Чем высоконагруженная информационная система похожа на огромный гипермаркет? Что делать, если 150 млн человек одновременно придут в гипермаркет за покупками? За что можно наказать руководителя гипермаркета, а за что нет? Почему время загрузки документа ночью намного меньше, чем днем? Почему время загрузки одного документа на самом деле ни о чем не говорит?
Высоконагруженные информационные системы имеют свои особенности, которые не очевидны для многих организаций-поставщиков. Мы расскажем, как устроена массовая загрузка документов (и других данных) и подробно рассмотрим этот непонятный для многих вопрос.
 Источник
Источник
При разработке крупных и высоконагруженных информационных систем (ИС) возникают задачи массовой загрузки данных. Тип данных не имеет значения и зависит от вашей предметной области. Это могут быть платежи, счета, показания датчиков, проекты закупок и т.д. Создание и развитие ГИС (государственных информационных систем) регламентируется законодательством и легко может случиться так, что закон обяжет организации разово загрузить в систему миллионы документов или, что еще интереснее, загружать миллионы документов на периодической основе, например, ежемесячно.
В своих проектах (немного про работу ЛАНИТ можно почитать тут и тут) мы периодически сталкиваемся с такими задачами и выработали все необходимые решения. Однако специфика решений имеет некоторые особенности, которые, как оказалось, не очевидны для многих организаций-поставщиков. К нашему удивлению, мы получали такие запросы и даже претензии:
Тот факт, что загрузка одного документа в информационную систему может занимать 10 секунд, сам по себе ничего не говорит о системе. Этот показатель вообще не имеет большого смысла, если мы говорим о системах массового обслуживания с очередями. Далее мы расскажем, как устроена массовая загрузка документов (и других данных) и подробно рассмотрим этот непонятный для многих вопрос.
По поводу ошибок загрузки также не все очевидно: есть много причин, по которым данные не загружаются в систему. Проблемы могут быть на стороне поставщиков информации и могут быть на стороне ИС. Ниже мы разберем разные ситуации и посмотрим статистику.
Допустим, в далекой китайской провинции, где проживают примерно 150 млн человек, имеется только один большой круглосуточный гипермаркет, куда население раз в месяц ходит закупаться рисом. Жители могут прийти за рисом в любой день месяца. Риса много, места в торговом зале тоже много. Основное узкое место – это оплата покупок на кассе, так как эта операция обязательная (нельзя пропускать покупателей без оплаты), требует времени и использования специального оборудования – касс. Для гипермаркета было бы лучше, чтобы люди как-то договорились между собой и приходили за покупками равномерно (и ночью, и днем), в этом случае использование касс было бы максимально эффективно.
Однако, как назло, покупатели не идут навстречу гипермаркету. Во-первых, они как-то не очень хотят ходить за покупками ночью. Во-вторых, иногда беспредельничают: то никого нет, то одновременно приходят несколько миллионов человек.
 Источник. Самый крупный торговый центр в мире New Century Global Center в г. Чэнду в Китае. Он имеет 18 этажей и площадь 1 700 000 кв.м.
Источник. Самый крупный торговый центр в мире New Century Global Center в г. Чэнду в Китае. Он имеет 18 этажей и площадь 1 700 000 кв.м.
Что делать гипермаркету? Компартия Китая поставила задачу обслуживать всех китайцев и всё тут. Каждый необслуженный китаец – это минус в карму начальника гипермаркета. Если недовольных китайцев станет слишком много, не сносить ему своей головушки! При этом, конечно, поставить 150 млн касс руководитель не может. Если вдруг через год хитрый контроллер принесёт отчет о том, что кассы используются на 1%, то несчастного директора ждет незавидная судьба. Если рядовой покупатель будет ждать слишком долго (больше минуты), то он с криками «пятисот четире гатеванау тамеаут хана вам всем нафиг» выбежит из гипермаркета и напишет заявление самому товарищу Мао.
Подсмотрев за океаном, как что работает, наш товарищ внедрил продвинутую систему управления очередями. Теперь это всё работает так. Взяв пачку с рисом, покупатель идет к терминалу получать номер в очереди. Время ожидания в очереди зависит от количества касс. Экспериментальным путем товарищ директор выяснил, сколько касс должно быть, чтобы покупатели, с одной стороны, слишком долго не стояли в очереди, а с другой стороны, коэффициент использования касс не был слишком низким.
 Источник
Источник
Все довольны. Система выдачи билетиков очень простая и работает всегда быстро. Количество касс подбирается таким образом, чтобы:
Примерно так же должна быть устроена ИС в части массового приема документов. Например, мы должны каждый месяц обеспечивать загрузку совокупно не менее 150 млн документов от 100 тыс. поставщиков. Для того, чтобы качество загруженных данных было высоким, необходимо все данные проверить перед загрузкой. Некорректные данные отбрасываются. А корректные должны быть разложены в структурированной форме в хранилище системы так, чтобы их можно было анализировать и использовать в дальнейшем.
Необходимость проверять данные перед загрузкой приводит к тому, что нужно выполнить ряд «контролей», начиная от форматных и заканчивая сложными (например, иногда необходим бизнес-контроль, доказывающий что организация имеет основание для загрузки передаваемых объектов).
Качеством проверок мы обычно жертвовать не можем. Считаем, что разработчики уже оптимизировали все алгоритмы и дальнейшая оптимизация слишком трудоемка или усложняет дальнейшее сопровождение и развитие системы. На наших проектах время обработки одного запроса, содержащего от одного до пятисот документов (платеж, счет, договор, проект закупки и т.п.), в среднем составляет несколько секунд на бекенде (см. пример на рисунке 1). Это время не является константным, а колеблется в некоторых пределах, так как в сложной системе всегда очень много различных факторов, которые могут повлиять на обработку пакета.
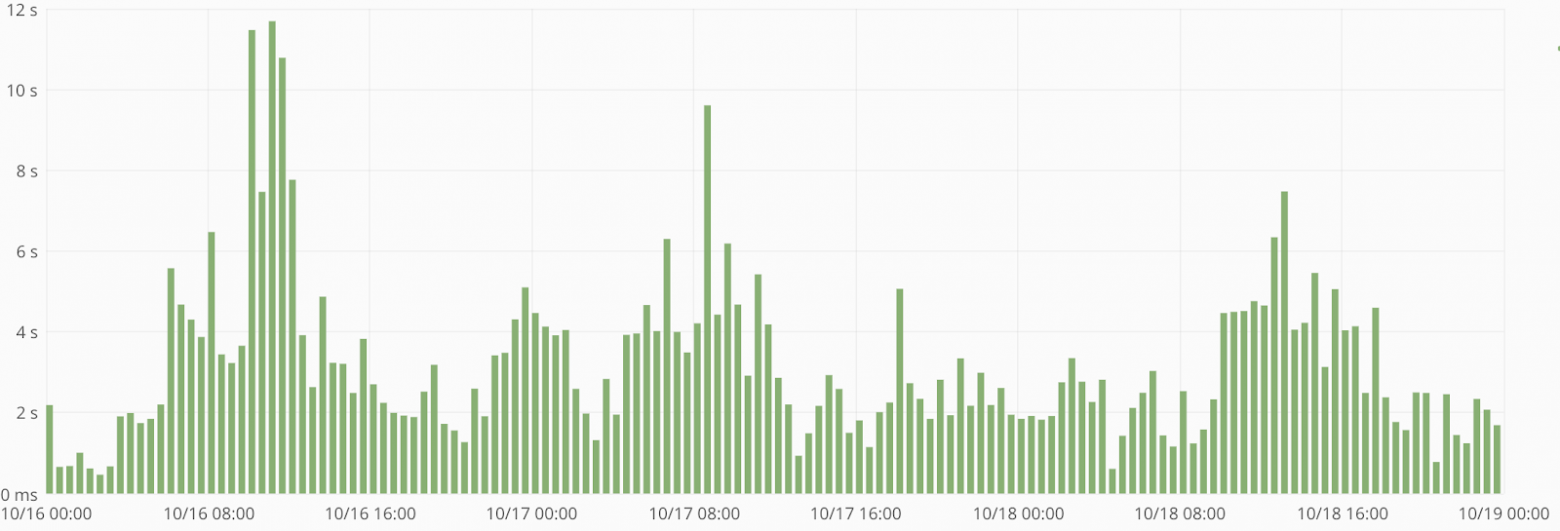 Рисунок 1. Типичный график времени обработки пакетов документов. Среднее время в районе трех секунд.
Рисунок 1. Типичный график времени обработки пакетов документов. Среднее время в районе трех секунд.
Даже если для вашей ИС сроки загрузки регламентируются законодательством, то для поставщиков документов, как правило, нет четкого плана-графика загрузки. Для разных типов документов имеются определенные шаблоны, например, счета могут выставляться в начале месяца, пики по загрузке других данных могут определяться сроками из НПА или быть связаны с концом года и т.д.
Поэтому на практике в каждый конкретный момент интенсивность загрузки документов бывает очень разной — точно предусмотреть это практически невозможно. Может так случиться, что все 150 млн документов добрые поставщики решат загрузить в систему одновременно. А это совсем не одно и то же, как если бы они их загружали строго по расписанию по 5 млн в сутки.
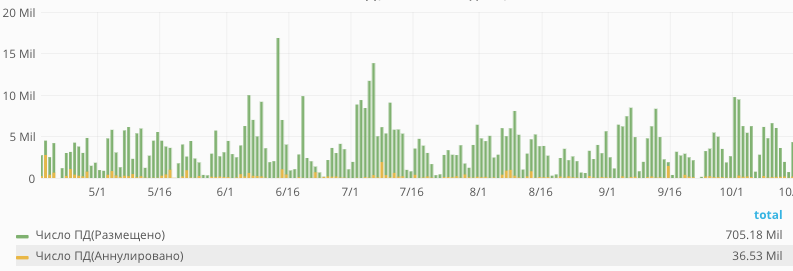 Рисунок 2. Пример распределения количества загруженных документов по суткам за последние полгода.
Рисунок 2. Пример распределения количества загруженных документов по суткам за последние полгода.
На рисунке 2 видно, что число загруженных за сутки документов колеблется в широких пределах. Понятно, что в среднем загружается примерно 4-5 млн документов в день. При этом в какие-то дни в систему было отправлено более 10 млн документов. Максимальное количество загруженных документов за сутки — более 17 млн.
Если мы посмотрим на почасовую динамику загрузки документов, то мы увидим еще большие колебания по трафику. В какие-то часы в ИС загружается по 50 тыс. документов, а в какие-то часы число загруженных документов превышает 1 млн. Чем меньший интервал мы берем, тем больший разброс по нагрузке мы видим.
Очевидно, что в систему одновременно может поступить и два, и три, и десять млн документов. Поэтому при проектировании механизмов массовой загрузки мы используем буферизацию запросов с помощью очередей. Любой запрос от пользователя сначала сохраняется в очереди. Таким образом мы можем принимать в систему запросы на прием документов с очень большой интенсивностью, ведь операция приема запроса очень простая. А вот валидация и загрузка документа делается уже специальными «обработчиками», количество которых настраивается в зависимости от имеющихся мощностей. Чем больше железа, тем больше «обработчиков», тем больше запросов одновременно система может обработать.
Мощность программно-аппаратного комплекса ИС определяется требуемой пропускной способностью и затратами на железо. Нужно найти баланс, чтобы нас (заказчика) устраивал коэффициент использования железа в периоды низкой загрузки, и при этом в пиковые периоды очередь данных на загрузку не росла слишком сильно. С учетом того, что ночью чаще всего мы получаем естественное снижение нагрузки, то можно пользоваться ориентиром — все данные должны загружаться либо в тот же день, либо за ночь. Если всё чаще случается, что данные не успевают загрузиться за ночь, то это сигнал увеличить пропускную способность за счет добавления железа.
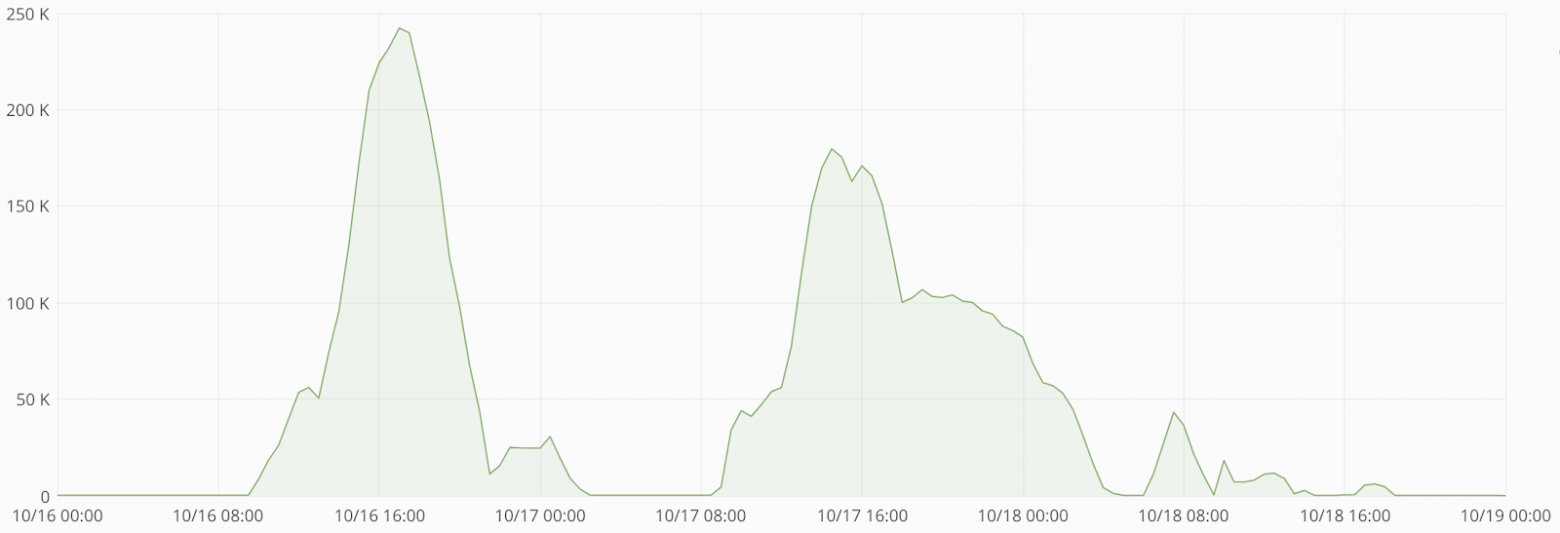 Рисунок 3. Пример графика изменения длины очереди на загрузку пакетов данных.
Рисунок 3. Пример графика изменения длины очереди на загрузку пакетов данных.
На рисунке 3 показана статистика по длине очереди на загрузку пакетов данных. Необходимо обратить внимание, что в дневные часы мы имеем характерный горб, а ночью очередь обнуляется.
Поскольку время загрузки пакета данных складывается из времени ожидания в очереди и времени обработки пакета данных на бекенде, то время загрузки ночью гораздо меньше, чем днем (см. рисунок 4).
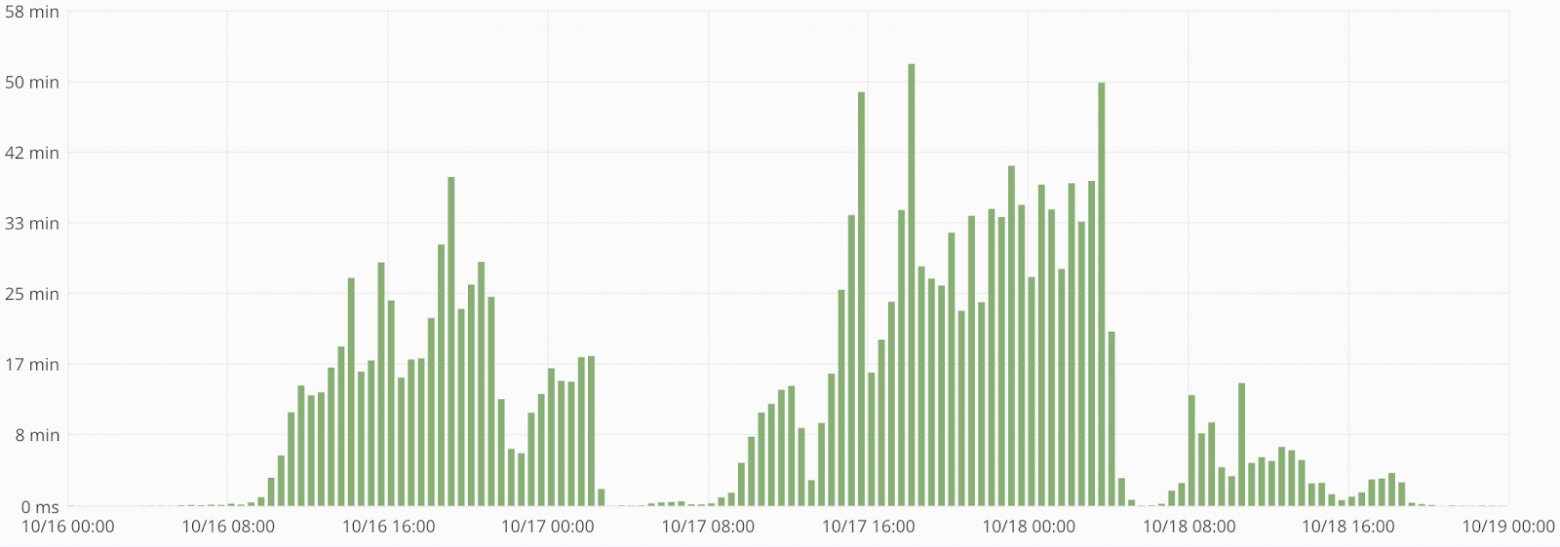 Рисунок 4. Время загрузки пакетов данных. Среднее за период составило 11,92 минуты. Время загрузки включает время ожидания в очереди и время обработки на бекенде.
Рисунок 4. Время загрузки пакетов данных. Среднее за период составило 11,92 минуты. Время загрузки включает время ожидания в очереди и время обработки на бекенде.
Можно сделать вывод: если поставщик отправит пакет данных ночью, время загрузки будет минимальное. С другой стороны, если мощности ИС подобраны таким образом, чтобы обрабатывать предполагаемый объем данных в тот же день или максимум за ночь, то поставщику нет смысла придерживать загрузку данных — нужно просто отправить весь объем документов, и он обработается максимально быстро.
Вернёмся к нашим претензиям. «Мы отправили на загрузку один документ, и он загружался целых 10 секунд. Поэтому, если нашей организации нужно будет загрузить 100 тыс. документов, у нас это займет 100 000 * 10 / 3600 = 277 часов!»
Каждый покупатель, приходя в гипермаркет в разные моменты, может быть обслужен за разное время. Оно будет зависеть от того, сколько покупателей пришли в магазин. Ночью кассы, скорее всего, будут пустые и покупателя обслужат немедленно. А в час пик можно зависнуть в очереди на несколько часов.
 Источник
Источник
Что делать, если нужно закупить рис на деревню из 100 тыс. жителей? Не имеет смысла отправлять каждого жителя деревни в гипермаркет друг за другом (следующий выходит только после того, как вернется предыдущий). Очевидно, что в этом случае покупка риса на всю деревню растянется на многие часы или сутки, так как придется отстоять очередь последовательно 100 тысяч раз. С другой стороны, если все жители деревни разом придут в гипермаркет, встанут в очередь все вместе, то они отстоят очередь одновременно. По сути они отстоят очередь только один раз. Время их ожидания в очереди будет также существенно зависеть от количества работающих касс.
Иными словами, на время загрузки большого количества данных влияет текущая нагрузка на систему (количество пакетов в очереди) и пропускная способность системы (интенсивность, с которой эти пакеты обрабатываются). Такой показатель как время загрузки отдельного пакета сам по себе недостаточен и ведет к ошибочным выводам.
Чтобы загрузить большой объем данных в ИС, не нужно отправлять запросы последовательно, дожидаясь обработки предыдущего. Нужно отправить в ИС сразу все запросы, они будут помещены в очередь и будут обработаны специальными «обработчиками» с интенсивностью, зависящей от имеющихся мощностей и возможностей. Очевидно, что обычно пропускная способность ИС значительно превосходит потребности каждого конкретного поставщика данных.
Как следствие, синхронные методы не годятся для массовой загрузки — это антипаттерн.
Что больше всего в этой истории волнует товарища директора? За что его могут наказать.
Покупателю может быть отказано в обслуживании – это всегда неприятно. Но причин, по которым такое может случиться, много, и они имеют разную природу. Давайте перечислим.
1. Если система выдачи талончиков в очередь не работает, это совсем плохо. Это прямо настолько плохо, что такие ситуации на следующий день разбираются прямо в кабинете товарища Мао.
2. Если очередь в гипермаркете увеличивается и покупатели начинают там надолго зависать, то это подозрительно, но не обязательно сразу плохо. За этим надо следить, но бывают две ситуации:
3. Если конкретный китаец не может приобрести рис, то это также может быть по разным причинам:
Понятно, что для любой ИС важной характеристикой механизмов массовой загрузки является доля отказов в обслуживании. Необходимо различать отказ в обслуживании по техническим причинам, связанным с работой ИС (отказ оборудования, системная ошибка и т. п.), и отказы по причинам, связанным с проблемами на стороне поставщика (некорректный формат пакета данных, некорректные данные с точки зрения бизнес-контролей и др.).
Ситуации могут быть разные. Но если ИС была разработана с учетом изложенных выше принципов и имеется процесс постоянного отслеживания и устранения технических ошибок, то рано или поздно ситуация стабилизируется. В хорошо работающей системе статистика по загрузке пакетов выглядит примерно как в таблице 1.
Таблица 1. Статистика по загрузке за июль 2018 года
Из таблицы видно, что большинство пакетов успешно загружаются. При этом высока доля ошибок на стороне поставщика информации. Это может быть связано с большим количеством поставщиков и разной степенью их готовности к информационному обмену. У поставщиков могут быть некачественные данные, у них могут быть проблемы с информационными системами. Какие-то данные могут отсутствовать в электронной структурированной форме, и требуется время для того, чтобы их получить.
К сожалению, ошибки ИС могут возникать, особенно, если идет её бурное развитие. Важно, чтобы был запущен процесс мониторинга ошибок в промышленной среде и анализ причин их возникновения. Мы на своих проектах в ЛАНИТ используем развитую систему мониторинга интеграционных механизмов, и если видим, что количество ошибок начинает расти, то определяем их источник и стараемся оперативно предпринять корректирующие действия.
В заключение хотелось бы еще раз повторить основные тезисы.
Высоконагруженные информационные системы имеют свои особенности, которые не очевидны для многих организаций-поставщиков. Мы расскажем, как устроена массовая загрузка документов (и других данных) и подробно рассмотрим этот непонятный для многих вопрос.
При разработке крупных и высоконагруженных информационных систем (ИС) возникают задачи массовой загрузки данных. Тип данных не имеет значения и зависит от вашей предметной области. Это могут быть платежи, счета, показания датчиков, проекты закупок и т.д. Создание и развитие ГИС (государственных информационных систем) регламентируется законодательством и легко может случиться так, что закон обяжет организации разово загрузить в систему миллионы документов или, что еще интереснее, загружать миллионы документов на периодической основе, например, ежемесячно.
В своих проектах (немного про работу ЛАНИТ можно почитать тут и тут) мы периодически сталкиваемся с такими задачами и выработали все необходимые решения. Однако специфика решений имеет некоторые особенности, которые, как оказалось, не очевидны для многих организаций-поставщиков. К нашему удивлению, мы получали такие запросы и даже претензии:
- «Мы отправили на загрузку один документ, и он загружался целых 10 секунд. Поэтому если нашей организации нужно будет загрузить 100 тыс. документов, то у нас это займет 100 000*10/3600=277 часов!»
- «Мы грузим-грузим документы, но в систему ничего не загружается».
Тот факт, что загрузка одного документа в информационную систему может занимать 10 секунд, сам по себе ничего не говорит о системе. Этот показатель вообще не имеет большого смысла, если мы говорим о системах массового обслуживания с очередями. Далее мы расскажем, как устроена массовая загрузка документов (и других данных) и подробно рассмотрим этот непонятный для многих вопрос.
По поводу ошибок загрузки также не все очевидно: есть много причин, по которым данные не загружаются в систему. Проблемы могут быть на стороне поставщиков информации и могут быть на стороне ИС. Ниже мы разберем разные ситуации и посмотрим статистику.
Китайский гипермаркет
Допустим, в далекой китайской провинции, где проживают примерно 150 млн человек, имеется только один большой круглосуточный гипермаркет, куда население раз в месяц ходит закупаться рисом. Жители могут прийти за рисом в любой день месяца. Риса много, места в торговом зале тоже много. Основное узкое место – это оплата покупок на кассе, так как эта операция обязательная (нельзя пропускать покупателей без оплаты), требует времени и использования специального оборудования – касс. Для гипермаркета было бы лучше, чтобы люди как-то договорились между собой и приходили за покупками равномерно (и ночью, и днем), в этом случае использование касс было бы максимально эффективно.
Однако, как назло, покупатели не идут навстречу гипермаркету. Во-первых, они как-то не очень хотят ходить за покупками ночью. Во-вторых, иногда беспредельничают: то никого нет, то одновременно приходят несколько миллионов человек.
Что делать гипермаркету? Компартия Китая поставила задачу обслуживать всех китайцев и всё тут. Каждый необслуженный китаец – это минус в карму начальника гипермаркета. Если недовольных китайцев станет слишком много, не сносить ему своей головушки! При этом, конечно, поставить 150 млн касс руководитель не может. Если вдруг через год хитрый контроллер принесёт отчет о том, что кассы используются на 1%, то несчастного директора ждет незавидная судьба. Если рядовой покупатель будет ждать слишком долго (больше минуты), то он с криками «пятисот четире гатеванау тамеаут хана вам всем нафиг» выбежит из гипермаркета и напишет заявление самому товарищу Мао.
Подсмотрев за океаном, как что работает, наш товарищ внедрил продвинутую систему управления очередями. Теперь это всё работает так. Взяв пачку с рисом, покупатель идет к терминалу получать номер в очереди. Время ожидания в очереди зависит от количества касс. Экспериментальным путем товарищ директор выяснил, сколько касс должно быть, чтобы покупатели, с одной стороны, слишком долго не стояли в очереди, а с другой стороны, коэффициент использования касс не был слишком низким.
Все довольны. Система выдачи билетиков очень простая и работает всегда быстро. Количество касс подбирается таким образом, чтобы:
- коэффициент использования касс позволил товарищу директору жить долго и счастливо;
- длина очереди была небольшой и китайцы проводили в ней мало времени (95 процентиль времени ожидания < разумного значения, например, 5 минут);
- даже если в результате стечения обстоятельств в магазин одновременно пришли бы много покупателей, то время ожидания растянется, но они будут обслужены часов до 23:00 вечера, чтобы они смогли вернуться домой и посмотреть выпуск новостей перед сном.
Примерно так же должна быть устроена ИС в части массового приема документов. Например, мы должны каждый месяц обеспечивать загрузку совокупно не менее 150 млн документов от 100 тыс. поставщиков. Для того, чтобы качество загруженных данных было высоким, необходимо все данные проверить перед загрузкой. Некорректные данные отбрасываются. А корректные должны быть разложены в структурированной форме в хранилище системы так, чтобы их можно было анализировать и использовать в дальнейшем.
Необходимость проверять данные перед загрузкой приводит к тому, что нужно выполнить ряд «контролей», начиная от форматных и заканчивая сложными (например, иногда необходим бизнес-контроль, доказывающий что организация имеет основание для загрузки передаваемых объектов).
Качеством проверок мы обычно жертвовать не можем. Считаем, что разработчики уже оптимизировали все алгоритмы и дальнейшая оптимизация слишком трудоемка или усложняет дальнейшее сопровождение и развитие системы. На наших проектах время обработки одного запроса, содержащего от одного до пятисот документов (платеж, счет, договор, проект закупки и т.п.), в среднем составляет несколько секунд на бекенде (см. пример на рисунке 1). Это время не является константным, а колеблется в некоторых пределах, так как в сложной системе всегда очень много различных факторов, которые могут повлиять на обработку пакета.
Даже если для вашей ИС сроки загрузки регламентируются законодательством, то для поставщиков документов, как правило, нет четкого плана-графика загрузки. Для разных типов документов имеются определенные шаблоны, например, счета могут выставляться в начале месяца, пики по загрузке других данных могут определяться сроками из НПА или быть связаны с концом года и т.д.
Поэтому на практике в каждый конкретный момент интенсивность загрузки документов бывает очень разной — точно предусмотреть это практически невозможно. Может так случиться, что все 150 млн документов добрые поставщики решат загрузить в систему одновременно. А это совсем не одно и то же, как если бы они их загружали строго по расписанию по 5 млн в сутки.
На рисунке 2 видно, что число загруженных за сутки документов колеблется в широких пределах. Понятно, что в среднем загружается примерно 4-5 млн документов в день. При этом в какие-то дни в систему было отправлено более 10 млн документов. Максимальное количество загруженных документов за сутки — более 17 млн.
Если мы посмотрим на почасовую динамику загрузки документов, то мы увидим еще большие колебания по трафику. В какие-то часы в ИС загружается по 50 тыс. документов, а в какие-то часы число загруженных документов превышает 1 млн. Чем меньший интервал мы берем, тем больший разброс по нагрузке мы видим.
Очевидно, что в систему одновременно может поступить и два, и три, и десять млн документов. Поэтому при проектировании механизмов массовой загрузки мы используем буферизацию запросов с помощью очередей. Любой запрос от пользователя сначала сохраняется в очереди. Таким образом мы можем принимать в систему запросы на прием документов с очень большой интенсивностью, ведь операция приема запроса очень простая. А вот валидация и загрузка документа делается уже специальными «обработчиками», количество которых настраивается в зависимости от имеющихся мощностей. Чем больше железа, тем больше «обработчиков», тем больше запросов одновременно система может обработать.
Мощность программно-аппаратного комплекса ИС определяется требуемой пропускной способностью и затратами на железо. Нужно найти баланс, чтобы нас (заказчика) устраивал коэффициент использования железа в периоды низкой загрузки, и при этом в пиковые периоды очередь данных на загрузку не росла слишком сильно. С учетом того, что ночью чаще всего мы получаем естественное снижение нагрузки, то можно пользоваться ориентиром — все данные должны загружаться либо в тот же день, либо за ночь. Если всё чаще случается, что данные не успевают загрузиться за ночь, то это сигнал увеличить пропускную способность за счет добавления железа.
На рисунке 3 показана статистика по длине очереди на загрузку пакетов данных. Необходимо обратить внимание, что в дневные часы мы имеем характерный горб, а ночью очередь обнуляется.
Поскольку время загрузки пакета данных складывается из времени ожидания в очереди и времени обработки пакета данных на бекенде, то время загрузки ночью гораздо меньше, чем днем (см. рисунок 4).
Можно сделать вывод: если поставщик отправит пакет данных ночью, время загрузки будет минимальное. С другой стороны, если мощности ИС подобраны таким образом, чтобы обрабатывать предполагаемый объем данных в тот же день или максимум за ночь, то поставщику нет смысла придерживать загрузку данных — нужно просто отправить весь объем документов, и он обработается максимально быстро.
Как прокормить целую деревню
Вернёмся к нашим претензиям. «Мы отправили на загрузку один документ, и он загружался целых 10 секунд. Поэтому, если нашей организации нужно будет загрузить 100 тыс. документов, у нас это займет 100 000 * 10 / 3600 = 277 часов!»
Каждый покупатель, приходя в гипермаркет в разные моменты, может быть обслужен за разное время. Оно будет зависеть от того, сколько покупателей пришли в магазин. Ночью кассы, скорее всего, будут пустые и покупателя обслужат немедленно. А в час пик можно зависнуть в очереди на несколько часов.
Что делать, если нужно закупить рис на деревню из 100 тыс. жителей? Не имеет смысла отправлять каждого жителя деревни в гипермаркет друг за другом (следующий выходит только после того, как вернется предыдущий). Очевидно, что в этом случае покупка риса на всю деревню растянется на многие часы или сутки, так как придется отстоять очередь последовательно 100 тысяч раз. С другой стороны, если все жители деревни разом придут в гипермаркет, встанут в очередь все вместе, то они отстоят очередь одновременно. По сути они отстоят очередь только один раз. Время их ожидания в очереди будет также существенно зависеть от количества работающих касс.
Иными словами, на время загрузки большого количества данных влияет текущая нагрузка на систему (количество пакетов в очереди) и пропускная способность системы (интенсивность, с которой эти пакеты обрабатываются). Такой показатель как время загрузки отдельного пакета сам по себе недостаточен и ведет к ошибочным выводам.
Чтобы загрузить большой объем данных в ИС, не нужно отправлять запросы последовательно, дожидаясь обработки предыдущего. Нужно отправить в ИС сразу все запросы, они будут помещены в очередь и будут обработаны специальными «обработчиками» с интенсивностью, зависящей от имеющихся мощностей и возможностей. Очевидно, что обычно пропускная способность ИС значительно превосходит потребности каждого конкретного поставщика данных.
Как следствие, синхронные методы не годятся для массовой загрузки — это антипаттерн.
За что можно наказать товарища директора
Что больше всего в этой истории волнует товарища директора? За что его могут наказать.
Покупателю может быть отказано в обслуживании – это всегда неприятно. Но причин, по которым такое может случиться, много, и они имеют разную природу. Давайте перечислим.
1. Если система выдачи талончиков в очередь не работает, это совсем плохо. Это прямо настолько плохо, что такие ситуации на следующий день разбираются прямо в кабинете товарища Мао.
2. Если очередь в гипермаркете увеличивается и покупатели начинают там надолго зависать, то это подозрительно, но не обязательно сразу плохо. За этим надо следить, но бывают две ситуации:
- очередь растет из-за того, что пришло слишком много китайцев одновременно, например, из-за слуха о повышении цен;
- очередь растет из-за того, что по какой-то причине сломалось много касс. Эта ситуация уже плохая, будет разбираться на планерке и может привести к выговорам.
3. Если конкретный китаец не может приобрести рис, то это также может быть по разным причинам:
- если китаец забыл взять деньги, то это не вина товарища директора;
- если на кассе что-то сломалось или китайца обругала кассирша, то это уже проблема гипермаркета. Если доля таких инцидентов возрастет до определенного уровня, то это станет большой проблемой.
Понятно, что для любой ИС важной характеристикой механизмов массовой загрузки является доля отказов в обслуживании. Необходимо различать отказ в обслуживании по техническим причинам, связанным с работой ИС (отказ оборудования, системная ошибка и т. п.), и отказы по причинам, связанным с проблемами на стороне поставщика (некорректный формат пакета данных, некорректные данные с точки зрения бизнес-контролей и др.).
Ситуации могут быть разные. Но если ИС была разработана с учетом изложенных выше принципов и имеется процесс постоянного отслеживания и устранения технических ошибок, то рано или поздно ситуация стабилизируется. В хорошо работающей системе статистика по загрузке пакетов выглядит примерно как в таблице 1.
| Количество запросов на загрузку, шт | Доля, % | |
| Полностью успешно загруженные пакеты |
125 977 459 |
79,94% |
| Пакеты, которые не были полностью или частично загружены в связи с проблемами на стороне поставщика (ФЛК, бизнес-контроль) |
29 936 543 |
19% |
| Пакеты, которые не были загружены из-за проблемы на стороне ИС |
38 805 |
0,02% |
| Пакеты-дубликаты |
1 638 886 |
1,04% |
| Всего |
156 812 782 |
100% |
Из таблицы видно, что большинство пакетов успешно загружаются. При этом высока доля ошибок на стороне поставщика информации. Это может быть связано с большим количеством поставщиков и разной степенью их готовности к информационному обмену. У поставщиков могут быть некачественные данные, у них могут быть проблемы с информационными системами. Какие-то данные могут отсутствовать в электронной структурированной форме, и требуется время для того, чтобы их получить.
К сожалению, ошибки ИС могут возникать, особенно, если идет её бурное развитие. Важно, чтобы был запущен процесс мониторинга ошибок в промышленной среде и анализ причин их возникновения. Мы на своих проектах в ЛАНИТ используем развитую систему мониторинга интеграционных механизмов, и если видим, что количество ошибок начинает расти, то определяем их источник и стараемся оперативно предпринять корректирующие действия.
Заключение
В заключение хотелось бы еще раз повторить основные тезисы.
- При разработке и развитии государственных или корпоративных ИС возникают задачи массовой загрузки данных. Поток запросов на загрузку в ИС, как правило, имеет случайный характер. Это означает, что мы примерно знаем распределение, но в каждый конкретный момент может прийти и очень мало, и очень много запросов.
- Механизмы приема данных для массовой загрузки должны быть построены с использованием очередей. По-другому нельзя и точка. В противном случае мы должны допускать потерю данных, если вдруг придет огромное число данных на загрузку, либо нам нужно использовать очень-очень много железа, которое простаивало бы 99% времени.
- Время загрузки данных складывается из времени ожидания в очереди и времени обработки данных. Время обработки пакетов данных на бекенде при адекватных процессах проектирования и разработки – это секунды или миллисекунды. Время ожидания в очереди (минуты) зависит от количества обработчиков, используемых системой. Количество обработчиков определяется мощностью программно-аппаратного комплекса. Больше железа – больше обработчиков, быстрее разбирается очередь. И наоборот.
- Синхронные сервисы не применимы для массовой загрузки, поэтому их не рекомендуется использовать.
- Если вы поставщик и вам нужно загрузить много данных, отправляйте их все в ИС сразу. Ни в коем случае не стоит отправлять данные последовательно друг за другом (следующий пакет не отправляется, пока не загрузится предыдущий).
Традиционно: у нас есть для вас вакансии!


{kind=link}
{kind=link}
{kind=link}