Не мы первые заметили, что компактные компьютеры типа Intel Compute Stick недостаточно хороши в плане производительности. Знакомясь с аналогичным устройством от Biostar, ожидания были не самые оптимистические. Как и младшие модели стик-компьютеров, Racing P1 работает на одном из самых слабеньких процессоров семейства Atom Z8000. Впрочем, выбранный компанией Biostar чип x5-Z8350 пусть на одну ступеньку, но продуктивнее своего младшего собрата. Попробуем оценить производительность данной платформы, которая стараниями Biostar уже не стик, но, правда, еще и не ноутбук.

Используемые инструменты — банчмарк NCRB (NUMA CPU and RAM Benchmarks) для Win64 и кроссплатформенная утилита для идентификации процессора JavaCPUID.
Процессор
Инструкция CPUID подтверждает, что на платформе Biostar Racing P1 установлен процессор Intel Atom x5-Z8350. Его штатная частота равна 1.44 ГГц, что, однако, не мешает ему при необходимости законно разгоняться до 1,92 ГГц. Даже при непродолжительном знакомстве с этой платформой очевиден парадокс: ее работа в диапазоне от 1,44 до 1,92 — скорее правило, чем исключение из него.

Принятие решения процессором x5-Z8350 о выборе минимальной или штатной тактовой частоты и запуске режима Turbo выполняется на основании анализа нагрузки и рабочей температуры. Рамки SDP (Scenario Dissipated Power) определяют типичное энергопотребление устройства. Механизмы управления самостоятельно оценивают ситуацию, и в случае «легкой» нагрузки снижают энергопотребление чипа. Возможность включить режим Turbo является функцией температуры, поэтому результаты летних и зимних тестов могут отличаться. В общем, Racing P1 тоже «переобувается» к сезону.
Выходя за рамки исследования отметим, что форсаж приводит к потреблению до 7 Ватт на силовых линиях ~220 В. Крейсерский режим Racing P1 уменьшает это значение приблизительно вполовину, режим сна требует чуть более 2 Вт от сети переменного тока (мониторинг потребления выполнялся обычным бытовым ваттметром).
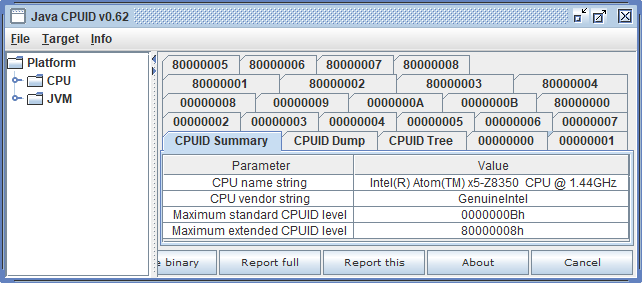
Intel Atom x5-Z8350 работает с данными, максимальная разрядность которых составляет 128 бит. Современные функциональные расширения AVX 256/512 не поддерживаются. Это значит, что нашим измерительным инструментом будет набор векторных инструкций SSE 128, а объектом измерений — кэш-память и динамическое ОЗУ.
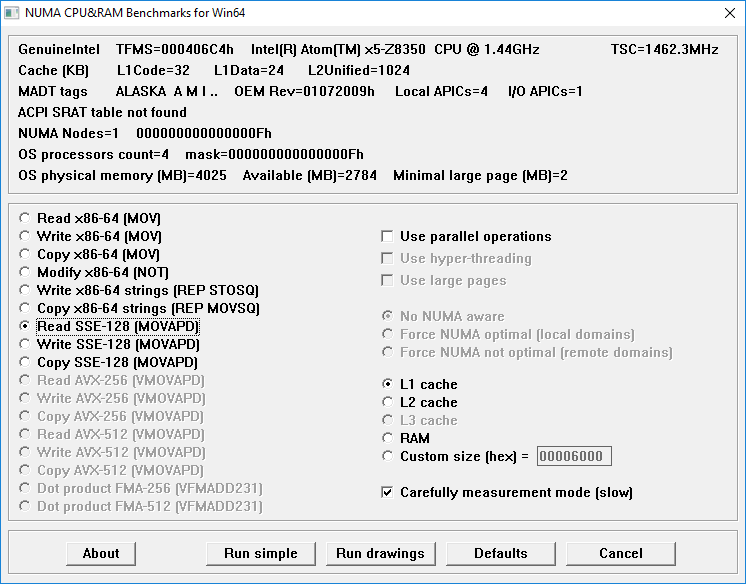
Здесь уместно важное отступление: в общем случае максимальная разрядность операндов не означает максимальную производительность. Так, ряд процессоров AMD в конструктиве до AM2 включительно обрабатывают две 64-битных загрузки классическими инструкциями MOV быстрее, чем одну 128-битную SSE-загрузку инструкцией MOVAPD. Вспомнив об этом, мы до начала измерений экспериментально убедились — использование SSE для Atom x5-Z8350 действительно является наиболее производительным сценарием.
Кэш-память L1
Обычно, объем кэш-памяти — величина, кратная степени двойки. На первом уровне производитель старается равномерно распределить ее между инструкциями и данными. Все эти каноны не соблюдаются архитектурой процессора x5-Z8350. У каждого из четырех его ядер 32 килобайта кэш-памяти для инструкций и 24 килобайта — для данных.

В ряде источников приводится произведение размера кэш-памяти одного ядра на их количество, что дает более впечатляющее представление: 128KB кэш инструкций и 96KB кэш данных. Официальная страничка по традиции умалчивает о кэш-памяти L1, во всяком случае, на момент написания этой статьи.
Отметим, кэш-память нулевого уровня (подобная L1 Trace Cache), хранящая декодированные команды и повышающая эффективность коротких циклов, не декларируется инструкцией CPUID. Проверка ее наличия и анализ функционирования достойны отдельной публикации.
Теории и практика: производительность кэш-памяти
Измерение скорости кэш-памяти состоит в циклических операциях чтения или записи блока, размер которого меньше размера исследуемого уровня кэш, а потому операции доступа к данным являются кэш-попаданиями (cache hits). Фактически, выбор целевого объекта (L1, L2 cache или DRAM) определяется размером обрабатываемого блока данных.
Задав тестируемую сущность, переходим к рассмотрению операции на уровне машинных команд. В нашем эксперименте используется развернутый цикл из шестнадцати SSE2-инструкций MOVAPD, каждая из которых передает 128-битный операнд между памятью и одним из XMM-регистров. В итоге за одну итерацию цикла полностью загружаются 16 регистров XMM0…XMM15.
Для полноты изложения заметим, что инструкция MOVAPD может использоваться и для передачи данных между двумя XMM-регистрами, но в нашем случае регистровые операции не дадут представление о производительности объектов памяти. Максимальную производительность обеспечивает обязательное для инструкции MOVAPD требование выравнивания: адрес операнда должен быть кратным 16 байтам (128 битам).
Бенчмарки кэш-памяти L1
Пока читаемый или записываемый блок меньше размера кэш-памяти L1 (на графике это ось X), скорость обмена высокая. Как только блок выходит за пределы L1 — возникают кэш-промахи и скорость падает. Очевидно, что при оценке производительности, информативной является «верхняя ступенька», соответствующая левому участку графика.
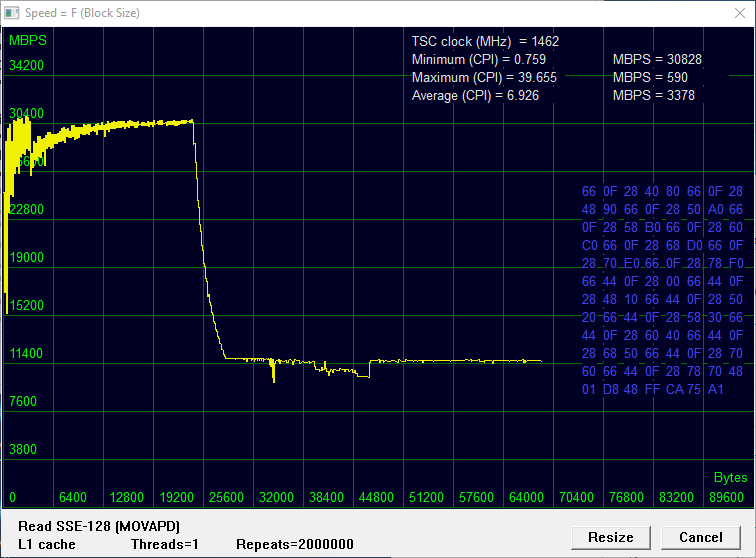
окрестность X = Размер L1
Максимальная скорость в мегабайтах в секунду (MBPS) соответствует минимальному количеству тактов на инструкцию (CPI, Clocks Per Instruction) и составляет около 30 GBPS.

окрестность X = Размер L1
Как видно из графиков, точка перегиба для чтения L1 соответствует теоретической величине в 24 килобайта. Для записи, примененную в данном процессоре политику кэширования характеризует «раннее падение» скорости, что станет темой отдельного исследования. Но уже сейчас можно отметить — эта политика не способствует рекордным показателям скорости записи, хотя в ряде случаев, возможно, и позволяет избежать засорения L1 ненужными данными.
В полученных результатах отображается скорость, развиваемая одним ядром процессора Atom x5-Z8350. Ряд тестов, в частности AIDA64, показывают суммарную производительность всех ядер.
Проведем небольшой теоретический расчет, смоделировав пиковую пропускную способность. Для исследуемого CPU тактовая частота в режиме Turbo составляет 1920 МГц. За один такт передается 128 бит или 16 байт:
- 1920 * 16 = 30720 (около 30 Гигабайт в секунду)
В качестве источника образцовых интервалов времени используется счетчик TSC (Time Stamp Counter). Поскольку ядро процессора и TSC в общем случае тактируются асинхронно, значения тактов TSC на инструкцию являются дробными величинами.
Убедимся, что процессор работает в режиме Turbo, опираясь на значения частот, указанные в документации. Один такт форсированной частоты ядра 1920 МГц составляет примерно 0,521 наносекунды. Один такт номинальной частоты 1440 МГц, на которой работает регистр Time Stamp Counter составляет примерно 0,694 наносекунды. Для инструкций, выполняемых за один такт, теоретическое значение количества тактов TSC на инструкцию (CPI) должно составлять
- 0,521 / 0,694 = 0,750
Отображаемые измеренные значения Minimum CPI в пределах 0,759…0,767 достаточно близки к этому значению.
Кэш-память L2
Четыре ядра исследуемого процессора разделены на две группы, по два ядра в каждой. Общий размер кэш-памяти L2 составляет 2 МБ и поровну разделен между ними. Вывод очевиден: каждому ядру доступен 1 мегабайт кэш-памяти L2, доступ к которому делится с соседом по группе.
Бенчмарки кэш-памяти L2
Скорость L2-кэш — это центральная «ступенька», возникающая при соблюдении двойного неравенства 24 КБ < X < 1 МБ, — когда обрабатываемый блок данных уже не помещается в L1, но еще помещается в L2.

окрестность X = Размер L2
Как видно из графиков, снижение скорости, обусловленное исчерпанием L2, происходит при превышении лимита в 1 МБ. Возможность «одолжить» кэш у соседней группы, передвинув момент спада скорости к точке 2 МБ, не обнаружена.
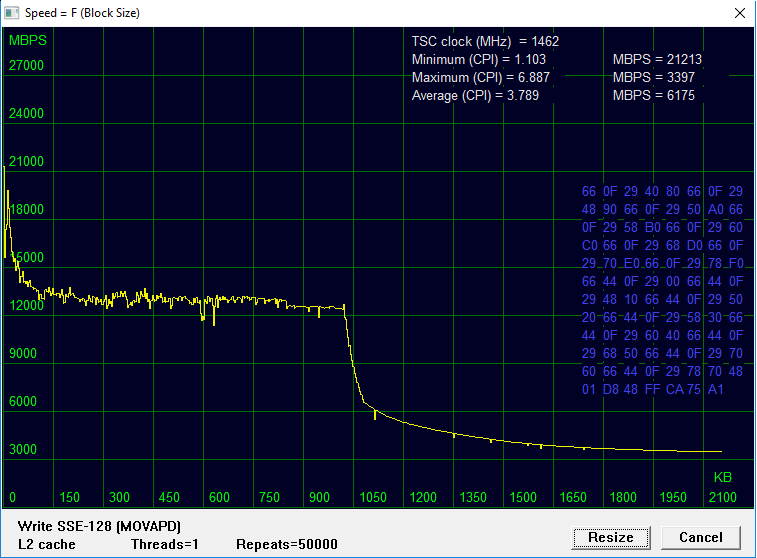
окрестность X = Размер L2
Оценка производительности L2-кэш по записи близка к показателям чтения: 12 против 11,5 GBPS. Теоретические предпосылки такого результата рассмотрим в следующей публикации.