Графики с необычными пиками мы теперь видим после каждых федеральных выборов. Впервые в массы они вышли после выборов в 2011 году, когда люди и увидели фальсификации, и ознакомились в целом с анализом данных по выборам и с проблемой целочисленного деления в частности.
У распределений даже стали появляться свои имена. Это и «борода Чурова» для выборов 2011, и «пик Володина» для знаменитых 62.2% в Саратове. Поскольку до сих пор даже на хабре появляются статьи, не знакомые с решением проблемы целочисленного деления и не согласные "добавлять мусор" небольшой случайной добавки в данные, давайте посмотрим на результаты совсем иначе. Мы зайдём к построению графиков с противоположной стороны, где проблемы целочисленного деления вообще нет. И тоже увидим пики на целых значениях.
Давайте придумаем, как проанализировать данные с выборов. Поскольку на участках разное количество людей, примерно близкий процент явки будет отличаться в десятых и сотых, даже когда комиссия хочет подогнать под некоторое круглое число, скажем, 85%. Например, явка 1658 человек на участок с 1950 избирателей в списке — это 85.03% явки, явка 1619 из 1905 избирателей — это 84.99%, а 263 человек из 309 — это 85.11%. Таким образом, нужно как-то понимать, а не подходит ли явка под круглый процент, учитывая количество избирателей и то, что ровно в, скажем, 85% попасть трудно (это будет лишь если число избирателей в списке участка кратно 20).
Поэтому делаем так — мы просто в цикле перебираем значение процента percent (в данном случае явки), и для каждого значения процента проверяем условие на число голосовавших voted, учитывая размер участка people:
Если условие

Пики широкие и не очень ярко выражены относительно их основания, да и после 70% кривая из Гаусса становится чем-то совсем незнакомым.
Посмотрим теперь не на сами УИКи, а на количество голосов в них, то есть каждую точку подсчитаем с весом, равным числу избирателей.
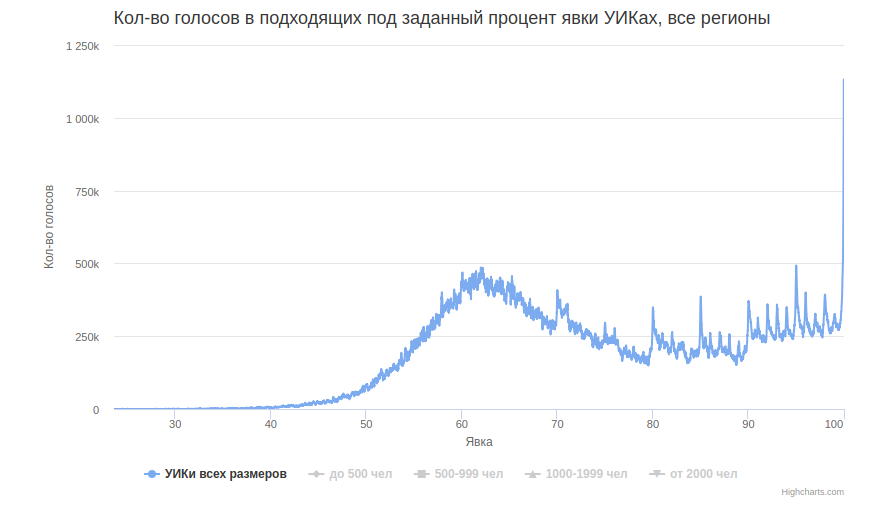
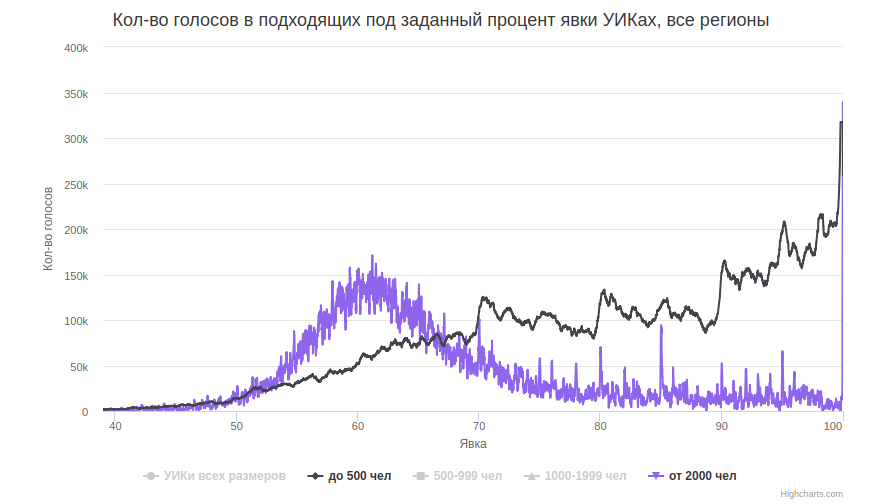
Пики на целых процентах видны теперь лучше. Похоже, крупные УИКи тоже «рисуют», и поэтому пики заметнее. Чтобы это увидеть, разобьём участки на 4 группы 0-499, 500-999, 1000-1999 и >=2000. Видно, что крупные участки своей массой гораздо ближе к Гауссу, чем мелкие.
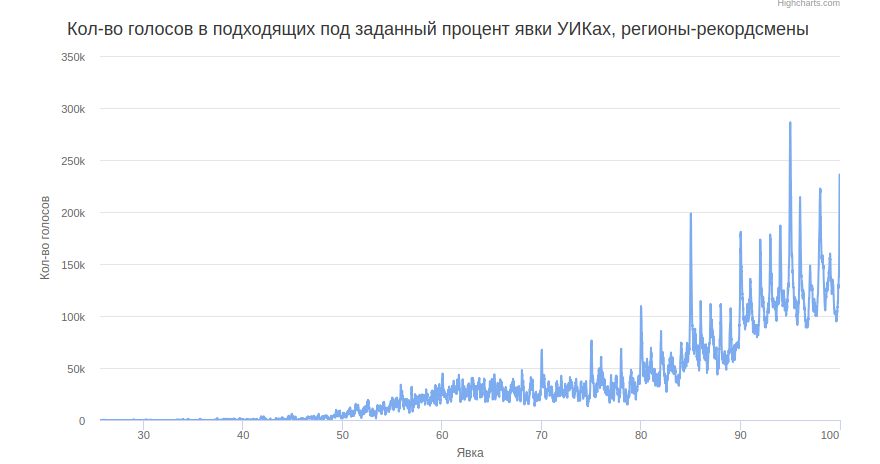
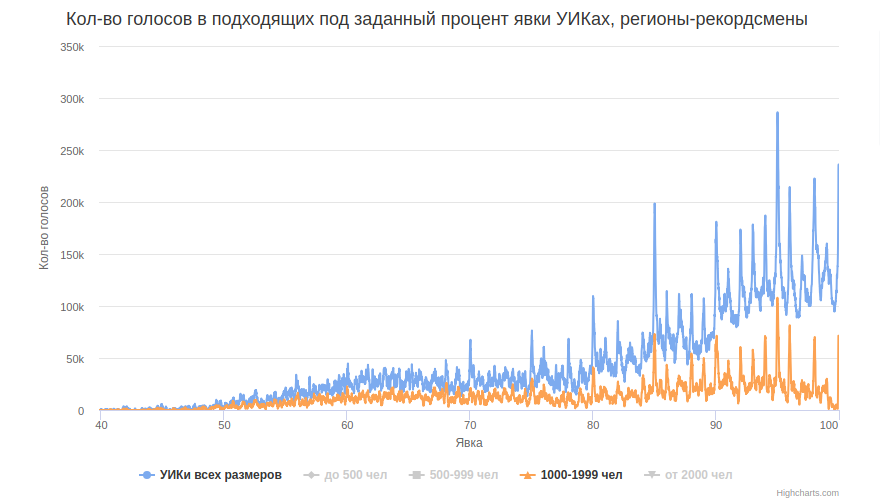
В заметке vsvor определил список регионов-лидеров целочисленного процента, можем посмотреть график по списку только выбранных 8 регионов-лидеров, ответственных за самый значительный вклад в рисование. Чтобы не перегружать график, берём не все группы участков.
Важно отметить, что у данного метода нет проблемы с шагом построения. Перебирать можно хоть с шагом в 1%, хоть с шагом в 0.001%, меняется лишь детальность прорисовки кривой. Шага в 0.01% достаточно для подробного рассмотрения пиков и нужды в шаге 0.001% нет.
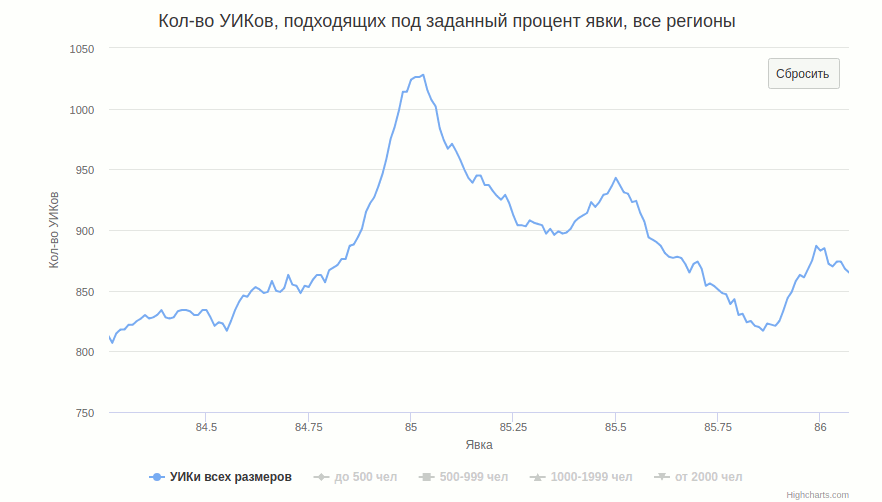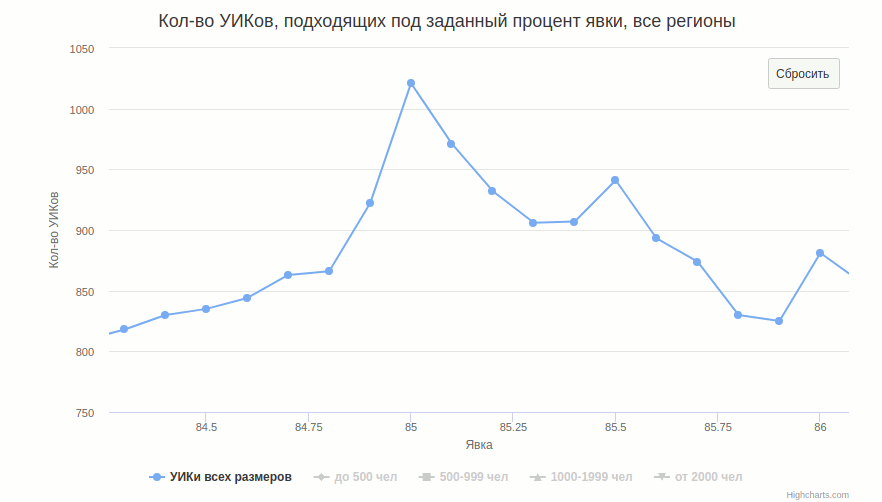
Исходя из целочисленности избирателей, очевидно, что в случае, если комиссия «рисует» результаты калькулятором и с точностью до 1 человека, ширина пика на половине его высоты будет примерно 100%/(число избирателей). Средние размеры участка для разных групп и соответствующие им проценты:
И при детальном рассмотрении видно, как ширины пиков у разных групп соответственно различаются
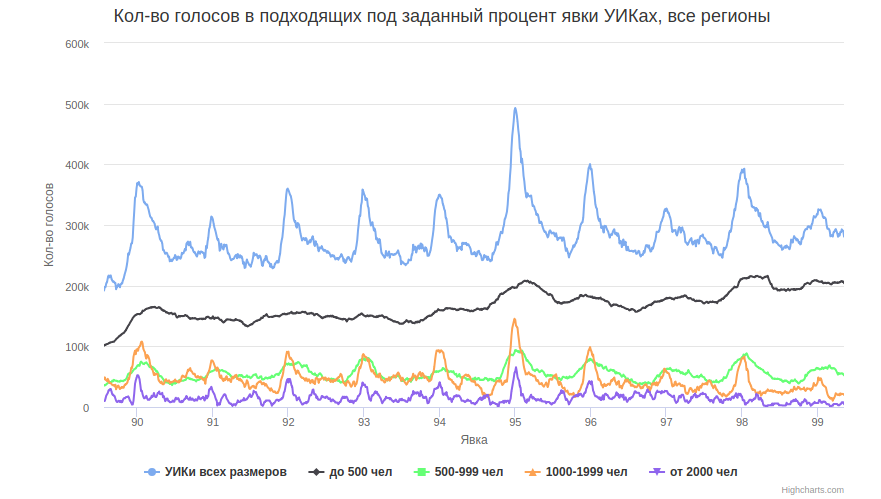
Все пики именно соответствующие размерам участка, кроме довольно широкого пика на 70%, у которого, видимо, задача была «не меньше 70%». И чем меньше группа, тем шире пик. Таким образом, видимые пики на целых числах — практически все с точностью до человека.
Пик на 100% отдельный, его сложнее проанализировать, но его полуширина тоже соответствует численности, но перед нами не широкий пик, который бы описывал этот набор участков как «пришло максимально возможное число», а нечто другое — на них явка 100% с точностью до человека, эта цифра либо несвободного голосования, либо «рисовательного» характера, либо особых участков вроде зарубежных, где цифра в 100% явки получается просто из-за способа попадания в список избирателей, например, в Сухуми на УИК 8000 пришли все 5297 из пожелавших. Под большим подозрением на «рисование» — стопроцентные участки на территории РФ, т.к. тяжело поверить, что ни один сельчанин не заболел или не передумал идти, даже если это далёкий посёлок Усть-Кабырза (карта) с участком 1719 Кемеровской области. Соседнее небольшое село вообще к 10 утра целиком проголосовало, и все в помещении. Но это уже предмет изучения для видео-наблюдения или для местных наблюдателей.
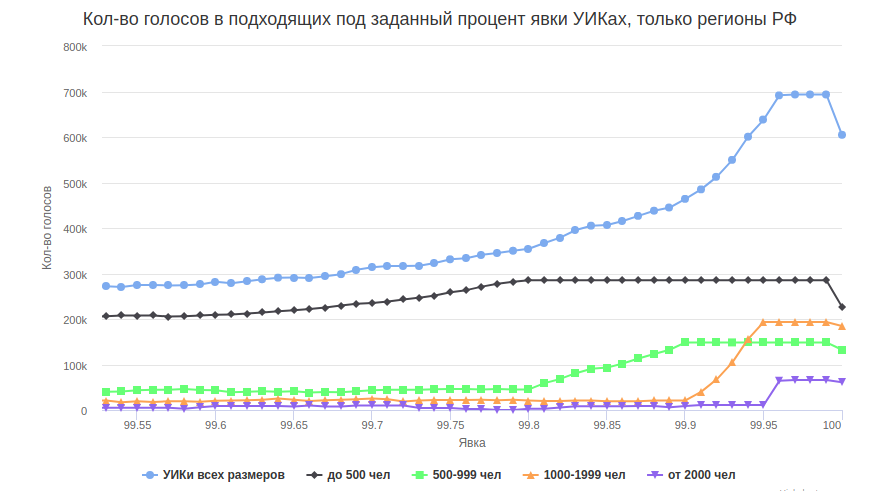
Я в данной статье не касаюсь вопроса подсчёта вероятности случайного появления подобных пиков, это уже было сделано ранее, например, через добавление границ графика как трёх сигм вокруг среднего. Отклонение в пиках заметно превышает три сигма, то есть вероятность самопроизвольного случайного проявления пиков ничтожна (3 сигма — менее 0.3%). Впрочем, после 70% явки начинается настолько сильное отклонение от нормального распределения, что смысл слегка теряется.
Также неслучайность пиков можно проверять прямой проверкой записей\показаний с участков. Например, Дагестан, УИК 1058, накрутил явку с 20% до целочисленных 98%, являющихся, кстати, тоже одним из пиковых значений в Дагестане, так что проект видео-наблюдения, который сейчас ещё в процессе, даст ещё много интересных свидетельств.
В целом же, конечно, форма кривой получается в точности, как и у других исследователей, хотя и другим методом. Неудивительно, рукотворность цифр «фонит» со всех сторон.
Удивительно то, что не так легко обывателю заметить комиссии, рисующие процент. Например, самый популярный процент явки, 95%, всего у 70 участков на Кубани — это мало, это всего 2.5%. Буквально пара участков с каждого района выбрали себе цифру 95%, это незаметно при рассмотрении результатов участка или даже района, но подсвечивается при рассмотрении всего края, когда реальные данные складываются в колоколообразное распределение, а рисованные — в заметные пики. Или 85% в Ставрополье — всего 40 участков, но пик возвышается огромный и неестественный.
Метод позволяет также оценить число «дорисованных» голосов через подсчёт, на сколько пик целочисленного процента возвышается над плато (основу которого составляют не только честные голоса, но и вбросы, и рисование цифр по наитию). Это даёт довольно точную оценку вовлечённых в рисование УИКов, но менее точную (скорее это оценка сверху) для числа «дорисованных» голосов, надо понимать, что если у участка отобрать дорисованное число, его нужно поместить в его место распределения (увы, неизвестное).
Как высоту можно взять разницу между высотой пика и средним арифметическим значений в районе +-0.5%. Простое суммирование высот пиков на целочисленных процентах даёт следующие значения:
То есть всего около 2.9% УИКов (удивительно!) создали такие замечательные пики. Большое число участков позволяет увидеть даже такую относительно небольшую затею, как рисование целых процентов явки всего тремя процентами участков. Если взять за оценку число добавленных победителю голосов в 10млн (Шпилькин), видно, что относительно небольшая часть нарисована целыми процентами. Основная часть фальсифицирующих комиссий или просто вбрасывает, сколько получится, или рисует цифру «на глаз».
По сути одно — тысячи избирательных комиссий беззастенчиво рисуют результаты с калькулятором, не страшась уголовного преследования. Конечно же, метод не позволяет сказать точно, какие именно из участков подогнали результат, но он может оценить их количество и сделать очевидным и бесспорным факт подгонки.
Да, рисование результатов с помощью калькулятора — не единственный метод возможных злоупотреблений со стороны комиссии, написать можно и случайно выбранную цифру. Можно предположить, что на участках с камерами самый удобный метод подгонки под желаемый результат — это вбросы: переписывание протокола или быстрое рисование с калькулятором легко заметить видео-наблюдением и независимым членам избирательной комиссии. Да и на камеру требуется показать подсчёт, а вбросы тонких пачек бюллетеней (50шт=4.5мм) практически невозможно заметить, если только не вести подсчёт явки все 12 часов или не обращать внимание на такие мелочи, как сгибающиеся под тяжестью пачки.
Поиграться с выборкой различных регионов и построением графиков для них можно по ссылке (там есть также графики и для числа УИКов).
Код, создающий json с данными для графиков (php, я обвязал его в laravel 5.4), поместил в gist, впрочем, он тривиален.
Источник данных — csv-файл от «Голоса».
UPD1. Обращено внимание на наличие графиков по УИКам, по ссылке
UPD2. Исправлен пример с УИК 1058 (регион — Дагестан, а не Татарстан)
UPD3. Подсчитал этим же методом, сколько из участков имеющих целочисленный процент, подходит также под условие целочисленного процент за победителя. Ограничил размер условием >=500 изб, вышло 2259 участков, что сходится по порядку с суммой пиков, то есть можно предположить, что выбирающие явку калькулятором в большинстве случаев и процент выбирали им же.
У распределений даже стали появляться свои имена. Это и «борода Чурова» для выборов 2011, и «пик Володина» для знаменитых 62.2% в Саратове. Поскольку до сих пор даже на хабре появляются статьи, не знакомые с решением проблемы целочисленного деления и не согласные "добавлять мусор" небольшой случайной добавки в данные, давайте посмотрим на результаты совсем иначе. Мы зайдём к построению графиков с противоположной стороны, где проблемы целочисленного деления вообще нет. И тоже увидим пики на целых значениях.
Метод перебора возможной явки
Давайте придумаем, как проанализировать данные с выборов. Поскольку на участках разное количество людей, примерно близкий процент явки будет отличаться в десятых и сотых, даже когда комиссия хочет подогнать под некоторое круглое число, скажем, 85%. Например, явка 1658 человек на участок с 1950 избирателей в списке — это 85.03% явки, явка 1619 из 1905 избирателей — это 84.99%, а 263 человек из 309 — это 85.11%. Таким образом, нужно как-то понимать, а не подходит ли явка под круглый процент, учитывая количество избирателей и то, что ровно в, скажем, 85% попасть трудно (это будет лишь если число избирателей в списке участка кратно 20).
Поэтому делаем так — мы просто в цикле перебираем значение процента percent (в данном случае явки), и для каждого значения процента проверяем условие на число голосовавших voted, учитывая размер участка people:
floor(percent * people / 100) === voted || ceil(percent * people / 100) === voted
Если условие
true, значит участок подходит к заданному проценту (и если он целый, участок можно подозревать в подгонке). По сути мы этим повторяем действие условной нечестной комиссии, которая с помощью калькулятора и выбранной цифры подсчитывает, а какую же явку нарисовать. Используем оба типа округления (вверх и вниз), т.к. и люди оба варианта используют, и настройка «5\4» у бухгалтерских калькуляторов может стоять в разных положениях. Таким образом мы можем для каждого значения явки проверить, какое количество участков ей удовлетворяет с точностью до человека с учётом их целочисленного размера. И если на определённых значениях будут узкие пики, которые заметно выше случайных колебаний кривой распределения, мы сможем достоверно утверждать, что значения в значительной части участков пика выбраны любителями целых чисел, то есть не его величеством рандомом, а разумными людьми, не знакомыми ни с уголовным кодексом, ни с математикой. Итак, попробуем просто построить данные и проверим, есть ли пики на целых значениях.Пики широкие и не очень ярко выражены относительно их основания, да и после 70% кривая из Гаусса становится чем-то совсем незнакомым.
Посмотрим теперь не на сами УИКи, а на количество голосов в них, то есть каждую точку подсчитаем с весом, равным числу избирателей.
Пики на целых процентах видны теперь лучше. Похоже, крупные УИКи тоже «рисуют», и поэтому пики заметнее. Чтобы это увидеть, разобьём участки на 4 группы 0-499, 500-999, 1000-1999 и >=2000. Видно, что крупные участки своей массой гораздо ближе к Гауссу, чем мелкие.
В заметке vsvor определил список регионов-лидеров целочисленного процента, можем посмотреть график по списку только выбранных 8 регионов-лидеров, ответственных за самый значительный вклад в рисование. Чтобы не перегружать график, берём не все группы участков.
Детальность прорисовки
Важно отметить, что у данного метода нет проблемы с шагом построения. Перебирать можно хоть с шагом в 1%, хоть с шагом в 0.001%, меняется лишь детальность прорисовки кривой. Шага в 0.01% достаточно для подробного рассмотрения пиков и нужды в шаге 0.001% нет.
Как понять пики. Полуширины для разных размеров участков.
Исходя из целочисленности избирателей, очевидно, что в случае, если комиссия «рисует» результаты калькулятором и с точностью до 1 человека, ширина пика на половине его высоты будет примерно 100%/(число избирателей). Средние размеры участка для разных групп и соответствующие им проценты:
| Размер УИК | Среднее число избирателей | Полуширина пика |
| До 500 чел | 248 | 0.40% |
| 500-999 чел | 726 | 0.14% |
| 1000-1999 чел | 1499 | 0.07% |
| от 2000 чел | 2368 | 0.04% |
| Все участки | 1116 | 0.09% |
И при детальном рассмотрении видно, как ширины пиков у разных групп соответственно различаются
Все пики именно соответствующие размерам участка, кроме довольно широкого пика на 70%, у которого, видимо, задача была «не меньше 70%». И чем меньше группа, тем шире пик. Таким образом, видимые пики на целых числах — практически все с точностью до человека.
Пик на 100% отдельный, его сложнее проанализировать, но его полуширина тоже соответствует численности, но перед нами не широкий пик, который бы описывал этот набор участков как «пришло максимально возможное число», а нечто другое — на них явка 100% с точностью до человека, эта цифра либо несвободного голосования, либо «рисовательного» характера, либо особых участков вроде зарубежных, где цифра в 100% явки получается просто из-за способа попадания в список избирателей, например, в Сухуми на УИК 8000 пришли все 5297 из пожелавших. Под большим подозрением на «рисование» — стопроцентные участки на территории РФ, т.к. тяжело поверить, что ни один сельчанин не заболел или не передумал идти, даже если это далёкий посёлок Усть-Кабырза (карта) с участком 1719 Кемеровской области. Соседнее небольшое село вообще к 10 утра целиком проголосовало, и все в помещении. Но это уже предмет изучения для видео-наблюдения или для местных наблюдателей.
Достоверность неслучайности
Я в данной статье не касаюсь вопроса подсчёта вероятности случайного появления подобных пиков, это уже было сделано ранее, например, через добавление границ графика как трёх сигм вокруг среднего. Отклонение в пиках заметно превышает три сигма, то есть вероятность самопроизвольного случайного проявления пиков ничтожна (3 сигма — менее 0.3%). Впрочем, после 70% явки начинается настолько сильное отклонение от нормального распределения, что смысл слегка теряется.
Также неслучайность пиков можно проверять прямой проверкой записей\показаний с участков. Например, Дагестан, УИК 1058, накрутил явку с 20% до целочисленных 98%, являющихся, кстати, тоже одним из пиковых значений в Дагестане, так что проект видео-наблюдения, который сейчас ещё в процессе, даст ещё много интересных свидетельств.
Чем этот метод лучше, чем простая гистограмма с бином
- Метод перебора процента позволяет обойти проблему целочисленного деления и не подбирать размер случайной «мусорной» добавки к чистым данным
- Он позволяет сказать число подходящих под процент участков с точностью до человека, чего нельзя сделать обычной гистограммой с бином. Фиксированный бин (обычно 0.1%) не учитывает различные размеры участков, и иногда просто определяет участок не в точный процент, а в соседние точки. Поэтому пики в моём «обратном» методе раза в 1.5 выше, т.к. доучитываются участки, не попадающие в бин из-за опять же целочисленности или человеческого фактора — округления разными способами.
- Ну и самое удобное — метод позволяет рисовать распределение с любой точностью, хоть до 0.001%, и это не перекраивает график. Уменьшение бина в обычной гистограмме уменьшает кол-во попадающих в бин и раскидывает точки по разным отрезкам, а вышеописанный метод лишь лучше прорисовывает отрезки между точками и получает плавнее кривые. И по ширине пика можно судить о том, с точностью до человека ли он.
В целом же, конечно, форма кривой получается в точности, как и у других исследователей, хотя и другим методом. Неудивительно, рукотворность цифр «фонит» со всех сторон.
В чём сила больших данных
Удивительно то, что не так легко обывателю заметить комиссии, рисующие процент. Например, самый популярный процент явки, 95%, всего у 70 участков на Кубани — это мало, это всего 2.5%. Буквально пара участков с каждого района выбрали себе цифру 95%, это незаметно при рассмотрении результатов участка или даже района, но подсвечивается при рассмотрении всего края, когда реальные данные складываются в колоколообразное распределение, а рисованные — в заметные пики. Или 85% в Ставрополье — всего 40 участков, но пик возвышается огромный и неестественный.
Масштабы рисования
Метод позволяет также оценить число «дорисованных» голосов через подсчёт, на сколько пик целочисленного процента возвышается над плато (основу которого составляют не только честные голоса, но и вбросы, и рисование цифр по наитию). Это даёт довольно точную оценку вовлечённых в рисование УИКов, но менее точную (скорее это оценка сверху) для числа «дорисованных» голосов, надо понимать, что если у участка отобрать дорисованное число, его нужно поместить в его место распределения (увы, неизвестное).
Как высоту можно взять разницу между высотой пика и средним арифметическим значений в районе +-0.5%. Простое суммирование высот пиков на целочисленных процентах даёт следующие значения:
| Участки до 500 чел | +0.23М голосов | 496 УИКов |
| Участки от 500 до 999 чел | +0.52М голосов | 823 УИКа |
| Участки от 1000 до 1999 чел | +1.28М голосов | 1007 УИКов |
| Участки от 2000 чел | +1.07М голосов | 514 УИКов |
| Всего | +3.1М голосов (или +2.5М для РФ) | 2840 УИКов |
То есть всего около 2.9% УИКов (удивительно!) создали такие замечательные пики. Большое число участков позволяет увидеть даже такую относительно небольшую затею, как рисование целых процентов явки всего тремя процентами участков. Если взять за оценку число добавленных победителю голосов в 10млн (Шпилькин), видно, что относительно небольшая часть нарисована целыми процентами. Основная часть фальсифицирующих комиссий или просто вбрасывает, сколько получится, или рисует цифру «на глаз».
И что всё это значит?
По сути одно — тысячи избирательных комиссий беззастенчиво рисуют результаты с калькулятором, не страшась уголовного преследования. Конечно же, метод не позволяет сказать точно, какие именно из участков подогнали результат, но он может оценить их количество и сделать очевидным и бесспорным факт подгонки.
Да, рисование результатов с помощью калькулятора — не единственный метод возможных злоупотреблений со стороны комиссии, написать можно и случайно выбранную цифру. Можно предположить, что на участках с камерами самый удобный метод подгонки под желаемый результат — это вбросы: переписывание протокола или быстрое рисование с калькулятором легко заметить видео-наблюдением и независимым членам избирательной комиссии. Да и на камеру требуется показать подсчёт, а вбросы тонких пачек бюллетеней (50шт=4.5мм) практически невозможно заметить, если только не вести подсчёт явки все 12 часов или не обращать внимание на такие мелочи, как сгибающиеся под тяжестью пачки.
Как заключение
Поиграться с выборкой различных регионов и построением графиков для них можно по ссылке (там есть также графики и для числа УИКов).
Код, создающий json с данными для графиков (php, я обвязал его в laravel 5.4), поместил в gist, впрочем, он тривиален.
Источник данных — csv-файл от «Голоса».
UPD1. Обращено внимание на наличие графиков по УИКам, по ссылке
UPD2. Исправлен пример с УИК 1058 (регион — Дагестан, а не Татарстан)
UPD3. Подсчитал этим же методом, сколько из участков имеющих целочисленный процент, подходит также под условие целочисленного процент за победителя. Ограничил размер условием >=500 изб, вышло 2259 участков, что сходится по порядку с суммой пиков, то есть можно предположить, что выбирающие явку калькулятором в большинстве случаев и процент выбирали им же.

