
Rise of the Tomb Raider (2015 год) — это сиквел превосходного перезапуска Tomb Raider (2013 год). Лично я нахожу обе части интересными, потому что они отошли от стагнирующей оригинальной серии и рассказали историю Лары заново. В этой игре, как и в приквеле, центральное место занимает сюжет, она предоставляет увлекательные механики крафтинга, охоты и скалолазания/исследований.
В Tomb Raider использовался разработанный Crystal Dynamics движок Crystal Engine, также применявшийся в Deus Ex: Human Revolution. В сиквеле использовали новый движок под названием Foundation, ранее разрабатывавшийся для Lara Croft and the Temple of Osiris (2014 год). Его рендеринг можно в целом описать как тайловый движок с предварительным проходом освещения, и позже мы узнаем, что это означает. Движок позволяет выбирать между рендерерами DX11 и DX12; я выбрал последний, по причинам, которые мы обсудим ниже. Для захвата кадра использовался Renderdoc 1.2 на Geforce 980 Ti, в игре включены все функции и украшательства.
Анализируемый кадр

Чтобы не было спойлеров, скажу, что в этом кадре плохие парни преследуют Лару, потому что она ищет артефакт, который разыскивают и они. Этот конфликт интересов никак не разрешить без оружия. Лара ночью пробралась на вражескую база. Я выбрал кадр с атмосферным и контрастным освещением, при котором движок может показать себя.
Предварительный проход глубины
Здесь выполняется привычная для многих игр оптимизация — небольшой предварительный проход глубины (примерно 100 вызовов отрисовки). Игра рендерит самые крупные объекты (а не те, которые занимают больше места на экране), чтобы воспользоваться преимуществом функции видеопроцессоров Early-Z. Подробнее о ней рассказывается в статье Intel. Если вкратце, то GPU способны избегать выполнения пиксельного шейдера, если могут определить, что он перекрыт предыдущим пикселем. Это довольно малозатратный проход, предварительно заполняющий Z-буфер значениями глубин.
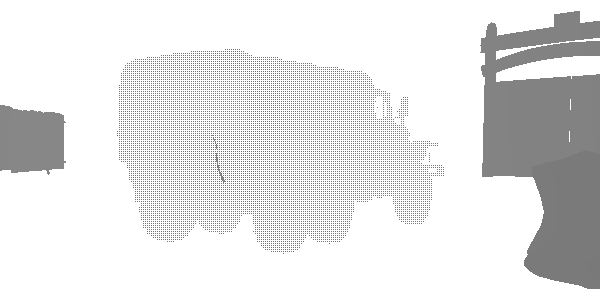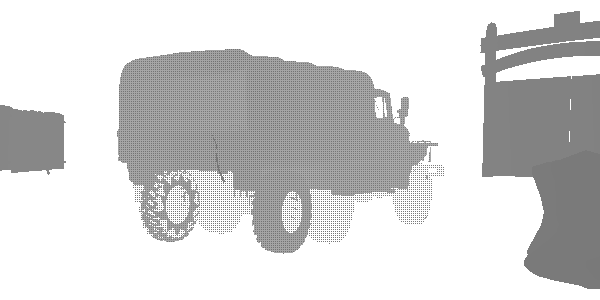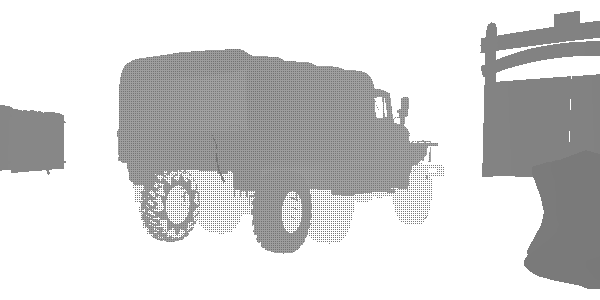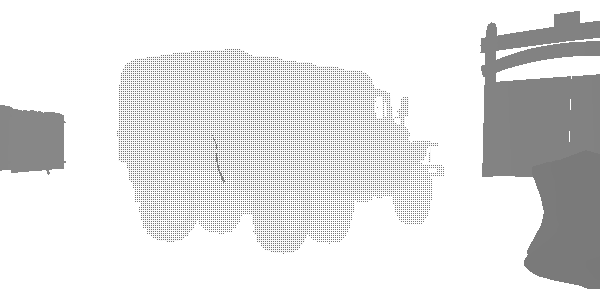
На этом этапе я обнаружил интересную технику уровней детализации (level of detail, LOD) под названием «fizzle» или «checkerboard». Это распространённый способ постепенного отображения или сокрытия объектов на расстоянии, чтобы в дальнейшем или заменить их мешем более низкого качества, или полностью скрыть их. Посмотрите на этот грузовик. Похоже, что он рендерится дважды, но на самом деле он рендерится с высоким LOD и низким LOD в одной и той же позиции. Каждый из уровней рендерит те пиксели, которые не отрендерил другой. Первый LOD имеет 182226 вершин, а второй LOD — 47250. На большом расстоянии они неразличимы, но один из них в три раза менее затратен. В этом кадре LOD 0 почти исчезает, а LOD 1 рендерится почти полностью. После полного исчезновения LOD 0 будет рендериться только LOD 1.

LOD 0

LOD 1
Псевдослучайная текстура и коэффициент вероятности позволяет нам отбрасывать пиксели, не прошедшие порогового значения. Эта текстура используется в ROTR. Можно задаться вопросом, почему же не используется альфа-смешение. У альфа-смешения есть множество недостатков по сравнению с fizzle fading.
- Удобство для предварительного прохода глубин: благодаря рендерингу непрозрачного объекта с проделанными в нём отверстиями, мы можем выполнять рендеринг в предварительном проходе и пользоваться early-z. Объекты с альфа-смешением на столь раннем этапе не рендерятся в буфер глубин из-за проблем с сортировкой.
- Необходимость дополнительных шейдеров: если используется отложенный рендерер, то шейдер непрозрачных объектов не содержит никакого освещения. Если вам нужно заменить непрозрачный объект прозрачным, то необходим отдельный вариант, в котором есть освещение. Кроме повышения объёма нужной памяти и сложности из-за по крайней мере одного дополнительного шейдера для всех непрозрачных объектов, они должны быть точными, чтобы избежать выступания объектов вперёд. Это сложно по многим причинам, но всё сводится к тому, что рендеринг теперь выполняется по другому пути кода.
- Больший объём перерисовки: альфа-смешение может создавать большую перерисовку и при определённом уровне сложности объектов может потребоваться большая доля полосы пропускания для затенения LOD.
- Z-конфликты: z-конфликты — это эффект мерцания, когда два полигона рендерятся на очень близкой друг к другу глубине. При этом неточность вычислений с плавающей запятой заставляет их рендериться по очереди. Если мы отрендерим два последовательных LOD, постепенно скрывая один и показывая второй, то они могут вызвать z-конфликт, потому что очень близки друг к другу. Всегда есть способы обойти это, например, предпочитая один полигон другому, но такая система оказывается сложной.
- Эффекты Z-буфера: многие эффекты наподобие SSAO используют только буфер глубин. Если бы мы рендерили прозрачные объекты в конце конвейера, когда ambient occlusion уже выполнено, то не могли бы его учесть.
Недостаток этой техники в том, что она выглядит хуже, чем альфа-смешение, но хороший паттерн шума, размытие после fizzle или временной антиалиасинг могут почти полностью скрыть это. В этом отношении ROTR не делает ничего особо необычного.
Проход нормалей
В своих играх Crystal Dynamics использует довольно необычную схему освещения, которую мы рассмотрим в проходе освещения. Пока же достаточно сказать, что движке нет прохода G-буфера; по крайней мере, в той степени, которая привычна в других играх. На этом проходе объекты передают на выход только информацию о глубине и нормалях. Нормали записываются в render target формата RGBA16_SNORM в мировом пространстве. Любопытно, что этот движок использует схему Z-up, а не Y-up (вверх направлена ось Z, а не Y), которая более часто применяется в других движках/пакетах моделирования. В альфа-канале содержится глянцевость (glossiness), которая в дальнейшем распаковывается как
exp2(glossiness * 12 + 1.0). Значение glossiness может быть и отрицательным, потому что знак используется как флаг, показывающий, является ли поверхность металлической. Это можно заметить и самостоятельно, потому что все тёмные цвета в альфа-канале относятся к металлическим объектам.| R | G | B | |
| Normal.x | Normal.y | Normal.z | Glossiness + Metalness |

Нормали

Glossiness/Metalness
Преимущества предварительного прохода глубин

Помните, что в разделе «Предварительный проход глубин» мы говорили об экономии затрат на пиксели? Я немного вернусь назад, чтобы проиллюстрировать её. Возьмём следующее изображение. Это рендеринг детализированной части горы в буфер нормалей. Renderdoc любезно выделил пиксели, прошедшие тест глубины, зелёным цветом, а не прошедшие его — красным (они не рендерятся). Общее количество пикселей, которые бы отрендерились без этого предварительного прохода, примерно равно 104518 (подсчитано в Photoshop). Общее количество пикселей, рендерящихся на самом деле, равно 23858 (вычислено Renderdoc). Экономия примерно в 77%! Как мы видим, при умном использовании этот предварительный проход может дать большой выигрыш, а требует он всего около ста вызовов отрисовки.
Запись многопоточных команд

Стоит отметить один интересный аспект, из-за которого я выбрал рендерер DX12 — запись многопоточных команд. В предыдущих API, например в DX11, рендеринг обычно выполняется в одном потоке. Графический драйвер получал от игры команды отрисовки и постоянно передавал запросы GPU, но игра не знала, когда это произойдёт. Это приводит к неэффективности, потому что драйвер должен каким-то образом догадываться, что пытается сделать приложение, и не масштабируется на несколько потоков. Более новые API, такие как DX12, передают управление разработчику, который сам может решать, как записывать команды и когда отправлять их. Хотя Renderdoc и не может показать, как выполняется запись, вы увидите, что есть семь проходов цвета, помеченные как Color Pass N, и каждый из них обёрнут в пару ExecuteCommandList: Reset/Close. Она обозначает начало и конец списка команд. На список приходится примерно 100-200 вызовов отрисовки. Это не означает, что они были записаны с помощью нескольких потоков, но намекает на это.
Следы на снегу

Если посмотреть на Лару, то можно заметить, что при перемещении перед скриншотом она оставила на снегу следы. В каждом кадре выполняется вычислительный шейдер (compute shader), записывающий деформации в определённых областях и применяющий их на основании типа и высоты поверхности. Здесь к снегу применяется только карта нормалей (т.е. геометрия не изменяется), но в некоторых областях, где толщина снега больше, деформация выполняется на самом деле! Можно также увидеть, как снег «падает» на место и заполняет оставленные Ларой следы. Гораздо подробнее эта техника описана в GPU Pro 7. Текстура деформации снега — это своего рода карта высот, отслеживающая движения Лары и склеенная по краям так, чтобы шейдер сэмплирования мог воспользоваться этим сворачиванием.
Атлас теней
При создании Shadow mapping используется довольно распространённый подход — упаковка как можно большего количества карт теней в общую текстуру теней. Такой атлас теней на самом деле является огромной 16-битной текстурой размером 16384×8196. Это позволяет очень гибко многократно использовать и масштабировать карты теней, находящиеся в атласе. В анализируемом нами кадре в атлас записано 8 карт теней. Четыре из них относятся к основному источнику направленного освещения (луне, ведь дело происходит ночью), потому что они используют каскадные карты теней — достаточно стандартную технику теней дальних расстояний для направленного освещения, которую я уже немного объяснял ранее. Более интересно то, что в захват этого кадра также включены несколько прожекторных и точечных источников освещения. То, что в этом кадре записано 8 карт теней, не означает, что в нём есть только 8 источников отбрасывающего тени освещения. Игра может кэшировать вычисления теней, то есть освещение, у которого не изменилась или позиция источника, или геометрия в области действия, не должно обновлять свою карту теней.

Похоже, что рендеринг карт теней тоже выигрывает от записи многопоточных команд в список, и в данном случае для рендеринга карт теней записано целых 19 списков команд.
Тени от направленного освещения
Тени от направленного освещения вычисляются до прохода освещения и позже сэмплируются. Я не знаю, что произошло бы, если бы в сцене было несколько источников направленного освещения.

Ambient Occlusion
Для ambient occlusion ROTR позволяет использовать на выбор или HBAO, или его разновидность HBAO+ (эту технику изначально опубликовала NVIDIA). Существует несколько вариаций этого алгоритма, поэтому я рассмотрю тот, который я обнаружил в ROTR. Сначала буфер глубин разделяется на 16 текстур, каждая из которых содержит 1/16 от всех значений глубин. Разделение выполняется таким образом, что каждая текстура содержит одно значение из блока 4×4 оригинальной текстуры, показанной на рисунке ниже. Первая текстура содержит все значения, отмеченные красным (1), вторая — значения, отмеченные синим (2), и так далее. Если вы хотите узнать подробности об этой технике, то вот статья Louis Bavoil, который также был одним из авторов статьи про HBAO.

Следующий этап вычисляет для каждой текстуры ambient occlusion, что даёт нам 16 текстур AO. Генерируется ambient occlusion следующим образом: несколько раз сэмплируется буфер глубин, воссоздавая позицию и накапливая результат вычислений для каждого из сэмплов. Каждая текстура ambient occlusion вычисляется с использованием разных координат сэмплирования, то есть в блоке пикселей 4×4 каждый пиксель рассказывает свою часть истории. Это сделано по причине производительности. Каждый пиксель уже сэмплирует буфер глубин 32 раз, а полный эффект потребует 16×32 = 512 сэмпла, что является перебором даже для самых мощных GPU. Затем они рекомбинируются в одну полноэкранную текстуру, которая получается довольно шумной, поэтому для сглаживания результатов сразу после этого выполняется проход полноэкранного размытия. Очень похожее решение мы видели в Shadow of Mordor.

Части HBAO

Полное HBAO с шумом

Полное HBAO с горизонтальным размытием

Готовое HBAO
Тайловый предварительный проход освещения
Предварительный проход освещения (Light Prepass) — довольно необычная техника. Большинство команд разработчиков использует сочетание отложенного + прямого расчёта освещения (с вариациями, например, с тайловым, кластерным) или полностью прямой для некоторых эффектов экранного пространства. Техника предварительного прохода освещения настолько необычна, что заслуживает объяснения. Если концепция традиционного отложенного освещения заключается в отделении свойств материалов от освещения, то в основе предварительного прохода освещения заложена идея отделения освещения от свойств материалов. Хотя такая формулировка выглядит немного глупо, отличие от традиционного отложенного освещения в том, что мы храним все свойства материалов (такие как albedo, specular color, roughness, metalness, micro-occlusion, emissive) в огромном G-буфере, и используем его позже как входные данные для последующих проходов освещения. Традиционное отложенное освещение может представлять большую нагрузку на пропускную способность; чем сложнее материалы, тем больше информации и операций необходимо в G-буфере. Однако в предварительном проходе освещения мы сначала накапливаем всё освещение отдельно, используя минимальный объём данных, а затем применяем их в последующих проходах к материалам. В данном случае освещению достаточно только нормалей, roughness и metalness. Шейдеры (здесь используются два прохода) выводят данные в три render target формата RGBA16F. Один содержит диффузное освещение, второй — зеркальное освещение, а третий — окружающее освещение. На этом этапе учитываются все данные теней. Любопытно, что в первом проходе (диффузное + зеркальное освещение) для полноэкранного прохода используется четырёхугольник (quad) из двух треугольников, а в других эффектах используется один полноэкранный треугольник (почему это важно, можно узнать здесь). С этой точки зрения весь кадр не является целостным.

Диффузное освещение

Зеркальное освещение

Окружающее освещение
Тайловая оптимизация
Тайловое освещение — это техника оптимизации, предназначенная для рендеринга большого количества источников освещения. ROTR разделяет экран на тайлы 16×16, а затем сохраняет информацию о том, какие источники пересекают каждый тайл, то есть вычисления освещения будут выполняться только для тех источников, которые касаются тайлов. В начале кадра запускается последовательность вычислительных шейдеров, определяющих какие источники касаются тайлов. На этапе освещения каждый пиксель определяет, в каком тайле он находится и обходит в цикле каждый источник освещения в тайле, выполняя все вычисления освещения. Если привязка источников к тайлам выполнена качественно, то можно сэкономить много вычислений и большую часть полосы пропускания, а также повысить производительность.
Увеличение масштаба с учётом глубины
Повышающая дискретизация с учётом глубины — это интересная техника, полезная на этом и последующих проходах. Иногда вычислительно затратные алгоритмы невозможно отрендерить в полном разрешении, поэтому они рендерятся с меньшим разрешением, а потом увеличиваются в масштабе. В нашем случае в половинном разрешении вычисляется окружающее освещение, то есть после расчётов освещение необходимо правильно воссоздать. В простейшем виде берутся 4 пикселя низкого разрешения и интерполируются, чтобы получить нечто, напоминающее исходное изображение. Это срабатывает для плавных переходов, но плохо выглядит на разрывах поверхностей, потому что там мы смешиваем несвязанные друг с другом величины, которые могут быть смежными в экранном пространстве, но отдалёнными друг от друга в мировом пространстве. В решениях этой проблемы обычно берутся несколько сэмплов буфера глубин и сравниваются с сэмплом глубин, который мы хотим воссоздать. Если сэмпл находится слишком далеко, то мы не учитываем его при воссоздании. Такая схема работает хорошо, но она означает, что шейдер воссоздания сильно нагружает полосу пропускания.
ROTR делает хитрый ход с помощью раннего отбрасывания стенсила. После прохода нормалей буфер глубин полностью заполнен, поэтому движок выполняет полноэкранный проход, помечающий все прерывающиеся пиксели в стенсил-буфере. Когда настаёт время воссоздания буфера окружающего освещения, движок использует два шейдера: один очень простой — для областей без разрывов глубин, другой — более сложный для пикселей с разрывами. Ранний стенсил отбрасывает пиксели, если они не принадлежат соответствующей области, то есть затраты есть только в нужных областях. На следующих изображениях гораздо понятнее:

Окружающее освещение в половинном разрешении

Повышение масштаба глубин внутренних частей

Окружающее освещение в полном разрешении, без рёбер

Повышение масштаба глубин рёбер

Готовое окружающее освещение

Приближенный вид половинного разрешения

Приближенный вид воссозданного изображения
После предварительного прохода освещения геометрия передаётся в конвейер, только на этот раз каждый объект сэмплирует текстуры освещения, текстуру ambient occlusion и другие свойства материалов, которые мы не записали в G-буфер с самого начала. Это хорошо, потому что здесь сильно экономится пропускная способность благодаря тому, что не нужно считывать кучу текстур, чтобы записывать их в большой G-буфер, чтобы потом их снова считать/декодировать. Очевидный недостаток такого подхода в том, что всю геометрию нужно передавать заново, а текстуры предварительного прохода освещения сами по себе представляют большую нагрузку на пропускную способность. Я задавался вопросом, почему для текстур предварительного прохода освещения не использовать более лёгкий формат, например R11G11B10F, но в альфа-канале есть дополнительная информация, поэтому это было бы невозможно. Как бы то ни было, это интересное техническое решение. На этом этапе вся непрозрачная геометрия уже отрендерена и освещена. Заметьте, что в неё включены такие испускающие свет объекты, как небо и экран ноутбука.

Отражения
Эта сцена — не особо хороший пример для демонстрации отражений, поэтому я выбрал другую. Шейдер отражений — это довольно сложное сочетание циклов, которые можно свести к двум частям: одна сэмплирует кубические карты, а другая выполняет SSR (Screen space reflection — вычисления отражений в экранном пространстве); всё это делается в одном проходе и в конце смешивается с учётом коэффициента, определяющего, обнаружило ли SSR отражение (вероятно, коэффициент не двоичный, а является значением в интервале [0, 1]). SSR работает стандартным для многих игр образом — многократно трассирует буфер глубин, пытаясь найти наилучшее пересечение между лучом, отражённым затеняемой поверхностью, и другой поверхностью в каком-нибудь месте экрана. SSR работает с mip-цепочкой ранее уменьшенного масштаба текущего HDR-буфера, а не со всем буфером.
Тут также есть такие факторы корректировки, как яркость отражения, а также своеобразная френелевская текстура, которая вычислена до этого прохода, на основании нормалей и roughness. Я не полностью уверен, но после изучения ассемблерного кода мне кажется, что ROTR может вычислять SSR только для гладких поверхностей. В движке нет mip-цепочки размытия после этапа SSR, которые существуют в других движках, и нет даже ничего наподобие трассировки буфера глубин с помощью лучей, которая варьируется на основании roughness. В целом, более шероховатые поверхности получают отражения от кубических карт, или не получают их вовсе. Тем не менее, там, где работает SSR, его качество очень высоко и стабильно, с учётом того, что он не накапливается по времени и для него не выполняется пространственное размытие. Альфа-данные тоже поддерживают SSR (в некоторых храмах можно увидеть очень красивые отражения в воде) и это хорошее дополнение, которое не часто увидишь.

Отражения до

Буфер отражений

Отражения после
Освещённый туман

В нашей сцене туман представлен плохо, потому что он затемняет фон, и поэтому создан частицами, так что мы снова используем пример с отражениями. Туман относительно прост, но довольно эффективен. Есть два режима: глобальный, общий цвет тумана, и цвет рассеяния внутрь, получаемый из кубической карты. Возможно, кубическую карту снова взяли из кубических карт отражений, а может быть, создали заново. В обоих режимах разрежение тумана берётся из глобальной текстуры разрежения, в которую запакованы кривые разрежения для нескольких эффектов. В такой схема замечательно то, что она даёт очень малозатратный освещённый туман, т.е. рассеяние внутрь изменяется в пространстве, создавая иллюзию взаимодействия тумана с отдалённым освещением. Такой подход также можно использовать для атмосферного рассеяния внутрь у неба.

Туман до

Туман после
Объёмное освещение
На ранних этапах кадра происходит несколько операций для подготовки к объёмному освещению. Из ЦП в GPU копируются два буфера: индексов источников освещения и данных источников освещения. Оба считываются вычислительным шейдером, который выводит 3D-текстуру 40x23x16 вида из камеры, содержащую количество источников освещения, пересекающих эту область. Текстура имеет размеры 40×23, потому что каждый тайл занимает 32×32 пикселя (1280/32 = 40, 720/32 = 22.5), а 16 — это количество пикселей в глубине. В текстуру включаются не все источники освещения, а только те, которые помечены как объёмные (в нашей сцене их три). Как мы увидим ниже, есть и другие фальшивые объёмные эффекты, создаваемые плоскими текстурами. Выводимая текстура имеет большее разрешение — 160x90x64. После определения количества источников освещения на тайл и их индекса последовательно запускаются три вычислительных шейдера, выполняющих следующие операции:
- Первый проход определяет количество входящего в ячейку света в пределах объёма в форме пирамиды видимости. Каждая ячейка накапливает влияние всех источников освещения, как будто в них есть взвешенные частицы, реагирующие на свет и возвращающие его часть в камеру.
- Второй проход выполняет размытие освещения с небольшим радиусом. Вероятно, это нужно, чтобы избежать мерцания при перемещении камеры, потому что разрешение очень низкое.
- Третий проход обходит текстуру объёма спереди назад, инкрементно прибавляя влияние каждого источника и выдавая готовую текстуру. По сути он симулирует общее количество входящего освещения по лучу до заданного расстояния. Так как каждая ячейка содержит часть света, отражённую частицами в сторону камеры, в то в каждой из них мы получим совместный вклад всех ранее пройденных ячеек. Этот проход тоже выполняет размытие.
Когда всё это завершится, у нас получается 3D-текстура, сообщающая, сколько света получает конкретная позиция относительно камеры. Всё, что остаётся сделать полноэкранному проходу — определить эту позицию, найти соответствующий воксель текстуры и прибавить его к HDR-буферу. Сам шейдер освещения очень прост и содержит всего около 16 инструкций.

Объёмное освещение до

Объёмное освещение после
Рендеринг волос
Если функция PureHair не включена, то поверх друг друга рендерятся стандартные слои волос. Это решение по-прежнему выглядит отлично, но я хотел бы сосредоточиться на самых современных технологиях. Если функция включена, то кадр начинается с симуляции волос Лары последовательностью вычислительных шедеров. Первая часть Tomb Raider использовала технологию под названием TressFX, а в сиквеле Crystal Dynamics реализовала улучшенную технологию. После первоначальных вычислений получается целых 7 буферов. Все они используются для управления волосами Лары. Процесс выполняется следующим образом:
- Запуск вычислительного шейдера для вычисления значений движения на основе предыдущих и текущий позиций (для motion blur)
- Запуск вычислительного шейдера для заполнения кубической карты светимости размером 1×1 на основе зонда отражений и информации светимости (освещения)
- Создание примерно 122 тысяч вершин в режиме полос треугольников (Triangle Strip) (каждая прядь волос — это полоса). Здесь нет никакого буфера вершин, как можно было бы ожидать при обычных вызовах отрисовки. Вместо них есть 7 буферов, содержащих всё необходимое для построения волос. Пиксельный шейдер выполняет ручную обрезку, если пиксель находится за пределами окна, то отбрасывается. Этот проход помечает стенсил как «содержащий волосы».
- Проход освещения/тумана рендерит полноэкранный quad со включенным тестированием стенсила, чтобы вычислялись только те пиксели, в которых действительно видны волосы. По сути, он считает волосы непрозрачнми и ограничивает затенение только теми прядями, которые видны на экране.
- Также есть финальный проход наподобие этапа 4, который выводит только глубину волос (выполняет копирование из текстуры «глубины волос»)
Если вам интересно узнать об этом подробнее, то у AMD есть множество ресурсов и презентаций, потому что это созданная компанией библиотека общего пользования. Меня сбил с толку этап перед этапом 1, в котором выполняется тот же вызов отрисовки, что и на этапе 3, при этом говорится, что он рендерит только в значения глубины, но на самом деле содержимое не рендерится, и это любопытно; возможно, Renderdoc мне чего-то недоговаривает. Я подозреваю, что он, возможно, пытался выполнить условный запрос рендеринга, но я не вижу никаких вызовов прогнозирования.

Волосы до

Видимые пиксели волос

Волосы с затенением
Тайловый рендеринг альфа-данных и частицы
Прозрачные объекты снова используют потайловую классификацию источников освещения, вычисленную для тайлового предварительного прохода освещения. Каждый прозрачный объект вычисляет собственное освещение в одном проходе, то есть количество инструкций и циклов становится довольно пугающим (именно поэтому для непрозрачных объектов и использовался предварительный проход освещения). Прозрачные объекты могут даже выполнять отражения в экранном пространстве, если они включены! Каждый объект рендерится в порядке сортировки сзади вперёд непосредственно в HDR-буфер, в том числе стекло, пламя, вода в колеях и т.д. Альфа-проход также рендерит подсветку краёв, когда Лара фокусируется на каком-то объекте (например, на бутылке с горючей смесью на ящике слева).

Однако частицы рендерятся в буфер половинного разрешения, чтобы сгладить огромную нагрузку на полосу пропускания, создаваемую их перерисовкой, особенно когда множество крупных, закрывающих экран частиц используется для создания тумана, мглы, пламени и т.д. Поэтому HDR-буфер и буфер глубин уменьшаются в половину по каждой из сторон, после чего начинается рендеринг частиц. Частицы создают огромный объём перерисовки, некоторые пиксели затеняются примерно 40 раз. На тепловой карте видно, что я имею в виду. Так как частицы рендерились в половинном разрешении, здесь используется тот же умный трюк с повышением масштаба, что и в окружающем освещении (в стенсиле помечаются разрывы, первый проход выполняет рендеринг во внутренние пиксели, второй воссоздаёт края). Можно заметить, что частицы рендерятся до некоторых других альфа-эффектов, таких как пламя, сияние и т.д. Это необходимо, чтобы альфу можно было правильно сортировать относительно, например, дыма. Также можно заметить, что здесь появляются «объёмные» лучи света, идущие от охранных прожекторов. Они добавляются здесь, а не создаются на этапе объёмного освещения. Это малозатратный, но реалистичный способ создания их на большом расстоянии.

Только непрозрачные объекты

Первый альфа-проход

Частицы половинного разрешения 1

Частицы половинного разрешения 2

Частицы половинного разрешения 3

Увеличение масштаба внутренних частей

Увеличение масштаба краёв

Полные альфа-данные
Выдержка и тональная коррекция
ROTR выполняет выдержку и тональную коррекцию за один проход. Однако хотя мы обычно считаем, что при тональной коррекции происходит гамма-коррекция, здесь это не так. Есть множество способов реализации выдержки, как мы это видели на примере других игр. Вычисление яркости (luminance) в ROTR выполняется очень интересно и не требует почти никаких промежуточных данных или проходов, поэтому мы объясним этот процесс подробнее. Весь экран разделяется на тайлы 64×64, после чего запускается вычисление групп (20, 12, 1) по 256 потоков в каждой для заполнения всего экрана. Каждый поток по сути выполняет следующую задачу (ниже представлен псевдокод):
for(int i = 0; i < 16; ++i) { uint2 iCoord = CalculateCoord(threadID, i, j); // Obtain coordinate float3 hdrValue = Load(hdrTexture, iCoord.xyz); // Read HDR float maxHDRValue = max3(hdrValue); // Find max component float minHDRValue = min3(hdrValue); // Find min component float clampedAverage = max(0.0, (maxHDRValue + minHDRValue) / 2.0); float logAverage = log(clampedAverage); // Natural logarithm sumLogAverage += logAverage; }
Каждая группа вычисляет логарифмическую сумму всех 64 пикселей (256 потоков, каждый из которых обрабатывает 16 значений). Вместо того, чтобы хранить среднее значение, она сохраняет сумму и количество действительно обработанных пикселей (не все группы обработают ровно 64×64 пикселя, потому что, например, могут выходить за края экрана). Шейдер с умом использует локальное хранилище потока для разделения суммы; каждый поток сначала работает с 16 горизонтальными значениями, а затем отдельные потоки суммируют все эти значения по вертикали, и наконец управляющий поток этой группы (поток 0) складывает результат и сохраняет их все в буфер. Этот буфер содержит 240 элементов, по сути давая нам среднюю яркость множества областей экрана. Последующая команда запускает 64 потока, которые обходят в цикле все эти значения и складывают их, чтобы получить окончательную яркость экрана. Также он возвращается обратно от логарифма к линейным единицам измерения.
У меня нет большого опыта работы с техниками выдержки, но чтение этого поста Кшиштофа Нарковича прояснило некоторые вещи. Сохранение в массив из 64 элементов необходимо для вычисления скользящего среднего, при котором можно просматривать предыдущие вычисленные значения и сглаживать кривую, чтобы избегать очень резких изменений яркости, создающих резкие изменения выдержки. Это очень сложный шейдер и я ещё не разобрался во всех его подробностях, но конечным результатом является соответствующее текущему кадру значение выдержки.
После нахождения адекватных значений выдержки один проход выполняет финальную выдержку плюс тональную коррекцию. Похоже, что в ROTR используется фотографическая тональная коррекция (Photographic Tonemapping), что объясняет использование логарифмических средних значений вместо обычных средних. Формулу тональной коррекции в шейдере (после выдержки) можно развернуть следующим образом:
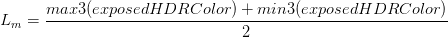

Краткое объяснение можно найти здесь. Я не смог разобраться, зачем нужно дополнительное деление на Lm, ведь оно отменяет влияние умножения. В любом случае whitePoint равно 1.0, поэтому процесс делает не очень много в этом кадре, изображение изменяет только выдержка. Здесь даже не происходит ограничение значений пределами интервала LDR! Оно происходит во время цветокоррекции, когда цветовой куб косвенно ограничивает значения больше 1.0.

Выдержка до

Выдержка после
Блики объектива
Блики объектива (Lens Flares) рендерятся интересным образом. Небольшой предварительный проход вычисляет текстуру размером 1xN (где N — это общее количество элементов бликов, которые будут рендериться как блики объектива, в нашем случае их 28). Эта текстура содержит альфа-значение для частицы и некую другую неиспользуемую информацию, но вместо вычисления её из запроса видимости или чего-то подобного, движок вычисляет её, анализируя буфер глубин вокруг частицы в круге. Для этого информация о вершинах хранится в буфере, доступном для пиксельного шейдера.

Затем каждый элемент рендерится как простые выровненные относительно экрана плоскости, испускаемые из источников освещения. Если альфа-значение меньше 0.01, то позиции присваивается значение NaN, чтобы эта частица не растеризировалась. Они немного походят на эффект bloom и добавляют свечения, но сам этот эффект создаётся позже.

Lens Flares до

Элементы Lens Flare

Lens Flares после
Bloom
В Bloom используется стандартный подход: выполняется даунсэмплинг HDR-буфера, яркие пиксели изолируются, а затем их масштаб последовательно увеличивается с размытием, чтобы расширить область их влияния. Результат увеличивается до разрешения экрана и композитингом накладывается поверх него. Здесь есть пара интересных моментов, стоящих исследования. Весь процесс выполняется с помощью 7 вычислительных шейдеров: 2 для даунсэмплинга, 1 для простого размытия, 4 для увеличения масштаба.
- Первый даунсэмплинг из полного в половинное разрешение выбирает пиксели ярче заданного порогового значения и выводит их в target половинного разрешения (mip 1). Также он пользуется возможностью и одновременно выполняет размытие. Можно заметить, что первая mip-текстура становится только немного темнее, потому что мы отбросили пиксели с довольно низким пороговым значением 0.02.
- Следующий шейдер даунсэмплинга берёт mip и создаёт за один проход mip 2, 3, 4 и 5.
- Следующий проход за один проход размывает mip 5. Во всём этом процессе нет отделимых операций размытия, которые мы иногда встречали. Все операции размытия пользуются групповой общей памятью, чтобы шейдер брал как можно меньше сэмплов и повторно используют данные своих соседей.
- Увеличение масштаба — тоже интересный процесс. Эти 3 прохода увеличения масштаба используют одинаковый шейдер и берут две текстуры, ранее размытую mip N и не размытую mip N + 1, смешивая их вместе с передаваемым снаружи коэффициентом, в тоже время размывая их. Это позволяет добавить в bloom более точные детали подсветки вместо тех, которые могут исчезнуть при размытии.
- Финальное увеличение масштаба увеличивает mip 1 и прибавляет его к финальному HDR-буферу, умножая результат на контролируемую силу bloom.

Bloom до

MIP 1 уменьшенного масштаба Bloom

MIP 2 уменьшенного масштаба Bloom

MIP 3 уменьшенного масштаба Bloom

MIP 4 уменьшенного масштаба Bloom

MIP 5 уменьшенного масштаба Bloom

Размытие MIP 5 эффекта Bloom

MIP 4 увеличенного масштаба Bloom

MIP 3 увеличенного масштаба Bloom

MIP 2 увеличенного масштаба Bloom

MIP 1 увеличенного масштаба Bloom

Bloom после
Любопытный аспект заключается в том, что текстуры уменьшенного масштаба изменяют соотношение сторон. Ради визуализации я их подправил, и могу только догадываться о причинах этого; возможно, это сделано для того, чтобы размеры текстур были кратны 16. Ещё один любопытный момент: так как эти шейдеры обычно очень ограничены полосой пропускания, хранящиеся в групповой общей памяти значения преобразуются из float32 в float16! Это позволяет шейдеру обменять математические операции на удвоение свободной памяти и полосы пропускания. Чтобы это стало проблемой, интервал значений должен стать довольно большим.
FXAA
ROTR поддерживает широкий ассортимент различных техник сглаживания (антиалиасинга), например FXAA (Fast Approximate AA) и SSAA (Super Sampling AA). Примечательно отсутствие опции включения temporal AA, потому что для большинства современных AAA-игр оно становится стандартным. Как бы то ни было, FXAA справляется со своей задачей замечательно, SSAA тоже работает неплохо, это довольно «тяжёлая» опция, если игре не хватает производительности.
Motion Blur
Похоже, что Motion blur (размытие в движении) использует подход, очень схожий с решение в Shadows of Mordor. После рендеринга объёмного освещения отдельный проход рендеринга выводит векторы движения из анимированных объектов в буфер движений. Затем этот буфер комбинируется с движением, вызванным камерой, а финальный буфер движений становится входными данным для прохода размытия, который выполняет размытие в направлении, указываемом векторами движения экранного пространства. Для оценки радиуса размытия за несколько проходов вычисляется текстура векторов движения в уменьшенном масштабе, чтобы каждый пиксель имел приблизительное представление о том, какое движение происходит по соседству с ним. Размытие выполняется за несколько проходов при половинном разрешении и, как мы видели, позже его масштаб с помощью стенсила увеличивается в два прохода. Несколько проходов выполняется по двум причинам: во-первых, чтобы уменьшить количество операций считывания текстур, необходимых для создания размытия с потенциально очень большим радиусом, во-вторых, потому что выполняются разные виды размытия. Это зависит от того, находился ли на текущих пикселях анимированный персонаж.

Motion Blur до

Скорость Motion Blur

Motion Blur, проход 1

Motion Blur, проход 2

Motion Blur, проход 3

Motion Blur, проход 4

Motion Blur, проход 5

Motion Blur, проход 6

Motion Blur, увеличение масштаба внутренних частей

Motion Blur, увеличение масштаба краёв
Дополнительные особенности и детали
Есть ещё несколько вещей, которые стоит упомянуть без особых подробностей.
- Заморозка камеры: при холодной погоде добавляет на камеру снежинки и иней
- Грязная камера: добавляет на камеру грязь
- Цветокоррекция: в конце кадра выполняется небольшая цветокоррекция, использующая довольно стандартный цветовой куб для выполнения цветокоррекции, как это описано выше, а также добавляет шума, чтобы придать некоторым сценам суровости
UI
UI реализован немного необычно — он рендерит все элементы в линейном пространстве. Обычно ко времени рендеринга UI уже выполнила тональную коррекцию и гамма-коррекцию. Однако ROTR использует линейное пространство вплоть до самого конца кадра. Это имеет смысл, ведь в игре используется напоминающий 3D UI; однако перед записью в HDR-буфер sRGB-изображений их необходимо преобразовать в линейное пространство, чтобы самая последняя операция (гамма-коррекция) не искажала цветов.
Подведём итоги
Надеюсь, вам понравилось чтение этого анализа так же, как мне его создание. Лично я точно многому из него научился. Поздравляю талантливых разработчиков из Crystal Dynamics с фантастической работой, проделанной для создания этого движка. Также хочу поблагодарить Балдура Карлссона за его фантастическую работу над Renderdoc. Его труд сделал отладку графики на PC гораздо более удобным процессом. Думаю, единственное, что было немного сложным в этом анализе — отслеживание самих запусков шейдеров, потому что на момент написания статьи эта функция недоступна для DX12. Надеюсь, со временем она появится и все мы будем очень довольны.

