Привет, Хаброжители!
Мы решили поделиться переводом главы «Системы на основе очередей задач» Из готовящейся к выходу новинки «Распределенные системы. Паттерны проектирования» (уже в типографии).
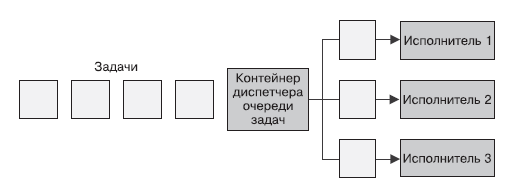
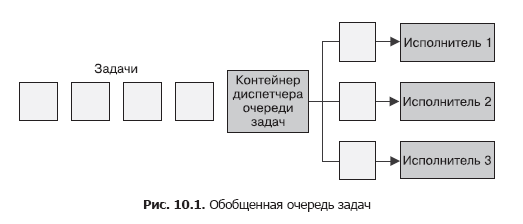
Простейшая форма пакетной обработки — очередь задач. В системе с очередью задач есть набор задач, которые должны быть выполнены. Каждая задача полностью независима от остальных и может быть обработана без всяких взаимодействий с ними. В общем случае цель системы с очередью задач — обеспечить выполнение каждого этапа работы в течение заданного промежутка времени. Количество рабочих потоков увеличивается либо уменьшается сообразно изменению нагрузки. Схема обобщенной очереди задач представлена на рис. 10.1.
Очередь задач — идеальный пример, демонстрирующий всю мощь паттернов проектирования распределенных систем. Большая часть логики работы очереди задач никак не зависит от рода выполняемой работы. Во многих случаях то же касается и доставки самих задач.
Проиллюстрируем данное утверждение с помощью очереди задач, изображенной на рис. 10.1. Посмотрев на нее еще раз, определите, какие ее функции могут быть предоставлены совместно используемым набором контейнеров. Становится очевидным, что большая часть реализации контейнеризованной очереди задач может использоваться широким спектром пользователей.
Построение очереди задач на основе контейнеров требует согласования интерфейсов между библиотечными контейнерами и контейнерами с пользовательской логикой. В рамках контейнеризованной очереди задач выделяется два интерфейса: интерфейс контейнера-источника, предоставляющего поток задач, требующих обработки, и интерфейс контейнера-исполнителя, который знает, как их обрабатывать.
Любая очередь задач функционирует на основе набора задач, требующих обработки. В зависимости от конкретного приложения, реализованного на базе очереди задач, существует множество источников задач, в нее попадающих. Но после получения набора задач схема работы очереди оказывается довольно простой. Следовательно, мы можем отделить специфичную для приложения логику работы источника задач от обобщенной схемы обработки очереди задач. Вспомнив ранее рассмотренные паттерны групп контейнеров, здесь можно разглядеть реализацию паттерна Ambassador. Контейнер обобщенной очереди задач является главным контейнером приложения, а специфичный для приложения контейнер-источник является послом, транслирующим запросы контейнера-диспетчера очереди конкретным исполнителям задач. Данная группа контейнеров изображена на рис. 10.2.

К слову, хотя контейнер-посол специфичен для приложения (что очевидно), существует также ряд обобщенных реализаций API источника задач. Например, источником может служить список фотографий, находящихся в некотором облачном хранилище, набор файлов на сетевом диске или даже очередь в системах, работающих по принципу «публикация/подписка», таких как Kafka или Redis. Несмотря на то что пользователи могут выбирать наиболее подходящие под свою задачу контейнеры-послы, им следует использовать обобщенную «библиотечную» реализацию самого контейнера. Так будет минимизирован объем работы и максимизировано повторное использование кода.
API очереди задач. Учитывая механизм взаимодействия очереди задач и зависящего от приложения контейнера-посла, нам следует сформулировать формальное определение интерфейса между двумя контейнерами. Существует много разных протоколов, но HTTP RESTful API просты в реализации и являются стандартом де-факто для подобных интерфейсов. Очередь задач ожидает, что в контейнере-после будут реализованы следующие URL:
URL /items/<item-name> предоставляет подробную информацию о конкретной задаче:
Обратите внимание, что в API не предусмотрено никаких механизмов фиксации факта выполнения задачи. Можно было бы разработать более сложный API и переложить большую часть реализации на контейнер-посол. Помните, однако, что наша цель — сосредоточить как можно большую часть общей реализации внутри диспетчера очереди задач. В этой связи диспетчер очереди задач должен сам следить за тем, какие задачи уже обработаны, а какие еще предстоит обработать.
Из этого API мы получаем сведения о конкретной задаче, а затем передаем значение поля item.data интерфейса контейнера-исполнителя.
Как только диспетчер очереди получил очередную задачу, он должен поручить ее некоторому исполнителю. Это второй интерфейс в обобщенной очереди задач. Сам контейнер и его интерфейс немного отличаются от интерфейса контейнера-источника по нескольким причинам. Во-первых, это «одноразовый» API. Работа исполнителя начинается с единственного вызова, и в течение жизненного цикла контейнера больше никаких вызовов не выполняется. Во-вторых, контейнер-исполнитель и диспетчер очереди задач находятся в разных группах контейнеров. Контейнер-исполнитель запускается посредством API оркестратора контейнеров в своей собственной группе. Это значит, что диспетчер очереди задач должен выполнить удаленный вызов, чтобы инициировать работу контейнера-исполнителя. Это также значит, что придется быть более осторожными в вопросах безопасности, так как злонамеренный пользователь кластера может загрузить его лишней работой.
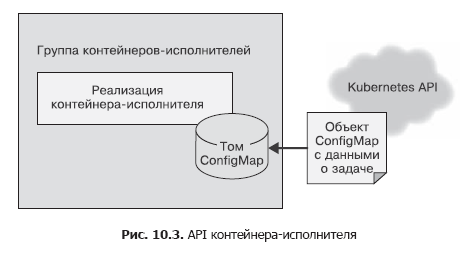
В контейнере-источнике для отправки списка задач диспетчеру задач мы использовали простой HTTP-вызов. Так было сделано исходя из того, что данный API-вызов нужно совершать несколько раз, а вопросы безопасности не учитывались, поскольку все работало в рамках localhost. API контейнера-исполнителя необходимо вызывать лишь однажды и важно убедиться, что другие пользователи системы не могут добавить работы исполнителям хоть случайно, хоть по злому умыслу. Следовательно, для контейнера-исполнителя будем использовать файловый API. При создании мы передадим контейнеру переменную среды под названием WORK_ITEM_FILE, значение которой ссылается на файл во внутренней файловой системе контейнера. Этот файл содержит данные о задаче, которую необходимо выполнить. Такого рода API, как показано ниже, может быть реализован Kubernetes-объектом ConfigMap. Его можно смонтировать в группу контейнеров как файл (рис. 10.3).
Такой механизм файлового API проще реализовать с помощью контейнера. Исполнитель в рамках очереди задач часто представляет собой простой сценарий командной оболочки, обращающийся к нескольким инструментам. Нецелесообразно поднимать для управления задачами целый веб-сервер — это приводит к усложнению архитектуры. Как и в случае с источниками задач, большая часть контейнеров-исполнителей будет представлять собой специализированные контейнеры для определенных задач, но есть и обобщенные исполнители, применимые для решения нескольких разных задач.
Рассмотрим пример контейнера-исполнителя, который скачивает файл из облачного хранилища, выполняет над ним сценарий командной оболочки, а затем копирует результат обратно в облачное хранилище. Такой контейнер может быть по большей части общим, но в качестве параметра ему может передаваться конкретный сценарий. Таким образом, большая часть кода работы с файлом может быть повторно использована многими пользователями/очередями задач. Конечному пользователю необходимо лишь предоставить сценарий, содержащий специфику обработки файла.
Что остается внедрить в повторно используемой реализации очереди, если реализации двух ранее описанных интерфейсов контейнеров у вас уже есть? Базовый алгоритм работы очереди задач довольно прост.
Этот алгоритм прост на словах, но в действительности его не так легко реализовать. К счастью, оркестратор Kubernetes имеет несколько возможностей, которые значительно упрощают его реализацию. А именно: в Kubernetes есть объект Job, который позволяет обеспечить надежную работу очереди задач. Объект Job можно настроить так, чтобы он запускал соответствующий контейнер-исполнитель либо разово, либо пока задача не будет успешно выполнена. Если контейнер-исполнитель настроить, чтобы он выполнялся до завершения задачи, то, даже когда машина в кластере откажет, задача в конце концов будет выполнена успешно.
Таким образом, построение очереди задач существенно упрощается, так как оркестратор берет на себя ответственность за надежное исполнение задач.
Кроме того, Kubernetes позволяет аннотировать задачи, что дает нам возможность пометить каждый объект-задачу названием обрабатываемого элемента очереди задач. Становится проще различать задачи, обрабатываемые и завершенные как успешно, так и с ошибкой.
Это значит, что мы можем реализовать очередь задач поверх оркестратора Kubernetes, не используя собственного хранилища. Все это существенно упрощает задачу построения инфраструктуры очереди задач.
Следовательно, подробный алгоритм работы контейнера — диспетчера очереди задач выглядит следующим образом.
Повторять бесконечно.
Приведу сценарий на языке Python, реализующий такую очередь:
В качестве примера использования очереди задач рассмотрим задачу генерации миниатюр видеофайлов. На основе этих миниатюр пользователи принимают решение о том, какие видео они хотят посмотреть.
Для реализации миниатюр понадобится два контейнера. Первый — для источника задач. Проще всего будет размещать задачи на общем сетевом диске, подключенном, например, по NFS (Network File System, сетевая файловая система). Источник задач получает список файлов в этом каталоге и передает их вызывающей стороне.
Приведу простую программу на NodeJS:
Данный источник определяет список фильмов, подлежащих обработке. Для извлечения миниатюр используется утилита ffmpeg.
Можно создать контейнер, запускающий такую команду:
Команда извлекает один из каждых 100 кадров (параметр -frames:v 100) и сохраняет его в формате PNG (например, thumb1.png, thumb2.png и т. д.).
Подобного рода обработку можно реализовать на основе существующего Docker-образа ffmpeg. Популярностью пользуется образ jrottenberg/ffmpeg.
Определив простой контейнер-источник и еще более простой контейнер-исполнитель, нетрудно заметить, какие преимущества имеет обобщенная, контейнерно-ориентированная система управления очередью. Она существенно сокращает время между проектированием и реализацией очереди задач.
Рассмотренная ранее очередь задач хорошо подходит для обработки заданий по мере их поступления, но может привести к скачкообразной нагрузке на ресурсы кластера оркестратора контейнеров. Это хорошо, когда у вас много разных видов заданий, создающих нагрузочные пики в разное время и тем самым равномерно распределяющих нагрузку на кластер во времени.
Но если у вас недостаточно видов нагрузки, подход «то густо, то пусто» к масштабированию очереди задач может потребовать резервирования дополнительных ресурсов для поддержки всплесков нагрузки. В остальное время ресурсы будут простаивать, без надобности опустошая ваш кошелек.
Для решения данной проблемы можно ограничить общее количество объектов Job, порождаемых очередью задач. Это естественным образом ограничит количество параллельно обрабатываемых заданий и, следовательно, снизит использование ресурсов при пиковой нагрузке. С другой стороны, увеличится длительность исполнения каждой отдельной задачи при высокой нагрузке на кластер.
Если нагрузка носит скачкообразный характер, это нестрашно, поскольку для выполнения скопившихся задач можно пользоваться интервалами простоя. Однако если устойчивая нагрузка слишком высока, очередь задач не будет успевать обрабатывать приходящие задания и на их выполнение будет затрачиваться все больше и больше времени.
В такой ситуации вам придется динамически подстраивать максимальное количество параллельно выполняемых задач и, соответственно, доступных вычислительных ресурсов для поддержания необходимого уровня производительности. К счастью, есть математические формулы, позволяющие определить, когда необходимо масштабировать очередь задач для обработки большего количества запросов.
Рассмотрим очередь задач, в которой новое задание появляется в среднем раз в минуту, а его выполнение занимает в среднем 30 секунд. Такая очередь в состоянии справиться с потоком приходящих в нее заданий. Даже если одномоментно придет большой пакет заданий, образовав затор, то со временем затор будет ликвидирован, поскольку до поступления очередного задания очередь успевает обработать в среднем два задания.
Если же новое задание приходит каждую минуту и на обработку одного задания уходит в среднем 1 минута, то такая система идеально сбалансирована, но при этом плохо реагирует на изменения в нагрузке. Она в состоянии справиться с всплесками нагрузки, но на это ей потребуется довольно много времени. У системы не будет простоя, но не будет и резерва машинного времени, чтобы скомпенсировать долгосрочное повышение скорости поступления новых задач. Для поддержания стабильности системы необходимо иметь резерв на случай долгосрочного роста нагрузки или непредвиденных задержек при обработке заданий.
Наконец, рассмотрим систему, в которой поступает одно задание в минуту, а обработка задания занимает две минуты. Такая система будет постоянно терять производительность. Длина очереди задач будет расти вместе с задержкой между поступлением и обработкой задач (и степенью раздраженности пользователей).
За значениями этих двух показателей необходимо постоянно следить. Усреднив время между поступлением заданий за длительный период времени, например на основе количества заданий за сутки, получим оценку межзадачного интервала. Необходимо также следить за средней продолжительностью обработки задания (без учета времени, проведенного им в очереди). В стабильной очереди задач среднее время обработки задачи должно быть меньше межзадачного интервала. Чтобы обеспечить выполнение такого условия, необходимо динамически подстраивать количество доступных очереди вычислительных ресурсов. Если задания обрабатываются параллельно, то время обработки следует разделить на количество параллельно обрабатываемых заданий. К примеру, если одно задание обрабатывается минуту, но параллельно обрабатываются четыре задачи, то эффективное время обработки одной задачи составляет 15 секунд, а значит, межзадачный интервал должен составлять не менее 16 секунд.
Такой подход позволяет без труда создать модуль масштабирования очереди задач в сторону увеличения. Масштабирование в сторону уменьшения несколько проблематичнее. Тем не менее можно использовать те же расчеты, что и ранее, дополнительно заложив определяемый эвристическим путем резерв вычислительных ресурсов. К примеру, можно снижать количество параллельно выполняемых задач до тех пор, пока время обработки одного задания не составит 90 % от межзадачного интервала.
Одна из основных тем данной книги — использование контейнеров с целью инкапсуляции и повторного применения кода. Она актуальна и для паттернов построения очередей задач, описываемых в данной главе. Помимо контейнеров, управляющих самой очередью, повторно использовать можно и группы контейнеров, образующих реализацию исполнителей. Допустим, каждое задание в очереди вам необходимо обработать тремя разными способами. Например, обнаружить на фотографии лица, сопоставить их с конкретными людьми, а затем размыть соответствующие части изображения. Можно поместить всю обработку в один контейнер-исполнитель, но это одноразовое решение, которое невозможно будет использовать повторно. Для замазывания на фото чего-нибудь еще, например машин, придется с нуля создавать контейнер-исполнитель.
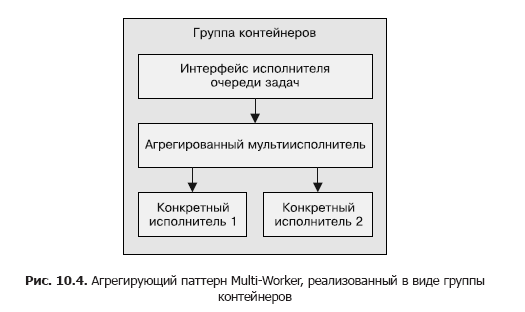
Возможности такого рода повторного использования можно добиться путем применения паттерна Multi-Worker, который фактически является частным случаем паттерна Adapter, описанного в начале книги. Паттерн Multi-Worker преобразует набор контейнеров в один общий контейнер с программным интерфейсом контейнера-исполнителя. Этот общий контейнер делегирует обработку нескольким отдельным, повторно используемым контейнерам. Данный процесс схематически изображен на рис. 10.4.
Благодаря повторному использованию кода путем комбинирования контейнеров-исполнителей снижаются трудозатраты людей, проектирующих распределенные системы пакетной обработки.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Распределенные системы.
Мы решили поделиться переводом главы «Системы на основе очередей задач» Из готовящейся к выходу новинки «Распределенные системы. Паттерны проектирования» (уже в типографии).
Простейшая форма пакетной обработки — очередь задач. В системе с очередью задач есть набор задач, которые должны быть выполнены. Каждая задача полностью независима от остальных и может быть обработана без всяких взаимодействий с ними. В общем случае цель системы с очередью задач — обеспечить выполнение каждого этапа работы в течение заданного промежутка времени. Количество рабочих потоков увеличивается либо уменьшается сообразно изменению нагрузки. Схема обобщенной очереди задач представлена на рис. 10.1.
Система на основе обобщенной очереди задач
Очередь задач — идеальный пример, демонстрирующий всю мощь паттернов проектирования распределенных систем. Большая часть логики работы очереди задач никак не зависит от рода выполняемой работы. Во многих случаях то же касается и доставки самих задач.
Проиллюстрируем данное утверждение с помощью очереди задач, изображенной на рис. 10.1. Посмотрев на нее еще раз, определите, какие ее функции могут быть предоставлены совместно используемым набором контейнеров. Становится очевидным, что большая часть реализации контейнеризованной очереди задач может использоваться широким спектром пользователей.
Построение очереди задач на основе контейнеров требует согласования интерфейсов между библиотечными контейнерами и контейнерами с пользовательской логикой. В рамках контейнеризованной очереди задач выделяется два интерфейса: интерфейс контейнера-источника, предоставляющего поток задач, требующих обработки, и интерфейс контейнера-исполнителя, который знает, как их обрабатывать.
Интерфейс контейнера-источника
Любая очередь задач функционирует на основе набора задач, требующих обработки. В зависимости от конкретного приложения, реализованного на базе очереди задач, существует множество источников задач, в нее попадающих. Но после получения набора задач схема работы очереди оказывается довольно простой. Следовательно, мы можем отделить специфичную для приложения логику работы источника задач от обобщенной схемы обработки очереди задач. Вспомнив ранее рассмотренные паттерны групп контейнеров, здесь можно разглядеть реализацию паттерна Ambassador. Контейнер обобщенной очереди задач является главным контейнером приложения, а специфичный для приложения контейнер-источник является послом, транслирующим запросы контейнера-диспетчера очереди конкретным исполнителям задач. Данная группа контейнеров изображена на рис. 10.2.
К слову, хотя контейнер-посол специфичен для приложения (что очевидно), существует также ряд обобщенных реализаций API источника задач. Например, источником может служить список фотографий, находящихся в некотором облачном хранилище, набор файлов на сетевом диске или даже очередь в системах, работающих по принципу «публикация/подписка», таких как Kafka или Redis. Несмотря на то что пользователи могут выбирать наиболее подходящие под свою задачу контейнеры-послы, им следует использовать обобщенную «библиотечную» реализацию самого контейнера. Так будет минимизирован объем работы и максимизировано повторное использование кода.
API очереди задач. Учитывая механизм взаимодействия очереди задач и зависящего от приложения контейнера-посла, нам следует сформулировать формальное определение интерфейса между двумя контейнерами. Существует много разных протоколов, но HTTP RESTful API просты в реализации и являются стандартом де-факто для подобных интерфейсов. Очередь задач ожидает, что в контейнере-после будут реализованы следующие URL:
- GET localhost/api/v1/items;
- GET localhost/api/v1/items<item-name>.
Зачем добавлять v1 в определение API, спросите вы? Появится ли когда-нибудь вторая версия интерфейса? Выглядит нелогично, но расходы на версионирование API при первоначальном его определении минимальны. Проводить же соответствующий рефакторинг позже станет крайне дорого. Возьмите за правило добавлять версии ко всем API, даже если не уверены, что они когда-либо изменятся. Береженого Бог бережет.URL /items/ возвращает список всех задач:
{ kind: ItemList, apiVersion: v1, items: [ "item-1", "item-2", …. ] }
URL /items/<item-name> предоставляет подробную информацию о конкретной задаче:
{ kind: Item, apiVersion: v1, data: { "some": "json", "object": "here", } }
Обратите внимание, что в API не предусмотрено никаких механизмов фиксации факта выполнения задачи. Можно было бы разработать более сложный API и переложить большую часть реализации на контейнер-посол. Помните, однако, что наша цель — сосредоточить как можно большую часть общей реализации внутри диспетчера очереди задач. В этой связи диспетчер очереди задач должен сам следить за тем, какие задачи уже обработаны, а какие еще предстоит обработать.
Из этого API мы получаем сведения о конкретной задаче, а затем передаем значение поля item.data интерфейса контейнера-исполнителя.
Интерфейс контейнера-исполнителя
Как только диспетчер очереди получил очередную задачу, он должен поручить ее некоторому исполнителю. Это второй интерфейс в обобщенной очереди задач. Сам контейнер и его интерфейс немного отличаются от интерфейса контейнера-источника по нескольким причинам. Во-первых, это «одноразовый» API. Работа исполнителя начинается с единственного вызова, и в течение жизненного цикла контейнера больше никаких вызовов не выполняется. Во-вторых, контейнер-исполнитель и диспетчер очереди задач находятся в разных группах контейнеров. Контейнер-исполнитель запускается посредством API оркестратора контейнеров в своей собственной группе. Это значит, что диспетчер очереди задач должен выполнить удаленный вызов, чтобы инициировать работу контейнера-исполнителя. Это также значит, что придется быть более осторожными в вопросах безопасности, так как злонамеренный пользователь кластера может загрузить его лишней работой.
В контейнере-источнике для отправки списка задач диспетчеру задач мы использовали простой HTTP-вызов. Так было сделано исходя из того, что данный API-вызов нужно совершать несколько раз, а вопросы безопасности не учитывались, поскольку все работало в рамках localhost. API контейнера-исполнителя необходимо вызывать лишь однажды и важно убедиться, что другие пользователи системы не могут добавить работы исполнителям хоть случайно, хоть по злому умыслу. Следовательно, для контейнера-исполнителя будем использовать файловый API. При создании мы передадим контейнеру переменную среды под названием WORK_ITEM_FILE, значение которой ссылается на файл во внутренней файловой системе контейнера. Этот файл содержит данные о задаче, которую необходимо выполнить. Такого рода API, как показано ниже, может быть реализован Kubernetes-объектом ConfigMap. Его можно смонтировать в группу контейнеров как файл (рис. 10.3).
Такой механизм файлового API проще реализовать с помощью контейнера. Исполнитель в рамках очереди задач часто представляет собой простой сценарий командной оболочки, обращающийся к нескольким инструментам. Нецелесообразно поднимать для управления задачами целый веб-сервер — это приводит к усложнению архитектуры. Как и в случае с источниками задач, большая часть контейнеров-исполнителей будет представлять собой специализированные контейнеры для определенных задач, но есть и обобщенные исполнители, применимые для решения нескольких разных задач.
Рассмотрим пример контейнера-исполнителя, который скачивает файл из облачного хранилища, выполняет над ним сценарий командной оболочки, а затем копирует результат обратно в облачное хранилище. Такой контейнер может быть по большей части общим, но в качестве параметра ему может передаваться конкретный сценарий. Таким образом, большая часть кода работы с файлом может быть повторно использована многими пользователями/очередями задач. Конечному пользователю необходимо лишь предоставить сценарий, содержащий специфику обработки файла.
Общая инфраструктура очередей задач
Что остается внедрить в повторно используемой реализации очереди, если реализации двух ранее описанных интерфейсов контейнеров у вас уже есть? Базовый алгоритм работы очереди задач довольно прост.
- Загрузить из контейнера-источника доступные на данный момент задачи.
- Уточнить состояние очереди задач на предмет того, какие задачи уже выполнены или еще выполняются.
- Для каждой из нерешенных задач породить контейнеры-исполнители с соответствующим интерфейсом.
- При успешном завершении контейнера-исполнителя зафиксировать, что задача выполнена.
Этот алгоритм прост на словах, но в действительности его не так легко реализовать. К счастью, оркестратор Kubernetes имеет несколько возможностей, которые значительно упрощают его реализацию. А именно: в Kubernetes есть объект Job, который позволяет обеспечить надежную работу очереди задач. Объект Job можно настроить так, чтобы он запускал соответствующий контейнер-исполнитель либо разово, либо пока задача не будет успешно выполнена. Если контейнер-исполнитель настроить, чтобы он выполнялся до завершения задачи, то, даже когда машина в кластере откажет, задача в конце концов будет выполнена успешно.
Таким образом, построение очереди задач существенно упрощается, так как оркестратор берет на себя ответственность за надежное исполнение задач.
Кроме того, Kubernetes позволяет аннотировать задачи, что дает нам возможность пометить каждый объект-задачу названием обрабатываемого элемента очереди задач. Становится проще различать задачи, обрабатываемые и завершенные как успешно, так и с ошибкой.
Это значит, что мы можем реализовать очередь задач поверх оркестратора Kubernetes, не используя собственного хранилища. Все это существенно упрощает задачу построения инфраструктуры очереди задач.
Следовательно, подробный алгоритм работы контейнера — диспетчера очереди задач выглядит следующим образом.
Повторять бесконечно.
- Получить список задач посредством интерфейса контейнера — источника задач.
- Получить список заданий, обслуживающих данную очередь задач.
- Выделить на основе этих списков перечень необработанных задач.
- Для каждой необработанной задачи создать объект Job, который порождает соответствующий контейнер-исполнитель.
Приведу сценарий на языке Python, реализующий такую очередь:
import requests import json from kubernetes import client, config import time namespace = "default" def make_container(item, obj): container = client.V1Container() container.image = "my/worker-image" container.name = "worker" return container def make_job(item): response = requests.get("http://localhost:8000/items/{}".format(item)) obj = json.loads(response.text) job = client.V1Job() job.metadata = client.V1ObjectMeta() job.metadata.name = item job.spec = client.V1JobSpec() job.spec.template = client.V1PodTemplate() job.spec.template.spec = client.V1PodTemplateSpec() job.spec.template.spec.restart_policy = "Never" job.spec.template.spec.containers = [ make_container(item, obj) ] return job def update_queue(batch): response = requests.get("http://localhost:8000/items") obj = json.loads(response.text) items = obj['items'] ret = batch.list_namespaced_job(namespace, watch=False) for item in items: found = False for i in ret.items: if i.metadata.name == item: found = True if not found: # Функция создает объект Job, пропущена # для краткости job = make_job(item) batch.create_namespaced_job(namespace, job) config.load_kube_config() batch = client.BatchV1Api() while True: update_queue(batch) time.sleep(10)
Практикум. Реализация генератора миниатюр видеофайлов
В качестве примера использования очереди задач рассмотрим задачу генерации миниатюр видеофайлов. На основе этих миниатюр пользователи принимают решение о том, какие видео они хотят посмотреть.
Для реализации миниатюр понадобится два контейнера. Первый — для источника задач. Проще всего будет размещать задачи на общем сетевом диске, подключенном, например, по NFS (Network File System, сетевая файловая система). Источник задач получает список файлов в этом каталоге и передает их вызывающей стороне.
Приведу простую программу на NodeJS:
const http = require('http'); const fs = require('fs'); const port = 8080; const path = process.env.MEDIA_PATH; const requestHandler = (request, response) => { console.log(request.url); fs.readdir(path + '/*.mp4', (err, items) => { var msg = { 'kind': 'ItemList', 'apiVersion': 'v1', 'items': [] }; if (!items) { return msg; } for (var i = 0; i < items.length; i++) { msg.items.push(items[i]); } response.end(JSON.stringify(msg)); }); } const server = http.createServer(requestHandler); server.listen(port, (err) => { if (err) { return console.log('Ошибка запуска сервера', err); } console.log(`сервер запущен на порте ${port}`) });
Данный источник определяет список фильмов, подлежащих обработке. Для извлечения миниатюр используется утилита ffmpeg.
Можно создать контейнер, запускающий такую команду:
ffmpeg -i ${INPUT_FILE} -frames:v 100 thumb.png
Команда извлекает один из каждых 100 кадров (параметр -frames:v 100) и сохраняет его в формате PNG (например, thumb1.png, thumb2.png и т. д.).
Подобного рода обработку можно реализовать на основе существующего Docker-образа ffmpeg. Популярностью пользуется образ jrottenberg/ffmpeg.
Определив простой контейнер-источник и еще более простой контейнер-исполнитель, нетрудно заметить, какие преимущества имеет обобщенная, контейнерно-ориентированная система управления очередью. Она существенно сокращает время между проектированием и реализацией очереди задач.
Динамическое масштабирование исполнителей
Рассмотренная ранее очередь задач хорошо подходит для обработки заданий по мере их поступления, но может привести к скачкообразной нагрузке на ресурсы кластера оркестратора контейнеров. Это хорошо, когда у вас много разных видов заданий, создающих нагрузочные пики в разное время и тем самым равномерно распределяющих нагрузку на кластер во времени.
Но если у вас недостаточно видов нагрузки, подход «то густо, то пусто» к масштабированию очереди задач может потребовать резервирования дополнительных ресурсов для поддержки всплесков нагрузки. В остальное время ресурсы будут простаивать, без надобности опустошая ваш кошелек.
Для решения данной проблемы можно ограничить общее количество объектов Job, порождаемых очередью задач. Это естественным образом ограничит количество параллельно обрабатываемых заданий и, следовательно, снизит использование ресурсов при пиковой нагрузке. С другой стороны, увеличится длительность исполнения каждой отдельной задачи при высокой нагрузке на кластер.
Если нагрузка носит скачкообразный характер, это нестрашно, поскольку для выполнения скопившихся задач можно пользоваться интервалами простоя. Однако если устойчивая нагрузка слишком высока, очередь задач не будет успевать обрабатывать приходящие задания и на их выполнение будет затрачиваться все больше и больше времени.
В такой ситуации вам придется динамически подстраивать максимальное количество параллельно выполняемых задач и, соответственно, доступных вычислительных ресурсов для поддержания необходимого уровня производительности. К счастью, есть математические формулы, позволяющие определить, когда необходимо масштабировать очередь задач для обработки большего количества запросов.
Рассмотрим очередь задач, в которой новое задание появляется в среднем раз в минуту, а его выполнение занимает в среднем 30 секунд. Такая очередь в состоянии справиться с потоком приходящих в нее заданий. Даже если одномоментно придет большой пакет заданий, образовав затор, то со временем затор будет ликвидирован, поскольку до поступления очередного задания очередь успевает обработать в среднем два задания.
Если же новое задание приходит каждую минуту и на обработку одного задания уходит в среднем 1 минута, то такая система идеально сбалансирована, но при этом плохо реагирует на изменения в нагрузке. Она в состоянии справиться с всплесками нагрузки, но на это ей потребуется довольно много времени. У системы не будет простоя, но не будет и резерва машинного времени, чтобы скомпенсировать долгосрочное повышение скорости поступления новых задач. Для поддержания стабильности системы необходимо иметь резерв на случай долгосрочного роста нагрузки или непредвиденных задержек при обработке заданий.
Наконец, рассмотрим систему, в которой поступает одно задание в минуту, а обработка задания занимает две минуты. Такая система будет постоянно терять производительность. Длина очереди задач будет расти вместе с задержкой между поступлением и обработкой задач (и степенью раздраженности пользователей).
За значениями этих двух показателей необходимо постоянно следить. Усреднив время между поступлением заданий за длительный период времени, например на основе количества заданий за сутки, получим оценку межзадачного интервала. Необходимо также следить за средней продолжительностью обработки задания (без учета времени, проведенного им в очереди). В стабильной очереди задач среднее время обработки задачи должно быть меньше межзадачного интервала. Чтобы обеспечить выполнение такого условия, необходимо динамически подстраивать количество доступных очереди вычислительных ресурсов. Если задания обрабатываются параллельно, то время обработки следует разделить на количество параллельно обрабатываемых заданий. К примеру, если одно задание обрабатывается минуту, но параллельно обрабатываются четыре задачи, то эффективное время обработки одной задачи составляет 15 секунд, а значит, межзадачный интервал должен составлять не менее 16 секунд.
Такой подход позволяет без труда создать модуль масштабирования очереди задач в сторону увеличения. Масштабирование в сторону уменьшения несколько проблематичнее. Тем не менее можно использовать те же расчеты, что и ранее, дополнительно заложив определяемый эвристическим путем резерв вычислительных ресурсов. К примеру, можно снижать количество параллельно выполняемых задач до тех пор, пока время обработки одного задания не составит 90 % от межзадачного интервала.
Паттерн Multi-Worker
Одна из основных тем данной книги — использование контейнеров с целью инкапсуляции и повторного применения кода. Она актуальна и для паттернов построения очередей задач, описываемых в данной главе. Помимо контейнеров, управляющих самой очередью, повторно использовать можно и группы контейнеров, образующих реализацию исполнителей. Допустим, каждое задание в очереди вам необходимо обработать тремя разными способами. Например, обнаружить на фотографии лица, сопоставить их с конкретными людьми, а затем размыть соответствующие части изображения. Можно поместить всю обработку в один контейнер-исполнитель, но это одноразовое решение, которое невозможно будет использовать повторно. Для замазывания на фото чего-нибудь еще, например машин, придется с нуля создавать контейнер-исполнитель.
Возможности такого рода повторного использования можно добиться путем применения паттерна Multi-Worker, который фактически является частным случаем паттерна Adapter, описанного в начале книги. Паттерн Multi-Worker преобразует набор контейнеров в один общий контейнер с программным интерфейсом контейнера-исполнителя. Этот общий контейнер делегирует обработку нескольким отдельным, повторно используемым контейнерам. Данный процесс схематически изображен на рис. 10.4.
Благодаря повторному использованию кода путем комбинирования контейнеров-исполнителей снижаются трудозатраты людей, проектирующих распределенные системы пакетной обработки.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Распределенные системы.

