В прошлой статье мы рассматривали ограничения и препятствия, которые возникают, когда нужно горизонтально масштабировать данные и иметь гарантию ACID-свойств транзакций. В этой статье рассказываем о технологии FoundationDB и разбираемся, как она помогает преодолеть эти ограничения при разработке mission-critical приложений.
FoundationDB — это распределенная NoSQL база данных с ACID-транзакциями уровня Serializable, хранящая отсортированные пары ключ-значение (ordered key-value store). Ключами и значениями могут быть произвольные последовательности байт. У неё нет единой точки падения — все машины кластера равноправны. Она сама распределяет данные по серверам кластера и масштабируется на лету: когда в кластер нужно добавить ресурсов, ты просто добавляешь адрес новой машины на конфигурационных серверах и база сама подхватывает ее.
В FoundationDB транзакции никогда не блокируют друг друга. Чтение реализовано через мультиверсионный контроль версий (MVCC), а запись — через оптимистичный контроль параллелизма (OCC). Разработчики заявляют, что когда все машины кластера в одном дата-центре, то задержка на запись данных (write latency) составляет 2-3 мс, а на чтение (read latency) — меньше миллисекунды. В документации встречаются оценки в 10-15 мс, что, вероятно, ближе к результатам в реальных условиях.
 * Не поддерживает ACID-свойства на нескольких шардах.
* Не поддерживает ACID-свойства на нескольких шардах.
У FoundationDB есть уникальное преимущество — автоматический решардинг. СУБД сама обеспечивает равномерную загрузку машин в кластере: при переполнении одного сервера она в фоновом режиме перераспределяет данные на соседние. При этом сохраняется гарантия уровня Serializable на все транзакции, а единственный заметный клиентам эффект — это незначительное увеличение задержки ответов (latency). БД следит, чтобы объем данных на наиболее и наименее загруженных серверах кластера отличался не более, чем на 5%.
Логически кластер FoundationDB представляет собой набор однотипных процессов на разных физических машинах. У процессов нет собственных конфигурационных файлов, поэтому они взаимозаменяемы. Несколько фиксированных процессов имеют выделенную роль — Coordinators, и каждый процесс кластера при старте знает их адреса. Важно, чтобы падения Coordinators были максимально независимыми, поэтому их лучше размещать на разных физических машинах или даже в разных дата-центрах.

Coordinators договариваются между собой через консенсус-алгоритм Paxos. Они выбирают процесс Cluster Controller, который дальше назначает роли остальным процессам кластера. Cluster Controller непрерывно сообщает всем Coordinators, что он жив. Если большинство Coordinators считает, что он умер, они просто выбирают нового. Ни Cluster Controller, ни Coordinators не участвуют в обработке транзакций, их главная задача — исключить ситуацию split brain.
Когда клиент хочет подключиться к БД, он обращается сразу ко всем Coordinators за адресом текущего Cluster Controller. Если большинство ответов совпало, он получает из Cluster Controller полную текущую конфигурацию кластера (если не совпало — обращается к Coordinators повторно).
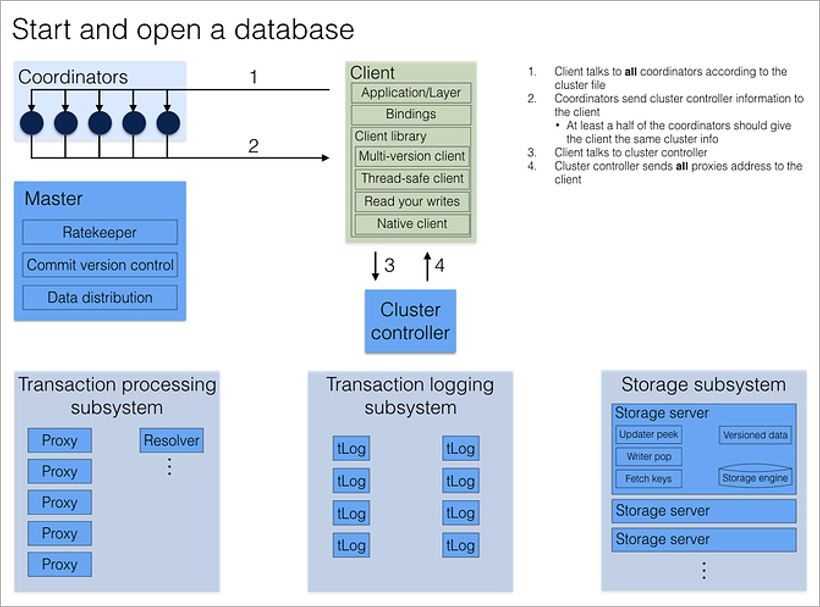
Cluster Controller знает общее число доступных процессов и распределяет роли: эти 5 будут Proxy, эти 2 — Resolver, этот — Master. И если какой-то из них умрёт, то он тут же найдет ему замену, назначив произвольному свободному процессу нужную роль. Это все происходит в фоне, незаметно для прикладного программиста.
Процесс Master отвечает за номер текущей версии набора данных (она увеличивается при каждой записи в БД), а также за распределение множества ключей по серверам хранения (storage servers) и rate-throttling (искусственное занижение производительности при больших нагрузках: если кластер знает, что клиент сделает много маленьких запросов, он подождет, сгруппирует их и ответит на всю пачку сразу).
Transaction logging и Storage — это две независимые подсистемы хранения данных. Первая — временное хранилище для быстрой записи данных на диск в порядке поступления, вторая — постоянное хранилище, где данные на диске отсортированы в порядке возрастания ключей. При каждом коммите транзакции как минимум три tLog-процесса должны сохранить данные, прежде чем кластер сообщит клиенту об успехе. Параллельно данные в фоне переезжают с tLog-серверов на Storage-сервера (хранение на которых также избыточное).
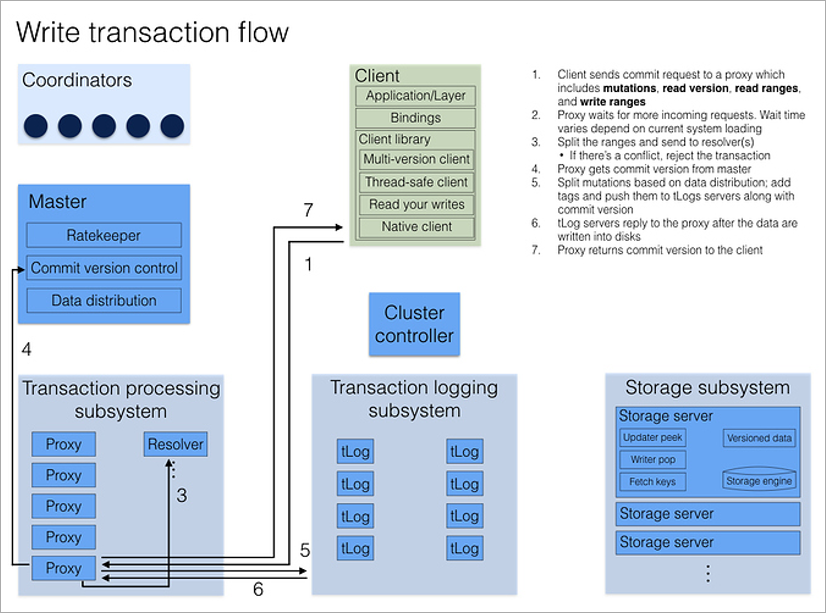
Все клиентские запросы обрабатывают процессы Proxy. Открывая транзакцию, клиент обращается к любому Proxy, тот опрашивает все остальные Proxy, и возвращает текущий номер версии данных кластера. Все последующие чтения происходят по этому номеру версии. Если другой клиент записал данные после того, как я открыл транзакцию, я его изменения просто не увижу.
Запись транзакции немного сложнее, поскольку нужно разруливать конфликты. Здесь включается процесс Resolver, который хранит в памяти все модифицированные ключи за некоторый период времени. Когда клиент завершает (commit) транзакцию записи, Resolver проверяет, не устарели ли данные, которые она читала. (То есть не было ли завершено транзакции, которая была открыта позже моей и изменила ключи, которые я читал.) Если такое произошло, транзакцию откатывают и клиентская библиотека сама(!) делает повторную попытку коммита. Единственное, о чём должен думать разработчик, — это чтобы транзакции были идемпотентные, то есть повторное применение должно давать идентичный результат. Один из способов добиться этого — сохранять в рамках транзакции какое-то уникальное значение, а в начале транзакции проверять его наличие в базе.
Как и в любой клиент-серверной системе бывают ситуации, когда транзакция завершена успешно, но клиент не получил подтверждение из-за обрыва связи. Клиентская библиотека относится к ним, как и к любой другой ошибке, — она просто повторяет попытку. Это потенциально может привести к повторному выполнению всей транзакции. Однако, если транзакция идемпотентная, никакой проблемы в этом нет — на итоговый результат это не повлияет.
В подсистеме хранения данных (Storage) могут быть тысячи серверов. К какому из них клиент должен обратиться, когда нужны данные по определенному ключу? От Cluster Controller клиент знает полную конфигурацию всего кластера, а она включает диапазоны ключей на каждом Storage-сервере. Поэтому он просто обращается напрямую к нужным Storage-серверам без каких-либо промежуточных запросов.
Если нужный Storage-сервер недоступен, то клиентская библиотека берет у Cluster Controller новую конфигурацию. Если в результате падения сервера кластер понимает, что избыточность недостаточна, он сразу же начинает собирать новую ноду из кусочков других Storage.
Предположим, что вы сохраняете в транзакции гигабайты данных. Как можно обеспечить быстрый отклик? Никак, и поэтому в FoundationDB просто ограничили размер одной транзакции 10 мегабайтами. Причем это ограничение на все данные, которых транзакция касается — читает или записывает. Каждая запись в БД тоже ограничена — ключ не может превышать 10 килобайт, значение — 100 килобайт. (При этом для оптимальной производительности разработчики рекомендуют ключи длиной 32 байта, а значения длиной 10 килобайт.)
Любая транзакция потенциально может стать источником конфликта, и тогда ее придется откатить. Поэтому ради скорости, пока не пришла команда commit, текущие изменения имеет смысл держать в оперативной памяти, а не на диске. Допустим, вы пишете данные в БД с нагрузкой 1GB/секунду. Тогда ваш кластер в экстремальном случае будет каждую секунду аллоцировать 3GB RAM (мы же пишем транзакции на 3 машинах). Как ограничить такой лавинообразный рост используемой памяти? Очень просто — ограничить максимальное время транзакции. В FoundationDB транзакция не может длится больше 5 секунд. Если клиент попытается обратиться к БД спустя 5 секунд после открытия транзакции, кластер будет игнорировать все его команды, пока он не откроет новую.
Предположим вы храните список людей, у каждого человека есть уникальный идентификатор, его используем в качестве ключа, а в значении пишем все остальные атрибуты — имя, пол, возраст, и т.д.
Как получить список всех людей, которым 30 лет без полного перебора? Обычно для этого в БД создают индекс. Индекс — это другое представление данных, созданное для быстрого поиска по дополнительным атрибутам. Мы можем просто добавить записи вида:
Теперь чтобы получить нужный список вам достаточно выполнить поиск по диапазону ключей (30, *). Поскольку FoundationDB хранит данные отсортированными по ключам, то такой запрос выполнится очень быстро. Конечно, индекс занимает дополнительное место на диске, но совсем немного. Обратите внимание, что дублируются не все атрибуты, а только возраст и идентификатор.
Важно, чтобы операции добавления самой записи и индекса на нее выполнялись в одной транзакции.
FoundationDB написана на C++. Работу над ней авторы начали в 2009 году, первая версия была выпущена в 2013-м, а в марте 2015-го их купила корпорация Apple. Спустя три года Apple неожиданно открыла исходный код. Ходят слухи, что Apple использует ее, среди прочего, для хранения данных сервиса iCloud.
Опытные разработчики обычно не сразу доверяют новым решениям. Могут пройти годы, прежде чем технология надежно зарекомендует себя и ее начнут массово использовать в проде. Чтобы сократить это время, авторы сделали интересное расширение языка C++: Flow. Оно позволяет изящно эмулировать работу с ненадежными внешними компонентами с возможностью полного предсказуемого повтора выполнения программы. Каждый вызов к сети или диску оборачивается в некоторую обертку (Actor), а каждый Actor имеет несколько реализаций. Стандартная реализация пишет данные на диск или в сеть, как и предполагалось. А другая пишет на диск 999 раз из 1000, а 1 раз из 1000 теряет. Альтернативная реализация сети может, например, менять байты в сетевых пакетах местами. Есть даже Actors, имитирующие работу неосторожного сисадмина. Такой может удалить папку с данными или поменять две папки местами. Разработчики гоняют тысячи симуляций, подставляя разных Actors, и с помощью Flow добиваются 100% воспроизводимости: если какой-то тест упал, они могут перезапустить симуляцию и получить падение в том же самом месте. В частности, чтобы исключить неопределенность, вносимую при переключении нитей планировщиком ОС, каждый процесс FoundationDB строго однопоточный.
Когда исследователя, обнаружившего сценарии потери данных практически во всех популярных NoSQL-решениях, попросили протестировать FoundationDB, он отказался, отметив, что не видит в этом смысла, поскольку авторы проделали гигантскую работу и их тестирование гораздо глубже и основательнее его собственного.
Принято упрощенно думать, что сбои в кластере случайны, однако опытные devops знают, что это далеко не так. Если у вас 10 тысяч дисков одного производителя и столько же другого, то частота сбоев (failure rate) у них будет разной. В FoundationDB возможна так называемая machine-aware конфигурация, в которой можно указать кластеру, какие машины находятся в одном дата-центре и какие процессы находятся на одной машине. БД будет учитывать это при распределении нагрузки между машинами. А еще у машин в кластере обычно разные характеристики. FoundationDB это тоже учитывает, смотрит длину очередей запросов и перераспределяет нагрузку сбалансировано: более слабые машины получают меньше запросов.
Итак, FoundationDB дает ACID-транзакции и самый высокий уровень изоляции, Serializable, на кластере из тысяч машин. Вместе с удивительной гибкостью и высокой производительностью это звучит как волшебство. Но за всё нужно платить, поэтому есть некоторые технологические ограничения.
Помимо уже упомянутых пределов на размеры и длину транзакции, важно отметить следующие особенности:
В переводе с английского «Foundation» означает «Основание» и авторы этой СУБД видят ее роль именно так: предоставлять высокий уровень надежности на уровне простых записей, а любая другая БД может быть реализована как надстройка над базовым функционалом. Таким образом, поверх FoundationDB потенциально можно делать разные другие слои — документы, графы, и т.д. Остается вопрос, как эти слои будут масштабироваться, не теряя производительности. Например, авторы CockroachDB уже шли этим путем — сделав слой SQL поверх RocksDB (локальный key value store) и получили проблемы производительности, присущие реляционным джойнам.
На сегодняшний день Apple разработала и опубликовала 2 слоя поверх FoundationDB: Document Layer (поддерживает MongoDB API) и Record Layer (хранит записи как наборы полей в формате Protocol Buffers, поддерживает индексы, доступен только на Java). Радует и приятно удивляет, что исторически закрытая компания Apple сегодня идет по стопам Google и Microsoft и публикует исходный код используемых внутри технологий.
В разработке ПО есть такой экзистенциальный конфликт: бизнес постоянно хочет от продукта изменений, улучшений. Но при этом хочет надежный софт. А эти два требования противоречат друг другу, потому что когда софт меняется, появляются баги и бизнес от этого страдает. Поэтому если в вашем продукте вы можете опереться на какую-то надежную, проверенную технологию и меньше кода писать самому, это всегда стоит сделать. В этом смысле, невзирая на определенные ограничения, круто иметь возможность не лепить костыли к разным NoSQL-базам данных, а использовать проверенное в продакшене решение с ACID-свойствами.
Год назад мы оптимистично смотрели на другую технологию — CockroachDB, но она не оправдала наших ожиданий по производительности. С тех пор мы потеряли аппетит к идее SQL-слоя над распределенным key-value store и поэтому не стали внимательно смотреть, например, на TiDB. Мы планируем осторожно попробовать FoundationDB как вторичную БД для самых крупных массивов данных в нашем проекте. Если у вас уже есть опыт реального использования FoundationDB или TiDB в проде, будем рады услышать ваше мнение в комментариях.
FoundationDB — это распределенная NoSQL база данных с ACID-транзакциями уровня Serializable, хранящая отсортированные пары ключ-значение (ordered key-value store). Ключами и значениями могут быть произвольные последовательности байт. У неё нет единой точки падения — все машины кластера равноправны. Она сама распределяет данные по серверам кластера и масштабируется на лету: когда в кластер нужно добавить ресурсов, ты просто добавляешь адрес новой машины на конфигурационных серверах и база сама подхватывает ее.
В FoundationDB транзакции никогда не блокируют друг друга. Чтение реализовано через мультиверсионный контроль версий (MVCC), а запись — через оптимистичный контроль параллелизма (OCC). Разработчики заявляют, что когда все машины кластера в одном дата-центре, то задержка на запись данных (write latency) составляет 2-3 мс, а на чтение (read latency) — меньше миллисекунды. В документации встречаются оценки в 10-15 мс, что, вероятно, ближе к результатам в реальных условиях.
* Не поддерживает ACID-свойства на нескольких шардах.У FoundationDB есть уникальное преимущество — автоматический решардинг. СУБД сама обеспечивает равномерную загрузку машин в кластере: при переполнении одного сервера она в фоновом режиме перераспределяет данные на соседние. При этом сохраняется гарантия уровня Serializable на все транзакции, а единственный заметный клиентам эффект — это незначительное увеличение задержки ответов (latency). БД следит, чтобы объем данных на наиболее и наименее загруженных серверах кластера отличался не более, чем на 5%.
Архитектура
Логически кластер FoundationDB представляет собой набор однотипных процессов на разных физических машинах. У процессов нет собственных конфигурационных файлов, поэтому они взаимозаменяемы. Несколько фиксированных процессов имеют выделенную роль — Coordinators, и каждый процесс кластера при старте знает их адреса. Важно, чтобы падения Coordinators были максимально независимыми, поэтому их лучше размещать на разных физических машинах или даже в разных дата-центрах.
Coordinators договариваются между собой через консенсус-алгоритм Paxos. Они выбирают процесс Cluster Controller, который дальше назначает роли остальным процессам кластера. Cluster Controller непрерывно сообщает всем Coordinators, что он жив. Если большинство Coordinators считает, что он умер, они просто выбирают нового. Ни Cluster Controller, ни Coordinators не участвуют в обработке транзакций, их главная задача — исключить ситуацию split brain.
Когда клиент хочет подключиться к БД, он обращается сразу ко всем Coordinators за адресом текущего Cluster Controller. Если большинство ответов совпало, он получает из Cluster Controller полную текущую конфигурацию кластера (если не совпало — обращается к Coordinators повторно).
Cluster Controller знает общее число доступных процессов и распределяет роли: эти 5 будут Proxy, эти 2 — Resolver, этот — Master. И если какой-то из них умрёт, то он тут же найдет ему замену, назначив произвольному свободному процессу нужную роль. Это все происходит в фоне, незаметно для прикладного программиста.
Процесс Master отвечает за номер текущей версии набора данных (она увеличивается при каждой записи в БД), а также за распределение множества ключей по серверам хранения (storage servers) и rate-throttling (искусственное занижение производительности при больших нагрузках: если кластер знает, что клиент сделает много маленьких запросов, он подождет, сгруппирует их и ответит на всю пачку сразу).
Transaction logging и Storage — это две независимые подсистемы хранения данных. Первая — временное хранилище для быстрой записи данных на диск в порядке поступления, вторая — постоянное хранилище, где данные на диске отсортированы в порядке возрастания ключей. При каждом коммите транзакции как минимум три tLog-процесса должны сохранить данные, прежде чем кластер сообщит клиенту об успехе. Параллельно данные в фоне переезжают с tLog-серверов на Storage-сервера (хранение на которых также избыточное).
Обработка запросов
Все клиентские запросы обрабатывают процессы Proxy. Открывая транзакцию, клиент обращается к любому Proxy, тот опрашивает все остальные Proxy, и возвращает текущий номер версии данных кластера. Все последующие чтения происходят по этому номеру версии. Если другой клиент записал данные после того, как я открыл транзакцию, я его изменения просто не увижу.
Запись транзакции немного сложнее, поскольку нужно разруливать конфликты. Здесь включается процесс Resolver, который хранит в памяти все модифицированные ключи за некоторый период времени. Когда клиент завершает (commit) транзакцию записи, Resolver проверяет, не устарели ли данные, которые она читала. (То есть не было ли завершено транзакции, которая была открыта позже моей и изменила ключи, которые я читал.) Если такое произошло, транзакцию откатывают и клиентская библиотека сама(!) делает повторную попытку коммита. Единственное, о чём должен думать разработчик, — это чтобы транзакции были идемпотентные, то есть повторное применение должно давать идентичный результат. Один из способов добиться этого — сохранять в рамках транзакции какое-то уникальное значение, а в начале транзакции проверять его наличие в базе.
Как и в любой клиент-серверной системе бывают ситуации, когда транзакция завершена успешно, но клиент не получил подтверждение из-за обрыва связи. Клиентская библиотека относится к ним, как и к любой другой ошибке, — она просто повторяет попытку. Это потенциально может привести к повторному выполнению всей транзакции. Однако, если транзакция идемпотентная, никакой проблемы в этом нет — на итоговый результат это не повлияет.
Масштабирование
В подсистеме хранения данных (Storage) могут быть тысячи серверов. К какому из них клиент должен обратиться, когда нужны данные по определенному ключу? От Cluster Controller клиент знает полную конфигурацию всего кластера, а она включает диапазоны ключей на каждом Storage-сервере. Поэтому он просто обращается напрямую к нужным Storage-серверам без каких-либо промежуточных запросов.
Если нужный Storage-сервер недоступен, то клиентская библиотека берет у Cluster Controller новую конфигурацию. Если в результате падения сервера кластер понимает, что избыточность недостаточна, он сразу же начинает собирать новую ноду из кусочков других Storage.
Предположим, что вы сохраняете в транзакции гигабайты данных. Как можно обеспечить быстрый отклик? Никак, и поэтому в FoundationDB просто ограничили размер одной транзакции 10 мегабайтами. Причем это ограничение на все данные, которых транзакция касается — читает или записывает. Каждая запись в БД тоже ограничена — ключ не может превышать 10 килобайт, значение — 100 килобайт. (При этом для оптимальной производительности разработчики рекомендуют ключи длиной 32 байта, а значения длиной 10 килобайт.)
Любая транзакция потенциально может стать источником конфликта, и тогда ее придется откатить. Поэтому ради скорости, пока не пришла команда commit, текущие изменения имеет смысл держать в оперативной памяти, а не на диске. Допустим, вы пишете данные в БД с нагрузкой 1GB/секунду. Тогда ваш кластер в экстремальном случае будет каждую секунду аллоцировать 3GB RAM (мы же пишем транзакции на 3 машинах). Как ограничить такой лавинообразный рост используемой памяти? Очень просто — ограничить максимальное время транзакции. В FoundationDB транзакция не может длится больше 5 секунд. Если клиент попытается обратиться к БД спустя 5 секунд после открытия транзакции, кластер будет игнорировать все его команды, пока он не откроет новую.
Индексы
Предположим вы храните список людей, у каждого человека есть уникальный идентификатор, его используем в качестве ключа, а в значении пишем все остальные атрибуты — имя, пол, возраст, и т.д.
| Ключ | Значение |
| 12345 | (Иванов Иван Иванович, М, 35) |
Как получить список всех людей, которым 30 лет без полного перебора? Обычно для этого в БД создают индекс. Индекс — это другое представление данных, созданное для быстрого поиска по дополнительным атрибутам. Мы можем просто добавить записи вида:
| Ключ | Значение |
| (35, 12345) | ‘’ |
Теперь чтобы получить нужный список вам достаточно выполнить поиск по диапазону ключей (30, *). Поскольку FoundationDB хранит данные отсортированными по ключам, то такой запрос выполнится очень быстро. Конечно, индекс занимает дополнительное место на диске, но совсем немного. Обратите внимание, что дублируются не все атрибуты, а только возраст и идентификатор.
Важно, чтобы операции добавления самой записи и индекса на нее выполнялись в одной транзакции.
Надежность
FoundationDB написана на C++. Работу над ней авторы начали в 2009 году, первая версия была выпущена в 2013-м, а в марте 2015-го их купила корпорация Apple. Спустя три года Apple неожиданно открыла исходный код. Ходят слухи, что Apple использует ее, среди прочего, для хранения данных сервиса iCloud.
Опытные разработчики обычно не сразу доверяют новым решениям. Могут пройти годы, прежде чем технология надежно зарекомендует себя и ее начнут массово использовать в проде. Чтобы сократить это время, авторы сделали интересное расширение языка C++: Flow. Оно позволяет изящно эмулировать работу с ненадежными внешними компонентами с возможностью полного предсказуемого повтора выполнения программы. Каждый вызов к сети или диску оборачивается в некоторую обертку (Actor), а каждый Actor имеет несколько реализаций. Стандартная реализация пишет данные на диск или в сеть, как и предполагалось. А другая пишет на диск 999 раз из 1000, а 1 раз из 1000 теряет. Альтернативная реализация сети может, например, менять байты в сетевых пакетах местами. Есть даже Actors, имитирующие работу неосторожного сисадмина. Такой может удалить папку с данными или поменять две папки местами. Разработчики гоняют тысячи симуляций, подставляя разных Actors, и с помощью Flow добиваются 100% воспроизводимости: если какой-то тест упал, они могут перезапустить симуляцию и получить падение в том же самом месте. В частности, чтобы исключить неопределенность, вносимую при переключении нитей планировщиком ОС, каждый процесс FoundationDB строго однопоточный.
Когда исследователя, обнаружившего сценарии потери данных практически во всех популярных NoSQL-решениях, попросили протестировать FoundationDB, он отказался, отметив, что не видит в этом смысла, поскольку авторы проделали гигантскую работу и их тестирование гораздо глубже и основательнее его собственного.
Принято упрощенно думать, что сбои в кластере случайны, однако опытные devops знают, что это далеко не так. Если у вас 10 тысяч дисков одного производителя и столько же другого, то частота сбоев (failure rate) у них будет разной. В FoundationDB возможна так называемая machine-aware конфигурация, в которой можно указать кластеру, какие машины находятся в одном дата-центре и какие процессы находятся на одной машине. БД будет учитывать это при распределении нагрузки между машинами. А еще у машин в кластере обычно разные характеристики. FoundationDB это тоже учитывает, смотрит длину очередей запросов и перераспределяет нагрузку сбалансировано: более слабые машины получают меньше запросов.
Итак, FoundationDB дает ACID-транзакции и самый высокий уровень изоляции, Serializable, на кластере из тысяч машин. Вместе с удивительной гибкостью и высокой производительностью это звучит как волшебство. Но за всё нужно платить, поэтому есть некоторые технологические ограничения.
Ограничения
Помимо уже упомянутых пределов на размеры и длину транзакции, важно отметить следующие особенности:
- Язык запросов — не SQL, то есть разработчикам с опытом SQL придется переучиваться.
- Клиентская библиотека поддерживает только 5 высокоуровневых языков (Phyton, Ruby, Java, Golang и C). Пока нет официального клиента для C#. Поскольку нет REST API, то единственный способ поддержать другой язык — это написать на нем обертку поверх стандартной библиотеки на C.
- Нет механизмов разделения доступа, всю эту логику должно обеспечивать ваше приложение.
- Не документирован формат хранения данных (хотя в коммерческих базах данных он тоже обычно не документируется). Это риск, потому что если вдруг кластер не соберется, то сходу непонятно, что делать и придется копаться в исходных файлах.
- Строго асинхронная модель программирования может казаться сложной начинающим разработчикам.
- Нужно постоянно думать об идемпотентности транзакций.
- Если придется разбивать длинные транзакции на маленькие, то о целостности на глобальном уровне нужно заботиться самому.
В переводе с английского «Foundation» означает «Основание» и авторы этой СУБД видят ее роль именно так: предоставлять высокий уровень надежности на уровне простых записей, а любая другая БД может быть реализована как надстройка над базовым функционалом. Таким образом, поверх FoundationDB потенциально можно делать разные другие слои — документы, графы, и т.д. Остается вопрос, как эти слои будут масштабироваться, не теряя производительности. Например, авторы CockroachDB уже шли этим путем — сделав слой SQL поверх RocksDB (локальный key value store) и получили проблемы производительности, присущие реляционным джойнам.
На сегодняшний день Apple разработала и опубликовала 2 слоя поверх FoundationDB: Document Layer (поддерживает MongoDB API) и Record Layer (хранит записи как наборы полей в формате Protocol Buffers, поддерживает индексы, доступен только на Java). Радует и приятно удивляет, что исторически закрытая компания Apple сегодня идет по стопам Google и Microsoft и публикует исходный код используемых внутри технологий.
Перспективы
В разработке ПО есть такой экзистенциальный конфликт: бизнес постоянно хочет от продукта изменений, улучшений. Но при этом хочет надежный софт. А эти два требования противоречат друг другу, потому что когда софт меняется, появляются баги и бизнес от этого страдает. Поэтому если в вашем продукте вы можете опереться на какую-то надежную, проверенную технологию и меньше кода писать самому, это всегда стоит сделать. В этом смысле, невзирая на определенные ограничения, круто иметь возможность не лепить костыли к разным NoSQL-базам данных, а использовать проверенное в продакшене решение с ACID-свойствами.
Год назад мы оптимистично смотрели на другую технологию — CockroachDB, но она не оправдала наших ожиданий по производительности. С тех пор мы потеряли аппетит к идее SQL-слоя над распределенным key-value store и поэтому не стали внимательно смотреть, например, на TiDB. Мы планируем осторожно попробовать FoundationDB как вторичную БД для самых крупных массивов данных в нашем проекте. Если у вас уже есть опыт реального использования FoundationDB или TiDB в проде, будем рады услышать ваше мнение в комментариях.

