
DeepMind, дочерняя компания Alphabet, которая занимается исследованиями в области искусственного интеллекта, объявила о новой вехе в этом грандиозном квесте: впервые ИИ обыграл человека в стратегии Starcraft II. В декабре 2018 года свёрточная нейросеть под названием AlphaStar размазала профессиональных игроков TLO (Дарио Вюнш, Германия) и MaNa (Гжегож Коминц, Польша), одержав десять побед. Об этом событии компания объявила вчера в прямой трансляции на YouTube и Twitch.
В обоих случаях и люди, и программа играли за протоссов. Хотя TLO не специализируется на этой расе, но зато MaNa оказал серьёзное сопротивления, а потом даже выиграл одну игру.
В популярной стратегии реального времени игроки представляют одну из трёх рас, которые конкурируют за ресурсы, строят структуры и сражаются на большой карте. Важно отметить, что скорость действия программы и её область видимости на поле боя были ограничены, чтобы AlphaStar не получила несправедливого преимущества над людьми (поправка: судя по всему, область видимости ограничили только в последнем матче). Собственно, по статистике программа даже совершала меньше действий в минуту, чем люди: в среднем 277 у AlphaStar, 390 у MaNa, 678 у TLO.

На видео показан вид игры с точки зрения агента ИИ во втором матче против MaNa. Вид со стороны человека тоже показан, но он был недоступен для программы.
AlphaStar обучалась играть за протоссов в среде под названием AlphaStar League. Сначала нейросеть трое суток просматривала записи игр, затем играла сама с собой, используя технику, известную как обучение с подкреплением, оттачивая навыки.
В декабре сначала организовали игровую сессию против TLO, в которой было проверено пять разных версий AlphaStar. По этому поводу TLO пожаловался, что никак не мог приспособиться к игре противника. Программа выиграла со счётом 5−0.
После оптимизации настроек нейросети через неделю был организован матч против MaNa. Программа опять выиграла пять игр, но MaNa взял реванш в последней игре против самой новой версии алгоритма в прямом эфире, так что ему есть чем гордиться.
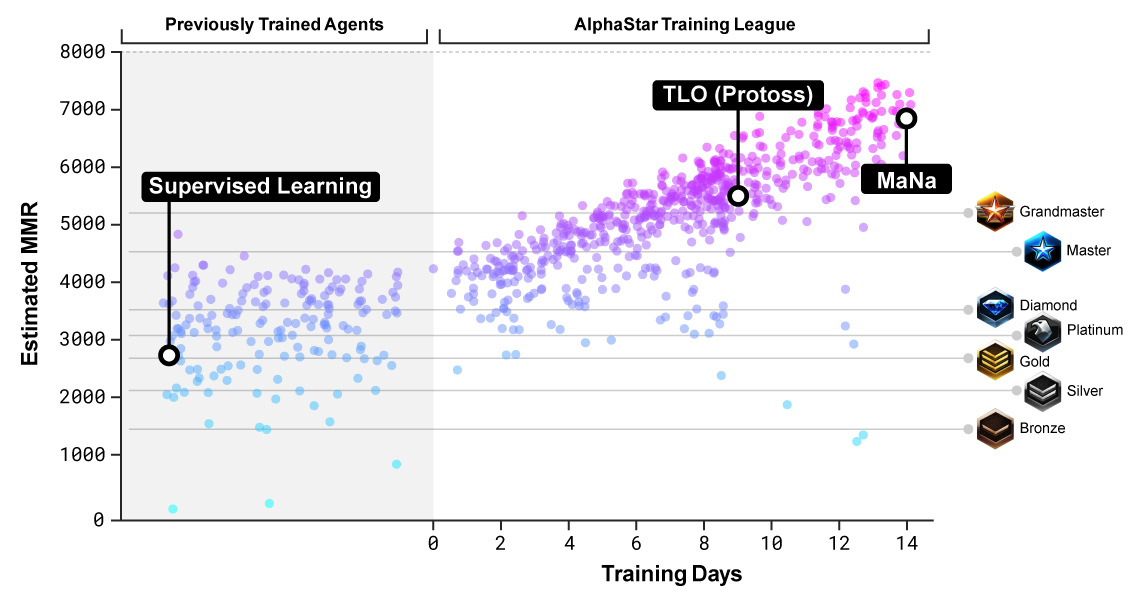
Оценка уровня противников, на которых обучалась нейросеть
Чтобы понять принципы стратегического планирования, AlphaStar должна была освоить особое мышление. Методы, разработанные для этой игры, потенциально могут оказаться полезными во многих практических ситуациях, когда требуется сложная стратегия: например, торговля или военное планирование.
Starcraft II — не только чрезвычайно сложная игра. Это также игра с неполной информацией, где игроки не всегда могут видеть действия своего противника. В ней также нет оптимальной стратегии. И требуется время, чтобы стали понятны результаты действий игрока: это тоже затрудняет обучение. Команда DeepMind использовала очень специализированную архитектуру нейронных сетей для решения этих проблем.
Ограниченность обучения на играх
DeepMind известна как разработчик программного обеспечения, которые обыграли лучших в мире профессионалов по го и шахматам. До этого компания разработала несколько алгоритмов, которые научились играть в простые игры Atari. Видеоигры — это отличный способ измерить прогресс в области искусственного интеллекта и сравнить компьютеры с людьми. Впрочем, это очень узкая область тестирования. Как и предыдущие программы, AlphaStar выполняет только одну задачу, хотя и невероятно хорошо.
Можно сказать, что слабый ИИ узкого назначения освоил навыки стратегического планирования и тактики боевых действий. Теоретически, эти навыки могут пригодиться в реальном мире. Но на практике это не обязательно так.
Некоторые эксперты считают, что подобные узкоспециализированные применения ИИ не имеют ничего общего с сильным ИИ: «Программы, которые научились мастерски играть в конкретную видеоигру или настольную игру на «сверхчеловеческом» уровне, полностью теряются при малейшем изменении условий (изменение фона на экране или изменение положения виртуальной «площадки» для отбивания «шарика»), — пишет профессор компьютерных наук в Портлендском государственном университете Мелани Митчелл в статье «Искусственный интеллект упёрся в барьер понимания». — Это лишь несколько примеров, демонстрирующих ненадёжность лучших программ ИИ, если ситуация немного отличаются от тех, на которых они обучались. Ошибки этих систем варьируются от смешных и безвредных до потенциально катастрофических».
Профессор считает, что гонка по коммерциализации ИИ оказала огромное давление на исследователей по созданию систем, которые работают «достаточно хорошо» в узких задачах. Но в конечном счёте развитие надёжного ИИ требует более глубокого изучения наших собственных способностей и нового понимания когнитивных механизмов, которые мы сами используем:
Наше собственное понимание ситуаций, с которыми мы сталкиваемся, основано на широких интуитивных «понятиях здравого смысла» о том, как работает мир, и о целях, мотивах и вероятном поведении других живых существ, особенно других людей. Кроме того, наше понимание мира опирается на наши основные способности обобщать то, что мы знаем, формировать абстрактные концепции и проводить аналогии — короче говоря, гибко адаптировать наши концепции к новым ситуациям. На протяжении десятилетий исследователи экспериментировали с обучением ИИ интуитивному здравому смыслу и устойчивым человеческим способностям к обобщению, но в этом очень трудном деле мало прогресса.
Нейросеть AlphaStar пока умеет играть только за протоссов. Разработчики заявили о планах обучить её в будущем играть и за другие расы.

