
SQL, что может быть проще? Каждый из нас может написать простенький запрос — набираем select, перечисляем необходимые колонки, затем from, имя таблицы, немного условий в where и все — полезные данные у нас в кармане, причем (почти) независимо от того какая СУБД в это время находится под капотом (а может и не СУБД вовсе). В результате работу практически с любым источником данных (реляционным и не очень) можно рассматривать с точки зрения обычного кода (со всеми вытекающими — version control, code review, статический анализ, автотесты и вот это все). И это касается не только самих данных, схем и миграций, а вообще всей жизнедеятельности хранилища. В этой статье поговорим о повседневных задачах и проблемах работы с различными БД под прицелом "database as code".
И начнем прямо с ORM. Первые батлы вида "SQL vs ORM" были замечены еще в допетровской Руси.
Объектно-реляционный мапинг
Сторонники ORM традиционно ценят скорость и простоту разработки, независимость от СУБД и чистоту кода. Для многих из нас код работы с БД (а зачастую и сама БД)
@Entity @Table(name = "stock", catalog = "maindb", uniqueConstraints = { @UniqueConstraint(columnNames = "STOCK_NAME"), @UniqueConstraint(columnNames = "STOCK_CODE") }) public class Stock implements java.io.Serializable { @Id @GeneratedValue(strategy = IDENTITY) @Column(name = "STOCK_ID", unique = true, nullable = false) public Integer getStockId() { return this.stockId; } ...
Модель обвешена умными аннотациями, а где-то за кулисами доблестный ORM генерирует и выполняет тонны какого-то SQL-кода. К слову сказать, разработчики всеми силами пытаются отгородиться от своей БД километрами абстракций, что говорит о некоторой "SQL ненависти".
По другую сторону баррикад приверженцы чистого "handmade"-SQL отмечают возможность выжимать все соки из своей СУБД без дополнительных прослоек и абстракций. В результате чего появляются "data-centric" проекты, где базой занимаются специально обученные люди (они же "базисты", они же "базовики", они же "базденьщики" и т.д.), а разработчикам только остается "дергать" готовые вьюхи и хранимые процедурки, не вдаваясь в подробности.
А что если взять лучшее из двух миров? Как это сделано в замечательном инструменте с жизнеутверждающим названием Yesql. Приведу пару строк из общей концепции в моем вольном переводе, а более подробно с ней можно познакомиться здесь.
Clojure это крутой язык для создания DSL'ей, но SQL уже сам по себе является крутым DSL, и нам не нужен еще один. S-выражения прекрасны, но здесь они не добавляют ничего нового. В итоге получаем скобки ради скобок. Не согласны? Тогда дождитесь того момента когда абстракция над БД даст течь, и вы начнете борьбу с функцией (raw-sql)
И что делать? Давайте оставим SQL обычным SQL'ем — один файл на один запрос:
-- name: users-by-country select * from users where country_code = :country_code
… а затем прочитайте этот файл, превратив его в обычную Clojure функцию:
(defqueries "some/where/users_by_country.sql" {:connection db-spec}) ;;; A function with the name `users-by-country` has been created. ;;; Let's use it: (users-by-country {:country_code "GB"}) ;=> ({:name "Kris" :country_code "GB" ...} ...)
Придерживаясь принципа "SQL отдельно, Clojure отдельно", вы получаете:
- Никаких синтаксических сюрпризов. Ваша база данных (как и любая другая) не соответствует SQL стандарту на 100% — но для Yesql это не важно. Вы никогда не будете тратить время на охоту за функциями с синтаксисом эквивалентным SQL. Вам никогда не придется возвращаться к функции (raw-sql "some ('funky' :: SYNTAX)")).
- Лучшая поддержка редактора. Ваш редактор уже имеет отличную поддержку SQL. Сохраняя SQL как SQL, вы можете просто использовать его.
- Командная совместимость. Ваши DBA могут читать и писать SQL, который вы используете в своем Clojure проекте.
- Более простая настройка производительности. Нужно построить план для проблемного запроса? Это не проблема, когда ваш запрос является обычным SQL.
- Повторное использование запросов. Перетащите эти же SQL-файлы в другой проекты, потому что это просто старый добрый SQL — просто поделитесь им.
По моему идея очень крутая и при этом очень простая, благодаря чему проект обрел множество последователей на самых разных языках. А мы далее попробуем применить похожую философию отделения SQL-кода от всего остального далеко за пределами ORM.
IDE & DB-менеджеры
Начнем с простой повседневной задачи. Часто нам приходится искать какие-либо объекты в БД, например, найти таблицу в схеме и изучить ее структуру (какие используются колонки, ключи, индексы, констрейнты и прочее). И от любой графической IDE или маломальского DB-manager'а, в первую очередь, мы ждем именно этих способностей. Чтобы было быстро и не пришлось ждать по полчаса, пока нарисуется окошко с нужной информацией (особенно при медленном соединении с удаленной БД), и при этом чтобы полученная информация была свежей и актуальной, а не закешированное старье. Причем чем сложнее и крупнее БД и больше их количество, тем сложнее это сделать.
Но обычно я забрасываю мышь куда подальше и просто пишу код. Допустим, необходимо узнать, какие таблицы (и с какими свойствами) содержаться в схеме "HR". В большинстве СУБД нужного результата можно добиться вот таким нехитрым запросом из information_schema:
select table_name , ... from information_schema.tables where schema = 'HR'
От базы к базе содержимое таких таблиц-справочников варьируется в зависимости от способностей каждой СУБД. И, например, для MySQL из этого же справочника можно получить специфичные для этой СУБД параметры таблицы:
select table_name , storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc) , row_format -- Формат строки ("Fixed", "Dynamic" etc) , ... from information_schema.tables where schema = 'HR'
Oracle не умеет information_schema, зато у него есть Oracle metadata, и больших проблем не возникает:
select table_name , pct_free -- Минимум свободного места в блоке данных (%) , pct_used -- Минимум используемого места в блоке данных (%) , last_analyzed -- Дата последнего сбора статистики , ... from all_tables where owner = 'HR'
Не исключение и ClickHouse:
select name , engine -- Используемый "движок" ("MergeTree", "Dictionary" etc) , ... from system.tables where database = 'HR'
Что-то похожее можно сделать и в Cassandra (где есть columnfamilies вместо tables и keyspace'ы вместо схем):
select columnfamily_name , compaction_strategy_class -- Стратегия сборки мусора , gc_grace_seconds -- Время жизни мусора , ... from system.schema_columnfamilies where keyspace_name = 'HR'
Для большинства остальных БД также можно придумать похожие запросы (даже в Mongo есть специальная системная коллекция, которая содержит в себе информацию о всех коллекциях в системе).
Само собой, таким способом можно получить информацию не только о таблицах, а вообще о любом объекте. Периодически добрые люди делятся таким кодом для разных БД, как, например, в серии хабра-статей "Функции для документирования баз данных PostgreSQL" (айб, бен, гим). Само собой, держать всю эту гору запросов в голове и постоянно набирать их — это "такое себе" удовольствие, поэтому в любимой IDE/редакторе у меня есть заранее заготовленный набор сниппетов для часто используемых запросов, и остается только впечатать имена объектов в шаблон.
В итоге такой способ навигации и поиска объектов гораздо более гибок, экономит много времени, позволяет получить именно ту информацию и в том виде, в котором сейчас необходимо (как, например, описано в посте "Экспорт данных из БД в любом формате: что умеют IDE на платформе IntelliJ").
Операции с объектами
После того как мы нашли и изучили нужные объекты, самое время с ними сделать что-нибудь полезное. Естественно, также не отрывая пальцев от клавиатуры.
Не секрет, что простое удаление таблицы будет выглядеть одинаково почти во всех БД:
drop table hr.persons
А вот с созданием таблицы уже поинтереснее. Практически любая СУБД (в том числе и многие NoSQL) в том или ином виде умеет "create table", и основная его часть даже мало будет отличаться (имя, список колонок, типы данных), но остальные детали могут разительно отличаться и зависят от внутреннего устройства и возможностей конкретной СУБД. Мой любимый пример — в документации Oracle только одни "голые" БНФ'ы для синтаксиса "create table" занимают 31 страницу. Другие СУБД обладают более скромными возможностями, но каждая из них также обладает множеством интересных и уникальных фич по созданию таблиц (postgres, mysql, cockroach, cassandra). Вряд ли какой-нибудь графический "wizard" из очередной IDE (особенно универсальной) сможет полностью покрыть все эти способности, а если и сможет, то это будет зрелище не для слабонервных. В то же время правильно и вовремя написанный оператор create table позволит без труда воспользоваться всеми из них, сделать хранение и доступ к вашим данным надежным, оптимальным и максимально комфортным.
Также во многих СУБД есть свои специфичные типы объектов, которые отсутствуют в других СУБД. Причем мы можем выполнять операции не только над объектами БД, но и над самой СУБД, например "убить" процесс, освободить какую-либо область памяти, включить трассировку, перейти в режим "read only" и многое другое.
А теперь немного порисуем
Одна из самых распространенных задач — построить диаграмму с объектами БД, на красивой картинке увидеть объекты и связи между ними. Это умеет практически любая графическая IDE, отдельные «command line»-утилиты, специализированные графические тулы и моделлеры. Которые вам что-то нарисуют "как умеют", а немного повлиять на этот процесс можно только с помощью нескольких параметров в конфигурационном файле или галочек в интерфейсе.
Но эту проблему можно решить гораздо проще, гибче и элегантнее, и конечно же с помощью кода. Для построения диаграмм любой сложности у нас есть сразу несколько специализированных языков разметки (DOT, GraphML etc), а к ним — целая россыпь приложений (GraphViz, PlantUML, Mermaid), которые умеют читать такие инструкции и визуализировать в самых разных форматах. Ну а информацию об объектах и связях между ними мы уже знаем как получить.
Приведем небольшой пример того, как это могло бы выглядеть, с использованием PlantUML и демонстрационной база данных для PostgreSQL (слева SQL-запрос, который сгенерирует нужную инструкцию для PlantUML, а справа результат):
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all select distinct ccu.table_name || ' --|> ' || tc.table_name as val from table_constraints as tc join key_column_usage as kcu on tc.constraint_name = kcu.constraint_name join constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name where tc.constraint_type = 'FOREIGN KEY' and tc.table_name ~ '.*' union all select '@enduml'
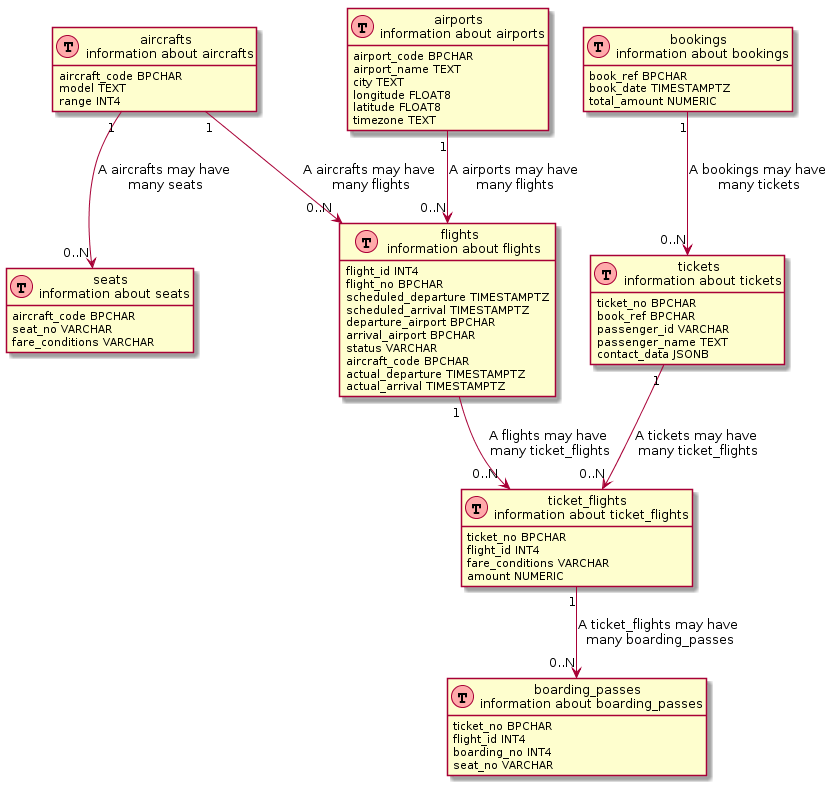
А если немного постараться, то на основе ER-шаблона для PlantUML можно получить что-то сильно похожее на настоящую ER-диаграмму:
-- Шапка select '@startuml !define Table(name,desc) class name as "desc" << (T,#FFAAAA) >> !define primary_key(x) <b>x</b> !define unique(x) <color:green>x</color> !define not_null(x) <u>x</u> hide methods hide stereotypes' union all -- Таблицы select format('Table(%s, "%s \n information about %s") {'||chr(10), table_name, table_name, table_name) || (select string_agg(column_name || ' ' || upper(udt_name), chr(10)) from information_schema.columns where table_schema = 'public' and table_name = t.table_name) || chr(10) || '}' from information_schema.tables t where table_schema = 'public' union all -- Связи между таблицами select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may have\n many %s"', ccu.table_name, tc.table_name) from information_schema.table_constraints as tc join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name where tc.constraint_type = 'FOREIGN KEY' and ccu.constraint_schema = 'public' and tc.table_name ~ '.*' union all -- Подвал select '@enduml'
Если внимательно присмотреться, то под капотом многие инструменты-визуализаторы точно также используют похожие запросы. Правда, запросы эти обычно глубоко "зашиты" в код самого приложения и сложны для понимания, не говоря уже о какой-либо их модификации.
Метрики и мониторинг
Перейдем к традиционно сложной теме — мониторинг производительности БД. Вспомню небольшую true story, рассказанную мне "одним моим другом". На очередном проекте жил-был некий могущественный DBA, и мало кто из разработчиков был с ним знаком лично, да и вообще видел когда-нибудь его в глаза (несмотря на то, что трудился он, по слухам, где-то в соседнем корпусе). В час "X", когда poduction-система крупного ретейлера начинала в очередной раз "плохо себя чувствовать", он молча присылал скриншоты графиков из ораклового Enterprise Manager, на которых бережно выделял критичные места красным маркером для "понятности" (это, мягко говоря, мало помогало). И вот по этой "фотокарточке" приходилось лечить. При этом доступа к драгоценному (в обоих смыслах этого слова) Enterprise Manager ни у кого не было, т.к. система сложная и дорогая, вдруг "разрабы чего-нить натыкают и все поломают". Поэтому разработчики "эмпирическим" путем находили место и причину тормозов и выпускали патч. Если грозное письмо от DBA не приходило повторно в ближайшее время, то все с облегчением выдыхали и возвращались к своим текущим задачам (до нового Письма).
Но процесс мониторинга может выглядеть более весело и дружелюбно, а самое главное — доступно и прозрачно для всех. Хотя бы базовая его часть, как дополнение к основным системам мониторинга (которые безусловно полезны и во многих случаях незаменимы). Любая СУБД свободно и абсолютно безвозмездно готова поделиться информацией о своем текущем состоянии и производительности. В той же самой "кровавой" Oracle DB практически любую информацию о производительности можно получить из системных представлений, начиная от процессов и сессий и заканчивая состоянием буферного кеша (например, DBA Scripts, раздел "Monitoring"). В Postgresql также есть целая россыпь системных представлений для мониторинга работы БД, в частности такие незаменимые в повседневной жизни любого DBA, как pg_stat_activity, pg_stat_database, pg_stat_bgwriter. В MySQL для этого предназначена даже отдельная схема performance_schema. А В Mongo встроенный профайлер агрегирует данные о производительности в системную коллекцию system.profile.
Т.о., вооружившись каким-либо сборщиком метрик (Telegraf, Metricbeat, Collectd), который умеет выполнять кастомные sql-запросы, хранилищем этих метрик (InfluxDB, Elasticsearch, Timescaledb) и визуализатором (Grafana, Kibana), можно получить достаточно легкую и гибкую систему мониторинга, которая будет тесно интегрирована с другими общесистемными метриками (получаемыми, например, от сервера приложений, от ОС и пр.). Как, например, это сделано в pgwatch2, где используется связка InfluxDB + Grafana и набор запросов к системным представлениям, к которым также можно добавить кастомные запросы.
Итого
И это только приблизительный перечень того, что можно сделать с нашей БД посредством обычного SQL-кода. Уверен, можно найти еще множество применений, пишите в комментариях. А о том, как (и самое главное зачем) это все заавтоматизировать и включить в свой CI/CD pipeline мы поговорим в следующий раз.

