Вторая часть перевода официальной документации по визуализации данных в Kibana.
Ссылка на оригинальный материал: Kibana User Guide [6.6] » Visualize
Ссылка на 1 часть: Руководство пользователя Kibana. Визуализация. Часть 1
Содержание:
Предупреждение. Эта функция является экспериментальной и может быть изменена или удаленна в будущем выпуске. Elastic приложит все усилия, чтобы исправить любые проблемы, но экспериментальные функции не подлежат поддержке SLA официальных функций GA.
Визуализация элементов управления позволяет добавлять интерактивные входные данные на информационные панели Kibana. Вы можете создать два типа входящей информации: выпадающий список или переключатель «один-из-многих».

Для инициализации визуализации элементов управления откройте вкладку Visualization и кликните кнопку +. Пролистайте до секции Others и выберите Controls.
Выпадающее меню позволяет пользователям фильтровать содержимое выбирая одну или больше опций из списка. Выпадающее меню динамически заполняется результатами агрегации значений (terms, прим. пер.).

Control Label. Подпись для выпадающего списка. По умолчанию, подпись является именем поля.
Index Pattern. Шаблон индекса, что содержит набор данных для визуализации.
Field. Поле используется для заполнения списка опций и фильтруется, когда пользователи взаимодействуют с вводом. Список доступных полей получается з опрделенного шаблона индекса.
Parent control. Элемент управления для создания цепочек выпадающих меню, таких что выбор в первом меню фильтрует значения во втором меню. Доступно только при создании нескольких выпадающих списков.
Multiselect. Когда включен, выпадающее меню позволяет пользователям выбирать несколько вариантов.
Size. Количество опций для включения в список.
Регулируемый диапазон позволяет пользователям фильтровать содержимое в пределах ранга чисел. Минимальное и максимальное значения регулируемого диапазона динамически определяются минимальным и максимальным значениями агрегации.
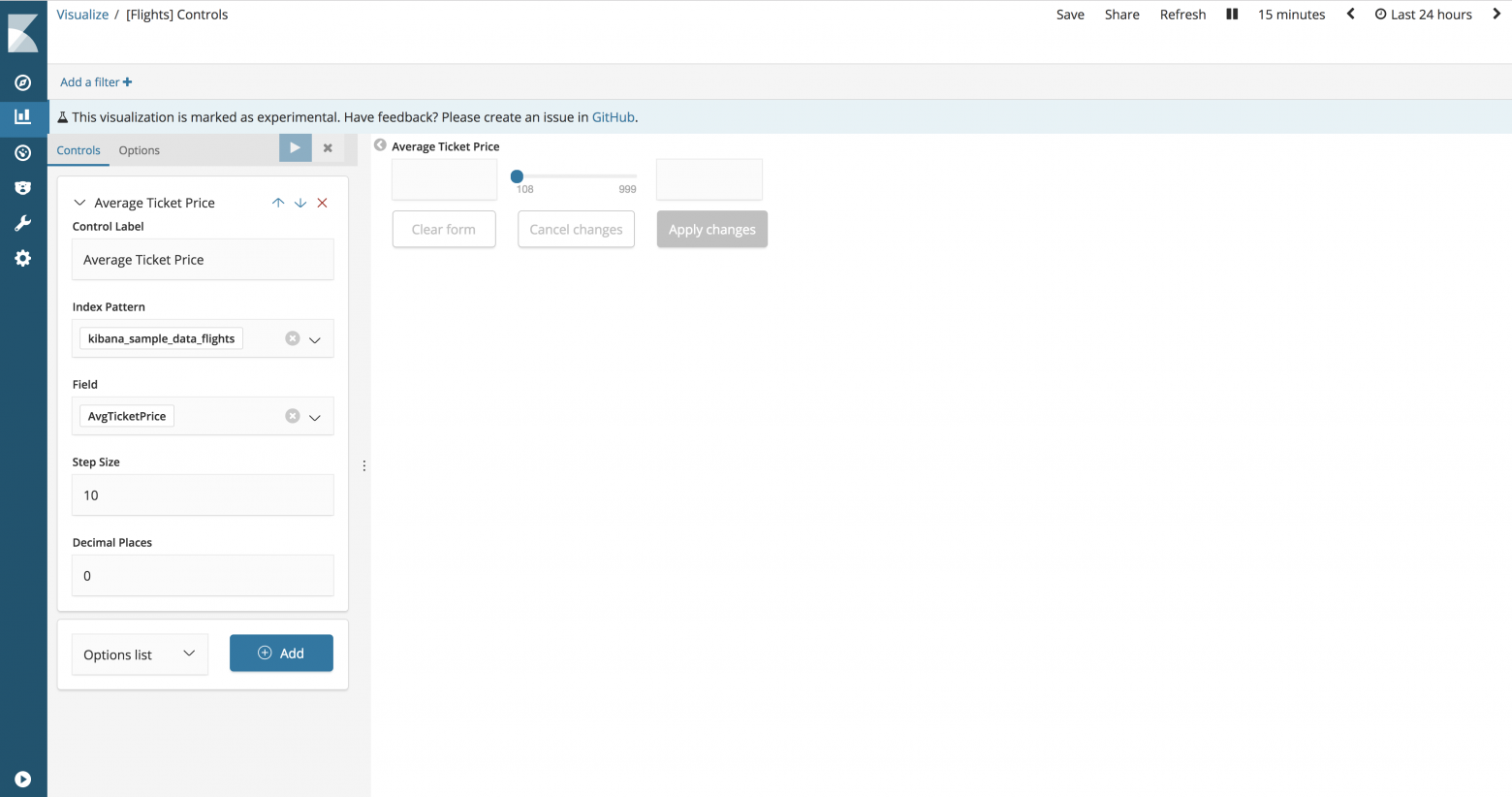
Control Label. Подпись регулируемого диапазона. По умолчанию, подписью является имя поля.
Index Pattern. Шаблон индекса, который содержит набор данных для визуализации.
Field. Поле используется для наполнения регулируемого диапазона и его фильтрации, когда пользователи взаимодействуют с входящими данными. Список доступных полей заполняется из определенного шаблона индекса.
Step Size. Увеличивает/уменьшает размер ползунка.
Decimal Places. Число десятичных знаков после запятой.
Откройте вкладку Options для настройки настроек, которые применяются ко всем входным элементам контроля в визуализации Controls.
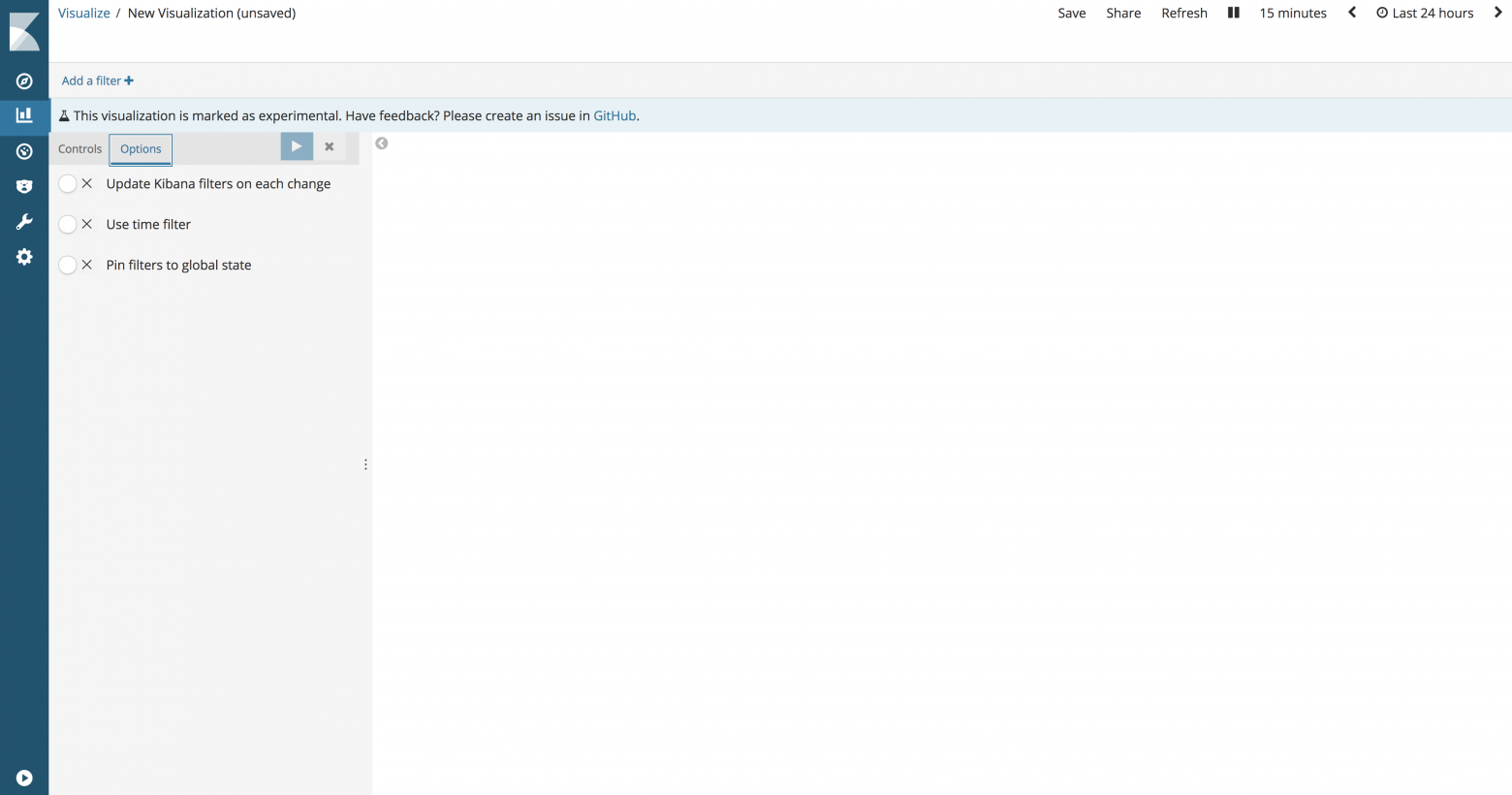
Update Kibana filters on each change. Когда включен, все входящие взаимодействия тот же час создают фильтры, что заставляют информационную панель обновляться. Когда выключено, фильтры Kibana создаются, когда пользователь кликнет Apply changes .
.
Use time filter. Когда включен, агрегации, что используются для генерации выпадающего списка опций и диапазона минимум-максимум, привязаны к глобальному времени Kibana.
Pin filters to global state. Когда включено все фильтры, созданные при взаимодействии с входными данными, автоматически закрепляются.
Метрические агрегации:
Count. Агрегация подсчета возвращает чистый подсчет элементов в выбранном шаблоне индекса.
Average. Данная агрегация возвращает среднее значение по числовому полю. Выбирайте поле из выпадающего списка.
Sum. Возвращает общую сумму по числовому полю. Выбирайте поле из выпадающего списка.
Min. Возвращает минимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Max. Возвращает максимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Unique Count. Кардинальная агрегация возвращает число уникальных значений в поле. Выбирайте поле из выпадающего списка.
Standard Deviation. Агрегация общей статистики возвращает стандартное отклонение данных в числовом поле. Выбирайте поле из выпадающего списка.
Top Hit. Агрегация топовых значений возвращает один или больше топовых значений из специального поля в вашем документе. Выбирайте поле из выпадающего списка, тип сортировки документов, количество значений, которые нужно вернуть.
Percentiles. Агрегация процентов разделяет значения числового поля на заданные диапазоны. Выбирайте поле из выпадающего списка, затем определите одну или больше областей в полях Percentiles. Кликните X для удаления поля процентов. Кликните +Add для добавления процентного поля.
Percentile Rank. Агрегация процентного ранга возвращает процентное ранжирование по выбранному числовому полю. Выбирайте поле из выпадающего списка, затем определите один или больше значений процентного ранга в полях Values. Кликните X для удаления поля значения. Кликните +Add для добавления поля значений.
Агрегации родительских источников данных:
Для каждой агрегации родительского источника информации необходимо определить метрику, для которой агрегация высчитана. Это может быть одна из уже существующих метрик или новая. Вы также можете вкладывать эти агрегации (к примеру, для получения третей производной).
Derivative. Агрегация производной подсчитывает производную определенных метрик.
Cumulative Sum. Агрегация накопительной суммы подсчитывает накопительную сумму определенных метрик в родительской гистограмме.
Moving Average. Агрегация скользящего среднего будет вставлять окно сквозь данные и писать среднее значение этого окна.
Serial Diff. Последовательное дифференцирование — это метод, где значения во временном ряде отнимаются от самых себя в другой временной период или задержки.
Агрегации родственного источника:
Как и в случае с агрегациями родительских источников, вам необходимо указать метрику по которой будет высчитываться агрегация родственного источника. Кроме этого, вам необходимо предусмотреть агрегацию сегментов, которая будет определять на каких сегментах агрегация будет запускаться.
Average Bucket. Среднее сегмента вычисляет среднее значение определенных метрик в агрегации родственных источников.
Sum Bucket. Высчитывает сумму значений определенной метрики в агрегации родственного источника.
Min Bucket. Возвращает минимальное значение определенной метрики в агрегации родственного источника.
Max Bucket. Возвращает максимальное значение определенной метрики в агрегации родственного источника.
Вы можете создать агрегацию кликнув на кнопке + Add Metrics.
Введите строку в поле Custom Label, чтобы изменить подпись.
Строки таблицы данных называют сегменты. Вы можете определить сегменты для разбивки таблицы на строки или для разбивки на дополнительные таблицы.
Каждый тип сегмента поддерживает следующие агрегации:
Date Histogram. Временная гистограмма построена на основе числового поля и организована по дате. Вы можете определить временные рамки для интервалов в секундах, минутах, часах, днях, неделях, месяцах или годах. Вы также можете определить интервал по умолчанию, выбрав Custom в качестве интервала и указав число и единицу времени в текстовом поле. По умолчанию единицами временного интервала являются: s для секунд, m для минут, h для часов, d для дней, w для недель, y для лет. Различные единицы поддерживают различные уровни точности, вплоть до одной секунды. Интервалы подписываются в начале интервала, используя ключ-дату, который возвращается из Elasticsearch. Для примера, на всплывающей подсказке для месячного интервала будет отображаться первый день месяца.
Histogram. Стандартная гистограмма строится на основе числового поля. Определите целочисленный интервал для этого поля. Установите флажок Show empty buckets, чтобы включить пустые интервалы в гистограмму.
Range. С помощью агрегации рангов вы можете определить ранги для значений числового поля. Кликните Add Range для добавления набора конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
Date Range. Агрегация временного ранга сообщает значения, которые находятся в указанном диапазоне дат. Вы можете указать диапазоны дат, используя математические выражения даты. Кликните Add Range, чтобы добавить набор конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
IPv4 Range. Агрегация IPv4 ранга позволяет вам определить диапазоны IPv4 адресов. Кликните Add Range, чтобы добавить набор конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
Terms. Агрегация значений позволяет вам определить верхние или нижние n элементов данного поля для отображения, упорядоченные по количеству или пользовательской метрике.
Filters. Вы можете определить набор фильтров для данных. Возможно указать фильтр как строку запроса или в формате JSON, так же как и в поисковой вкладке Discover. Кликните Add Filter, чтобы добавить другой фильтр. Кликните кнопку label, чтобы открыть поле подписи, где вы можете напечатать имя для отображения на визуализации.
Significant Terms. Выводит результаты экспериментальной агрегации знаковых значений. Значение параметра Size определяет число входов, что эта агрегация возвращает.
Geohash. Агрегация гео хеша выводит точки на основе географических координат.
Однажды определив тип агрегации сегмента, вы можете определить подгруппы агрегаций для улучшения визуализации. Кликните + Add sub-buckets для создания вложенного сегмента, затем выберите Split Rows или Split Table, затем выберите агрегацию из списка типов.
Вы можете использовать стрелочки вверх/вниз справа от типа агрегации что бы изменить приоритет агрегации.
Введите строку в поле Custom Label что бы изменить подпись.
Вы можете кликнуть по ссылке Advanced что бы отобразить больше опций для ваших метрик или агрегации сегмента:
Exclude Pattern. Укажите шаблон в этом поле что бы исключить с результатов.
Include Pattern. Укажите шаблон в этом поле что бы включить в результаты.
JSON Input. Текстовое поле, где вы можете добавить специфичные свойства в формате JSON для слияния с определенной агрегацией, как нижеследующем примере:
Примечание. В Elasticsearch 1.4.3 и позже этот функционал нуждается во включенном динамическом скриптинге Groovy.
Доступность этих параметров зависит от выбранной вами агрегации.
Выберите вкладку Options что бы изменить следующие аспекты таблицы:
Per Page. Это поле контролирует нумерацию страниц таблицы. По умолчанию, значение равно десяти строчкам на страницу.
Флажки включения/отключения доступны для следующих действий:
Show metrics for every bucket/level. Отметьте эту позицию что бы отобразить промежуточные результаты для каждой агрегации сегмента.
Show partial rows. Отмечайте эту позицию для вывода строки даже при отсутствии результата.
Примечание. Включение этих опций может серьезно повлиять на производительность.
Виджет Markdown — это поле ввода текста, которое принимает GitHub-нутый текст Markdown. Kibana исполняет текст, который вы вводите в это поле и отображает результаты на информационной панели. Вы можете кликнуть ссылку Help для перехода на страницу помощи по GitHub-нутый Markdown. Кликните Apply для вывода исполняемого текста на панели предпросмотра или Discard для возврата предыдущей версии.
Метрическая визуализация выводит одно число для каждой выбранной агрегации.
Метрические агрегации:
Count. Агрегация подсчета возвращает чистый подсчет элементов в выбранном шаблоне индекса.
Average. Данная агрегация возвращает среднее значение по числовому полю. Выбирайте поле из выпадающего списка.
Sum. Возвращает общую сумму по числовому полю. Выбирайте поле из выпадающего списка.
Min. Возвращает минимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Max. Возвращает максимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Unique Count. Кардинальная агрегация возвращает число уникальных значений в поле. Выбирайте поле из выпадающего списка.
Standard Deviation. Агрегация общей статистики возвращает стандартное отклонение данных в числовом поле. Выбирайте поле из выпадающего списка.
Top Hit. Агрегация топовых значений возвращает один или больше топовых значений из специального поля в вашем документе. Выбирайте поле из выпадающего списка, тип сортировки документов, количество значений, которые нужно вернуть.
Percentiles. Агрегация процентов разделяет значения числового поля на заданные диапазоны. Выбирайте поле из выпадающего списка, затем определите одну или больше областей в полях Percentiles. Кликните X для удаления поля процентов. Кликните +Add для добавления процентного поля.
Percentile Rank. Агрегация процентного ранга возвращает процентное ранжирование по выбранному числовому полю. Выбирайте поле из выпадающего списка, затем определите один или больше значений процентного ранга в полях Values. Кликните X для удаления поля значения. Кликните +Add для добавления поля значений.
Агрегации родительских источников данных:
Для каждой агрегации родительского источника информации необходимо определить метрику, для которой агрегация высчитана. Это может быть одна из уже существующих метрик или новая. Вы также можете вкладывать эти агрегации (к примеру, для получения третей производной).
Derivative. Агрегация производной подсчитывает производную определенных метрик.
Cumulative Sum. Агрегация накопительной суммы подсчитывает накопительную сумму определенных метрик в родительской гистограмме.
Moving Average. Агрегация скользящего среднего будет вставлять окно сквозь данные и писать среднее значение этого окна.
Serial Diff. Последовательное дифференцирование — это метод, где значения во временном ряде отнимаются от самых себя в другой временной период или задержки.
Агрегации родственного источника:
Как и в случае с агрегациями родительских источников, вам необходимо указать метрику по которой будет высчитываться агрегация родственного источника. Кроме этого, вам необходимо предусмотреть агрегацию сегментов, которая будет определять на каких сегментах агрегация будет запускаться.
Average Bucket. Среднее сегмента вычисляет среднее значение определенных метрик в агрегации родственных источников.
Sum Bucket. Высчитывает сумму значений определенной метрики в агрегации родственного источника.
Min Bucket. Возвращает минимальное значение определенной метрики в агрегации родственного источника.
Max Bucket. Возвращает максимальное значение определенной метрики в агрегации родственного источника.
Вы можете создать агрегацию кликнув на кнопке + Add Metrics.
Введите строку в поле Custom Label, чтобы изменить подпись.
Вы можете кликнуть по ссылке Advanced что бы отобразить больше опций:
JSON Input. Текстовое поле, где вы можете добавить специфичные свойства в формате JSON для слияния с определенной агрегацией, как нижеследующем примере:
Примечание. В Elasticsearch 1.4.3 и позже этот функционал нуждается во включенном динамическом скриптинге Groovy.
Доступность этих параметров зависит от выбранной вами агрегации.
Кликните вкладку Options для выведения ползунка размера шрифта.
Третья часть.
Ссылка на оригинальный материал: Kibana User Guide [6.6] » Visualize
Ссылка на 1 часть: Руководство пользователя Kibana. Визуализация. Часть 1
Содержание:
- Controls Visualization
- Data Table
- Markdown Widget
- Metric
Controls Visualization
Предупреждение. Эта функция является экспериментальной и может быть изменена или удаленна в будущем выпуске. Elastic приложит все усилия, чтобы исправить любые проблемы, но экспериментальные функции не подлежат поддержке SLA официальных функций GA.
Визуализация элементов управления позволяет добавлять интерактивные входные данные на информационные панели Kibana. Вы можете создать два типа входящей информации: выпадающий список или переключатель «один-из-многих».
Adding Input Controls
Для инициализации визуализации элементов управления откройте вкладку Visualization и кликните кнопку +. Пролистайте до секции Others и выберите Controls.
Dropdown menu
Выпадающее меню позволяет пользователям фильтровать содержимое выбирая одну или больше опций из списка. Выпадающее меню динамически заполняется результатами агрегации значений (terms, прим. пер.).
Control Label. Подпись для выпадающего списка. По умолчанию, подпись является именем поля.
Index Pattern. Шаблон индекса, что содержит набор данных для визуализации.
Field. Поле используется для заполнения списка опций и фильтруется, когда пользователи взаимодействуют с вводом. Список доступных полей получается з опрделенного шаблона индекса.
Parent control. Элемент управления для создания цепочек выпадающих меню, таких что выбор в первом меню фильтрует значения во втором меню. Доступно только при создании нескольких выпадающих списков.
Multiselect. Когда включен, выпадающее меню позволяет пользователям выбирать несколько вариантов.
Size. Количество опций для включения в список.
Range slider
Регулируемый диапазон позволяет пользователям фильтровать содержимое в пределах ранга чисел. Минимальное и максимальное значения регулируемого диапазона динамически определяются минимальным и максимальным значениями агрегации.
Control Label. Подпись регулируемого диапазона. По умолчанию, подписью является имя поля.
Index Pattern. Шаблон индекса, который содержит набор данных для визуализации.
Field. Поле используется для наполнения регулируемого диапазона и его фильтрации, когда пользователи взаимодействуют с входящими данными. Список доступных полей заполняется из определенного шаблона индекса.
Step Size. Увеличивает/уменьшает размер ползунка.
Decimal Places. Число десятичных знаков после запятой.
Глобальные переменные
Откройте вкладку Options для настройки настроек, которые применяются ко всем входным элементам контроля в визуализации Controls.
Update Kibana filters on each change. Когда включен, все входящие взаимодействия тот же час создают фильтры, что заставляют информационную панель обновляться. Когда выключено, фильтры Kibana создаются, когда пользователь кликнет Apply changes
.Use time filter. Когда включен, агрегации, что используются для генерации выпадающего списка опций и диапазона минимум-максимум, привязаны к глобальному времени Kibana.
Pin filters to global state. Когда включено все фильтры, созданные при взаимодействии с входными данными, автоматически закрепляются.
Data Table
Метрические агрегации:
Count. Агрегация подсчета возвращает чистый подсчет элементов в выбранном шаблоне индекса.
Average. Данная агрегация возвращает среднее значение по числовому полю. Выбирайте поле из выпадающего списка.
Sum. Возвращает общую сумму по числовому полю. Выбирайте поле из выпадающего списка.
Min. Возвращает минимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Max. Возвращает максимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Unique Count. Кардинальная агрегация возвращает число уникальных значений в поле. Выбирайте поле из выпадающего списка.
Standard Deviation. Агрегация общей статистики возвращает стандартное отклонение данных в числовом поле. Выбирайте поле из выпадающего списка.
Top Hit. Агрегация топовых значений возвращает один или больше топовых значений из специального поля в вашем документе. Выбирайте поле из выпадающего списка, тип сортировки документов, количество значений, которые нужно вернуть.
Percentiles. Агрегация процентов разделяет значения числового поля на заданные диапазоны. Выбирайте поле из выпадающего списка, затем определите одну или больше областей в полях Percentiles. Кликните X для удаления поля процентов. Кликните +Add для добавления процентного поля.
Percentile Rank. Агрегация процентного ранга возвращает процентное ранжирование по выбранному числовому полю. Выбирайте поле из выпадающего списка, затем определите один или больше значений процентного ранга в полях Values. Кликните X для удаления поля значения. Кликните +Add для добавления поля значений.
Агрегации родительских источников данных:
Для каждой агрегации родительского источника информации необходимо определить метрику, для которой агрегация высчитана. Это может быть одна из уже существующих метрик или новая. Вы также можете вкладывать эти агрегации (к примеру, для получения третей производной).
Derivative. Агрегация производной подсчитывает производную определенных метрик.
Cumulative Sum. Агрегация накопительной суммы подсчитывает накопительную сумму определенных метрик в родительской гистограмме.
Moving Average. Агрегация скользящего среднего будет вставлять окно сквозь данные и писать среднее значение этого окна.
Serial Diff. Последовательное дифференцирование — это метод, где значения во временном ряде отнимаются от самых себя в другой временной период или задержки.
Агрегации родственного источника:
Как и в случае с агрегациями родительских источников, вам необходимо указать метрику по которой будет высчитываться агрегация родственного источника. Кроме этого, вам необходимо предусмотреть агрегацию сегментов, которая будет определять на каких сегментах агрегация будет запускаться.
Average Bucket. Среднее сегмента вычисляет среднее значение определенных метрик в агрегации родственных источников.
Sum Bucket. Высчитывает сумму значений определенной метрики в агрегации родственного источника.
Min Bucket. Возвращает минимальное значение определенной метрики в агрегации родственного источника.
Max Bucket. Возвращает максимальное значение определенной метрики в агрегации родственного источника.
Вы можете создать агрегацию кликнув на кнопке + Add Metrics.
Введите строку в поле Custom Label, чтобы изменить подпись.
Строки таблицы данных называют сегменты. Вы можете определить сегменты для разбивки таблицы на строки или для разбивки на дополнительные таблицы.
Каждый тип сегмента поддерживает следующие агрегации:
Date Histogram. Временная гистограмма построена на основе числового поля и организована по дате. Вы можете определить временные рамки для интервалов в секундах, минутах, часах, днях, неделях, месяцах или годах. Вы также можете определить интервал по умолчанию, выбрав Custom в качестве интервала и указав число и единицу времени в текстовом поле. По умолчанию единицами временного интервала являются: s для секунд, m для минут, h для часов, d для дней, w для недель, y для лет. Различные единицы поддерживают различные уровни точности, вплоть до одной секунды. Интервалы подписываются в начале интервала, используя ключ-дату, который возвращается из Elasticsearch. Для примера, на всплывающей подсказке для месячного интервала будет отображаться первый день месяца.
Histogram. Стандартная гистограмма строится на основе числового поля. Определите целочисленный интервал для этого поля. Установите флажок Show empty buckets, чтобы включить пустые интервалы в гистограмму.
Range. С помощью агрегации рангов вы можете определить ранги для значений числового поля. Кликните Add Range для добавления набора конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
Date Range. Агрегация временного ранга сообщает значения, которые находятся в указанном диапазоне дат. Вы можете указать диапазоны дат, используя математические выражения даты. Кликните Add Range, чтобы добавить набор конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
IPv4 Range. Агрегация IPv4 ранга позволяет вам определить диапазоны IPv4 адресов. Кликните Add Range, чтобы добавить набор конечных точек ранга. Кликните красный символ (x), чтобы удалить ранг.
Terms. Агрегация значений позволяет вам определить верхние или нижние n элементов данного поля для отображения, упорядоченные по количеству или пользовательской метрике.
Filters. Вы можете определить набор фильтров для данных. Возможно указать фильтр как строку запроса или в формате JSON, так же как и в поисковой вкладке Discover. Кликните Add Filter, чтобы добавить другой фильтр. Кликните кнопку label, чтобы открыть поле подписи, где вы можете напечатать имя для отображения на визуализации.
Significant Terms. Выводит результаты экспериментальной агрегации знаковых значений. Значение параметра Size определяет число входов, что эта агрегация возвращает.
Geohash. Агрегация гео хеша выводит точки на основе географических координат.
Однажды определив тип агрегации сегмента, вы можете определить подгруппы агрегаций для улучшения визуализации. Кликните + Add sub-buckets для создания вложенного сегмента, затем выберите Split Rows или Split Table, затем выберите агрегацию из списка типов.
Вы можете использовать стрелочки вверх/вниз справа от типа агрегации что бы изменить приоритет агрегации.
Введите строку в поле Custom Label что бы изменить подпись.
Вы можете кликнуть по ссылке Advanced что бы отобразить больше опций для ваших метрик или агрегации сегмента:
Exclude Pattern. Укажите шаблон в этом поле что бы исключить с результатов.
Include Pattern. Укажите шаблон в этом поле что бы включить в результаты.
JSON Input. Текстовое поле, где вы можете добавить специфичные свойства в формате JSON для слияния с определенной агрегацией, как нижеследующем примере:
{ "script" : "doc['grade'].value * 1.2" }Примечание. В Elasticsearch 1.4.3 и позже этот функционал нуждается во включенном динамическом скриптинге Groovy.
Доступность этих параметров зависит от выбранной вами агрегации.
Выберите вкладку Options что бы изменить следующие аспекты таблицы:
Per Page. Это поле контролирует нумерацию страниц таблицы. По умолчанию, значение равно десяти строчкам на страницу.
Флажки включения/отключения доступны для следующих действий:
Show metrics for every bucket/level. Отметьте эту позицию что бы отобразить промежуточные результаты для каждой агрегации сегмента.
Show partial rows. Отмечайте эту позицию для вывода строки даже при отсутствии результата.
Примечание. Включение этих опций может серьезно повлиять на производительность.
Markdown Widget
Виджет Markdown — это поле ввода текста, которое принимает GitHub-нутый текст Markdown. Kibana исполняет текст, который вы вводите в это поле и отображает результаты на информационной панели. Вы можете кликнуть ссылку Help для перехода на страницу помощи по GitHub-нутый Markdown. Кликните Apply для вывода исполняемого текста на панели предпросмотра или Discard для возврата предыдущей версии.
Metric
Метрическая визуализация выводит одно число для каждой выбранной агрегации.
Метрические агрегации:
Count. Агрегация подсчета возвращает чистый подсчет элементов в выбранном шаблоне индекса.
Average. Данная агрегация возвращает среднее значение по числовому полю. Выбирайте поле из выпадающего списка.
Sum. Возвращает общую сумму по числовому полю. Выбирайте поле из выпадающего списка.
Min. Возвращает минимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Max. Возвращает максимальное значение по числовому полю. Выбирайте поле из выпадающего списка.
Unique Count. Кардинальная агрегация возвращает число уникальных значений в поле. Выбирайте поле из выпадающего списка.
Standard Deviation. Агрегация общей статистики возвращает стандартное отклонение данных в числовом поле. Выбирайте поле из выпадающего списка.
Top Hit. Агрегация топовых значений возвращает один или больше топовых значений из специального поля в вашем документе. Выбирайте поле из выпадающего списка, тип сортировки документов, количество значений, которые нужно вернуть.
Percentiles. Агрегация процентов разделяет значения числового поля на заданные диапазоны. Выбирайте поле из выпадающего списка, затем определите одну или больше областей в полях Percentiles. Кликните X для удаления поля процентов. Кликните +Add для добавления процентного поля.
Percentile Rank. Агрегация процентного ранга возвращает процентное ранжирование по выбранному числовому полю. Выбирайте поле из выпадающего списка, затем определите один или больше значений процентного ранга в полях Values. Кликните X для удаления поля значения. Кликните +Add для добавления поля значений.
Агрегации родительских источников данных:
Для каждой агрегации родительского источника информации необходимо определить метрику, для которой агрегация высчитана. Это может быть одна из уже существующих метрик или новая. Вы также можете вкладывать эти агрегации (к примеру, для получения третей производной).
Derivative. Агрегация производной подсчитывает производную определенных метрик.
Cumulative Sum. Агрегация накопительной суммы подсчитывает накопительную сумму определенных метрик в родительской гистограмме.
Moving Average. Агрегация скользящего среднего будет вставлять окно сквозь данные и писать среднее значение этого окна.
Serial Diff. Последовательное дифференцирование — это метод, где значения во временном ряде отнимаются от самых себя в другой временной период или задержки.
Агрегации родственного источника:
Как и в случае с агрегациями родительских источников, вам необходимо указать метрику по которой будет высчитываться агрегация родственного источника. Кроме этого, вам необходимо предусмотреть агрегацию сегментов, которая будет определять на каких сегментах агрегация будет запускаться.
Average Bucket. Среднее сегмента вычисляет среднее значение определенных метрик в агрегации родственных источников.
Sum Bucket. Высчитывает сумму значений определенной метрики в агрегации родственного источника.
Min Bucket. Возвращает минимальное значение определенной метрики в агрегации родственного источника.
Max Bucket. Возвращает максимальное значение определенной метрики в агрегации родственного источника.
Вы можете создать агрегацию кликнув на кнопке + Add Metrics.
Введите строку в поле Custom Label, чтобы изменить подпись.
Вы можете кликнуть по ссылке Advanced что бы отобразить больше опций:
JSON Input. Текстовое поле, где вы можете добавить специфичные свойства в формате JSON для слияния с определенной агрегацией, как нижеследующем примере:
{ "script" : "doc['grade'].value * 1.2" }Примечание. В Elasticsearch 1.4.3 и позже этот функционал нуждается во включенном динамическом скриптинге Groovy.
Доступность этих параметров зависит от выбранной вами агрегации.
Кликните вкладку Options для выведения ползунка размера шрифта.
Третья часть.

