Предисловие
На просторах интернета имеется множество туториалов объясняющих принцип работы LDA(Latent Dirichlet Allocation — Латентное размещение Дирихле) и то, как применять его на практике. Примеры обучения LDA часто демонстрируются на "образцовых" датасетах, например "20 newsgroups dataset", который есть в sklearn.
Особенностью обучения на примере "образцовых" датасетов является то, что данные там всегда в порядке и удобно сложены в одном месте. При обучении продакшн моделей, на данных, полученных прямиком из реальных источников все обычно наоборот:
- Много выбросов.
- Неправильная разметка(если она есть).
- Очень сильные дисбалансы классов и 'некрасивые' распределения каких-либо параметров датасета.
- Для текстов, это: грамматические ошибки, огромное кол-во редких и уникальных слов, многоязычность.
- Неудобный способ харнения данных(разные или редкие форматы, необходимость парсинга)
Исторически, я стараюсь учиться на примерах, максимально приближенных к реалиям продакшн-действительности потому, что именно таким образом можно наиболее полно прочувстовать проблемные места конкретного типа задач. Так было и с LDA и в этой статье я хочу поделиться своим опытом — как запускать LDA с нуля, на совершенно сырых данных. Некоторая часть статьи будет посвящена получению этих самых данных, для того, чтобы пример обрел вид полноценного 'инженерного кейса'.
Topic modeling и LDA.
Для начала, рассмотрим, что вообще делает LDA и в каких задачах используется.
Наиболее часто LDA применяется для Topic Modeling(Тематическое моделирование) задач. Под такими задачами подразумеваются задачи кластеризации или классификации текстов — таким образом, что каждый класс или кластер содержит в себе тексты со схожими темами.
Для того, чтобы применять к датасету текстов(далее корпус текстов) LDA, необходимо преобразовать корпус в term-document matrix(Терм-документная матрица).
Терм-документная матрица — это матрица которая имеер размер  , где
, где
N — количество документов в корпусе, а W — размер словаря корпуса т.е. количество слов(уникальных) которые встречаются в нашем корпусе. В i-й строке, j-м столбце матрицы находится число — сколько раз в i-м тексте встретилось j-е слово.
LDA строит, для данной Терм-документной матрицы и T заранее заданого числа тем — два распределения:
- Распределение тем по текстам.(на практике задается матрицей размера
 )
) - Распределение слов по темам.(матрица размера
 )
)
Значения ячеек данных матриц — это соответственно вероятности того, что данная тема содержится в данном документе(или доля темы в документе, если рассматривать документ как смесь разных тем) для матрицы 'Распределение тем по текстам'.
Для матрицы 'Распределение слов по темам' значения — это соотв-но вероятность встретить в тексте с темой i слово j, качествено, можно рассматривать эти числа как коэффициенты характеризующие, то насколько данное слово характерно для данной темы.
Следует сказать, что под словом тема понимается не 'житейское' определение этого слова. LDA выделяет T тем, но что это за темы и соответствуют ли они каким-либо известным темам текстов, как например: 'Спорт', 'Наука', 'Политика' — неизвестно. В данном случае, уместно скорее говорить о теме, как о некой абстрактной сущности, которая задается строкой в матрице распределения слов по темам и с некоторой вероятностью соответствует данному тексту, если угодно можно представить ее, как семейство характерных наборов слов встречающихся вместе, с соответствующими вероятностями(из таблицы) в некотором определенном множестве текстов.
Если вам интересно более подробно и 'в формулах' изучить как именно обучается и работает LDA, то вот некоторые материалы(которые использовались автором):
- Оригинальная статья
- На английском, с наглядными примерами
- Подробно на русском
- О реализации на Python
Добываем дикие данные
Для нашей 'лабораторной работы', нам понадобится кастомный датасет со своими недостатками и особенностями. Добыть его можно в разных местах: выкачать отзывы с Кинопоиска, статьи из Википедии, новости с какого-нибудь новостного портала, мы возьмем чуть более экстремальный вариант — посты из сообществ ВКонтакте.
Делать это мы будем так:
- Выбираем некоторого пользователя ВК.
- Получаем список всех его друзей.
- Для каждого друга берем все его сообщества.
- Для каждого сообщества каждого друга выкачиваем первые n(n=100)постов сообщества и объединяем в один текст-контент сообщества.
Инструменты и статьи
Для выкачивания постов будем использовать модуль vk для работы с API ВКонтакте, для Python. Один из наиболее замысловатых моментов при написании приложения с использованием API ВКонтакте — это авторизация, к счастью, код выполняющий эту работу уже написан и есть в открытом доступе, кроме vk я использовал небольшой модуль для авторизации — vkauth.
Ссылки на используемые модули и статьи для изучения API ВКонтакте:
- vkauth
- vkauth туториал
- vk туториал
- vk туториал №2
- Официальная документация API ВКонтакте
Пишем код
И так, с помощью vkauth, авторизируемся:
#authorization of app using modules imported. app_id = '6203169' perms = ['photos','friends','groups'] API_ver = '5.68' Auth = VKAuth(perms, app_id, API_ver) Auth.auth() token = Auth.get_token() user_id = Auth.get_user_id() #starting session session = vk.Session(access_token=token) api = vk.API(session)
В процессе, был написан небольшой модуль содержащий все необходимые для выгрузки контента в соответствующем формате функции, ниже они преведены, давайте пройдемся по ним:
def get_friends_ids(api, user_id): ''' For a given API object and user_id returns a list of all his friends ids. ''' friends = api.friends.get(user_id=user_id, v = '5.68') friends_ids = friends['items'] return friends_ids def get_user_groups(api, user_id, moder=True, only_open=True): ''' For a given API user_id returns list of all groups he subscribed to. Flag model to get only those groups where user is a moderator or an admin) Flag only_open to get only public(open) groups. ''' kwargs = {'user_id' : user_id, 'v' : '5.68' } if moder == True: kwargs['filter'] = 'moder' if only_open == True: kwargs['extended'] = 1 kwargs['fields'] = ['is_closed'] groups = api.groups.get(**kwargs) groups_refined = [] for group in groups['items']: cond_check = (only_open and group['is_closed'] == 0) or not only_open if cond_check: refined = {} refined['id'] = group['id'] * (-1) refined['name'] = group['name'] groups_refined.append(refined) return groups_refined def get_n_posts_text(api, group_id, n_posts=50): ''' For a given api and group_id returns first n_posts concatenated as one text. ''' wall_contents = api.wall.get(owner_id = group_id, count=n_posts, v = '5.68') wall_contents = wall_contents['items'] text = '' for post in wall_contents: text += post['text'] + ' ' return text
Итоговый пайплайн имеет следующий вид:
#id of user whose friends you gonna get, like: https://vk.com/id111111111 user_id = 111111111 friends_ids = vt.get_friends_ids(api, user_id) #collecting all groups groups = [] for i,friend in tqdm(enumerate(friends_ids)): if i % 3 == 0: sleep(1) friend_groups = vt.get_user_groups(api, friend, moder=False) groups += friend_groups #converting groups to dataFrame groups_df = pd.DataFrame(groups) groups_df.drop_duplicates(inplace=True) #reading content(content == first 100 posts) for i,group in tqdm(groups_df.iterrows()): name = group['name'] group_id = group['id'] #Different kinds of fails occures during scrapping #For examples there are names of groups with slashes #Like: 'The Kaaats / Indie-rock' try: content = vt.get_n_posts_text(api, group_id, n_posts=100) dst_path = join(data_path, name + '.txt') with open(dst_path, 'w+t') as f: f.write(content) except Exception as e: print('Error occured on group:', name) print(e) continue #need it because of requests limitaion in VK API. if i % 3 == 0: sleep(1)
Fails
В целом, сама по себе процедура выкачивания данных не представляет собой ничего трудного, обратить внимание следует лишь на два момента:
- Иногда, в силу приватности некоторых сообществ вы будете получать ошибки доступа, иногда другие ошибки — решается установкой try,except в правильном месте.
- У ВК есть ограничение на количество запросов в секунду.
При совершении большого количества запросов, например в цикле, мы так же будем ловить ошибки. Эту проблему можно решить несколькими способами:
- Тупо и прямо: Воткнуть sleep(some) каждые 3 запроса. Делается в одну строчку и сильно замедляет выгрузку, в ситуациях, когда объемы данных не велики, а на более изощренные методы нет времени — вполне приемлимо.(Реализовано в данной статье)
- Разобраться в работе Long Poll запросов https://vk.com/dev/using_longpoll
В данной работе был выбран простой и медленный способ, в дальнейшем, я возможно напишу микростатью про способы обхода или ослабления ограничений на количество запросов в секунду.
Итог
С затравочным 'некоторым' пользователем имеющим ~150 друзей, удалось добыть 4679 текстов — каждый характеризует некоторое сообщество ВК. Тексты сильно варьируются по размеру и написаны на многих языках — часть из них не пригодна для наших целей, но об этом мы поговорим чуть дальше.
Основная часть
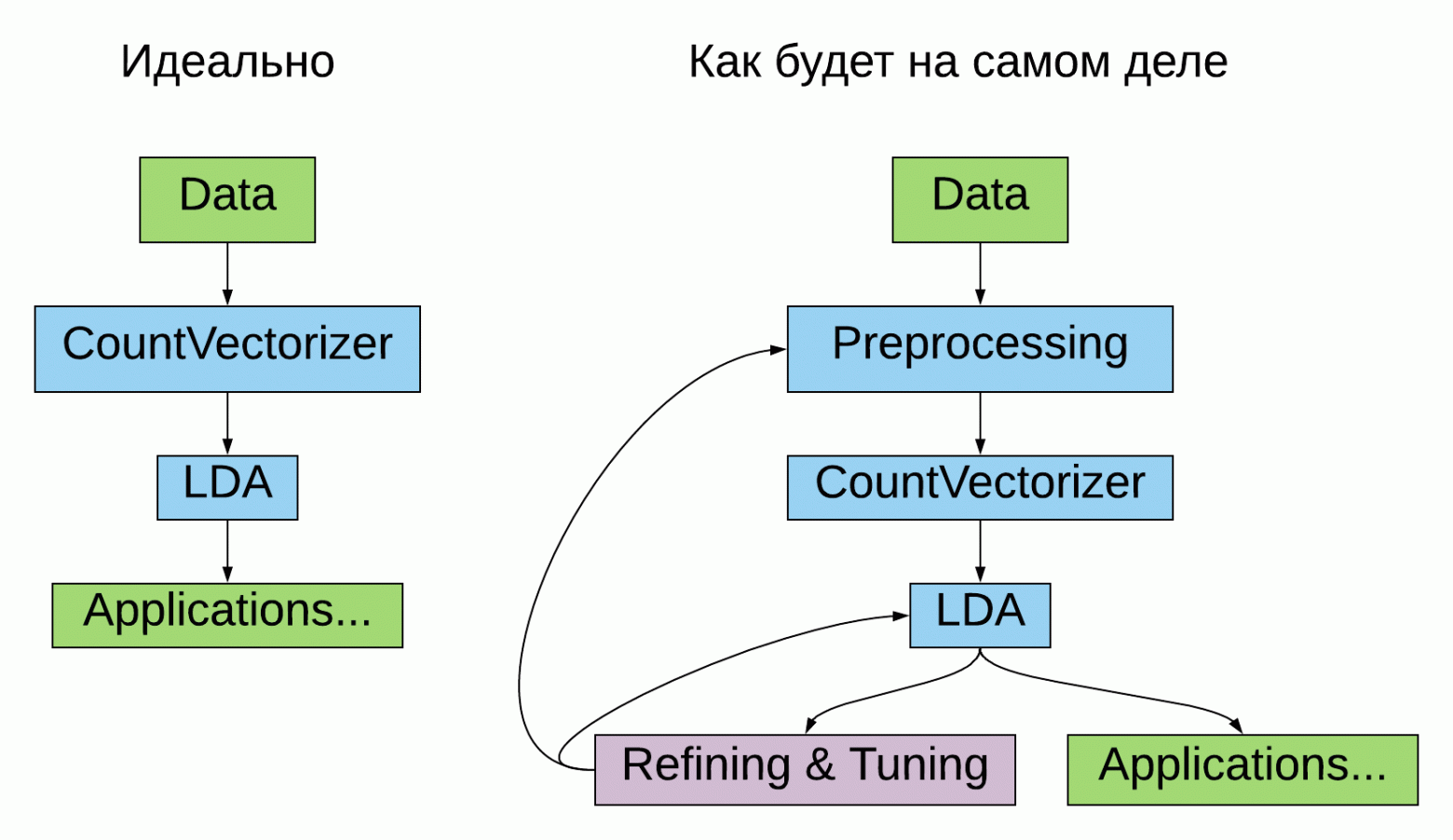
Пройдемся по всем блокам нашего пайплайна — сначала, по обязательным(Идеально), затем по остальным — они, как раз и представляют наибольший интерес.
CountVectorizer
Перед тем, как учить LDA, нам необходимо представить наши документы в виде Терм-документной матрицы. Это обычно включает в себя такие операции как:
- Удаление путктуации/чисел/ненужных лексем.
- Токенизация(представление в виде списка слов)
- Подсчет слов, составление терм-документной матрицы.
Все эти действия в sklearn удобно реализованы в рамках одной программной сущности — sklearn.feature_extraction.text.CountVectorizer.
Все, что нужно сделать это:
count_vect = CountVectorizer(input='filename', stop_words=stopwords, vocabulary=voc) dataset = count_vect.fit_transform(train_names)
LDA
Аналогично с CountVectorizer`ом, LDA, прекрасно реализовано в Sklearn и других фреймворках, поэтмому уделять непосредственно их реализациям много места, в нашей, сугубо практической статье нет особого смысла.
Все, что нужно, чтобы запустить LDA это:
#training LDA lda = LDA(n_components = 60, max_iter=30, n_jobs=6, learning_method='batch', verbose=1) lda.fit(dataset)
Preprocessing
Если мы просто возьмем наши тексты сразу после того как скачали их и конвертируем в Терм-документную матрицу с помощью CountVectorizer, со встроеным дефолтным токенайзером, мы получим матрицу размера 4679x769801(на используемых мной данных).
Размер нашего словаря будет составлять 769801. Даже если допустить, что большая часть слов информативны, то мы все равно вряд ли получим хороший LDA, нас ждет что-то вроде 'Проклятия размерностей', не говоря уже о том, что практически для любого компьютера, мы просто забьем всю оперативную память. На деле, большя часть этих слов совершенно не информативны. Огромная часть из них это:
- Смайлы, символы, числа.
- Уникальные или очень редкие слова(например польские слова из группы с польскими мемами, слова написаные с ошибками или на 'олбанском').
- Очень частые части речи(например, предлоги и местоимения).
Кроме того, многие группы в ВК специализируются исключительно на изображениях — там почти нет текстовых постов — тексты соответствующие им вырождены, в Терм-документной матрице они будут давать нам практически полностью нулевые строки.
И так, давайте же отсортируем это все!
Токенизируем все тексты, уберем из них пунктуацию и числа, посмотрим на гистограмму распределения текстов по количеству слов:
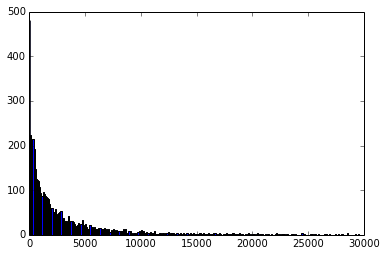
Уберем все тексты размером меньше 100 слов(их 525)
Теперь словарь:
Удаление всех лексем(слова) состоящих не из букв, в рамках нашей задачи — это вполне допустимо. CountVectorizer делает это сам, даже если нет, то думаю здесь не нужно приводить примеров(они есть в полной версии кода к статье).
Одной из наиболее распространенных процедур по уменьшению размера словаря является удаление так называемых stopwords(стопворды) — слов не несущих смысловой нагрузки или/и не имеющих тематической окрашенности(в нашем случае — Topic Modeling же). Такими словами в нашем случае являются, например:
- Местоимения и предлоги.
- Артикли — the,a.
- Общеупотребительные слова: 'быть', 'хорошо', 'наверное' и.т.д...
В модуле nltk есть сформированные списки стопвордов на русском и на английском, но они слабоваты. В интернете можно найти еще списки стопвордов для любого языка и добавить их к тем, что есть в nltk. Так мы и сделаем. Возьмем дополнительно стопворды отсюда:
- https://github.com/stopwords-iso/stopwords-ru/blob/master/stopwords-ru.json
- https://gist.github.com/menzenski/7047705
На практике, при решении конкретных задач списки стопвордов постепенно корректируются и дополняются по мере обучения моделей, так как для каждого конкретного датасета и задачи существуют свои конкретные 'несодержательные' слова. Мы тоже подберем себе кастомных стопвордов после обучения нашего LDA 'первого поколения'.
Сама по себе процедура удаления стопвордов встроена в CountVectorizer — нам только нужен их список.
Достаточно ли того, что мы сделали?

Большинство слов которые находятся в нашем словаре по-прежнему не слишком информативны для обучения на них LDA и не находятся в списке стопвордов. Поэтому применим к нашим данным еще один способ фильтрации.

, где
t — слово из словаря.
D — корпус(множество текстов)
d — один из текстов корпуса.
Посчитаем IDF всех наших слов, и отсечем слова с самым большим idf(очень редкие) и с самым маленьким(широкораспространенные слова).
#'training' (tf-)idf vectorizer. tf_idf = TfidfVectorizer(input='filename', stop_words=stopwords, smooth_idf=False ) tf_idf.fit(train_names) #getting idfs idfs = tf_idf.idf_ #sorting out too rare and too common words lower_thresh = 3. upper_thresh = 6. not_often = idfs > lower_thresh not_rare = idfs < upper_thresh mask = not_often * not_rare good_words = np.array(tf_idf.get_feature_names())[mask] #deleting punctuation as well. cleaned = [] for word in good_words: word = re.sub("^(\d+\w*$|_+)", "", word) if len(word) == 0: continue cleaned.append(word)
Полученный после вышеописанных процедур уже вполне пригоден для обучения LDA, но произведем еще стемминг — в нашем датасете часто встречаются одни и те же слова, но в разных падежах. Для стемминга использовался pymystem3.
#Stemming m = Mystem() stemmed = set() voc_len = len(cleaned) for i in tqdm(range(voc_len)): word = cleaned.pop() stemmed_word = m.lemmatize(word)[0] stemmed.add(stemmed_word) stemmed = list(stemmed) print('After stemming: %d'%(len(stemmed)))
После применения вышеописанных фильтраций размер словаря уменьшился с 769801 до
13611 и уже с такими данными, можно получить LDA модель приемлимого качества.
Тестирование, применение и тюнинг LDA
Теперь, когда у нас есть датасет, препроцессинг и модели которые мы обучили на обработаном датасете, хорошо было бы проверить адекватность наших моделей, а так же соорудить для них какие-нибудь приложения.
В качестве приложения, для начала рассмотрим задачу генерации ключевых слов для данного текста. Сделать это в достаточно простом варианте можно следующим образом:
- Получаем из LDA распределение тем для данного текста.
- Выбираем n(например n=2) наиболее выраженных темы.
- Для каждой из тем, выбираем m(например m=3) наиболее характерных слова.
- У нас есть набор из n*m слов характеризующих данный текст.
Напишем простой класс-интерфейс который и будет реализовывать данный способ генерации ключевых слов:
#Let\`s do simple interface class class TopicModeler(object): ''' Inteface object for CountVectorizer + LDA simple usage. ''' def __init__(self, count_vect, lda): ''' Args: count_vect - CountVectorizer object from sklearn. lda - LDA object from sklearn. ''' self.lda = lda self.count_vect = count_vect self.count_vect.input = 'content' def __call__(self, text): ''' Gives topics distribution for a given text Args: text - raw text via python string. returns: numpy array - topics distribution for a given text. ''' vectorized = self.count_vect.transform([text]) lda_topics = self.lda.transform(vectorized) return lda_topics def get_keywords(self, text, n_topics=3, n_keywords=5): ''' For a given text gives n top keywords for each of m top texts topics. Args: text - raw text via python string. n_topics - int how many top topics to use. n_keywords - how many top words of each topic to return. returns: list - of m*n keywords for a given text. ''' lda_topics = self(text) lda_topics = np.squeeze(lda_topics, axis=0) n_topics_indices = lda_topics.argsort()[-n_topics:][::-1] top_topics_words_dists = [] for i in n_topics_indices: top_topics_words_dists.append(self.lda.components_[i]) shape=(n_keywords*n_topics, self.lda.components_.shape[1]) keywords = np.zeros(shape=shape) for i,topic in enumerate(top_topics_words_dists): n_keywords_indices = topic.argsort()[-n_keywords:][::-1] for k,j in enumerate(n_keywords_indices): keywords[i * n_keywords + k, j] = 1 keywords = self.count_vect.inverse_transform(keywords) keywords = [keyword[0] for keyword in keywords] return keywords
Применим наш метод к нескольким текстам и посмотрим что получается:
Cообщество: Агентство путешествий "Краски Мира"
Ключевые слова: ['photo', 'social', 'travel', 'сообщество', 'путешествие', 'евро', 'проживание', 'цена', 'польша', 'вылет']
Cообщество: Food Gifs
Ключевые слова: ['масло', 'ст', 'соль', 'шт', 'тесто', 'приготовление', 'лук', 'перец', 'сахар', 'гр']
Результаты выше не 'cherry pick' и выглядят вполне адекватно. На деле, это результаты из уже настроенной модели. Первые LDA, которые были обучены в рамках этой статьи выдавали существенно более плохие результаты, среди ключевых слов можно было часто увидеть, например:
- Составные компоненты веб адресов: www, http, ru, com...
- Общеупотребительные слова.
- единицы измерения: cm, метр, км...
Настройка(тюнинг) модели производился следующим образом:
- Для каждой темы, выбираем n(n=5) наиболее характерных слов.
- Считаем их idf, по тренеровочному корпусу.
- Вносим в ключевые слова 5-10% наиболее широкораспространенных.
Подобную 'чистку', следует проводить аккуратно, предварительно просматривая, те самые 10% слов. Скорее, так следует выбирать кандидатов на удаление, а после уже в ручную отбирать из них слова которые следует удалить.
Где-то на 2-3 поколении моделей, с подобным способом отбора стопвордов, для топ-5% широкораспространенных топ-слов распределений мы получаем:
['любой', 'полностью', 'правильно', 'легко', 'следующий', 'интернет', 'небольшой', 'способ', 'сложно', 'настроение', 'столько', 'набор', 'вариант', 'название', 'речь', 'программа', 'конкурс', 'музыка', 'цель', 'фильм', 'цена', 'игра', 'система', 'играть', 'компания', 'приятно']
Еще приложения
Первое, что приходит в голову конкретно мне — это использовать распределения тем в тексте как 'эмбеддинги' текстов, в такой интерпретации можно применять к ним алгоритмы визуализации или кластеризации, и искать уже итоговые 'эффективные ' тематические кластеры таким образом.
Проделаем это:
term_doc_matrix = count_vect.transform(names) embeddings = lda.transform(term_doc_matrix) kmeans = KMeans(n_clusters=30) clust_labels = kmeans.fit_predict(embeddings) clust_centers = kmeans.cluster_centers_ embeddings_to_tsne = np.concatenate((embeddings,clust_centers), axis=0) tSNE = TSNE(n_components=2, perplexity=15) tsne_embeddings = tSNE.fit_transform(embeddings_to_tsne) tsne_embeddings, centroids_embeddings = np.split(tsne_embeddings, [len(clust_labels)], axis=0)
На выходе, мы получим следующего вида картинку:
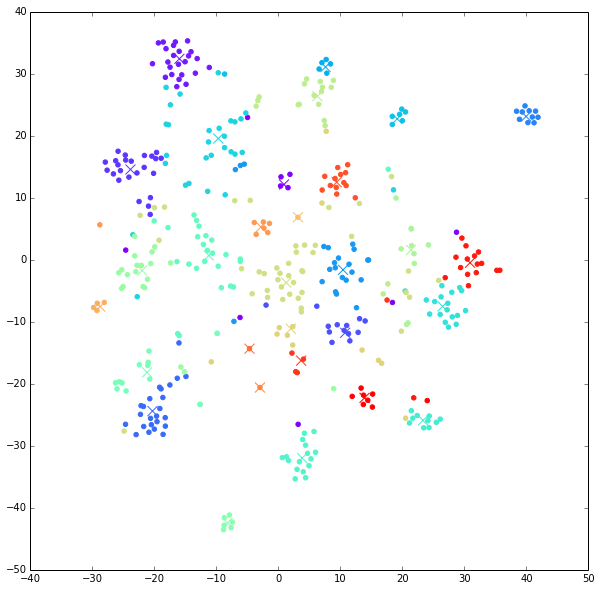
Крестики — это центры тяжести(cenroids) кластеров.
На изображении tSNE ембеддингов, видно, что кластеры выделенные с помощью KMeans, образуют достаточно связные и чаще всего пространственно разделимые между собой множества.
Все остальное, up to you.
Ссылка на весь код: https://gitlab.com/Mozes/VK_LDA

