрация высокочастотных слов на spark
Как я писал, фильтровать будем слова, для которых мера IDF меньше чем 1.12. Для этого нам сначала надо посчитать частоты всех слов. Это прямо классическая задача на анализ больших данных:
def get_words(doc): return [(word, 1) for word in set(doc['stemmed'])] word_counts = stemmed_docs.flatMap(get_words)\ .reduceByKey(lambda x, y: x+y)
Здесь используются две интересные функции спарка:
- flatMap — работает аналогично map, но возвращает не одно значение для одного значения входного датасета, а несколько. В нашем случае — возвращаем пару ключ-значение (<слово>, 1) для каждого слова, хотя бы раз входящего в документ.
- reduceByKey — позволяет обработать все значения для одного ключа. В нашем случае просуммировать.
Далее рассчитаем IDF для всех токенов:
doc_count = stemmed_docs.count() def get_idf(doc_count, doc_with_word_count): return math.log(doc_count/doc_with_word_count) idf = word_counts.mapValues(lambda word_count: get_idf(doc_count, word_count))
Получим список высокочастотных стоп-слов:
idf_border = 1.12 stop_words_list =idf.filter(lambda x: x[1] < idf_border).keys().collect() stop_words = set(sop_words)
Тут используются функции спарка:
- filter() — оставляет в датасете только элементы, подходящие под определенный критерий;
- keys() — оставляет только ключи в датасете (есть аналогичная функция values(), которая оставляет только значения);
- collect() — собирает распределенный датасет в локальный список. После этого над ним больше нельзя выполнять спарсковские функции.
У меня получилось 50 стоп-слов, среди которых присутствуют как очевидные: "в", "о", "не", так и менее очевидные, но логичные для хабра: "хабрахабр", "мобильн", "песочниц", "поддержк", "регистрац".
Построение обратного индекса
Задача построить датасет типа слово -> множество URL очень похожа на задачу посчитать количество документов, в которых встречается слово, с одним различием: мы будем не прибавлять единицу каждый раз, а добавлять новый URL в множество.
def token_urls(doc): res = [] for token in set(doc['stemmed']): if token not in stop_words: res.append((token, doc['url'])) return res index_rdd = stemmed_docs.flatMap(token_urls)\ .aggregateByKey(set(),\ lambda x, y: x.union({y}), lambda x, y: x.union(y))
Тут в дополнение к уже использованной ранее функции flatMap используется еще и функция aggregateByKey, которая очень похожа на reduceByKey, но принимает три параметра:
- пустой объект-аккумулятор, в котором будет накапливаться результат;
- функцию, которая добавляет в аккумулятор одно значение;
- функцию, которая может слить два аккумулятора в один. Значения для одного ключа могут агрегироваться параллельно, эта функция нужна для объединения частично агрегированных результатов.
Дальше осталось только сохранить обратный индекс. Для того чтобы его сохранить, нам подойдет любое распределенное key-value хранилище. Я выбрал aerospike— он быстрый, хорошо распределяется. Записывать в значение для токена прямо сериализованное множество url-ов:
В общем, все просто:
import pickle storage = LazyAerospike(config.AEROSPIKE_ADDRESS) results = index_rdd.map(lambda x: storage.put(x[0], pickle.dumps(x[1]))).collect()
Тут я использую pickle — стандартный питоновский способ сериализации почти любых объектов. Также использую небольшую обертку над стандартным клиентом aerospike, которая позволяет инициализировать соединение с базой данных в момент первой записи или чтения. Это нужно, так как spark не может распараллелить подключение к базе данных по всем узлам кластера, приходится каждый раз подключаться заново.
class LazyAerospike(object): import aerospike def __init__(self, addr, namespace='test', table='index'): self.addr = addr self.connection = None self.namespace = namespace self.table = table def check_connection(self): if self.connection is None: config = { 'hosts': [ (self.addr, 3000) ] } self.connection = self.aerospike.Client(config).connect() def _get_full_key(self, key): return (self.namespace, self.table, key) def put(self, key, value): self.check_connection() key_full = self._get_full_key(key) self.connection.put(key_full, {'value': value}) return True def get(self, key): self.check_connection() key_full = self._get_full_key(key) value = self.connection.get(key_full) return value[2]['value']
API для извлечения данных
Осталось написать функцию, которая будет исполняться во время пользовательского запроса. С ней все просто: разбиваем запрос на токены, извлекаем множества URL-ов для каждого токена и пересекаем их:
def index_get_urls(keyword): raw_urls = storage.get(keyword) return pickle.loads(raw_urls) def search(query): stemmer = RussianStemmer() tokenizer = RegexpTokenizer(r'[а-яёa-z0-9]+') keywords_all = [stemmer.stem(token) \ for token in tokenizer.tokenize(query)] keywords = list(filter(lambda token: \ token not in stop_words, keywords_all)) if len(keywords) == 0: return [] result_set= index_get_urls(keywords[0]) for keyword in keywords[1:]: result_set=\ result_set.intersection(index_get_urls(keyword)) return result_set
Запускаем и убеждаемся, что все работает как надо (тут я запускал на небольшом семпле):

Заключение
Настоящая поисковая система, конечно, устроена гораздо сложнее. Например, я храню множества очень неоптимально, достаточно было бы вместо самих url-ов хранить только их id-шники. Тем не менее архитектура получилась распределенная и потенциально может действительно работать на большой части Интернета и под большими нагрузками.
В продакшене вам, скорее всего, не нужно будет реализовывать поисковую систему руками — лучше воспользоваться готовыми решениями, например таким, как ElasticSearch.
Однако понимание основ того, как работает обратный индекс, может помочь его правильно настроить и использовать, ну и для решения похожих задач может оказаться очень полезным.
В этой статье я не затронул самую интересную, на мой взгляд, часть поиска — ранжирование. О нем речь пойдет в следующих статьях.

