Развертываение kubernetes HA с containerd

Добрый день уважаемые читатели Хабра! 24.05.2018 г. в официальном блоге Kubernetes была опубликована статья под названием Kubernetes Containerd Integration Goes GA, в которой говорится, что интеграция containerd с Kubernetes готова к production. Также ребята из компании Флант в своем блоге разместили перевод статьи на русский язык, добавив немного уточнений от себя. Почитав документацию проекта на github, я решил попробовать containerd на "собственной шкуре".
У нас в компании есть несколько проектов в стадии "до продакшена еще очень далеко". Вот они и станут нашими подопытными; для них мы решили попробовать развернуть отказоустойчивый кластер Kubernetes с использованием containerd и посмотреть, есть ли жизнь без docker.
Если Вам интересно посмотреть, как мы это делали и что из этого получилось, — добро пожаловать под кат.
Cхема и описание развертывания

При разворачивании кластера, как и обычно, ( об этом я писал в предыдущей статье мы используем
Демоны keepalived общаются по протоколу VRRP, посылая друг другу сообщения на адрес 224.0.0.18.
Если сосед не прислал свое сообщение, то по истечению периода он считается умершим. Как только упавший сервер начинает слать свои сообщения в сеть, все возвращается на свои места
Работу с API сервером на нодах kubernetes мы настраиваем следующим образом.
После установки кластера настраиваем kube-proxy, меняем порт с 6443 на 16443 (подробности ниже). На каждом из мастеров развернут nginx, который работает как loadbalancer, слушает порт 16443 и делает upstream по всем трем мастерам на порт 6443 (подробности ниже).
Данной схемой достигнута повышенная отказоустойчивость c помощью keepalived, а так же с помощью nginx достигнута балансировка между API серверами на мастерах.
В прошлой статье я описывал развертывание nginx и etcd в docker. Но в данном случае docker у нас отсутствует, поэтому nginx и etcd будут работать локально на мастернодах.
Теоретически можно было бы развернуть nginx и etcd с помощью containerd, но в случае каких либо проблем данный подход усложнил бы диагностику, поэтому все же решили не экспериментировать и запускать из локально.
Описание серверов для развертывания:
| Name | IP | Службы |
|---|---|---|
| VIRTIP | 172.26.133.160 | ------ |
| kube-master01 | 172.26.133.161 | kubeadm, kubelet, kubectl, etcd, containerd, nginx, keepalived |
| kube-master02 | 172.26.133.162 | kubeadm, kubelet, kubectl, etcd, containerd, nginx, keepalived |
| kube-master03 | 172.26.133.163 | kubeadm, kubelet, kubectl, etcd, containerd, nginx, keepalived |
| kube-node01 | 172.26.133.164 | kubeadm, kubelet, kubectl, containerd |
| kube-node02 | 172.26.133.165 | kubeadm, kubelet, kubectl, containerd |
| kube-node03 | 172.26.133.166 | kubeadm, kubelet, kubectl, containerd |
Установка kubeadm, kubelet, kubectl и сопутствующие пакеты
Все комманды выполнять из под root
sudo -i
apt-get update && apt-get install -y apt-transport-https curl curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl unzip tar apt-transport-https btrfs-tools libseccomp2 socat util-linux mc vim keepalived
Установка conteinerd
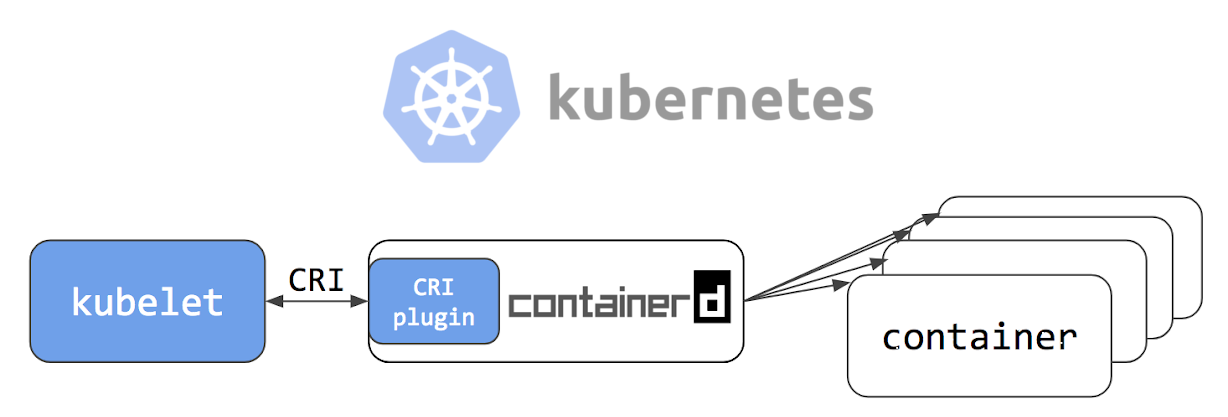
cd / wget https://storage.googleapis.com/cri-containerd-release/cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz tar -xvf cri-containerd-1.1.0-rc.0.linux-amd64.tar.gz
Настраиваем конфиги containerd
mkdir -p /etc/containerd nano /etc/containerd/config.toml
Добавляем в файл:
[plugins.cri] enable_tls_streaming = true
Cтартуем conteinerd проверяем, что все ОК
systemctl enable containerd systemctl start containerd systemctl status containerd ● containerd.service - containerd container runtime Loaded: loaded (/etc/systemd/system/containerd.service; disabled; vendor preset: enabled) Active: active (running) since Mon 2018-06-25 12:32:01 MSK; 7s ago Docs: https://containerd.io Process: 10725 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS) Main PID: 10730 (containerd) Tasks: 15 (limit: 4915) Memory: 14.9M CPU: 375ms CGroup: /system.slice/containerd.service └─10730 /usr/local/bin/containerd Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Get image filesystem path "/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs"" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=error msg="Failed to load cni during init, please check CRI plugin status before setting up network for pods" error="cni con Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="loading plugin "io.containerd.grpc.v1.introspection"..." type=io.containerd.grpc.v1 Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start subscribing containerd event" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start recovering state" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg=serving... address="/run/containerd/containerd.sock" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="containerd successfully booted in 0.308755s" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start event monitor" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start snapshots syncer" Jun 25 12:32:01 hb-master02 containerd[10730]: time="2018-06-25T12:32:01+03:00" level=info msg="Start streaming server"
Установка и запуск etcd
Важное замечание, я проводил установку кластера kubernetes версии 1.10. Буквально через пару дней, во время написания статьи вышла версия 1.11 Если вы устанавливаете версию 1.11, то установите переменную ETCD_VERSION="v3.2.17", если 1.10 то ETCD_VERSION="v3.1.12".
export ETCD_VERSION="v3.1.12" curl -sSL https://github.com/coreos/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin/
Копируем конфиги с гитахаба.
git clone https://github.com/rjeka/k8s-containerd.git cd k8s-containerd
Настраиваем переменные в конфиг файле.
vim create-config.sh
#!/bin/bash # local machine ip address export K8SHA_IPLOCAL=172.26.133.161 # local machine etcd name, options: etcd1, etcd2, etcd3 export K8SHA_ETCDNAME=kube-master01 # local machine keepalived state config, options: MASTER, BACKUP. One keepalived cluster only one MASTER, other's are BACKUP export K8SHA_KA_STATE=MASTER # local machine keepalived priority config, options: 102, 101,100 MASTER must 102 export K8SHA_KA_PRIO=102 # local machine keepalived network interface name config, for example: eth0 export K8SHA_KA_INTF=ens18 ####################################### # all masters settings below must be same ####################################### # master keepalived virtual ip address export K8SHA_IPVIRTUAL=172.26.133.160 # master01 ip address export K8SHA_IP1=172.26.133.161 # master02 ip address export K8SHA_IP2=172.26.133.162 # master03 ip address export K8SHA_IP3=172.26.133.163 # master01 hostname export K8SHA_HOSTNAME1=kube-master01 # master02 hostname export K8SHA_HOSTNAME2=kube-master02 # master03 hostname export K8SHA_HOSTNAME3=kube-master03 # keepalived auth_pass config, all masters must be same export K8SHA_KA_AUTH=56cf8dd754c90194d1600c483e10abfr #etcd tocken: export ETCD_TOKEN=9489bf67bdfe1b3ae077d6fd9e7efefd # kubernetes cluster token, you can use 'kubeadm token generate' to get a new one export K8SHA_TOKEN=535tdi.utzk5hf75b04ht8l # kubernetes CIDR pod subnet, if CIDR pod subnet is "10.244.0.0/16" please set to "10.244.0.0\\/16" export K8SHA_CIDR=10.244.0.0\\/16
настройки на локальной машине каждой из нод (на каждой ноде свои)
K8SHA_IPLOCAL — IP адрес ноды на которой настраивается скрипт
K8SHA_ETCDNAME — имя локальной машины в кластере ETCD
K8SHA_KA_STATE — роль в keepalived. Одна нода MASTER, все остальные BACKUP.
K8SHA_KA_PRIO — приоритет keepalived, у мастера 102 у остальных 101, 100 При падении мастера с номером 102, его место занимает нода с номером 101 и так далее.
K8SHA_KA_INTF — keepalived network interface. Имя интерфейса который будет слушать keepalived.
Общие настройки для всех мастернод одинаковые:
K8SHA_IPVIRTUAL=172.26.133.160 — виртуальный IP кластера.
K8SHA_IP1...K8SHA_IP3 — IP адреса мастеров
K8SHA_HOSTNAME1 ...K8SHA_HOSTNAME3 — имена хостов для мастернод. Важный пункт, по этим именам kubeadm будет генерировать сертификаты.
K8SHA_KA_AUTH — пароль для keepalived. Можно задать произвольный
K8SHA_TOKEN — токен кластера. Можно сгенерировать командой kubeadm token generate
K8SHA_CIDR — адрес подсети для подов. Я использую flannel поэтому CIDR 0.244.0.0/16. Обязательно экранировать — в конфиге должно быть K8SHA_CIDR=10.244.0.0\/16
Запускаем скрипт, который сконфигурирует nginx, keepalived, etcd и kubeadmin
./create-config.sh
Запускаем etcd.
etcd я поднимал без tls. Если Вам нужен tls, то в официальной документации kubernetes подробно написано, как генерировать сертификаты для etcd.
systemctl daemon-reload && systemctl start etcd && systemctl enable etcd
Проверка статуса
etcdctl cluster-health member ad059013ec46f37 is healthy: got healthy result from http://192.168.5.49:2379 member 4d63136c9a3226a1 is healthy: got healthy result from http://192.168.4.169:2379 member d61978cb3555071e is healthy: got healthy result from http://192.168.4.170:2379 cluster is healthy etcdctl member list ad059013ec46f37: name=hb-master03 peerURLs=http://192.168.5.48:2380 clientURLs=http://192.168.5.49:2379,http://192.168.5.49:4001 isLeader=false 4d63136c9a3226a1: name=hb-master01 peerURLs=http://192.168.4.169:2380 clientURLs=http://192.168.4.169:2379,http://192.168.4.169:4001 isLeader=true d61978cb3555071e: name=hb-master02 peerURLs=http://192.168.4.170:2380 clientURLs=http://192.168.4.170:2379,http://192.168.4.170:4001 isLeader=false
Если все хорошо, приступаем к следующему шагу.
Настраиваем kubeadmin
Если вы используете kubeadm версии 1.11 этот шаг можно пропустить
Для того, чтобы kybernetes начал работать не с docker, а с containerd, настроим конфиг kubeadmin
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
После [Service] добавляем строчку в блок
Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
[Service] Environment="KUBELET_EXTRA_ARGS=--runtime-cgroups=/system.slice/containerd.service --container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock" Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true" Environment="KUBELET_NETWORK_ARGS=--network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin" Environment="KUBELET_DNS_ARGS=--cluster-dns=10.96.0.10 --cluster-domain=cluster.local" Environment="KUBELET_AUTHZ_ARGS=--authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca.crt" Environment="KUBELET_CADVISOR_ARGS=--cadvisor-port=0" Environment="KUBELET_CERTIFICATE_ARGS=--rotate-certificates=true --cert-dir=/var/lib/kubelet/pki" ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_SYSTEM_PODS_ARGS $KUBELET_NETWORK_ARGS $KUBELET_DNS_ARGS $KUBELET_AUTHZ_ARGS $KUBELET_CADVISOR_ARGS $KUBELET_CERTIFICATE_ARGS $KUBELET_EXTRA_ARGS
Если вы ставите версию 1.11 и хотите поэкспериментировать с CoreDNS вместо kube-dns и потестить динамическую конфигурацию, раскоментируйте в файле настройки kubeadm-init.yaml следующий блок:
feature-gates: DynamicKubeletConfig: true CoreDNS: true
Рестартуем kubelet
systemctl daemon-reload && systemctl restart kubelet
Инициализация первого мастера
Перед тем, как запустить kubeadm, нужно рестартануть keepalived и проверить его статус
systemctl restart keepalived.service systemctl status keepalived.service ● keepalived.service - Keepalive Daemon (LVS and VRRP) Loaded: loaded (/lib/systemd/system/keepalived.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2018-06-27 10:40:03 MSK; 1min 44s ago Process: 4589 ExecStart=/usr/sbin/keepalived $DAEMON_ARGS (code=exited, status=0/SUCCESS) Main PID: 4590 (keepalived) Tasks: 7 (limit: 4915) Memory: 15.3M CPU: 968ms CGroup: /system.slice/keepalived.service ├─4590 /usr/sbin/keepalived ├─4591 /usr/sbin/keepalived ├─4593 /usr/sbin/keepalived ├─5222 /usr/sbin/keepalived ├─5223 sh -c /etc/keepalived/check_apiserver.sh ├─5224 /bin/bash /etc/keepalived/check_apiserver.sh └─5231 sleep 5
проверить, пингуется ли VIRTIP
ping -c 4 172.26.133.160 PING 172.26.133.160 (172.26.133.160) 56(84) bytes of data. 64 bytes from 172.26.133.160: icmp_seq=1 ttl=64 time=0.030 ms 64 bytes from 172.26.133.160: icmp_seq=2 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=3 ttl=64 time=0.050 ms 64 bytes from 172.26.133.160: icmp_seq=4 ttl=64 time=0.056 ms --- 172.26.133.160 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3069ms rtt min/avg/max/mdev = 0.030/0.046/0.056/0.012 ms
После этого запускаем kubeadmin. Обязательно указать строчку --skip-preflight-checks. Kubeadmin по умолчанию ищет docker и без пропуска проверок вывалится с ошибкой.
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
После того, как kubeadm отработал, сохраняем cгенерированную строку. Она понадобится для ввода в кластер рабочих нод.
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Далее указываем, где хранится файл admin.conf
Если работаем под root то:
vim ~/.bashrc export KUBECONFIG=/etc/kubernetes/admin.conf source ~/.bashrc
Для простого пользователя следуем инструкциям на экране.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
Добавляем в кластер еще 2 мастера. Для этого нужно скопировать сертификаты из kube-master01 на kube-master02 и kube-master03 в каталог /etc/kubernetes/. Я для этого настраивал доступ по ssh для root, а после копирования файлов возвращал настройки обратно.
scp -r /etc/kubernetes/pki 172.26.133.162:/etc/kubernetes/ scp -r /etc/kubernetes/pki 172.26.133.163:/etc/kubernetes/
После копирования на kube-master02 и kube-master03 запускаем.
kubeadm init --config=kubeadm-init.yaml --skip-preflight-checks
Установка CIDR flannel
на kube-master01 выполнить
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
Акутальную версию flanel можно посмотреть в документации kubernetes.
Дожидаемся пока создадутся все контейнеры
watch -n1 kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE kube-system kube-apiserver-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-apiserver-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-apiserver-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-controller-manager-kube-master01 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-controller-manager-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-controller-manager-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-dns-86f4d74b45-8c24s 3/3 Running 0 17m 10.244.2.2 kube-master03 kube-system kube-flannel-ds-4h4w7 1/1 Running 0 2m 172.26.133.163 kube-master03 kube-system kube-flannel-ds-kf5mj 1/1 Running 0 2m 172.26.133.162 kube-master02 kube-system kube-flannel-ds-q6k4z 1/1 Running 0 2m 172.26.133.161 kube-master01 kube-system kube-proxy-9cjtp 1/1 Running 0 6m 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 0 17m 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master01 1/1 Running 0 18m 172.26.133.161 kube-master01 kube-system kube-scheduler-kube-master02 1/1 Running 0 6m 172.26.133.162 kube-master02 kube-system kube-scheduler-kube-master03 1/1 Running 0 6m 172.26.133.163 kube-master03
Делаем репликацию kube-dns на все три мастера
На kube-master01 выполнить
kubectl scale --replicas=3 -n kube-system deployment/kube-dns
Установка и настройка nginx
На каждой мастер ноде устанавливаем nginx в качестве балансировщика для API Kubernetes
У меня все машины кластера на debian. Из пакетов nginx не поддерживает модуль stream, по этому добавим репозитории nginx и установим его из репозиториев nginx`a. Если у вас другая ОС, то смотрите документацию nginx.
wget https://nginx.org/keys/nginx_signing.key sudo apt-key add nginx_signing.key echo -e "\n#nginx\n\ deb http://nginx.org/packages/debian/ stretch nginx\n\ deb-src http://nginx.org/packages/debian/ stretch nginx" >> /etc/apt/sources.list apt-get update && apt-get install nginx -y
Создадим конфиг nginx (если еще не создан)
./create-config.sh
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf;
}
stream {
upstream apiserver {
server 172.26.133.161:6443 weight=5 max_fails=3 fail_timeout=30s;
server 172.26.133.162:6443 weight=5 max_fails=3 fail_timeout=30s;
server 172.26.133.163:6443 weight=5 max_fails=3 fail_timeout=30s;
} server { listen 16443; proxy_connect_timeout 1s; proxy_timeout 3s; proxy_pass apiserver; }
}
Проверяем, что все ОК и применяем конфигурацию
nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful systemctl restart nginx systemctl status nginx ● nginx.service - nginx - high performance web server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Thu 2018-06-28 08:48:09 MSK; 22s ago Docs: http://nginx.org/en/docs/ Process: 22132 ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf (code=exited, status=0/SUCCESS) Main PID: 22133 (nginx) Tasks: 2 (limit: 4915) Memory: 1.6M CPU: 7ms CGroup: /system.slice/nginx.service ├─22133 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf └─22134 nginx: worker process
Протестируем работу балансировщика
curl -k https://172.26.133.161:16443 | wc -l % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 233 100 233 0 0 12348 0 --:--:-- --:--:-- --:--:-- 12944
Конфигурируем kube-proxy для работы с балансировщиком
После того, как настроен балансировщик, редактируем порт в настройках kubernetes.
kubectl edit -n kube-system configmap/kube-proxy
Меняем настройки server на https://172.26.133.160:16443
Далее нужно настроить kube-proxy на работу c новым портом
kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-9cjtp 1/1 Running 1 22h 172.26.133.163 kube-master03 kube-system kube-proxy-9sqk2 1/1 Running 1 22h 172.26.133.161 kube-master01 kube-system kube-proxy-jg2pt 1/1 Running 4 22h 172.26.133.162 kube-
Удаляем все поды, после удаления они автоматом пересоздаются с новыми настройками
kubectl delete pod -n kube-system kube-proxy-XXX ```bash Проверяем что все рестартанули. Время жизни должно быть небольшое ```bash kubectl get pods --all-namespaces -o wide | grep proxy kube-system kube-proxy-hqrsw 1/1 Running 0 33s 172.26.133.161 kube-master01 kube-system kube-proxy-kzvw5 1/1 Running 0 47s 172.26.133.163 kube-master03 kube-system kube-proxy-zzkz5 1/1 Running 0 7s 172.26.133.162 kube-master02
Добавление рабочих нод в кластер
На каждой ноде из-под рута выполнить команду, которую сгенерировал kubeadm
kubeadm join 172.26.133.160:6443 --token XXXXXXXXXXXXXXXXXXXXXXXXX --discovery-token-ca-cert-hash sha256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX --cri-socket /run/containerd/containerd.sock --skip-preflight-checks
Если строчку "потеряли", то нужно сгенерировать новую
kubeadm token generate kubeadm token create <generated-token> --print-join-command --ttl=0
На рабочих нодах в файлах /etc/kubernetes/bootstrap-kubelet.conf и /etc/kubernetes/kubelet.conf меняем
значение переменной server на наш VIRTIP
vim /etc/kubernetes/bootstrap-kubelet.conf server: https://172.26.133.60:16443 vim /etc/kubernetes/kubelet.conf server: https://172.26.133.60:16443
И рестартуем containerd и kubernetes
systemctl restart containerd kubelet
Установка dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml
Создаем пользователя с админскими полномочиями:
kubectl apply -f kube-dashboard/dashboard-adminUser.yaml
Получаем токен для входа:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')
Настраиваем доступ dashboard через NodePort на VIRTIP
kubectl -n kube-system edit service kubernetes-dashboard
Заменяем значение type: ClusterIP на type: NodePort и в секцию port: добавляем значение nodePort: 30000 (или порт в диапазоне 30000 до 32000 на котором вы хотите что бы была доступна панель):

Теперь панель доступна по адресу https://VIRTIP:30000
Heapster
Далее установим Heapster — это инструмент для получения метрик составляющих кластера.
Установка:
git clone https://github.com/kubernetes/heapster.git cd heapster kubectl create -f deploy/kube-config/influxdb/ kubectl create -f deploy/kube-config/rbac/heapster-rbac.yaml
Выводы
Особых проблем при работе с containerd я не заметил. Один раз был непонятный глюк с подом после удаления деплоя. Kubernetes считал, что под удален, но под стал таким своеобразным "зомби. Он остался существовать на ноде, но в статусе extended.
Я считаю, что Containerd более ориентирована в качестве среды выполнения контейнеров для kubernetes. Скорее всего в перспективе в качестве среды для запуска микросервисов в Kubernetes можно и нужно будет использовать разные среды, которые будут ориентированны для разных задач, проектов и т.д.
Проект очень быстро развивается. Alibaba Cloud начал активно использовать conatinerd и подчеркивает, что это идеальная среда для выполнения контейнеров.
Как уверяют разработчики, интеграция containerd в облачной платформе Google Kubernetes теперь эквивалентна интеграции Docker.
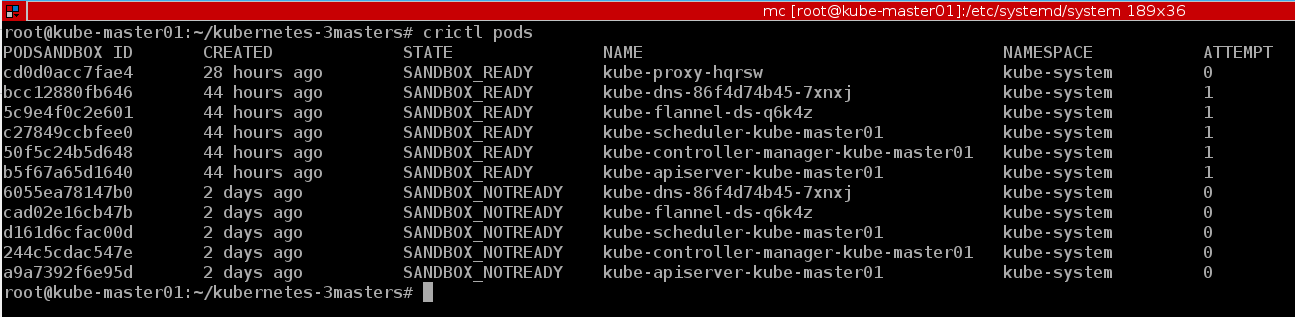
Хороший пример работы консольной утилиты crictl . Также приведу немного примеров из созданного кластера:
kubectl describe nodes | grep "Container Runtime Version:"

В Docker CLI отсутствуют основные концепции Kubernetes, например, pod и namespace, а crictl поддерживает данные концепции
crictl pods
А если нужно, то можем посмотреть и контейнеры в привычном формате, как у docker
crictl ps

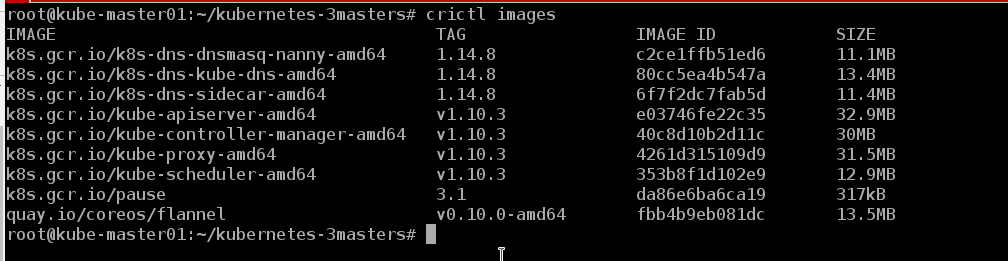
Можем посмотреть образы, которые есть на ноде
crictl images
Как оказалось, жизнь без docker` есть :)
Про баги и глюки пока говорить рано, кластер у нас работает где-то неделю. В ближайшее время на него будет перенесен test, а в случае успеха скорее всего и dev стенд одного из проектов. Об этом есть идея написать цикл статей охватывающих процессы DevOps, такие как: создание кластера, настройка ingress контроллера и вынос его на отдельные ноды кластера, автоматизация сборки образов, проверка образов на уязвимости, деплой и т.д. А пока будем смотреть на стабильность работы, искать баги и осваивать новые продукты.
Также данный мануал подойдет для развертывания отказоустойчивого кластера c docker, нужно только поставить docker по инструкции из официальной документации Kubernetes и пропустить шаги по установке containerd и настройки конфига kubeadm.
Или можно поставить containerd и docker одновременно на один хост, и, как уверяют разработчики, они прекрасно будут работать вместе. Containerd, как среда запуска контенеров для kubernetes, а docker — просто как docker )))
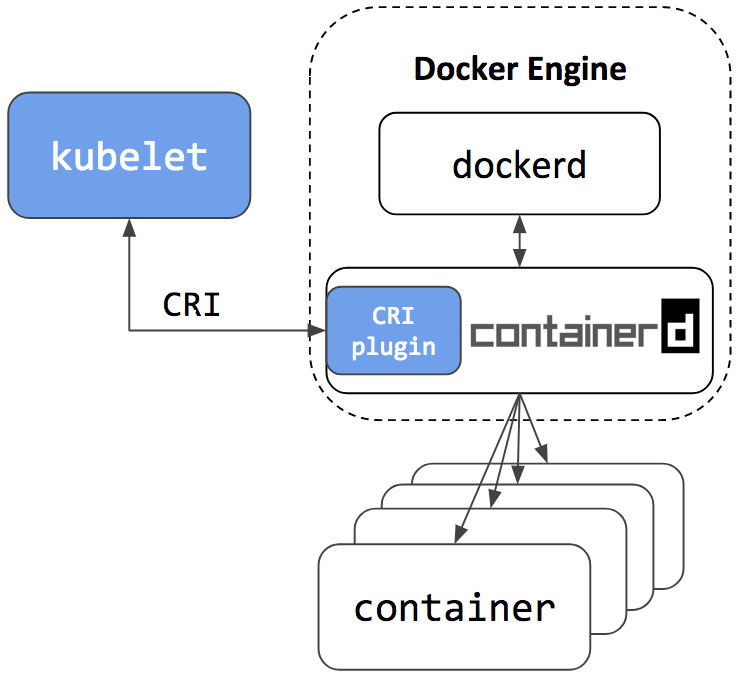
В репозитории containerd есть ansible playbook для установки кластера с одним мастером. Но мне было интереснее "поднять" систему руками, чтобы более детально разобраться в настройке каждого компонента и понять, как это работает на практике.
Возможно, когда нибудь дойдут руки, и я напишу свой playbook для разворачивания кластера c HA, так как за последние пол года я развернул их уже больше десятка и пора бы, наверно, автоматизировать процесс.
Также во время написания статьи вышла версия kubernetes 1.11. Об основных изменениях можно почитать в блоге Флант или в официальном блоге kubernetes. Мы обновили тестовые кластеры до версии 1.11 и заменили kube-dns на CoreDNS. Дополнительно включили функцию DynamicKubeletConfig для тестирования возможностей динамического обновления конфигов.
Используемые материалы:
- Kubernetes Containerd Integration Goes GA
- Интеграция containerd с Kubernetes, заменяющая Docker, готова к production
- containerd github
- Kubernetes Documentation
- Документанция NGINX
Спасибо, что дочитали до конца.
Так как информации по kubernetes, особенно по кластерам работающим в реальных условиях, в рунете очень мало, то указания на неточности приветствуются, как и замечания по общей схеме развертывания кластера. Постараюсь их учесть и сделать соответствующие исправления. И я всегда готов ответить на вопросы в комментариях, на githab и в любых соцсетях указанных в моем профиле.
С уважением Евгений.

