Вряд ли кто-то будет спорить, что наблюдение за производительностью дисковой подсистемы — чуть ли не важнейшая задача для всех высоконагруженных систем хранения и баз данных. Я изначально столкнулся с этим давным-давно, еще когда приходилось наблюдать за PostgreSQL. В последнее время вернулся к этому вопросу в связи с необходимостью тестирования различных хранилищ.
Сегодня хочу поделиться с сообществом своим текущим опытом на реальном примере zabbix и его связке с block stat.

Я являюсь архитектором баз данных и систем хранения очень высокой производительности и больших объемов. Поэтому часто сталкиваюсь с задачами оценки, как те или иные параметры настройки системы влияют на работу СХД, какие железные конфигурации СХД лучше.
Да есть куча утилит, которая позволит протестировать диски, например тот же fio. Но ничто не сравнится с тестированием реальной нагрузкой.
Однако прежде чем подавать реальную и настоящую нагрузку, неплохо бы сначала протестировать на синтетике. А наблюдать за синтетикой лучше теми же средствами, что и за боевой системой, просто потому, что даже если ваши метрики не совсем верны методологически – они будут хотя бы те же самые и по ним можно будет делать выводы лучше/хуже.
Когда то давным-давно для этих целей использовал iostat, лютый парсер к нему и gnuplot, и даже написал статейку habr.com/post/165855. Скажу я вам – это жутко неудобно.
Куда как удобнее натравить на систему zabbix и мониторить. А к zabbix можно прикрутить модную Grafana и мониторить красиво. Сразу скажу – выбор zabbix скорее исторический: «потому что он уже был».
Справедливости ради скажу, что в zabbix уже есть встроенные ключи vfs.dev.*, но увы очень мало: скорость чтения и записи, объем.
А что нужно нам?
Практика показывает что ключевые метрики по которым можно оценивать дисковую подсистему это:
Так как эти метрики очень зависят друг от друга, то не зная все нельзя сделать правильные выводы.
Все эти метрики есть в iostat. Но как их положить в zabbix?
Легкое гугление приводит нас к различным парсерам iostat, в том числе и здесь.
Но мне по душе другой вариант, а именно парсинг вывода /sys/class/block/*/stat
Плюсы метода:
Но есть и недостатки:
Итак, кроме самого zabbix и zabbix-agent на наблюдаемой машине нам потребуется awk. Мы используем дистрибутив CentOS 7.4 и zabbix 3.4
Данные в zabbix мы будем собирать при помощи zabbix-agent, создав пользовательские ключи. Для этого в /etc/zabbix/zabbix_agentd.d нужно создать файлик userparameter_custom.vfs.conf примерно со следующим содержимым:
Тут все просто — создаем пользовательский ключ custom.vfs.dev.io.ms, в качестве параметра передаем туда имя блочного устройства, значением параметра будет 10 колонка файлика stat.
В этом файлике статистики всего 11 колонок, посмотреть их описание можно вот тут.
Колонка №10 это io_tics — количество миллисекунд затраченным устройством на ввод вывод. Как почти все параметры — эта цифра является аккумулятором и постоянно возрастает. Как же получить из них привычные метрики.
Эта метрика аналогична значению поля utils команды iostat -x. Характеризует загрузку дисковой подсистемы. По сути это сколько процентов реального времени система затратила на операции ввода-вывода за интервал между опросами. Как правило при приближении к 100% система начинает все больше простаивать в ожидании когда диски обработают ваши запросы.
Чтобы получить эту цифру — надо взять значение 10 колонки файла статистики и запомнить его в zabbix как скорость изменения в секунду, не забыв умножить на 0.1 так как значение в статистике в миллисекундах, а нам нужны проценты.

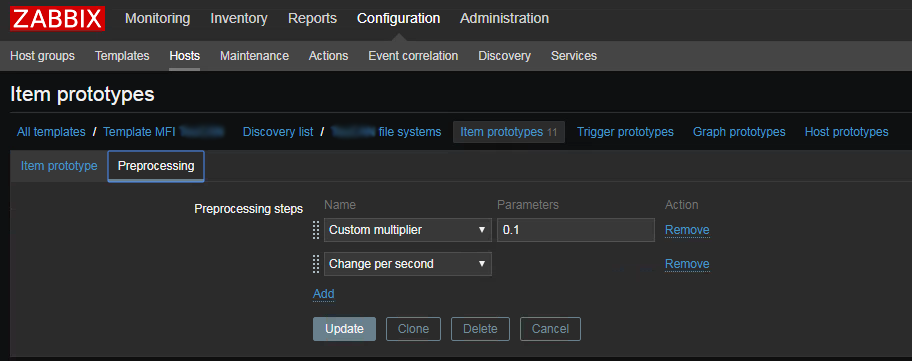
Аналогичным образом можно посчитать нагрузку записью/чтением (колонки write_ticks / read_ticks).
Эта метрика аналогична r_svctime и w_svctime для записи и чтения соответственно. По сути это усредненное время обработки запросов за интервал между опросами.
Данная метрика чуть посложнее. Рассмотрим на примере запросов на запись.
Для этого нам понадобится создать три ключа:
Абсолютно также считается время обработки запросов на чтение, только используя колонки №1 read I/Os и №4 read_ticks.
Метрика показывающая с какой скоростью данные были записаны или прочитаны
Для этой метрики используются колонки №3 read sectors и №5 write sectors. Значение сколько было прочитано или записано «секторов». Точно так же в zabbix сохраняем как изменение за секунду.
Единственный ньюанс - значение в файле указанно «в попугаях-секторах», причем размер этого «сектора» фиксирован 512 байт и не зависит от реальных значений ни физического ни логического сектора устройства (проверял на нескольких устройствах с реальным размером физического сектора 4к). Так что чтобы пересчитать в байты — не забудьте умножить на 512.
Эта метрика — те самые пресловутые IOPS
Самая простая метрика — мы ее уже записывали для подсчета svc time это значение колонок №5 write I/Os и №1 read I/Os также сохраненные как скорость в секунду.
Этих метрик мне как правило достаточно для того чтобы я мог делать обоснованные выводы. Конечно это не все цифры которые можно получить из файла статистики. Например там есть и число текущих обрабатываемых запросов, и количество запросов которые были объеденены. Но полагаю при необходимости вам не составит труда добавить их по аналогии с описанным.
И да не претендую на авторство — сам метод был когда-то давно загуглен, но за давностью лет ссылки конечно затерялись.
В заключении приведу шаблончик и файлик параметров.
Увы NDA заставляет кое-что подчистить из них, но надеюсь на работоспособность шаблона это не повлияет.
А в шапке скриншот из Grafana прикрученной поверх zabbix — демонстрирующий реальные цифры с одной из тестовых инсталляций.
Сегодня хочу поделиться с сообществом своим текущим опытом на реальном примере zabbix и его связке с block stat.
Небольшое отступление
Я являюсь архитектором баз данных и систем хранения очень высокой производительности и больших объемов. Поэтому часто сталкиваюсь с задачами оценки, как те или иные параметры настройки системы влияют на работу СХД, какие железные конфигурации СХД лучше.
Да есть куча утилит, которая позволит протестировать диски, например тот же fio. Но ничто не сравнится с тестированием реальной нагрузкой.
Однако прежде чем подавать реальную и настоящую нагрузку, неплохо бы сначала протестировать на синтетике. А наблюдать за синтетикой лучше теми же средствами, что и за боевой системой, просто потому, что даже если ваши метрики не совсем верны методологически – они будут хотя бы те же самые и по ним можно будет делать выводы лучше/хуже.
Когда то давным-давно для этих целей использовал iostat, лютый парсер к нему и gnuplot, и даже написал статейку habr.com/post/165855. Скажу я вам – это жутко неудобно.
Куда как удобнее натравить на систему zabbix и мониторить. А к zabbix можно прикрутить модную Grafana и мониторить красиво. Сразу скажу – выбор zabbix скорее исторический: «потому что он уже был».
Мониторинг дисков в zabbix
Справедливости ради скажу, что в zabbix уже есть встроенные ключи vfs.dev.*, но увы очень мало: скорость чтения и записи, объем.
А что нужно нам?
Практика показывает что ключевые метрики по которым можно оценивать дисковую подсистему это:
- Количество операций в секунду (ops)
- Пропускная способность (throughput)
- Время обработки запроса (latency или правильней svctime)
- Утилизация дисковой подсистемы (utilization)
Так как эти метрики очень зависят друг от друга, то не зная все нельзя сделать правильные выводы.
Все эти метрики есть в iostat. Но как их положить в zabbix?
Легкое гугление приводит нас к различным парсерам iostat, в том числе и здесь.
Но мне по душе другой вариант, а именно парсинг вывода /sys/class/block/*/stat
Плюсы метода:
- это первоисточник данных — iostat так же использует эти данные
- для разбора показателей можно ограничиться только однострочником в UserParameter без дополнительных скриптов.
Но есть и недостатки:
- Некоторые параметры необходимо вычислять делением дельты одного на дельту другого, причем не простой, а временной (скорости). В zabbix это сделать можно, но это будут не одновременные запросы, как если бы это делал сложный скрипт, а отношение последних значений, что в принципе не совсем верно, но в нашем случае довольно точно.
Итак, кроме самого zabbix и zabbix-agent на наблюдаемой машине нам потребуется awk. Мы используем дистрибутив CentOS 7.4 и zabbix 3.4
Данные в zabbix мы будем собирать при помощи zabbix-agent, создав пользовательские ключи. Для этого в /etc/zabbix/zabbix_agentd.d нужно создать файлик userparameter_custom.vfs.conf примерно со следующим содержимым:
UserParameter=custom.vfs.dev.io.ms[*],cat /sys/class/block/$1/stat | awk '{print $$10}'
Тут все просто — создаем пользовательский ключ custom.vfs.dev.io.ms, в качестве параметра передаем туда имя блочного устройства, значением параметра будет 10 колонка файлика stat.
В этом файлике статистики всего 11 колонок, посмотреть их описание можно вот тут.
Колонка №10 это io_tics — количество миллисекунд затраченным устройством на ввод вывод. Как почти все параметры — эта цифра является аккумулятором и постоянно возрастает. Как же получить из них привычные метрики.
Утилизация дисковой подсистемы
Эта метрика аналогична значению поля utils команды iostat -x. Характеризует загрузку дисковой подсистемы. По сути это сколько процентов реального времени система затратила на операции ввода-вывода за интервал между опросами. Как правило при приближении к 100% система начинает все больше простаивать в ожидании когда диски обработают ваши запросы.
Чтобы получить эту цифру — надо взять значение 10 колонки файла статистики и запомнить его в zabbix как скорость изменения в секунду, не забыв умножить на 0.1 так как значение в статистике в миллисекундах, а нам нужны проценты.
Аналогичным образом можно посчитать нагрузку записью/чтением (колонки write_ticks / read_ticks).
Время обработки запроса
Эта метрика аналогична r_svctime и w_svctime для записи и чтения соответственно. По сути это усредненное время обработки запросов за интервал между опросами.
Данная метрика чуть посложнее. Рассмотрим на примере запросов на запись.
Для этого нам понадобится создать три ключа:
- write utils — количество времени потраченное на запись — колонка №8 write_ticks сохраненная, как скорость изменения в секунду между опросами. По сути значение ключа в zabbix будет утилизация записью.
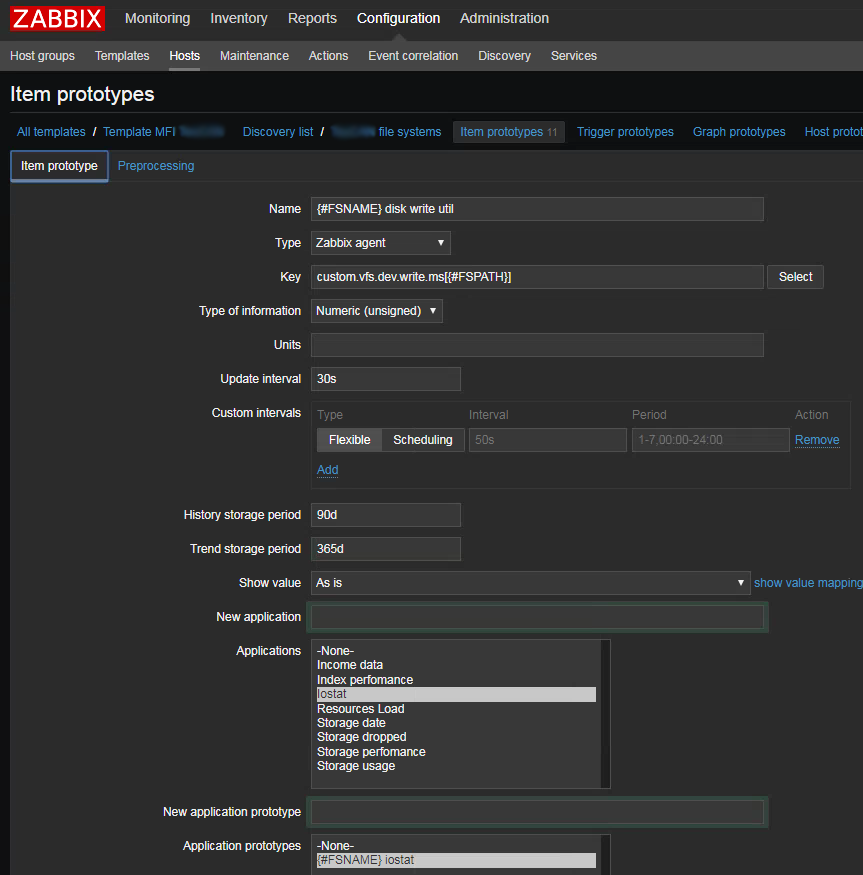
- write ops — количество запросов на запись — колонка №5 write I/Os. Так же сохраняем как скорость
- svctime или latency — искомый параметр. Создаем как вычисляемое значение: последнее значение write utils / последнее значение write ops. Плюс еще поделить на 1000 чтобы в секунды перейти
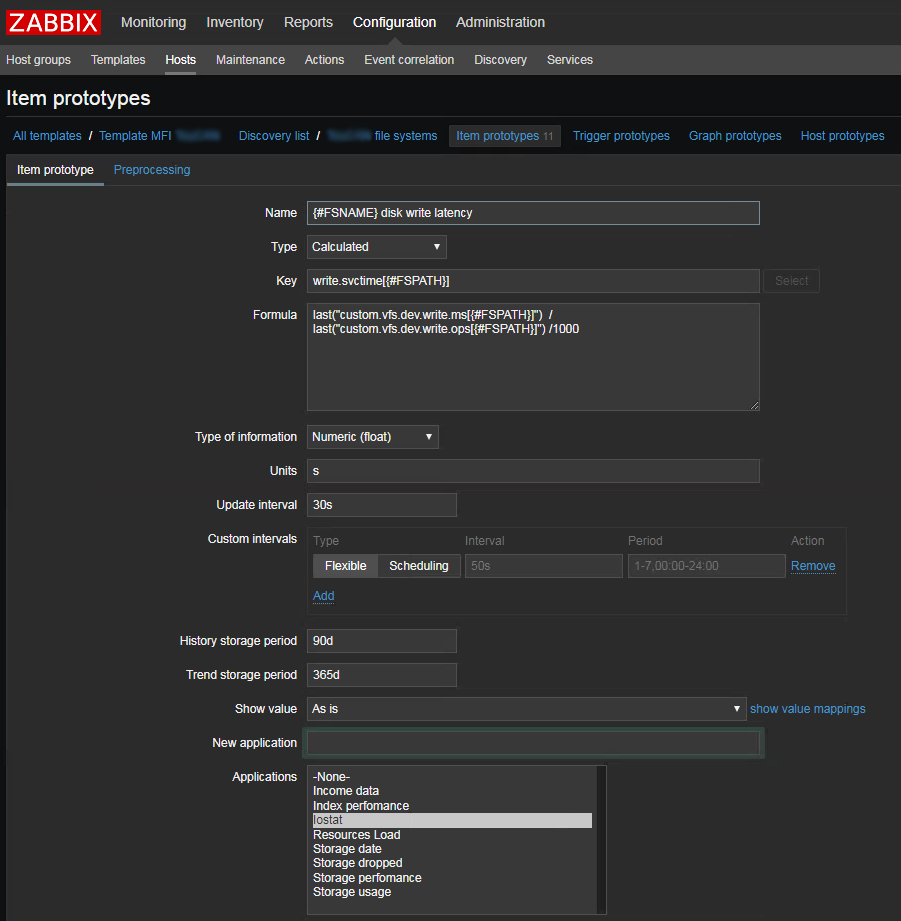
Абсолютно также считается время обработки запросов на чтение, только используя колонки №1 read I/Os и №4 read_ticks.
Пропускная способность
Метрика показывающая с какой скоростью данные были записаны или прочитаны
Для этой метрики используются колонки №3 read sectors и №5 write sectors. Значение сколько было прочитано или записано «секторов». Точно так же в zabbix сохраняем как изменение за секунду.
Единственный ньюанс - значение в файле указанно «в попугаях-секторах», причем размер этого «сектора» фиксирован 512 байт и не зависит от реальных значений ни физического ни логического сектора устройства (проверял на нескольких устройствах с реальным размером физического сектора 4к). Так что чтобы пересчитать в байты — не забудьте умножить на 512.
Количество операций ввода-вывода в секунду
Эта метрика — те самые пресловутые IOPS
Самая простая метрика — мы ее уже записывали для подсчета svc time это значение колонок №5 write I/Os и №1 read I/Os также сохраненные как скорость в секунду.
Заключение
Этих метрик мне как правило достаточно для того чтобы я мог делать обоснованные выводы. Конечно это не все цифры которые можно получить из файла статистики. Например там есть и число текущих обрабатываемых запросов, и количество запросов которые были объеденены. Но полагаю при необходимости вам не составит труда добавить их по аналогии с описанным.
И да не претендую на авторство — сам метод был когда-то давно загуглен, но за давностью лет ссылки конечно затерялись.
В заключении приведу шаблончик и файлик параметров.
Увы NDA заставляет кое-что подчистить из них, но надеюсь на работоспособность шаблона это не повлияет.
А в шапке скриншот из Grafana прикрученной поверх zabbix — демонстрирующий реальные цифры с одной из тестовых инсталляций.

