
На прошлой неделе мы рассказали про свой небольшой демо-проект Shrimp, который наглядно показывает, как можно использовать C++ные библиотеки RESTinio и SObjectizer в более-менее похожих на реальность условиях. Shrimp — это маленькое приложение на C++17, которое посредством RESTinio принимает HTTP-запросы на масштабирование изображений и обслуживает эти запросы в многопоточном режиме посредством SObjectizer-а и ImageMagick++.
Проект оказался более чем полезным для нас самих. Копилка хотелок для расширения функциональности RESTinio и SObjectizer заметно пополнилась. Кое что уже даже нашло свое воплощение в совсем свежей версии RESTinio-0.4.7. Так что мы решили не останавливаться на самой первой и самой тривиальной версии Shrimp-а, а сделать еще одну-две итераций вокруг этого проекта. Если кому-то интересно что и как мы сделали за это время, милости просим под кат.
В качестве спойлера: речь пойдет о том, как мы избавились от параллельной обработки идентичных запросов, как добавили в Shrimp логирование с помощью отличной библиотеки spdlog, а также сделали команду принудительного сброса кэша трансформированных картинок.
v0.3: контроль параллельной обработки идентичных запросов
Самая первая версия Shrimp-а, описанная в предыдущей статье, содержала серьезное упрощение: не было контроля за тем, обрабатывается ли в данный момент такой же запрос или нет.
Представьте себе, что Shrimp впервые получает запрос вида "/demo.jpg?op=resize&max=1024". Такой картинки в кэше трансформированных изображений еще нет, поэтому запрос идет на обработку. Обработка может занять значительное время, скажем, несколько сотен миллисекунд.
Обработка запроса еще не завершилась, а Shrimp вновь получает такой же запрос "/demo.jpg?op=resize&max=1024", но уже от другого клиента. Результата трансформации в кэше еще нет, поэтому и этот запрос пойдет на обработку.
Ни первый, ни второй запросы еще не завершились, а Shrimp вновь может получить такой же запрос "/demo.jpg?op=resize&max=1024". И этот запрос также пойдет на обработку. Получится, что одна и та же картинка масштабируется к одному и тому же размеру параллельно несколько раз.
Это не есть хорошо. Поэтому первым делом мы решили в Shrimp-е от такого серьезного косяка избавиться. Сделали мы это за счет двух хитрых контейнеров в агенте transform_manager. Первый контейнер является очередью ждущих свободных transformer-ов запросов. Это контейнер с именем m_pending_requests. Второй контейнер хранит запросы, которые уже пошли в обработку (т.е. этим запросам были выделены конкретные transformer-ы). Это контейнер с именем m_inprogress_requests.
Когда transform_manager получает очередной запрос, он проверяет наличие готовой картинки в кэше трансформированных изображений. Если преобразованной картинки нет, то проверяются контейнеры m_inprogress_requests и m_pending_requests. И если запроса с такими параметрами ни в одном из этих контейнеров нет, только тогда делается попытка поставить запрос в очередь m_pending_requests. Выглядит это приблизительно следующим образом:
void a_transform_manager_t::handle_not_transformed_image( transform::resize_request_key_t request_key, sobj_shptr_t<resize_request_t> cmd ) { const auto store_to = [&](auto & queue) { queue.insert( std::move(request_key), std::move(cmd) ); }; if( m_inprogress_requests.has_key( request_key ) ) { // Подобный запрос уже обрабатывается. // Добавляем новый запрос к списку обрабатываемых в данный момент. store_to( m_inprogress_requests ); } else if( m_pending_requests.has_key( request_key ) ) { // Подобный запрос уже ждет своей очереди. store_to( m_pending_requests ); } else if( m_pending_requests.unique_keys() < max_pending_requests ) { // Это еще неизвестный запрос и у нас есть возможность его сохранить. store_to( m_pending_requests ); // При наличии свободных transformer-ов запрос можно отправить на обработку. try_initiate_pending_requests_processing(); } else { // Мы перегружены, от обработки отказываемся. do_503_response( std::move(cmd->m_http_req) ); } }
Выше было сказано, что m_inprogress_requests и m_pending_requests — это хитрые контейнеры. Но в чем же хитрость?
Хитрость в том, что эти контейнеры сочетают в себе свойства как обычной FIFO-очереди (в которой сохраняется хронологический порядок добавления элементов), так и multimap-а, т.е. ассоциативного контейнера, в котором одному ключу может быть сопоставлено несколько значений.
Сохранение хронологического порядка важно, поскольку самые старые элементы в m_pending_requests нужно периодически проверять и изымать из m_pending_requests те запросы, для которых превышено максимальное время ожидания. А эффективный доступ к элементам по ключу нужен как для проверки наличия идентичных запросов в очередях, так и для того, чтобы из очереди можно было изъять за один раз все дублирующиеся запросы.
В Shrimp-е мы навелосипедили свой небольшой контейнер для этих целей. Хотя, если бы в Shrimp-е использовался Boost, то можно было бы воспользоваться Boost.MultiIndex. И, вероятно, если со временем эффективный поиск в m_pending_requests нужно будет организовать еще по каким-то критериям, то Boost.MultiIndex в Shrimp-е придется задействовать.
v0.4: логирование с помощью spdlog
Первую версию Shrimp-а мы стремились оставить максимально простой и компактной. Из-за чего в первой версии Shrimp-а мы не стали использовать логирование. Вообще.
С одной стороны, это позволило сохранить код первой версии лаконичным, не содержащим ничего, кроме нужной Shrimp-у бизнес-логики. Но, с другой стороны, отсутствие логирования затрудняет и разработку Shrimp-а, и его эксплуатацию. Поэтому, как только дошли руки, мы сразу же подтащили в Shrimp отличную современную C++ную библиотеку для логирования — spdlog. Дышать сразу стало легче, хотя код некоторых методов вырос в объеме.
Например, показанный выше код метода handle_not_transformed_image() с логированием начинает выглядеть приблизительно так:
void a_transform_manager_t::handle_not_transformed_image( transform::resize_request_key_t request_key, sobj_shptr_t<resize_request_t> cmd ) { const auto store_to = [&](auto & queue) { queue.insert( std::move(request_key), std::move(cmd) ); }; if( m_inprogress_requests.has_key( request_key ) ) { // Подобный запрос уже обрабатывается. m_logger->debug( "same request is already in progress; request_key={}", request_key ); // Добавляем новый запрос к списку обрабатываемых в данный момент. store_to( m_inprogress_requests ); } else if( m_pending_requests.has_key( request_key ) ) { // Подобный запрос уже ждет своей очереди. m_logger->debug( "same request is already pending; request_key={}", request_key ); store_to( m_pending_requests ); } else if( m_pending_requests.unique_keys() < max_pending_requests ) { // Это еще неизвестный запрос и у нас есть возможность его сохранить. m_logger->debug( "store request to pending requests queue; request_key={}", request_key ); store_to( m_pending_requests ); // При наличии свободных transformer-ов запрос можно отправить на обработку. try_initiate_pending_requests_processing(); } else { // Мы перегружены, от обработки отказываемся. m_logger->warn( "request is rejected because of overloading; " "request_key={}", request_key ); do_503_response( std::move(cmd->m_http_req) ); } }
Настройка логеров spdlog
Логирование в Shrimp-е производится на консоль (т.е. в стандартный поток вывода). В принципе, можно было бы пойти по совсем простому пути и создать в Shrimp-е единственный экземпляр spd-шного логера. Т.е. можно было бы вызвать stdout_color_mt (или stdout_logger_mt), а затем передать этот логер всем сущностям в Shrimp-е. Но мы пошли чуть более сложным путем: мы вручную создали т.н. sink (т.е. канал, куда spdlog будет выводить сформированные сообщения), а для сущностей Shrimp-а создавали отдельные логеры, привязанные к этому sink-у.
// Вспомогательные функции для создания логеров. [[nodiscard]] spdlog::sink_ptr make_logger_sink() { auto sink = std::make_shared< spdlog::sinks::ansicolor_stdout_sink_mt >(); return sink; } [[nodiscard]] std::shared_ptr<spdlog::logger> make_logger( const std::string & name, spdlog::sink_ptr sink, spdlog::level::level_enum level = spdlog::level::trace ) { auto logger = std::make_shared< spdlog::logger >( name, std::move(sink) ); logger->set_level( level ); logger->flush_on( level ); return logger; } // Пример создания отдельных логеров для каждого из агентов: auto manager = coop.make_agent_with_binder< a_transform_manager_t >( create_one_thread_disp( "manager" )->binder(), make_logger( "manager", logger_sink ) ); ... const auto worker_name = fmt::format( "worker_{}", worker ); auto transformer = coop.make_agent_with_binder< a_transformer_t >( create_one_thread_disp( worker_name )->binder(), make_logger( worker_name, logger_sink ), app_params.m_storage );
С настройкой логеров в spdlog есть тонкий момент: по умолчанию логер игнорирует сообщения с уровнями важности trace и debug. А именно они оказываются максимально полезными при отладке. Поэтому в make_logger мы по умолчанию активируем логирование для всех уровней, в том числе и для trace/debug.
Благодаря тому, что для каждой сущности в Shrimp-е есть свой логер со своим именем, мы можем видеть в логе кто и что делает:
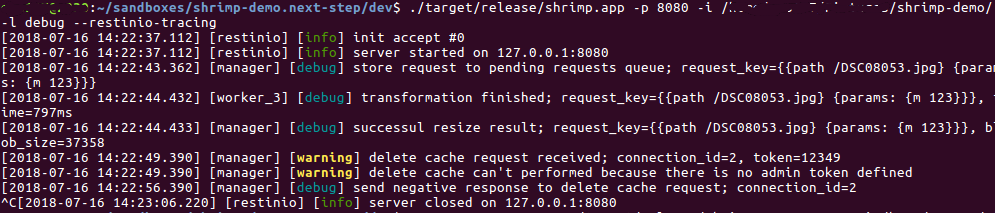
Трассировка SObjectizer-а посредством spdlog
Временами логирования, которое выполняется в рамках основной бизнес-логики SObjectizer-приложения, недостаточно для отладки приложения. Бывает непонятно, почему какое-то действие инициируется в одном агенте, но не выполняется реально в другом агенте. В этом случае сильно помогает встроенный в SObjectizer механизм msg_tracing (о котором мы рассказывали в отдельной статье). Но среди штатных реализаций msg_tracing-а для SObjectizer нет такой, которая бы использовала spdlog. Эту реализацию для Shrimp-а мы сделаем сами:
class spdlog_sobj_tracer_t : public so_5::msg_tracing::tracer_t { std::shared_ptr<spdlog::logger> m_logger; public: spdlog_sobj_tracer_t( std::shared_ptr<spdlog::logger> logger ) : m_logger{ std::move(logger) } {} virtual void trace( const std::string & what ) noexcept override { m_logger->trace( what ); } [[nodiscard]] static so_5::msg_tracing::tracer_unique_ptr_t make( spdlog::sink_ptr sink ) { return std::make_unique<spdlog_sobj_tracer_t>( make_logger( "sobjectizer", std::move(sink) ) ); } };
Здесь мы видим реализацию специального SObjectizer-овского интерфейса tracer_t, в которой главное — это виртуальный метод trace(). Именно он и выполняет трассировку внутренностей SObjectizer-а средствами spdlog.
Далее эта реализация устанавливается в качестве трейсера при запуске SObjectizer-а:
so_5::wrapped_env_t sobj{ [&]( so_5::environment_t & env ) {...}, [&]( so_5::environment_params_t & params ) { if( sobj_tracing_t::on == sobj_tracing ) params.message_delivery_tracer( spdlog_sobj_tracer_t::make( logger_sink ) ); } };
Трассировка RESTinio посредством spdlog
Помимо трассировки того, что происходит внутри SObjectizer-а, временами бывает очень полезно протрассировать и то, что происходит внутри RESTinio. В обновленной версии Shrimp-а такая трассировка так же добавлена.
Реализована эта трассировка через определение специального класса, который может выполнять логирование в RESTinio:
class http_server_logger_t { public: http_server_logger_t( std::shared_ptr<spdlog::logger> logger ) : m_logger{ std::move( logger ) } {} template< typename Builder > void trace( Builder && msg_builder ) { log_if_enabled( spdlog::level::trace, std::forward<Builder>(msg_builder) ); } template< typename Builder > void info( Builder && msg_builder ) { log_if_enabled( spdlog::level::info, std::forward<Builder>(msg_builder) ); } template< typename Builder > void warn( Builder && msg_builder ) { log_if_enabled( spdlog::level::warn, std::forward<Builder>(msg_builder) ); } template< typename Builder > void error( Builder && msg_builder ) { log_if_enabled( spdlog::level::err, std::forward<Builder>(msg_builder) ); } private: template< typename Builder > void log_if_enabled( spdlog::level::level_enum lv, Builder && msg_builder ) { if( m_logger->should_log(lv) ) { m_logger->log( lv, msg_builder() ); } } std::shared_ptr<spdlog::logger> m_logger; };
Этот класс ни от чего не наследуется, поскольку механизм логирования в RESTinio основан на обобщенном программировании, а не на традиционном объектно-ориентированном подходе. Что позволяет полностью избавиться от каких-либо накладных расходов в случаях, когда логирование вовсе не нужно (подробнее мы раскрывали эту тему, когда рассказывали о применении шаблонов в RESTinio).
Далее нам нужно указать, что HTTP-шный сервер будет использовать показанный выше класс http_server_logger_t в качестве своего логера. Это делается за счет уточнения свойств HTTP-сервера:
struct http_server_traits_t : public restinio::default_traits_t { using logger_t = http_server_logger_t; using request_handler_t = http_req_router_t; };
Ну а дальше остается всего ничего — создать конкретный экземпляр spd-шного логера и отдать этот логер в создаваемый HTTP-сервер:
auto restinio_logger = make_logger( "restinio", logger_sink, restinio_tracing_t::off == restinio_tracing ? spdlog::level::off : log_level ); restinio::run( asio_io_ctx, shrimp::make_http_server_settings( thread_count.m_io_threads, params, std::move(restinio_logger), manager_mbox_promise.get_future().get() ) );
v0.5: принудительный сброс кэша трансформированных картинок
В процессе отладки Shrimp-а обнаружилась одна небольшая штука, которая немного раздражала: для того, чтобы сбросить содержимое кэша трансформированных картинок приходилось перезапускать весь Shrimp. Казалось бы мелочь, а неприятно.
Раз неприятно, то следует от этого недостатка избавиться. Благо сделать это совсем не сложно.
Во-первых, мы определим еще один URL в Shrimp-е, на который можно присылать HTTP DELETE запросы: "/cache". Соответственно, повесим на этот URL свой обработчик:
std::unique_ptr< http_req_router_t > make_router( const app_params_t & params, so_5::mbox_t req_handler_mbox ) { auto router = std::make_unique< http_req_router_t >(); add_transform_op_handler( params, *router, req_handler_mbox ); add_delete_cache_handler( *router, req_handler_mbox ); return router; }
где функция add_delete_cache_handler() выглядит следующим образом:
void add_delete_cache_handler( http_req_router_t & router, so_5::mbox_t req_handler_mbox ) { router.http_delete( "/cache", [req_handler_mbox]( auto req, auto /*params*/ ) { const auto qp = restinio::parse_query( req->header().query() ); auto token = qp.get_param( "token"sv ); if( !token ) { return do_403_response( req, "No token provided\r\n" ); } // Delegate request processing to transform_manager. so_5::send< so_5::mutable_msg<a_transform_manager_t::delete_cache_request_t> >( req_handler_mbox, req, restinio::cast_to<std::string>(*token) ); return restinio::request_accepted(); } ); }
Немного многословно, но ничего сложного. В query string запроса должен быть параметр token. Этот параметр должен содержать строку со специальным значением административного токена. Сбросить кэш можно только если значение токена из параметра token совпадет с тем, что задано при запуске Shrimp-а. Если параметра token нет, то запрос к обработке не принимается. Если же token есть, то агенту transform_manager, который и владеет кэшем, отправляется специальное сообщение-команда, выполнив которую агент transform_manager сам ответит на HTTP-запрос.
Во-вторых, мы реализуем обработчик нового сообщения delete_cache_request_t в агенте transform_manager_t:
void a_transform_manager_t::on_delete_cache_request( mutable_mhood_t<delete_cache_request_t> cmd ) { m_logger->warn( "delete cache request received; " "connection_id={}, token={}", cmd->m_http_req->connection_id(), cmd->m_token ); const auto delay_response = [&]( std::string response_text ) { so_5::send_delayed< so_5::mutable_msg<negative_delete_cache_response_t> >( *this, std::chrono::seconds{7}, std::move(cmd->m_http_req), std::move(response_text) ); }; if( const char * env_token = std::getenv( "SHRIMP_ADMIN_TOKEN" ); // Token must be present and must not be empty. env_token && *env_token ) { if( cmd->m_token == env_token ) { m_transformed_cache.clear(); m_logger->info( "cache deleted" ); do_200_plaintext_response( std::move(cmd->m_http_req), "Cache deleted\r\n" ); } else { m_logger->error( "invalid token value for delete cache request; " "token={}", cmd->m_token ); delay_response( "Token value mismatch\r\n" ); } } else { m_logger->warn( "delete cache can't performed because there is no " "admin token defined" ); // Operation can't be performed because admin token is not avaliable. delay_response( "No admin token defined\r\n" ); } }
Здесь есть два момента, которые следует пояснить.
Первый момент в реализации on_delete_cache_request() — это сама проверка значения токена. Административный токен задается через переменную среды SHRIMP_ADMIN_TOKEN. Если эта переменная задана и ее значение совпадает со значением из параметра token запроса HTTP DELETE, то кэш очищается и сразу же формируется положительный ответ на запрос.
А второй момент в реализации on_delete_cache_request() — это принудительная задержка отрицательного ответа на HTTP DELETE. Если пришло неправильное значение административного токена, то следует задержать ответ на HTTP DELETE для того, чтобы не возникало желание подобрать значение токена перебором. Но как сделать эту задержку? Ведь вызвать std::thread::sleep_for() не вариант.
Тут нам на помощь приходят отложенные сообщения SObjectizer-а. Вместо того, чтобы сразу формировать отрицательный ответ внутри on_delete_cache_request(), агент transform_manager просто отсылает сам себе отложенное сообщение negative_delete_cache_response_t. Таймер SObjectizer-а отсчитает положенное время и доставит агенту это сообщение после истечения заданной задержки. И вот в обработчике negative_delete_cache_response_t уже можно будет сразу сформировать ответ на HTTP DELETE запрос:
void a_transform_manager_t::on_negative_delete_cache_response( mutable_mhood_t<negative_delete_cache_response_t> cmd ) { m_logger->debug( "send negative response to delete cache request; " "connection_id={}", cmd->m_http_req->connection_id() ); do_403_response( std::move(cmd->m_http_req), std::move(cmd->m_response_text) ); }
Т.е. получается следующий сценарий:
- HTTP-сервер получает HTTP DELETE запрос, преобразует этот запрос в сообщение delete_cache_request_t агенту transform_manager;
- агент transform_manager получает сообщение delete_cache_request_t и либо сразу формирует положительный ответ на запрос, либо отсылает себе отложенное сообщение negative_delete_cache_response_t;
- агент transform_manager получает сообщение negative_delete_cache_response_t и сразу же формирует отрицательный ответ на соответствующий HTTP DELETE запрос.
Конец второй части
В завершении второй части вполне естественно задаться вопросом: «Что дальше?»
Дальше, вероятно, будет еще одна итерация и еще одно обновление нашего демо-проекта. Хочется сделать такую штуку, как преобразование изображения из одного формата в другой. Скажем, на сервере картинка лежит в jpg, а клиенту после трансформации она отдается в webp.
Еще было бы интересно приделать отдельную «страничку» с отображением текущей статистики по работе Shrimp-а. Прежде всего это просто любопытно. Но, в принципе, такую страничку можно приспособить и для нужд мониторинга жизнеспособности Shrimp-а.
Если у кого-то есть еще пожелания на тему того, что хотелось бы увидеть в Shrimp-е или же в статьях вокруг Shrimp-а, то мы будем рады услышать любые конструктивные соображения.
Отдельно хочется отметить один аспект в реализации Shrimp-а, который нас несколько удивил. Это активное использование мутабельных сообщений при общении агентов друг с другом и HTTP-сервером. Обычно в нашей практике происходит наоборот — чаще обмен данными идет посредством иммутабельных сообщений. Здесь не так. Что говорит о том, что мы не зря в свое время прислушались к пожеланиям пользователей и добавили в SObjectizer мутабельные сообщения. Так что если вы хотели бы что-то увидеть в RESTinio или SObjectizer-е, то не стесняйтесь, делитесь своими идеями. К хорошим мы обязательно прислушиваемся.
Ну и совсем уж в заключение хочется поблагодарить всех, кто нашел время и высказался по поводу первой версии Shrimp-а, как здесь, на Хабре, так и через другие ресурсы. Спасибо!
Продолжение...

