В DataGrip, как и в других наших IDE с поддержкой баз данных, есть механизм экспорта данных. Пользователь выбирает формат экспорта из предложенных или создает его сам.

Таблица, представление или результат могут быть экспортированы в файл или буфер обмена.
Экспорт в файл:
— Контекстное меню на таблице или представлении в дереве → Dump data to file.
— Контекстное меню на запросе в редакторе → Execute to file.
— В панели инструментов редактора данных или результата нажать кнопку Dump data → To File...
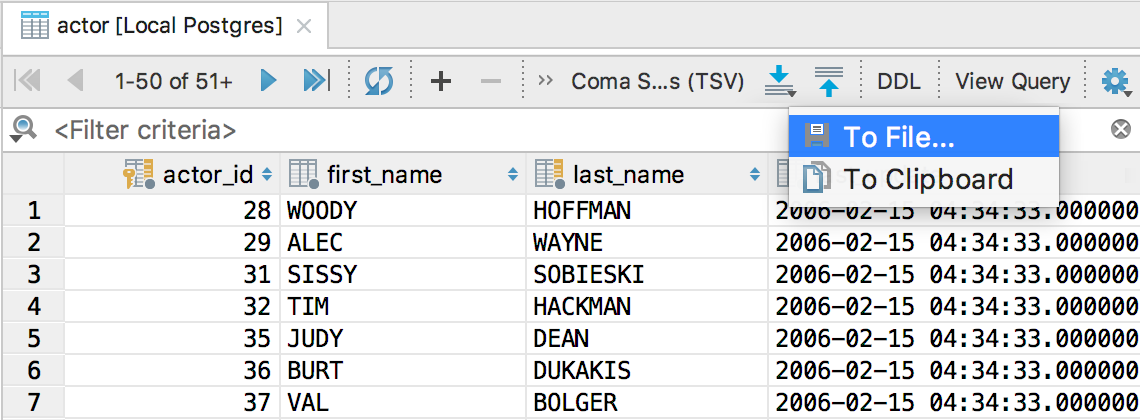
Экспорт в буфер обмена:
— Выбрать данные для экспорта в редакторе данных или результате и нажать Copy или Ctrl/Cmd+C.
— В панели инструментов результата или редактора данных нажать кнопку Dump data → To File...
Некоторые форматы настроены по умолчанию. Сам механизм экспортирования мы зовём «экстрактором»: в IDE уже встроены несколько экстракторов для разных форматов. На примере рассмотрим экспорт данных в буфер обмена, но это работает и для экспорта в файл.
В меню слева от кнопки Dump Data выберите экстрактор.

Набор INSERT/UPDATE запросов или JSON, CSV, HTML — решать вам. Здесь описано, как работают встроенные экстракторы, не будем на этом заострять внимание.
Логично, что пользователи хотят расширить встроенные возможности.

Чтобы создать собственный экстрактор для формата на основе CSV (или, строго говоря, DSV), в этом же меню нажмите на Configure CSV formats…

Здесь можно внести изменения в уже существующие экстракторы или создать свой. Например, Confluence Wiki Markup.

Сохранённый новый экстрактор появится в меню:

Для более сложных случаев используйте скрипты. Несколько встроенных экстракторов — это скрипты на Groovy или JavaScript: CSV-Groovy.csv.groovy, HTML-JavaScript.html.js и другие. В наших примерах будем использовать Groovy.
Разберём имя файла CSV-Groovy.csv.groovy:
CSV-Groovy — имя скрипта.
csv — расширение файла с результатом.
groovy — расширение файла скрипта. Если редактируете его в IntelliJ IDEA, поможет иметь подсветку кода и автодополнение.
Скрипты обычно расположены в `Scratches and Consoles/Extensions/Database Tools and SQL/data/extractors`. Чтобы попасть в эту папку, нажмите Go to scripts directory в меню выбора экстракторов.

Изменяйте существующие экстракторы или добавляйте новые в эту папку. Например, создадим экстрактор для экспорта данных в одну строчку через запятую. Это удобно, если значения из одного столбца вставят в оператор IN предложения WHERE.
На основе существующего экстрактора мы создали новый: CSV-ToOneRow-Groovy.csv.groovy.

Доступно в контексте:
В DasTable два важных метода:
До версии 2017.3:
Начиная с 2017.3:
Ещё про API читайте здесь.
Если вы проделываете это в IntelliJ IDEA с установленным Groovy, будут работать подсветка и автодополнение:

Положите новый скрипт в папку и вперед: он готов к использованию и виден в меню.

Например, скопируйте эти значения и вставьте в запрос.

Ещё один пример: в MySQL и PostgreSQL допускается многострочный синтаксис для INSERT. Изменив текущий экстрактор для INSERT’ов, получим новый файл: SQL-Inserts-MultirowSynthax.sql.groovy.
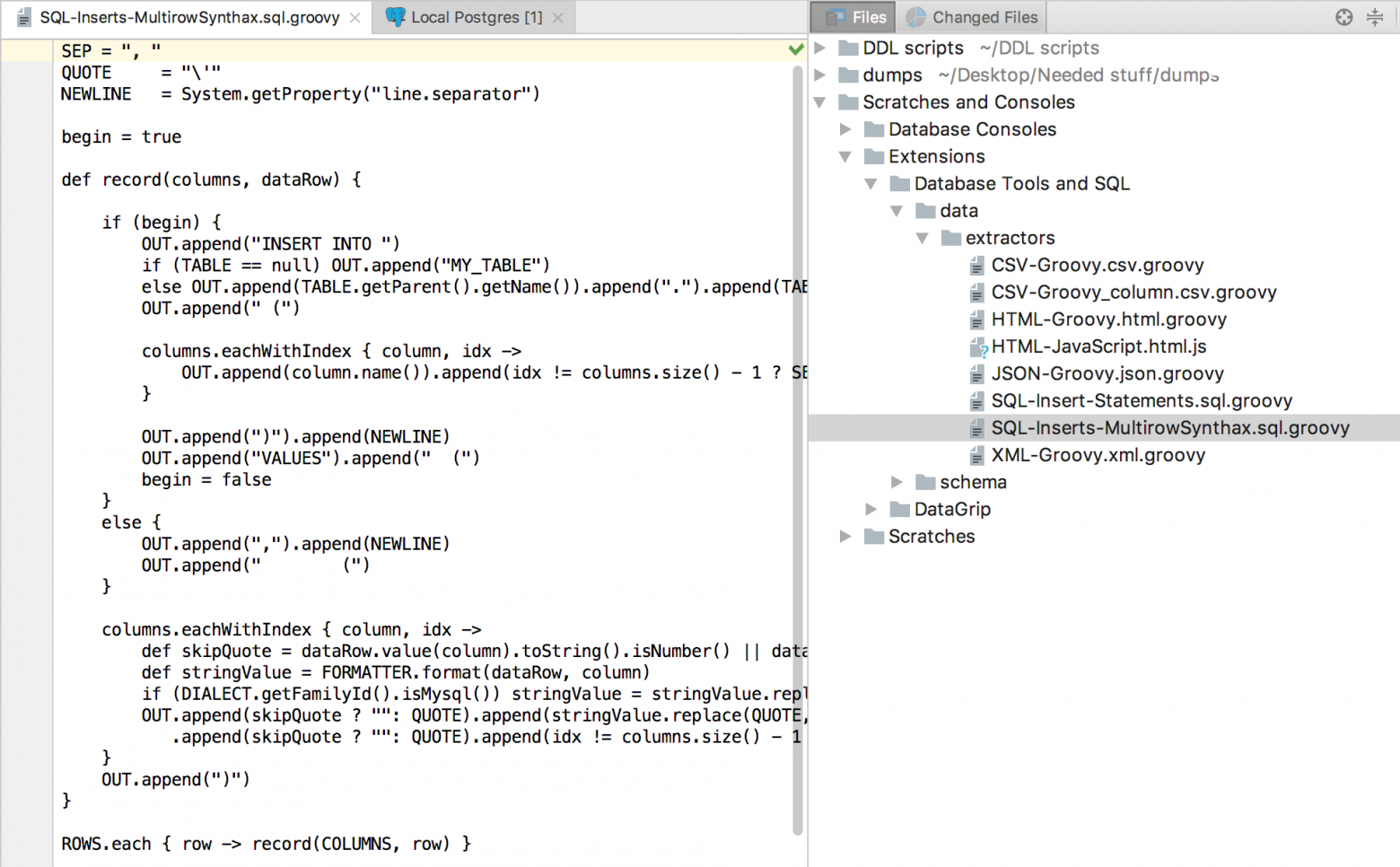
Выбираем только что созданный экстрактор, копируем данные.
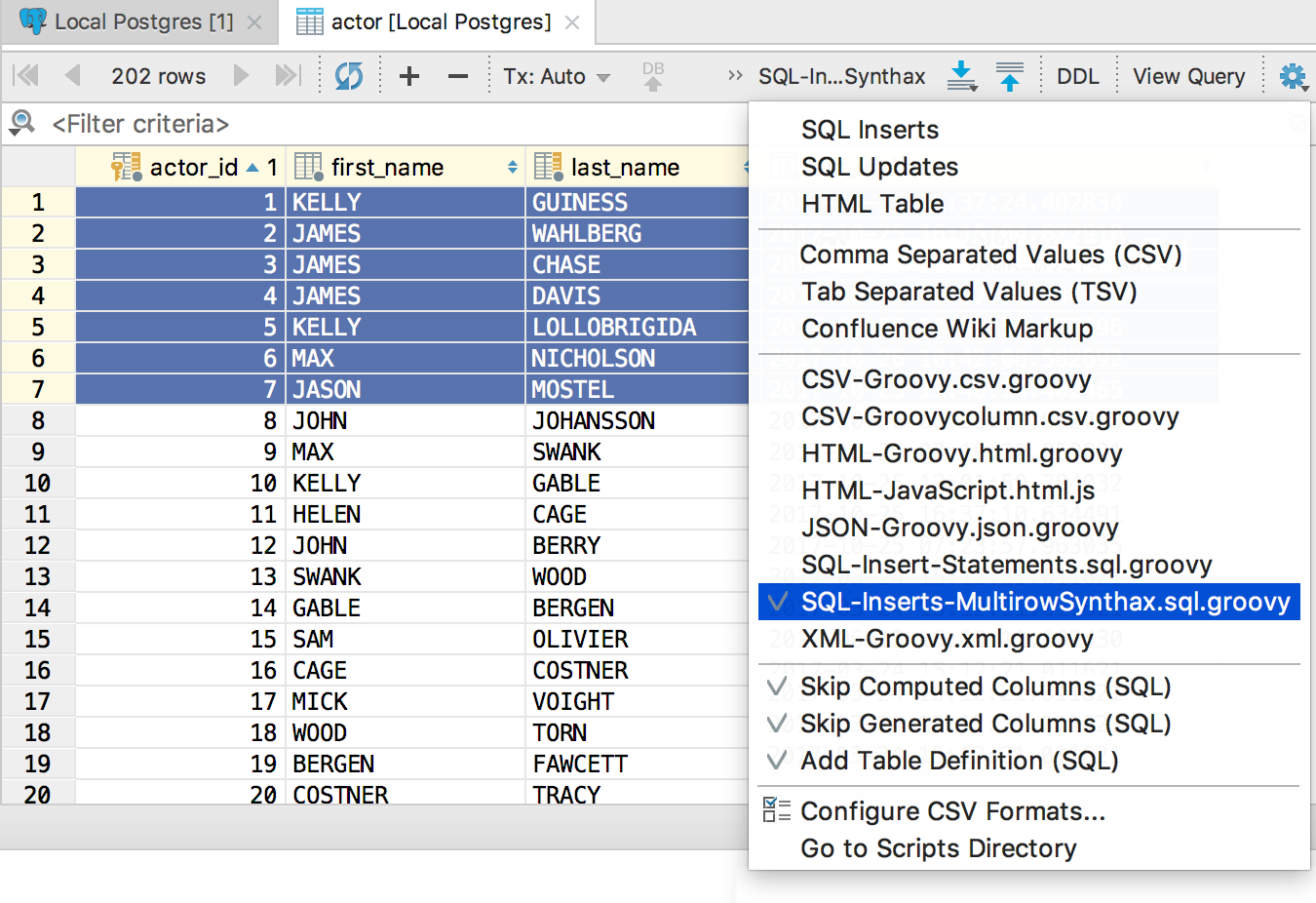
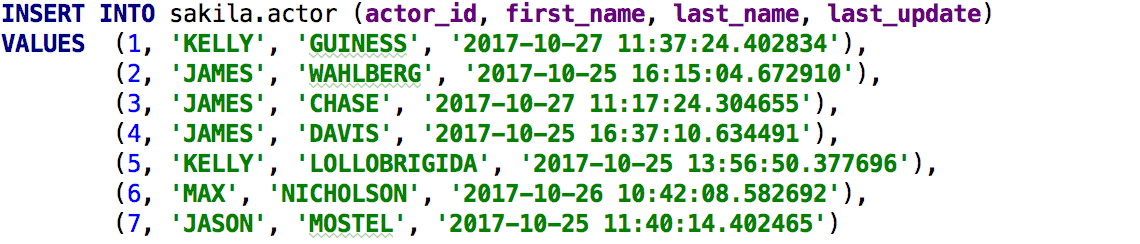
Готово:
Некоторые пользователи уже разобрались с этим и написали свои экстракторы:
— Текстовая таблица. (Похожий).
— Массив Php.
— Markdown.
— DBunit XML.
Будет круто, если этот текст вдохновит вас писать свои экстракторы и делиться ими с другими!
Команда DataGrip
Направления экспорта
Таблица, представление или результат могут быть экспортированы в файл или буфер обмена.
Экспорт в файл:
— Контекстное меню на таблице или представлении в дереве → Dump data to file.
— Контекстное меню на запросе в редакторе → Execute to file.
— В панели инструментов редактора данных или результата нажать кнопку Dump data → To File...
Экспорт в буфер обмена:
— Выбрать данные для экспорта в редакторе данных или результате и нажать Copy или Ctrl/Cmd+C.
— В панели инструментов результата или редактора данных нажать кнопку Dump data → To File...
Форматы по умолчанию
Некоторые форматы настроены по умолчанию. Сам механизм экспортирования мы зовём «экстрактором»: в IDE уже встроены несколько экстракторов для разных форматов. На примере рассмотрим экспорт данных в буфер обмена, но это работает и для экспорта в файл.
В меню слева от кнопки Dump Data выберите экстрактор.
Набор INSERT/UPDATE запросов или JSON, CSV, HTML — решать вам. Здесь описано, как работают встроенные экстракторы, не будем на этом заострять внимание.
Логично, что пользователи хотят расширить встроенные возможности.
Пользовательские экстракторы на основе CSV
Чтобы создать собственный экстрактор для формата на основе CSV (или, строго говоря, DSV), в этом же меню нажмите на Configure CSV formats…
Здесь можно внести изменения в уже существующие экстракторы или создать свой. Например, Confluence Wiki Markup.
Сохранённый новый экстрактор появится в меню:
Создание экстрактора в любой формат при помощи скриптов
Для более сложных случаев используйте скрипты. Несколько встроенных экстракторов — это скрипты на Groovy или JavaScript: CSV-Groovy.csv.groovy, HTML-JavaScript.html.js и другие. В наших примерах будем использовать Groovy.
Разберём имя файла CSV-Groovy.csv.groovy:
CSV-Groovy — имя скрипта.
csv — расширение файла с результатом.
groovy — расширение файла скрипта. Если редактируете его в IntelliJ IDEA, поможет иметь подсветку кода и автодополнение.
Скрипты обычно расположены в `Scratches and Consoles/Extensions/Database Tools and SQL/data/extractors`. Чтобы попасть в эту папку, нажмите Go to scripts directory в меню выбора экстракторов.
Изменяйте существующие экстракторы или добавляйте новые в эту папку. Например, создадим экстрактор для экспорта данных в одну строчку через запятую. Это удобно, если значения из одного столбца вставят в оператор IN предложения WHERE.
На основе существующего экстрактора мы создали новый: CSV-ToOneRow-Groovy.csv.groovy.
Доступно в контексте:
OUT {append()} //объект для вывода данных
FORMATTER {format(row, col); formatValue(Object, col)} //конвертер данных в строку
TRANSPOSED Boolean //нажата ли кнопка Transpose (в меню по иконке с шестеренкой)
COLUMNS List<DataColumn> //выбранные столбцы
ALL_COLUMNS List<DataColumn> //все столбцы
//Это равные объекты, если ничего не выделено.
ROWS Iterable<DataRow> //выбранные строчки, где:
DataRow { rowNumber(); first(); last(); data(): List<Object>; value(column): Object }
DataColumn { columnNumber(); name() }
TABLE DasTable //текущая таблицаВ DasTable два важных метода:
До версии 2017.3:
DasObject getDbParent()
JBIterable<DasObject> getDbChildren(Class, ObjectKind)Начиная с 2017.3:
DasObject getDasParent()
JBIterable<DasObject> getDasChildren(ObjectKind) Ещё про API читайте здесь.
Если вы проделываете это в IntelliJ IDEA с установленным Groovy, будут работать подсветка и автодополнение:
Положите новый скрипт в папку и вперед: он готов к использованию и виден в меню.
Например, скопируйте эти значения и вставьте в запрос.
Ещё один пример: в MySQL и PostgreSQL допускается многострочный синтаксис для INSERT. Изменив текущий экстрактор для INSERT’ов, получим новый файл: SQL-Inserts-MultirowSynthax.sql.groovy.
Выбираем только что созданный экстрактор, копируем данные.
Готово:
Некоторые пользователи уже разобрались с этим и написали свои экстракторы:
— Текстовая таблица. (Похожий).
— Массив Php.
— Markdown.
— DBunit XML.
Будет круто, если этот текст вдохновит вас писать свои экстракторы и делиться ими с другими!
Команда DataGrip
