Эта статья расшифровка видеодоклада Алексея Вахова из Учи.ру «Облака в облаках»
Учи.ру — онлайн-платформа для школьного образования, более 2 миллионов школьников, регулярно решают у нас интерактивные занятия. Все наши проекты хостятся полностью в публичных облаках, 100% приложений работают в контейнерах, начиная от самых маленьких, для внутреннего пользования, и заканчивая крупными продакшенами на 1k+ запросов в секунду. Так получилось, что у нас 15 изолированных докер-кластеров (не Kubernetes, sic!) в пяти облачных провайдерах. Полторы сотни пользовательских приложений, количество которых постоянно растет.
Я буду рассказывать очень конкретные вещи: как мы переходили на контейнеры, как управляемся с инфраструктурой, проблемы с которыми столкнулись, что заработало, а что нет.
В процессе доклада мы обсудим:
- Мотивацию выбора технологий и особенности бизнеса
- Инструменты: Ansible, Terraform, Docker, Github Flow, Consul, Nomad, Prometheus, Shaman — web-интерфейс для Nomad.
- Использовании федерации кластеров для управления распределенной инфраструктурой
- NoOps выкатки, тестовые окружения, схемы приложения (практически все изменения девелоперы делают самостоятельно)
- Занимательные истории из практики
Кому интересно, прошу под кат.
Меня зовут Алексей Вахов. Я работаю техническим директором в компании Учи.ру. Мы хостимся в публичных облаках. Активно используем Terraform, Ansible. С тех пор мы полностью перешли на Docker. Очень довольны. Насколько довольны, как мы довольны — буду рассказывать.

Компания Учи.ру занимается производством продуктов для школьного образования. У нас есть основная платформа, на которой дети решают интерактивные задачи по разным предметам в России, в Бразилии, в США. Мы проводим онлайн олимпиады, конкурсы, кружки, лагеря. С каждым годом эта активность растет.

С точки зрения инженерии классический веб-стек (Ruby, Python, NodeJS, Nginx, Redis, ELK, PostgreSQL). Основная особенность, что много приложений. Приложения размещаются по всему миру. Каждый день идут выкатки в production.
Вторая особенность — у нас очень часто меняются схемы. Просят поднять новое приложение, старое остановить, добавить cron для background jobs. Каждые 2 недели идет новая олимпиада — это новое приложение. Это все нужно сопровождать, мониторить, бекапить. Поэтому окружение супердинамическое. Динамичность это наша основная сложность.
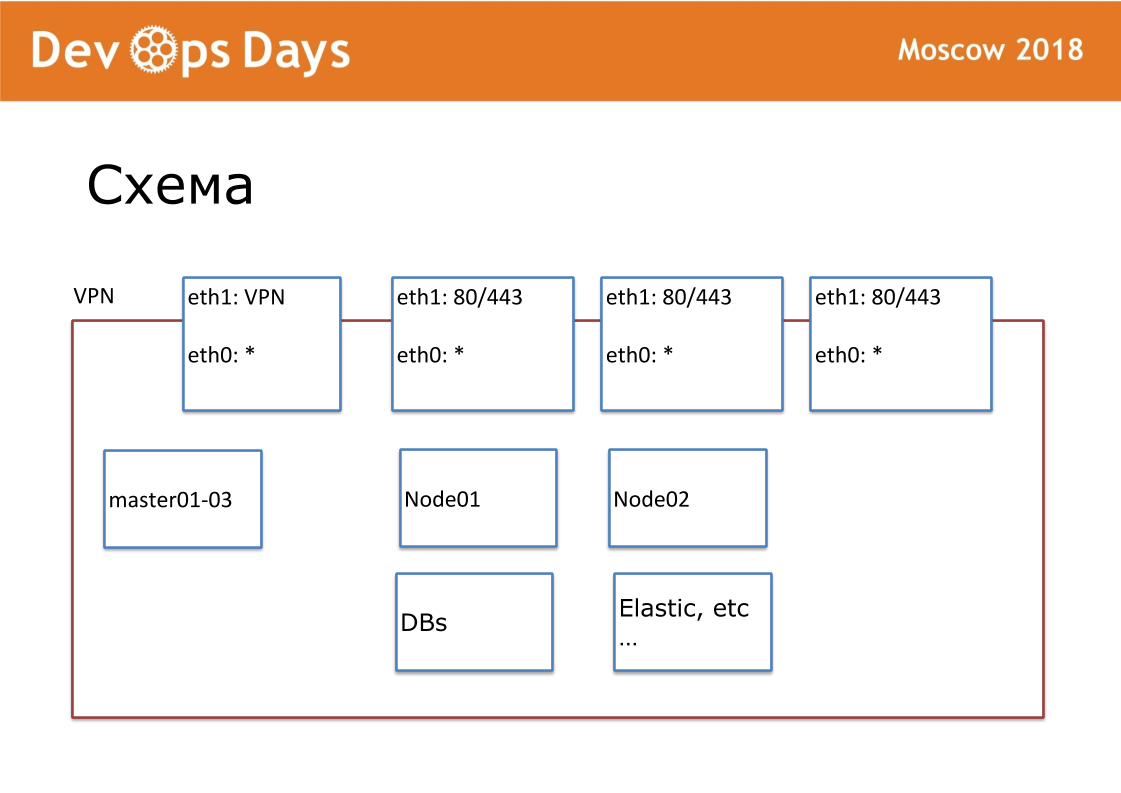
Рабочей единицей у нас является площадка. В терминах облачных провайдеров это Project. Наша площадка это полностью изолированная сущность с API и приватной подсетью. Когда мы заходим в страну, мы ищем местные облачные провайдеры. Не везде есть Google и Amazon. Иногда бывают что отсутствует API к облачному провайдеру. Наружу публикуем VPN и HTTP, HTTPS на балансеры. Все остальные сервисы общаются внутри облака.

Под каждую площадку у нас создан свой Ansible репозиторий. В репозитории есть hosts.yml, playbook, роли и 3 тайных папки, про которые дальше буду рассказывать. Это terraform, provision, routing. Мы фанаты стандартизации. У нас репозиторий должен всегда называться "ansible-имя площадки". Каждое название файла, внутреннюю структуру мы стандартизируем. Это очень важно для дальнейшей автоматизации.

Terraform полтора года назад настроили, так им и пользуемся. Terraform без модулей, без файловой структуры (используется плоская структура). Файловая структура terraform: 1 сервер — 1 файл, настройка сети и другие настройки. С помощью terraform мы описываем сервера, диски, домены, s3-бакеты, сети и так далее. Terraform на площадке полностью готовит железо.

Терраформ создает сервера, затем ансибл эти сервера накатывает. Из-за того что у нас везде используется одна и таже версия операционной системы, то мы все роли написали с нуля. В интернете обычно публикуются Ansible роли под все операционные системы, которые не работают нигде. Мы все взяли Ansible роли и оставили только то что нам нужно. Стандартизировали Ansible роли. У нас 6 базовых playbook. При запуске Ansible устанавливает стандартный список ПО: OpenVPN, PostgreSQL, Nginx, Docker. Kubernetes мы не используем.

Мы используем Consul + Nomad. Это очень простые программы. Запускаются 2 программы, написанные на Golang на каждом сервере. Consul отвечает за Service Discovery, health check и key-value для хранения конфигурации. Nomad отвечает за scheduling, за выкатку. Nomad запускает контейнеры, обеспечивает выкатки, в том числе rolling-update по health check, позволяет запускать sidecar-контейнеры. Кластер легко расширять или наоборот уменьшать. Nomad поддерживает распределенный Cron.
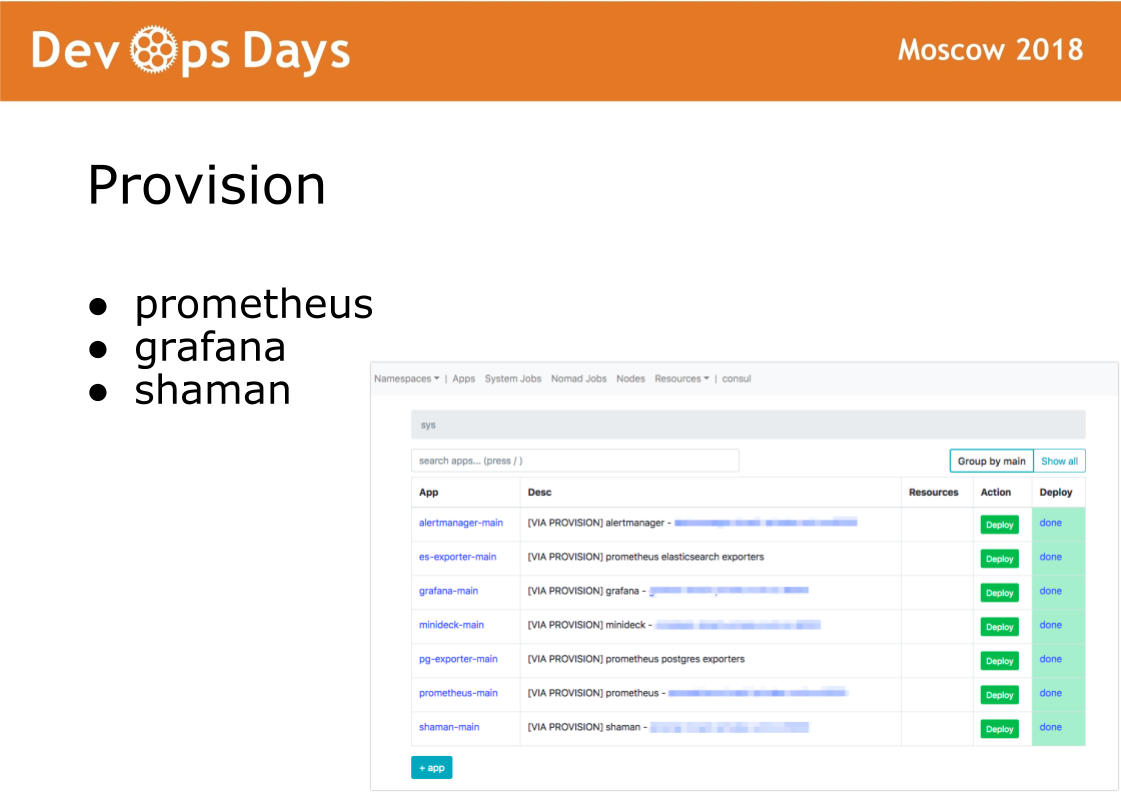
После того как мы зашли в площадку, Ansible выполняет playbook, расположенные в директории provision. Playbook в этой директории отвечают за установку программного обеспечения в docker кластер, который используют администраторы. Устанавливаются prometheus, grafana и тайный софт shaman.
Shaman это Web-dashboard для nomad. Nomad низкоуровневый и к нему пускать разработчиков не очень хочется. В shaman видим список приложений, разработчикам выдаем кнопку деплоя приложений. Разработчики могут менять конфигурации: добавлять контейнеры, переменные окружения, заводить сервисы.
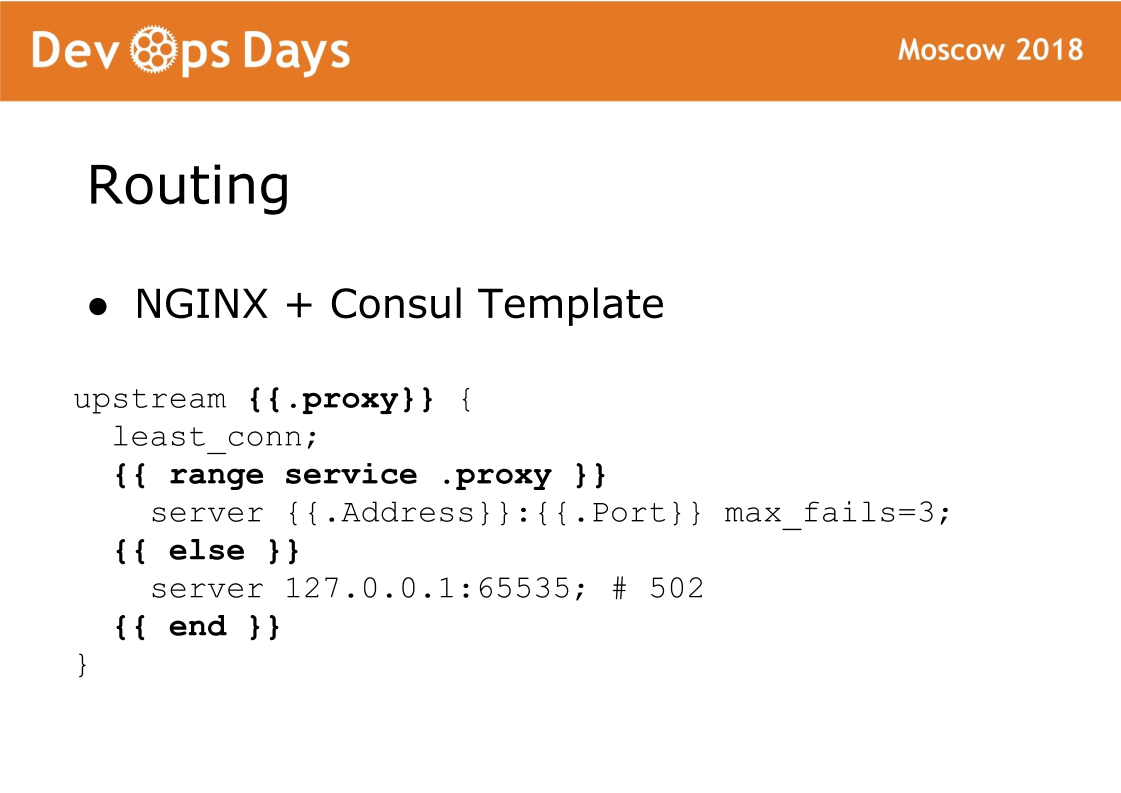
И наконец финальный компонент площадки — это routing. Routing у нас хранится в K/V хранилище консула, то есть там связка между upstream, service, url и тд. На каждом балансере крутится Consul template, который генерит конфиг nginx и делает его reload. Очень надежная штука, у нас не было никогда с ней проблем. Фишка такой схемы, что трафик принимает стандартный nginx и всегда можно посмотреть какой конфиг сгенерировался и работать как со стандартным nginx.

Таким образом каждая площадка состоит из 5 слоев. С помощью terraform'а мы настраиваем железо. Ansible'ом проводим базовую настройку серверов, ставим docker-кластер. Provision закатывает системный софт. Routing направляет трафик внутри площадки. Applications содержит приложения пользователей и приложения администраторов.
Мы довольно долго отлаживали эти слои, чтобы они были максимально одинаковые. Provision, routing совпадают 100% между площадками. Поэтому и для девелоперов каждая площадка абсолютно одинаковая.
Если ИТ-специалисты переключается с проекта на проект, то попадают в полностью типовое окружение. В ansible мы не смогли сделать идентичными настройки firewall, VPN для разных облачных провайдеров. С сетью все облачные провайдеры работают по-разному. Terraform везде свой, потому что он содержит специфичные конструкции для каждого облачного провайдера.
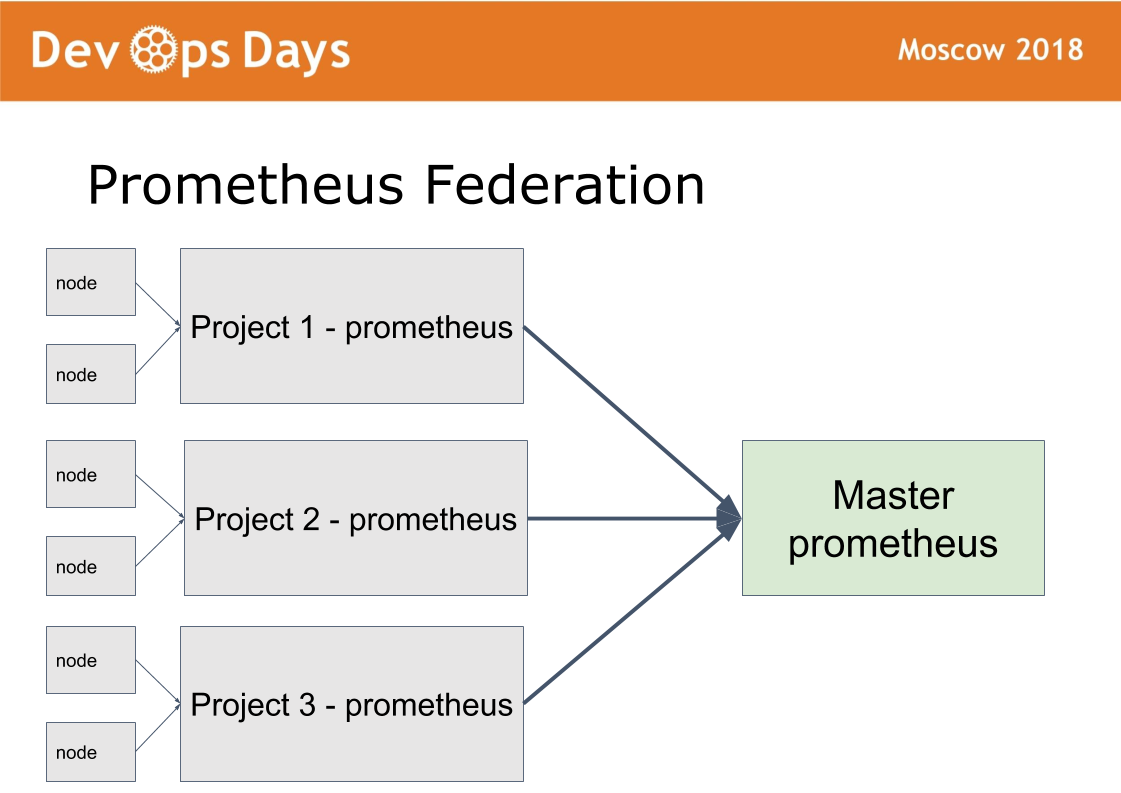
У нас 14 production площадок. Возникает вопрос: как ими управлять? Мы сделали 15-ую мастер площадку, в которую пускаем только админов. Она работает по схеме федерации.
Идею взяли из prometheus. В prometheus есть режим, когда в каждой площадке устанавливаем prometheus. Prometheus публикуем наружу через HTTPS basic auth авторизацию. Prometheus мастер забирает только нужные метрики c удаленных prometheus. Это дает возможность сравнить метрики приложения в разных облаках, найти самые загруженные или незагруженные приложения. Централизованное оповещение (alerting) идет через мастер prometheus для админов. Разработчики получают оповещения от локальных prometheus.
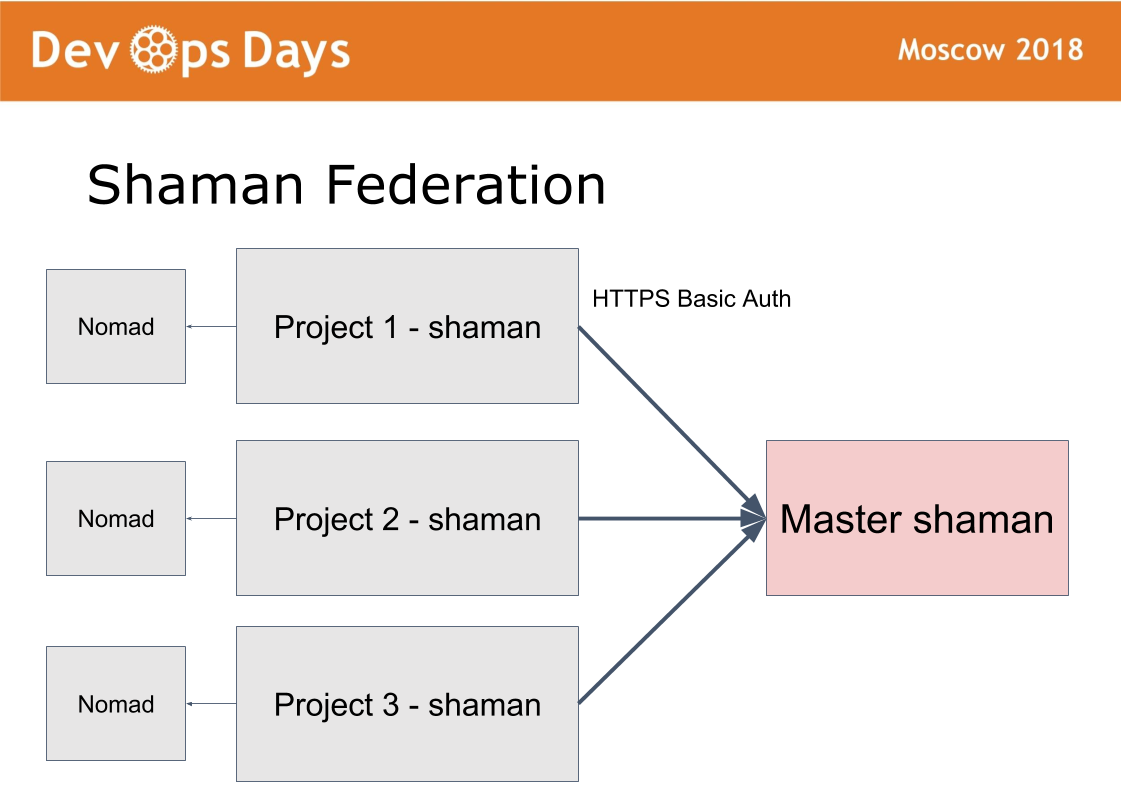
По такой же схеме настроен shaman. Через главную площадку администраторы могут деплоить, конфигурировать на любой площадке через единый интерфейс. Достаточно большой класс задач решаем не выходя с этой master площадки.

Расскажу, как мы переходили на docker. Этот процесс очень небыстрый. Мы переходили примерно 10 месяцев. Летом 2017 года у нас было 0 контейнеров production. В апреле 2018 мы докеризировали и выкатили в production последнее наше приложение.
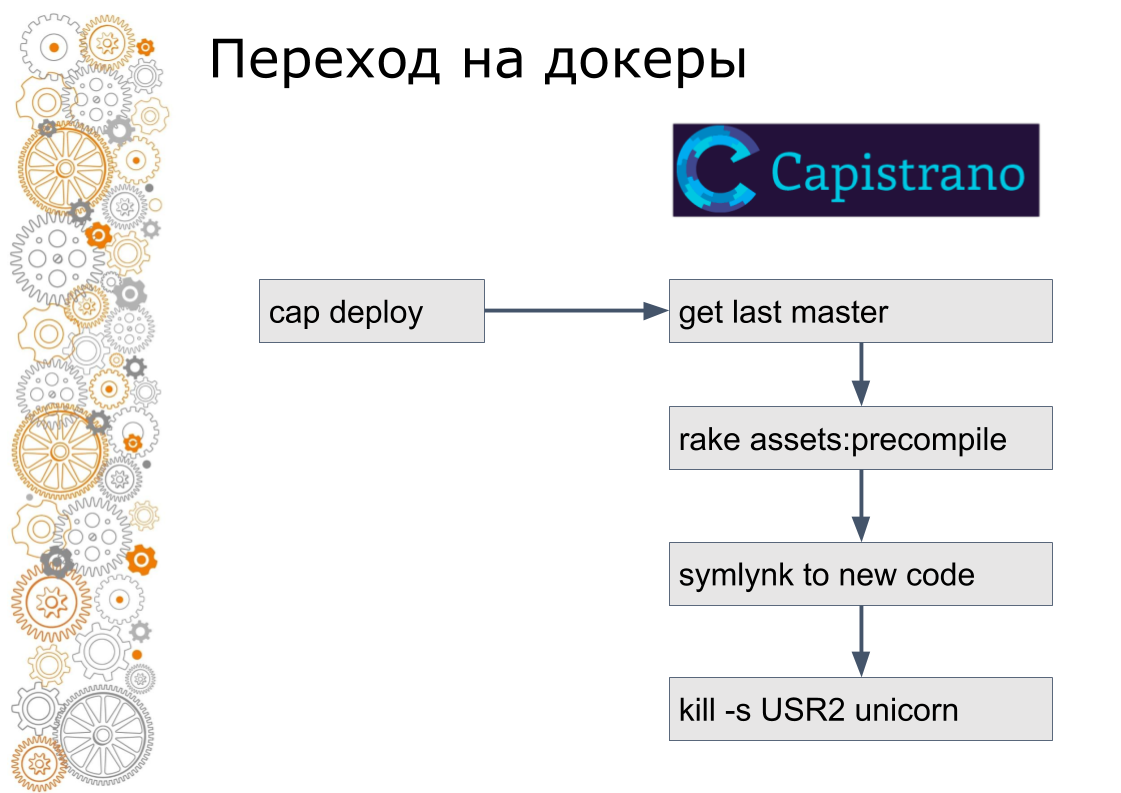
Мы из мира ruby on rails. Раньше было 99% приложений Ruby on Rails. Rails выкатывается через Capistrano. Технически Capistrano работает следующим образом: разработчик запускает cap deploy, capistrano заходит на все application сервера по ssh, забирает последнюю версию кода, собирает asset, миграции БД. Capistrano делает симлинк на новую версию кода и посылает USR2 сигнал веб-приложению. По этому сигналу веб-сервер подхватывает новый код.
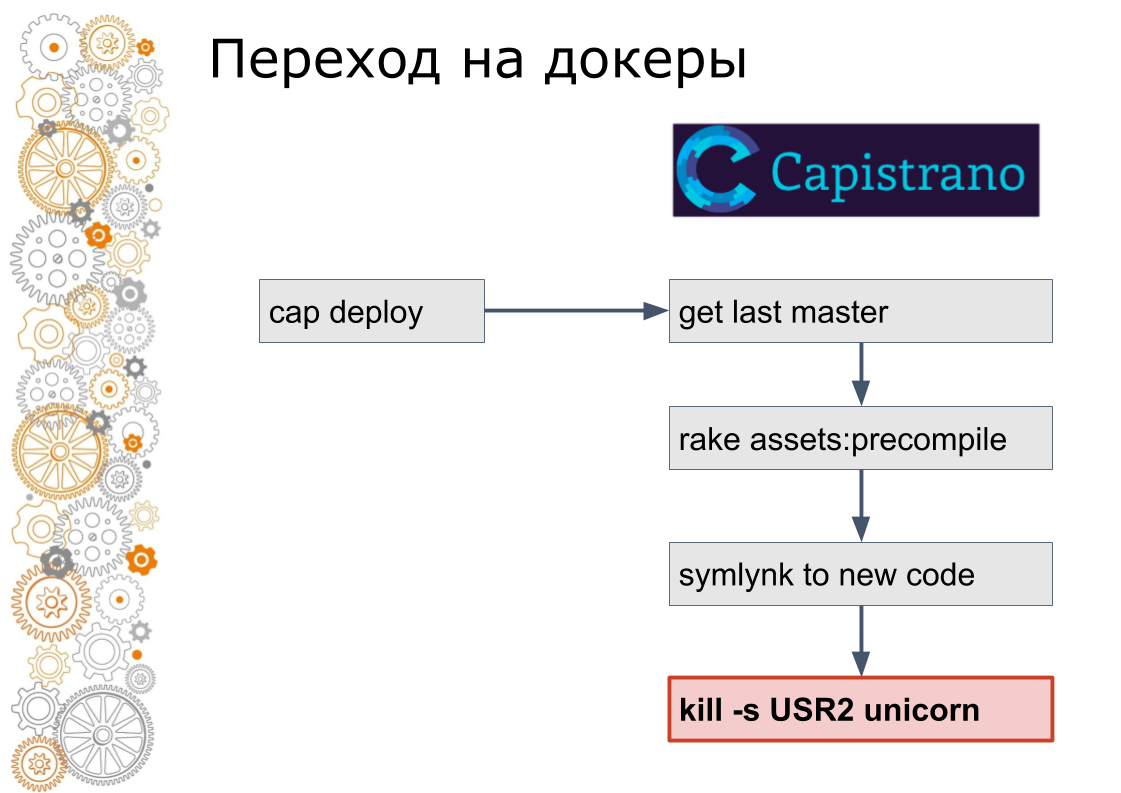
Последний шаг в docker так не делается. В docker нужно старый контейнер остановить, новый контейнер поднять. Тут возникает вопрос: как переключать трафик? В облачном мире за это отвечает service discovery.
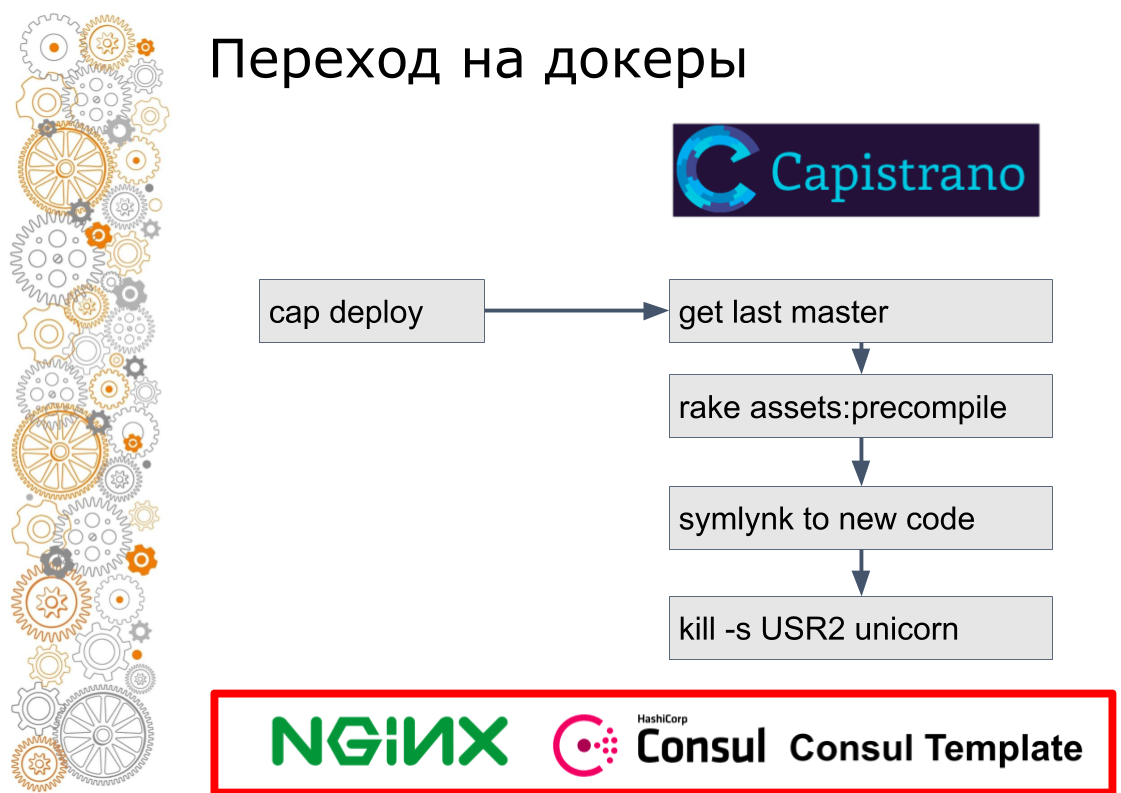
Поэтому мы на каждую площадку добавили consul. Consul добавили потому что использовали Terraform. Все конфиги nginx мы завернули в consul template. Формально то же самое, но уже мы были готовы динамически управлять трафиком внутри площадок.
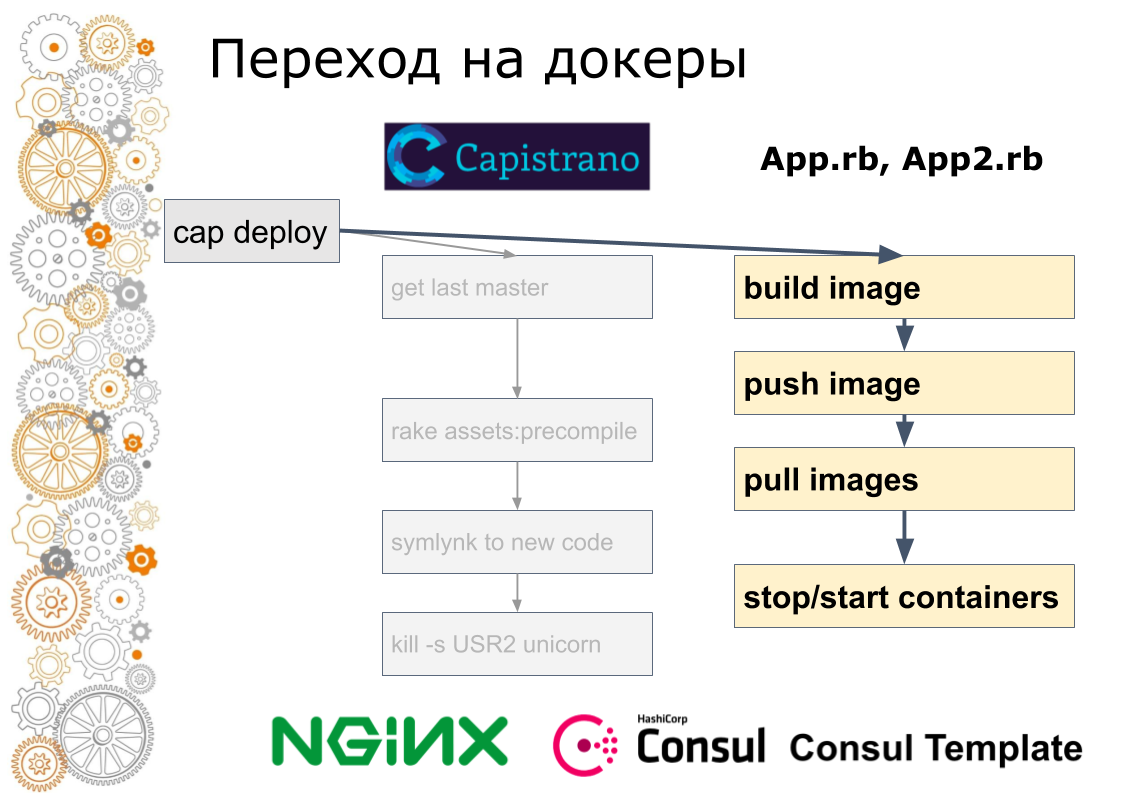
Далее мы написали на ruby скрипт, который на одном из серверов собирал образ, пушил его в реестр, потом заходил по ssh на каждый сервер поднимал новые и останавливал старые контейнеры, регистрируя их в consul'е. Разработчики также продолжали запускать cap deploy, но сервисы уже работали в docker'е.
Я помню что было две версии скрипта, второй получился уже довольно продвинутым, там был роллинг апдейт, когда маленькое количество контейнеров останавливалось, поднимались новые, выжидались консул хелфчеки и двигались дальше.

Потом поняли что это тупиковый способ. Cкрипт увеличился до 600 строк. Следующим шагом ручной шедулинг мы заменили Nomad. Спрятав от разработчика детали работы. То есть они все еще вызывали cap deploy, но внутри была уже совсем другая технология.

И под конец мы перенесли деплой в UI и отняли доступ на сервера, оставив зеленую кнопку деплоя и интерфейс управления.
В принципе такой переход получился конечно долгим, но мы избежали проблемы, которую я встречал довольно много раз.
Есть какой-то легаси стек, система или что-то типа того. Хаченная уже просто в лоскуты. Начинается разработка новой версии. Через пару месяцев или пару лет, в зависимости от размера компании, в новой версии реализовано меньше половину нужного функционала, а старая версия еще убежала в преред. И та новая стала тоже весьма легаси. И пора уже начинать новую, третью версию с нуля. Вообщем это бесконечный процесс.
Поэтому мы всегда двигаем весь стек целиком. Маленьками шажками, кривенько, с костылями, но целиком. У нас нельзя обновить например docker engine на одной площадке. Нужно обновлять везде, раз есть желание.

Выкатки. Все инструкции по docker выкатывают в docker 10 контейнеров nginx, либо 10 контейнеров redis. Это плохой пример, потому что образы уже собраны, образы легкие. Мы запаковали наши rails приложения в docker. Размер docker образов был 2-3 гигабайта. Они выкатыкаются не так быстро.

Вторая проблема пришла от хипстерского веба. Хипстерский веб это всегда Github Flow. В 2011 году был эпохальный был пост что Github Flow рулит, так весь веб и катится. Как это выглядит? Master ветка всегда production. При добавлении нового функционала делаем ветку. При мерже делаем code-review, запускаем тесты, поднимает staging окружение. Бизнес смотрит staging окружение. В момент Х если все успешно, то мы мержим ветку в master и выкатываем в production.
На capistrano это работало отлично, потому что он для этого и был создан. Docker нам всегда продает pipeline. Cобрали контейнер. Контейнер можно передать разработчику, тестеру, передать в production. Но в момент мержа в master код уже другой. Все docker образа, которые собирали из feature-ветки, они собраны не из master.

Как мы сделали? Собираем образ, кладем его в локальный docker registry. И после этого делаем остальные операции: миграции, деплоим в production.

Чтобы быстро этот образ собрать мы используем Docker-in-Docker. В интернете все пишут что это анти-паттерн, он крешится. У нас ничего подобного не было. Сколько уже работает с ним никогда проблем не было. Директорию /var/lib/docker мы пробрасываем на основной сервер, используя Persistent volume. Все промежуточные образы лежат на основном сервере. Сборка нового образа укладывается за несколько минут.

Для каждого приложения делаем локальный внутренний docker registry и свой build volume. Потому что docker сохраняет все слои на диске и их сложно чистить. Сейчас мы знаем дисковую утилизацию кадого локального docker registry. Мы знаем сколько он диска требуют. Можно получать оповещения через централизованную Grafana и чистить. Пока мы их руками чистим. Но будем это автоматизировать.

Еще один момент. Docker-образ собрали. Теперь этот образ нужно разложить по серверам. При копировании большого docker-образа не справляется сеть. В облаке у нас 1 Gbit/s. В облаке происходит глобальный затык. Сейчас мы деплоим docker образ на 4 тяжелых production сервера. На графике видно диск работал на 1 пачке серверов. Затем деплоится вторая пачка серверов. Снизу видно утилизацию канала. Примерно 1 Gbit/s мы почти вытягиваем. Больше там особо особо уже не ускорить.
Мой любимый production это Южная Африка. Там очень дорогое и медленное железо. В четыре раза дороже, чем в России. Там очень плохой интернет. Интернет модемного уровня, но не глючный. Там мы выкатываем приложения за 40 минут с учетом тюнига кешей, параметров таймаутов.

Последняя проблема, которая меня волновала перед тем как связывались docker — это нагрузка. На самом деле нагрузка такая же как и без докера с идентичным железом. Единственный нюанс мы уперлись всего в одну точку. Если из Docker engine собирать логи через встроенный fluentd драйвер, то на нагрузке около 1000 rps начинался замусориваться внутренний буфер fluentd и запросы начинают тормозить. Мы вынесли логирование в sidecar контейнеры. В nomad это называется log-shipper. Рядом с большим контейнером приложения висит небольшой контейнер. Единственная задача его забирать логи и отправлять в централизованное хранилище.

Какие были проблемы/решения/вызовы. Я попытался проанализировать какая была задача. Особенности нашей проблематики это:
- много независимых приложений
- постоянные изменения схемы инфраструктуры
- Github flow и большие docker-образы

Наши решения
- Федерация docker-кластеров. С точки зрения управляемости тяжело. Но docker хорош с точки зрения выкатки бизнес-функционала в production. Мы работаем с персональными данными и у нас в каждой стране сертификация. В изолированной площадке такую сертификацию легко проходить. При сертификации все возникают вопросы: где вы хоститесь, как у вас облачный провайдер, где вы храните персональные данные, куда бекапите, кто имеет доступ данным. Когда все изолировано, то круг подозреваемых описать гораздо легче и следить за всем этим гораздо легче.
- Оркестрация. Понятно что kubernetes. Он везде. Но хочу сказать, что Consul + Nomad — это вполне production решение.
- Сборка образов. Быстро собирать образы в Docker-in-Docker можно.
- При использовании Docker держать нагрузку 1000 rps тоже можно.
Вектор направления развития
Сейчас одна из больших проблем — рассинхронизация версий программного обеспечения на площадках. Раньше мы настраивали сервера руками. Потом мы стали devops-инженерами. Теперь настраиваем сервера с помощью ansible. Cейчас у нас тотальная унификация, стандартизация. Внедряем обычное мышление в голову. У нас нельзя поправить PostgreSQL руками на сервере. Если нужна какая-то тонкая настройка именно на 1 сервер, то думаем как эту настройку распространить везде. Если не стандартизировать, то будет зоопарк настроек.
Я восхищен и очень рад, что мы из коробки бесплатно получаем действительно очень приятную в работе инфраструктуру.

Вы можете добавиться ко мне в facebook. Если мы что-нибудь новое хорошее сделаем, то я об этом напишу.
Вопросы:
В чем преимущество Consul Template перед Ansible Template, например для настройки правил firewall и прочего?
Ответ: Сейчас у нас трафик со внешних балансировщиков идет прямо на контейнеры. Там нет никого промежуточного слоя. Там формируется конфиг, который пробрасывает IP-адреса и порты кластера. Также у нас все настройки балансиров лежат в K/V в Consul. У нас есть идея, чтобы отдать настройки роутинга разработчикам через безопасный интерфейс чтобы они ничего не сломали.
Вопрос: По поводу однородности всех площадок. Неужели не бывает запросов от бизнеса или от разработчиков, что нужно на этой площадке выкатить что-нибудь нестандартное? Например, tarantool с cassandra.
Ответ: Бывает, но это очень большая редкость. Это мы оформляем внутренний отдельный артефакт. Есть такая проблема, но она редкая.
Вопрос: Решение проблемы доставки это использовать приватный docker registry в каждой площадке и оттуда уже быстро получать docker образы.
Ответ: Все равно деплой упрется в сеть, так как мы раскладываем docker образ на там 15 серверов одновременно. Мы упираемся внутри сети. Внутри сети 1 Gbit/s.
Вопрос: Такое огромное количество docker-контейнеров основаны примерно на одном и том же стеке технологий?
Ответ: Ruby, Python, NodeJS.
Вопрос: Как часто вы тестируете или проверяете на обновление свои docker-образы? Как вы решаете проблемы обновления, например, когда glibc, openssl надо починить во всех docker?
Ответ: Если нашли такую ошибку, уязвимость, то садимся на неделю и чиним. Если нужно выкатить, то мы можем выкатить целиком целое облако (все приложения) с нуля церез федерацию. Мы можем прокликать все зеленые кнопки для деплоя приложений и уйти пить чай.
Вопрос: Вы собираетесь свой shaman выпустить в opensource?
Ответ: Вот Андрей (показывает на человека из зала) обещает нам осенью выложить shaman. Но там нужно добавить поддержку kubernetes. Opensource всегда должен быть более качественный.

