 Привет, Хабр! Меня зовут Станислав Семенов, я работаю над технологиями извлечения данных из документов в R&D ABBYY. В этой статье я расскажу об основных подходах к обработке полуструктурированных документов (инвойсы, кассовые чеки и т.д.), которые мы использовали совсем недавно и которые используем прямо сейчас. А еще мы поговорим о том, насколько для решения этой задачи применимы методы машинного обучения.
Привет, Хабр! Меня зовут Станислав Семенов, я работаю над технологиями извлечения данных из документов в R&D ABBYY. В этой статье я расскажу об основных подходах к обработке полуструктурированных документов (инвойсы, кассовые чеки и т.д.), которые мы использовали совсем недавно и которые используем прямо сейчас. А еще мы поговорим о том, насколько для решения этой задачи применимы методы машинного обучения.В качестве документов будем рассматривать инвойсы, т.к. в мире они очень широко распространены и наиболее востребованы в плане извлечения данных. Кстати, автоматическая обработка инвойсов – это один из популярных сценариев у наших зарубежных заказчиков. Например, с помощью ABBYY FlexiCapture американская PepsiCo Imaging Technology сократила время обработки инвойсов и количество ошибок из-за ручного ввода, а европейский ритейлер Sportina в 2 раза быстрее стал вводить данные из счетов в учетные системы.
Инвойсы – это документы, которые используются в международной коммерческой практике и имеют большое значение для бизнеса. Что-то похожее на инвойс в России – это, например, товарная накладная. Данные из таких документов попадают в различные учетные системы, и ошибки там, мягко говоря, не приветствуются.
Обычный инвойс можно считать вполне структурированным, он содержит два основных класса объектов:
- различные поля из заголовка (номер документа, дата, отправитель, получатель, итоговая сумма и т.д.),
- табличные данные – это список товаров и услуг (количество, цена, описание и т.д.).
Вот так он примерно выглядит:

Ежегодно на обработку инвойсов компании расходуют миллионы человеко-часов. И это очень дорого. По разным подсчетам, для компании обработка одного бумажного инвойса обходится от $10 до $40, где значительная часть этих расходов – ручной труд по вводу и выверке данных.
Есть компании, которые обрабатывают миллионы инвойсов в месяц. Для этого они содержат целый штат в сотни, а иногда тысячи человек. Нетрудно оценить, что увеличение точности распознавания или эффективности извлечения данных всего на 1% позволяет сократить издержки крупных компаний в сотни тысяч и даже в миллионы долларов ежегодно.
С другой стороны, документов катастрофически много. В 2017 году компания Billentis оценила общее количество порождаемых за год счетов/инвойсов в мире в 400 миллиардов. Из них только около 10% были электронные, а остальные — требуют полностью ручного ввода или интенсивного участия человека. Если распечатать 400 миллиардов документов на стандартной бумаге в формате A4, то это тысячи грузовиков бумаги в день или стопка бумаги примерно в человеческий рост каждую секунду!
Несколько слов о том, как развивались технологии

Многие компании разрабатывают специализированный софт, который умеет распознавать документы и извлекать из них данные. Но качество обработки инвойсов все еще не идеально. «В чем проблема?» — спросите вы.
Все дело в огромном многообразии инвойсов. К инвойсам не предъявляются стандарты, и каждая компания вольна создавать свой собственный вариант документа: вид, структуру и расположение полей.
Нахождение полей по ключевым словам
Первые попытки извлечения данных сводились к тому, чтобы среди всех распознанных слов находить специальные ключевые — такие, как, например, Invoice Number или Total, а потом в небольшой окрестности этих слов, например, справа или снизу, находить сами значения.
Расположение Invoice Number в разных инвойсах (кликабельно):
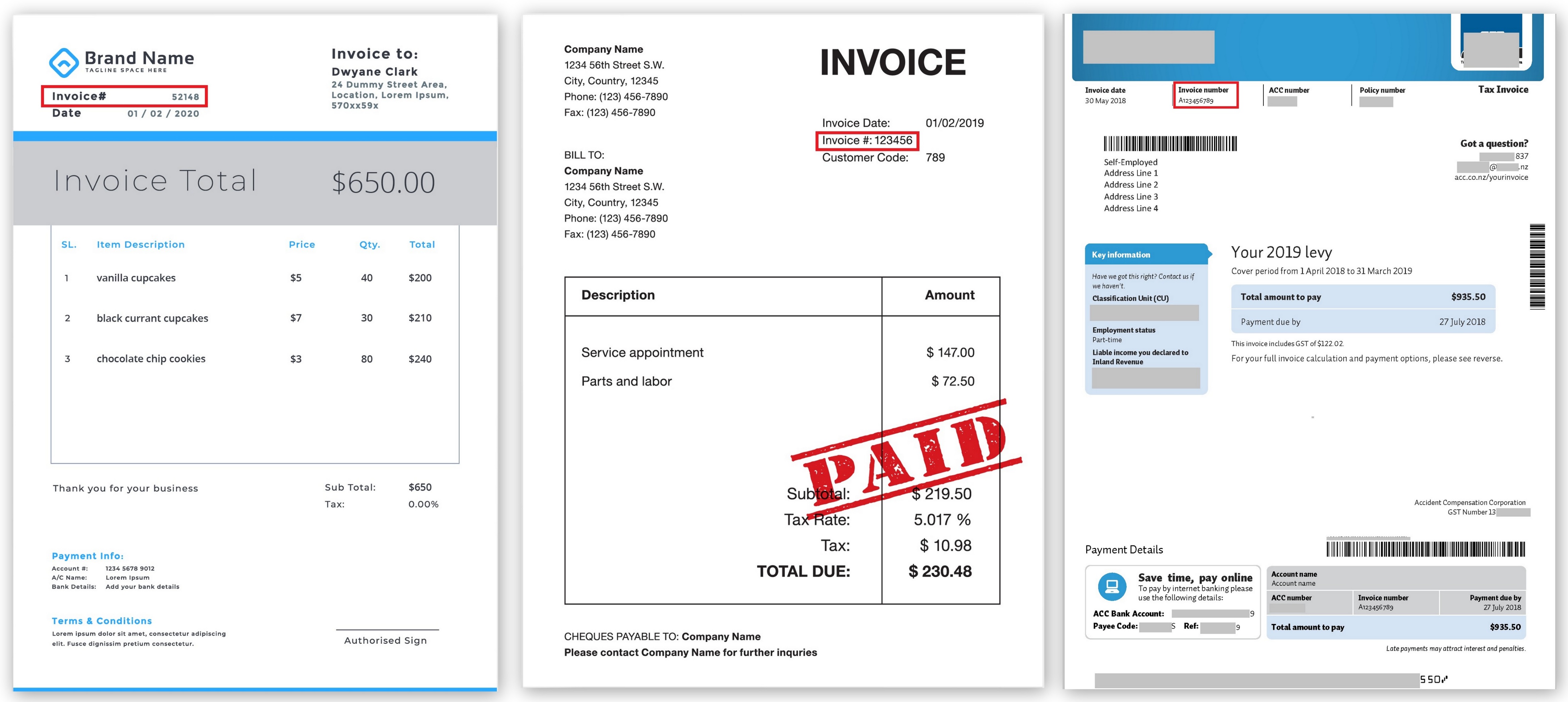
Программировалась целая логика, что бывают такие-то поля, они находятся в таком-то месте документа, вокруг них находятся другие поля на каких-то расстояниях. И это как-то работало до тех пор, пока не появлялась какая-то другая компания, которая начинала присылать свои документы совершенно другой формы. Или прежняя компания вдруг меняла формат, и все переставало работать.
Шаблоны
Бороться с этим, каждый раз что-то перепрограммируя, было нерационально. Поэтому на помощь пришла новая парадигма – использование шаблонов. Шаблон – это набор полей, которые нужно найти в документе, и набор правил, как эти поля находить. Основное преимущество здесь в том, что шаблоны создаются визуально. Например, мы хотим искать Invoice Number и Total, выбираем эти поля и настраиваем параметры, что такое-то поле идет сразу после такого-то ключевого слова, оно находится в верхней части документа и содержит цифры и знаки пунктуации.
Были разработаны специализированные инструменты, так называемые редакторы шаблонов, где уже продвинутые пользователи без помощи программистов могли быстро вручную задавать какую-то логику. Как только приходил документ новой формы, под него создавался свой шаблон и все более-менее начинало работать.
Образец шаблона (кликабельный):
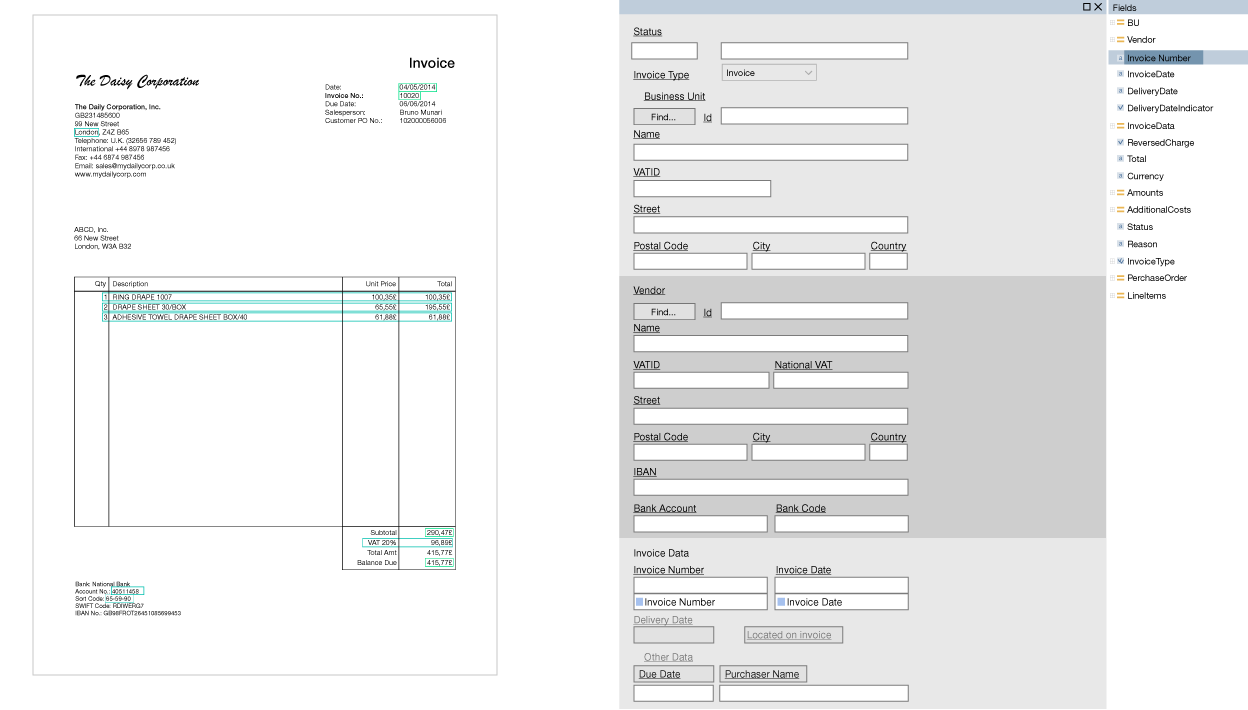
Но сделать один шаблон – это мало, их нужно сделать сотни и даже тысячи. И поэтому настройка продукта под каждого клиента иногда может занимать большое время. Невозможно заранее создать «универсальные» шаблоны, которые будут покрывать все многообразие инвойсов.
С помощью шаблонов удается значительно повысить качество извлечения таблиц. Но зачастую встречаются сложные табличные структуры, с нестандартным представлением данных, несколькими уровнями вложенности, и шаблоны в этих случаях не всегда хорошо справляются. Поэтому опять приходится писать какие-то скрипты, которые содержат множество вручную подобранных параметров, условий, исключений и т.д.
Использование машинного обучения
Технологии сегодня не стоят на месте, и с развитием машинного обучения появилась возможность передать задачу извлечения данных из документов нейронным сетям.
Сегодня можно выделить несколько основных подходов, которые используются на практике:
- Первый подход заключается в работе напрямую с входным изображением документа. То есть на вход сети подается изображение (картинка) или фрагмент, и сеть учится находить небольшие области, где расположены нужные поля, а потом текст в этих областях распознается с помощью классических технологий OCR (Optical Character Recognition). Это end-to-end решение, которое можно быстро реализовать. Можно взять готовую сеть поиска объектов на изображениях, например, YOLO или Faster R-CNN и обучить ее на размеченных картинках документов.
Недостаток такого подхода – не самое лучшее качество извлекаемых данных и сложность извлечения таблиц. По сути, данный подход в каком-то роде похож на задачу поиска нужных слов на изображении (word spotting), фундаментальную проблему из области компьютерного зрения, только здесь мы ищем не слова, а нужные поля. - Второй подход – это обработка извлеченного из документа текста. Это может быть или текст из PDF, или полностраничный OCR документа. Здесь используются технологии обработки естественного языка NLP (Natural Language Processing). Из отдельных слов собираются строки, из строк формируются различные фрагменты текста, абзацы или колонки, и в них уже сеть учится выделять различные именованные сущности NER (Named-Entity Recognition).
Возможны различные способы формирования фрагментов текста. Можно скомбинировать первый и второй подход, обучить одну сеть находить на изображениях большие блоки с определенной информацией, например, данные об отправителе или данные о получателе, где сразу содержится название, адрес, реквизиты и т.д., а потом текст каждого такого блока передавать во вторую NER сеть.
Качество у такого подхода может получиться выше, чем просто в первом подходе, но достаточно сложно построить эффективную модель. На сегодняшний день существуют довольно продвинутые модели, например, LSTM-CRF for NER, которые могут тегировать слова в тексте и определять сущности. - Третий подход – построение семантического представления документа без привязки к типу документа, т.е. когда мы не знаем, что перед нами за документ, но пытаемся это понять в процессе обработки. На вход сети подается совокупность слов документа с их различными признаками (например, содержит ли слово только буквы или является ли оно числом), геометрическим расположением слов (координаты, отступы) и с различными выявленными при анализе изображения разделителями и связями, а на выходе получаем для каждого слова свой определенный набор характеристик. По полученным характеристикам формируются различные наборы гипотез возможных полей или таблиц, которые в дальнейшем перебираются и оцениваются дополнительным классификатором. Затем выбирается наиболее достоверная гипотеза структуры и содержания документа.
Это уже технически наиболее сложное решение, но можно решить задачу извлечения данных из документов в общем виде.
Как мы используем нейронные сети
Мы в ABBYY не только внимательно следим за достижениями науки и техники, но создаем и свои передовые технологии и внедряем их в различные продукты.
Ниже на рисунке приведена общая архитектура нашего решения с использованием нейронных сетей.
Картинка кликабельна
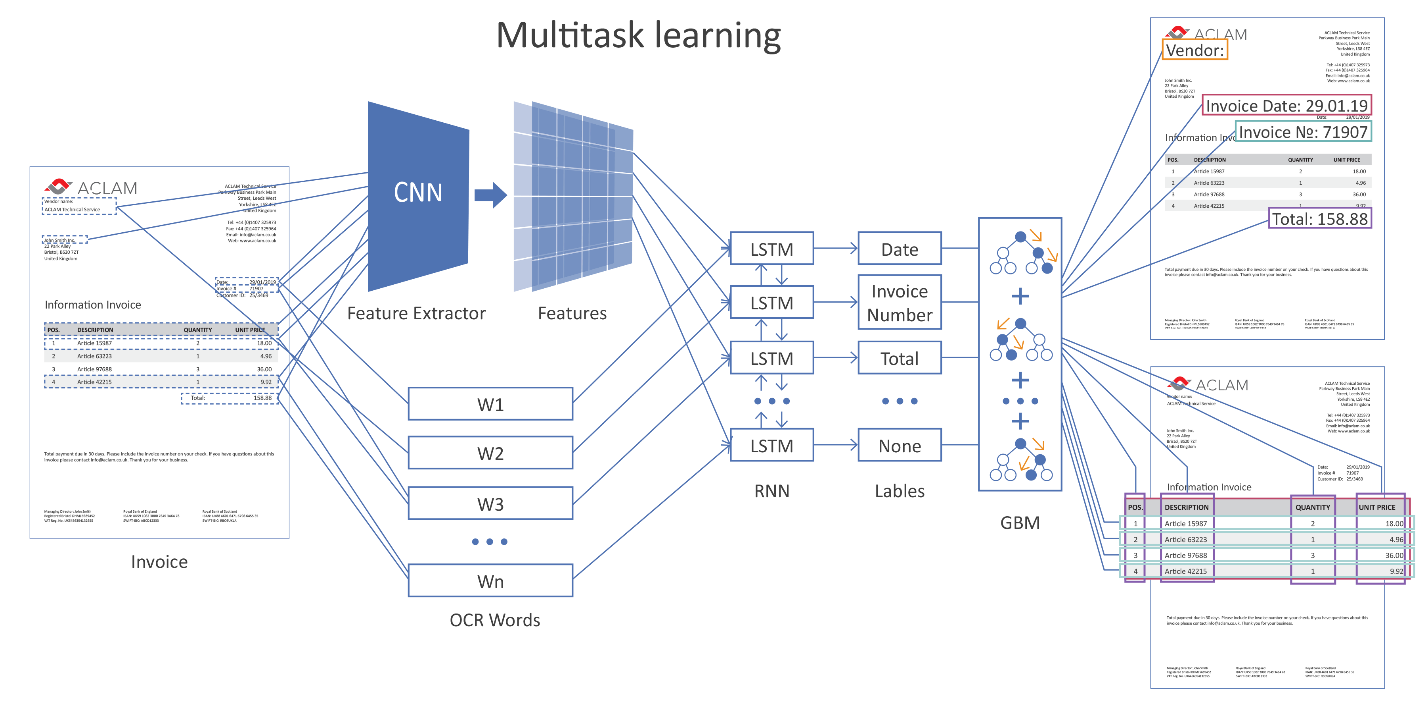
На вход сети подается целиком страница документа. С помощью сверточных слоев (CNN) формируются различные геометрические признаки, например, взаимное расположение слов относительно друг друга. Далее эти признаки объединяются с векторным представлением распознанных слов (word embeddings) и подаются на рекуррентные (LSTM) и полносвязные слои. Имеется несколько различных выходных слоев (multi-task learning), каждый выход решает свою задачу:
- определение типа поля, которому может соответствовать слово,
- гипотезы границ таблицы,
- гипотезы строк таблицы, границ колонок и др.
Если документ многостраничный, то сеть делает свое предсказание для каждой отдельной страницы, потом результаты объединяются.
Далее формируются гипотезы возможного расположения полей и таблиц, с помощью отдельно обученной функции регрессии производится их оценка, и самая уверенная гипотеза побеждает.
Для повышения точности извлечения данных помимо разделения документов по типу (чек, инвойс, договор и т.д.) происходит дополнительная кластеризация уже внутри своего типа по дополнительным признакам.
Например, для инвойсов это может быть вендор или просто внешний вид (по степени похожести расположения полей). А дальше в зависимости от той или иной группы (кластера) применяются специфические настройки алгоритмов. Технически, имея примеры корректно размеченных инвойсов для разных групп, можно на стороне пользователя дообучать механизмы оценки и выбора правильных гипотез.
Для настройки всевозможных параметров наших алгоритмов и нейронных сетей используется метод дифференциальной эволюции, который очень хорошо показал себя на практике.
Наши результаты использования машинного обучения

- Разработанный метод извлечения данных из структурированных документов с использованием машинного обучения во многих случаях показывает лучшие результаты, чем запрограммированные решения, основанные на эвристиках. Прирост качества по различным метрикам составляет от нескольких единиц до десятков процентов на различных извлекаемых сущностях.
- Появилось неоспоримое преимущество перед классическим подходом – возможность дообучать сеть на новых данных. В случае с многообразием форм документов, теперь это не проблема, а скорее потребность. Чем их больше, тем лучше; тем сильнее будет способность сети к обобщению и тем выше будет качество.
- Появилась возможность выпустить так называемое решение «из коробки», когда пользователь просто устанавливает продукт (по сути, обученную сеть), и все сразу начинает работать с приемлемым результатом. Не нужно ничего программировать, долго и мучительно настраивать шаблоны, подбирать всякие параметры.
Важная деталь, про которую также хотелось бы упомянуть – это данные. Никакое машинное обучение не может случиться без качественных данных. Машинное обучение дает лучшие результаты, чем инженерия знаний, только при наличии достаточного количества размеченных данных. В случае инвойсов – это десятки тысяч вручную размеченных документов, и эта цифра постоянно растет.
Кроме того, мы используем продвинутые механизмы аугментации данных (data augmentation), меняем названия организаций, адреса, списки товаров и виды услуг в таблицах, даты, различные количественные характеристики, такие как цена, количество, стоимость и т.д. Также меняем порядок следования различных сущностей в документах, что позволяет в итоге генерировать миллионы совершенно различных документов для обучения.
Вместо заключения
В завершение можно сказать, что программирование пока еще, конечно, не исчезло, но постепенно меняет свою роль. С каждым новым днем машинное обучение начинает справляться с возложенными на него задачами все лучше в самых разных отраслях, вытесняя классические подходы. Неоспоримое преимущество машинного обучения в эффективности: десятки человеко-лет интеллектуального труда теперь обходятся в десятки машино-часов обучения. Поэтому в ближайшем будущем мы видим еще большее развитие и применимость сетей во всех наших разработках. И если вам это интересно, мы всегда открыты к предложениям и сотрудничеству.

