При разработке ПО для микроконтроллеров на С++ очень часто можно столкнуться с тем, что использование стандартной библиотеки может привести к нежелательным дополнительным расходам ресурсов, как ОЗУ, так и ПЗУ. Поэтому зачастую классы и методы из библиотеки
Поэтому иногда приходится изобретать велосипеды, чтобы выполнить все эти условия. Таких задач немного, но они есть. В данном посте, хотелось бы рассказать про вроде бы как простую задачку — расширить коды возврата существующих подсистем в ПО для микроконтроллера.
Допустим у вас есть подсистема диагностики CPU и у неё есть перечисляемые коды возврата, скажем такие:
В случае, если подсистема диагностики CPU обнаружит отказ одного из модуля CPU, (например, ALU или RAM) она должна будет возвратить соответствующий код.
Тоже самое для другой подсистемы, пусть это будет диагностика измерений, проверяющей что измеренное значение находится в диапазоне и оно вообще валидно (не равное NAN или Infinity):
Для каждой подсистемы пусть будет метод
И есть некий журнал, который при возникновении ошибки должен логировать код ошибки.
Для понимания я напишу это в очень упрощенном виде:
Ясно, что при преобразовании перечисляемых типов в целое, мы можем получить одно и то же значение для разных типов. Как же различить что код первой ошибки это код ошибки подсистемы диагностики Cpu, а второй подсистемы измерения?
Логично было бы чтобы метод
Думаю, очевидны недостатки такого подхода. Во-первых, много ручной работы, нужно вручную определять диапазоны и коды возврата, что непременно приведет к человеческой ошибке. Во-вторых, подсистем может быть много, и дописывать для каждой подсистемы перечисления вообще не вариант.
Собственно, было бы замечательно, если бы можно было вообще не трогать перечисления, расширить их коды немного другим способом, например, чтобы имелась возможность сделать так:
Или так:
Или так:
Как видно из кода, здесь используется некий класс
Ваши собственные std::code_error
Поддержка системных ошибок в C++
Детерминированные исключения и обработка ошибок в «C++ будущего»
Основная претензия заключается в том, что для использования этого класса, нам необходимо унаследовать
Кроме того, придется также описывать категорию(имя и сообщение) для каждого своего перечисляемого типа вручную. А еще код означающий отсутствие ошибки в
Хотелось бы, чтобы накладных расходов, кроме как добавление номера категории, вообще не было.
Поэтому было бы логично «изобрести» что-то такое, что позволяло бы разработчику сделать минимум телодвижений в части добавления категории для своего перечисляемого типа.
Для начала нужно сделать класс, похожий на
Класс должен хранить в себе код ошибки, код категории и код соответствующий отсутствию ошибок, оператор приведения, и оператор присваивания. Соответствующий класс выглядит следующим образом:
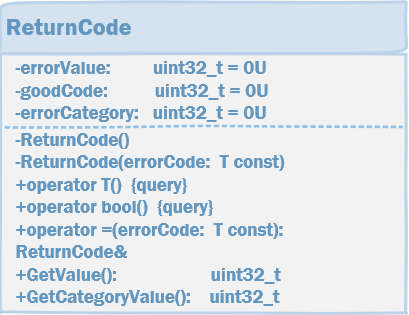
Нужно немного пояснить, что тут происходит. Для начала шаблонный конструктор
Он позволяет создать объект класс из любого перечисляемого типа:
Для того, чтобы конструктор мог принимать только перечисляемый тип, в его тело добавлен
Также конструктор инициализирует приватные атрибуты, я вернусь к этому позже…
Далее оператор приведения:
Он также может привести только к перечисляемому типу и позволяет делать нам следующее:
Ну и отдельно оператор bool():
Позволит нам напрямую проверять есть ли вообще ошибка в коде возврата:
По сути это все. Остается вопрос в функциях
Ясно, что эти функции могут быть предоставлены пользователем, и мы честно можем их вызывать в нашем конструкторе через механизм аргумент-зависимого поиска.
Например:
Это требует дополнительных усилий от разработчика. Нужно для каждого перечисляемого типа, который мы хотим категоризировать добавлять эти два метода и обновлять
Однако наше желание это чтобы разработчик вообще практически ничего не добавлял в код и не заморачивался по поводу того, как ему расширить свой перечисляемый тип.
Что же можно сделать.
Итак, сконцентрируемся на первой задаче — автоматическое вычисление категории. Идея, подсказанная моим коллегой, заключается в том, чтобы разработчик имел возможность зарегистрировать свой перечисляемый тип. Это можно сделать используя шаблон с переменным количеством аргументов. Объявим такую структуру
Теперь чтобы зарегистрировать новое перечисление, которое должно быть расширено категорией просто зададим новый тип
Если вдруг нам надо добавить еще одно перечисление, то просто добавляем его в список параметров шаблона:
Очевидно, что категорией для наших перечислений может быть позиция в списке параметров шаблона, т.е. для
Что тут происходит. В кратце, функция
Разберем подробнее. Самую нижняя функцию
Здесь ветка
Как только все типы в списке закончатся,
Что же произойдет, если тип есть в списке. В этом случае, будет работать другая ветка ветка c
Тут идет проверка на совпадение типов
На второй итерации рекурсионный вызов функции прекратиться и на выходе получим 1(из первой итерации) + 0(из второй) = 1 — это и есть индекс типа Measure_Error в списке
Поскольку это функция
Все это можно было не писать, будь в распоряжении С++17. К сожалению мой IAR компилятор не поддерживает в полной мере С++17, а так можно было всю портянку заменить на следующий код:
Осталось теперь сделать шаблонные методы
Вот и все. Давайте теперь посмотрим, что происходит при таком конструировании объекта:
Вернемся обратно к конструктору класса
Он шаблонный, и в случае, если
Для разработчика, который возжелал пользоваться
Зарегистрировать свой перечисляемый тип в списке.
И никаких лишних движений, существующий код не трогается, а для расширения нужно всего лишь зарегистрировать тип в списке. Причем, все это сделается на этапе компиляции, и компилятор не только рассчитает все категории, но и предупредит вас в случае, если вы забыли зарегистрировать тип, или попытались передать тип не являющийся неперечисляемым.
Справедливость ради, стоит отметь, что в тех 10% кода, где у перечислений вместо кода Ок используется другое названия, придется сделать свою специализацию для этого типа.
Я выложил небольшой пример здесь: пример кода
В общем виде, вот такое приложение:
Выведет следующие строки:
std не совсем подходят для реализации в микроконтроллере. Существуют также некоторые ограничения в использовании динамически выделяемой памяти, RTTI, исключений и так далее. В общем случае, чтобы писать компактный и быстрый код нельзя просто так взять библиотеку std и начать пользоваться, скажем операторами типа typeid, потому что необходима поддержка RTTI, а это уже накладные расходы, хоть и не очень большие.Поэтому иногда приходится изобретать велосипеды, чтобы выполнить все эти условия. Таких задач немного, но они есть. В данном посте, хотелось бы рассказать про вроде бы как простую задачку — расширить коды возврата существующих подсистем в ПО для микроконтроллера.
Задача
Допустим у вас есть подсистема диагностики CPU и у неё есть перечисляемые коды возврата, скажем такие:
enum class Cpu_Error { Ok, Alu, Rom, Ram } ;
В случае, если подсистема диагностики CPU обнаружит отказ одного из модуля CPU, (например, ALU или RAM) она должна будет возвратить соответствующий код.
Тоже самое для другой подсистемы, пусть это будет диагностика измерений, проверяющей что измеренное значение находится в диапазоне и оно вообще валидно (не равное NAN или Infinity):
enum class Measure_Error { OutOfLimits, Ok, BadCode } ;
Для каждой подсистемы пусть будет метод
GetLastError() возвращающий перечисляемый тип ошибки данной подсистемы. Для CpuDiagnostic будет возвращен код типа Cpu_Error, для MeasureDiagnostic код типа Measure_Error.И есть некий журнал, который при возникновении ошибки должен логировать код ошибки.
Для понимания я напишу это в очень упрощенном виде:
void Logger::Update() { Log(static_cast<uint32_t>(cpuDiagnostic.GetLastError()) ; Log(static_cast<uint32_t>(measureDiagnostic.GetLastError()) ; }
Ясно, что при преобразовании перечисляемых типов в целое, мы можем получить одно и то же значение для разных типов. Как же различить что код первой ошибки это код ошибки подсистемы диагностики Cpu, а второй подсистемы измерения?
Поиск решений
Логично было бы чтобы метод
GetLastError() возвращал различный код для различных подсистем. Одним из самых прямых решений в лоб, было бы использование различных диапазонов кодов для каждого перечисляемого типа. Что-то типа такогоconstexpr tU32 CPU_ERROR_ALU = 0x10000001 ; constexpr tU32 CPU_ERROR_ROM = 0x10000002 ; ... constexpr tU32 MEAS_ERROR_OUTOF = 0x01000001 ; constexpr tU32 MEAS_ERROR_BAD = 0x01000002 ; ... enum class Cpu_Error { Ok, Alu = CPU_ERROR_ALU, Rom = CPU_ERROR_ROM, Ram = CPU_ERROR_RAM } ; ...
Думаю, очевидны недостатки такого подхода. Во-первых, много ручной работы, нужно вручную определять диапазоны и коды возврата, что непременно приведет к человеческой ошибке. Во-вторых, подсистем может быть много, и дописывать для каждой подсистемы перечисления вообще не вариант.
Собственно, было бы замечательно, если бы можно было вообще не трогать перечисления, расширить их коды немного другим способом, например, чтобы имелась возможность сделать так:
ResultCode result = Cpu_Error::Ok ; //GetLastError() возвращает перечисление Cpu_Error result = cpuDiagnostic.GetLastError() ; if(result) //проверяем были ли ошибки { //логируем сразу и код и категорию кода Logger::Log(result) ; } //GetLastError() возвращает перечисление Measure_Error result = measureDiagnostic.GetLastError() ; if(result) //проверяем были ли ошибки { //логируем сразу и код и категорию кода Logger::Log(result) ; }
Или так:
ReturnCode result ; for(auto it: diagnostics) { //GetLastError() возвращает перечисление подсистемы диагностики result = it.GetLastError() ; if (result) //проверяем были ли ошибки { Logger::Log(result) ; //логируем и код и категорию кода } }
Или так:
void CpuDiagnostic::SomeFunction(ReturnCode errocode) { Cpu_Error status = errorcode ; switch (status) { case CpuError::Alu: // do something ; break; .... } }
Как видно из кода, здесь используется некий класс
ReturnCode, который должен содержать и код ошибки и его категорию. В стандартной библиотеке есть такой класс std::error_code, который собственно практически все это делает. Очень хорошо его назначение описано здесь:Ваши собственные std::code_error
Поддержка системных ошибок в C++
Детерминированные исключения и обработка ошибок в «C++ будущего»
Основная претензия заключается в том, что для использования этого класса, нам необходимо унаследовать
std::error_category, который явно сильно перегружен для использования во встроенном ПО на небольших микроконтроллерах. Даже хотя бы использованием std::string.class CpuErrorCategory: public std::error_category { public: virtual const char * name() const; virtual std::string message(int ev) const; };
Кроме того, придется также описывать категорию(имя и сообщение) для каждого своего перечисляемого типа вручную. А еще код означающий отсутствие ошибки в
std::error_code равен 0. А возможны варианты когда для разных типов код отсутствия ошибок будет различен. Хотелось бы, чтобы накладных расходов, кроме как добавление номера категории, вообще не было.
Поэтому было бы логично «изобрести» что-то такое, что позволяло бы разработчику сделать минимум телодвижений в части добавления категории для своего перечисляемого типа.
Для начала нужно сделать класс, похожий на
std::error_code, умеющий преобразовывать любой перечисляемый тип в целое и обратно из целого в перечисляемый тип. Плюсом к этим возможностям, чтобы была возможность вернуть категорию, собственно значение кода, а также уметь делать проверку://GetLastError() возвращает перечисление CpuError ReturnCode result(cpuDiagnostic.GetLastError()) ; if(result) //проверяем были ли ошибки { ... }
Решение
Класс должен хранить в себе код ошибки, код категории и код соответствующий отсутствию ошибок, оператор приведения, и оператор присваивания. Соответствующий класс выглядит следующим образом:
Код класса
class ReturnCode { public: ReturnCode() { } template<class T> explicit ReturnCode(const T initReturnCode): errorValue(static_cast<tU32>(initReturnCode)), errorCategory(GetCategory(initReturnCode)), goodCode(GetOk(initReturnCode)) { static_assert(std::is_enum<T>::value, "Тип должен быть перечисляемым") ; } template<class T> operator T() const { //Cast to only enum types static_assert(std::is_enum<T>::value, "Тип должен быть перечисляемым") ; return static_cast<T>(errorValue) ; } tU32 GetValue() const { return errorValue; } tU32 GetCategoryValue() const { return errorCategory; } operator bool() const { return (GetValue() != goodCode); } template<class T> ReturnCode& operator=(const T returnCode) { errorValue = static_cast<tU32>(returnCode) ; errorCategory = GetCategory(returnCode) ; goodCode = GetOk(returnCode) ; return *this ; } private: tU32 errorValue = 0U ; tU32 errorCategory = 0U ; tU32 goodCode = 0U ; } ;
Нужно немного пояснить, что тут происходит. Для начала шаблонный конструктор
template<class T> explicit ReturnCode(const T initReturnCode): errorValue(static_cast<tU32>(initReturnCode)), errorCategory(GetCategory(initReturnCode)), goodCode(GetOk(initReturnCode)) { static_assert(std::is_enum<T>::value, "Тип должен быть перечисляемым") ; }
Он позволяет создать объект класс из любого перечисляемого типа:
ReturnCode result(Cpu_Error::Ok) ; ReturnCode result1(My_Error::Error1); ReturnCode result2(cpuDiagnostic.GetLatestError()) ;
Для того, чтобы конструктор мог принимать только перечисляемый тип, в его тело добавлен
static_assert, который на этапе компиляции проверит передаваемый в конструктор тип с помощью std::is_enum и выдаст ошибку с понятным текстом. Реального кода тут не генерится, это все для компилятора. Так что по факту это пустой конструктор.Также конструктор инициализирует приватные атрибуты, я вернусь к этому позже…
Далее оператор приведения:
template<class T> operator T() const { //Cast to only enum types static_assert(std::is_enum<T>::value, "Тип должен быть перечисляемым") ; return static_cast<T>(errorValue) ; }
Он также может привести только к перечисляемому типу и позволяет делать нам следующее:
ReturnCode returnCode(Cpu_Error::Rom) ; Cpu_Error status = errorCode ; returnCode = My_Errror::Error2; My_Errror status1 = returnCode ; returnCode = myDiagnostic.GetLastError() ; MyDiagsonticError status2 = returnCode ;
Ну и отдельно оператор bool():
operator bool() const { return (GetValue() != goodCode); }
Позволит нам напрямую проверять есть ли вообще ошибка в коде возврата:
//GetLastError() возвращает перечисление Cpu_Error ReturnCode result(cpuDiagnostic.GetLastError()) ; if(result) //проверяем были ли ошибки { ... }
По сути это все. Остается вопрос в функциях
GetCategory() и GetOkCode(). Как нетрудно догадаться, первая предназначена для того, чтобы перечисляемый тип, каким то образом сообщил о своей категории классу ReturnCode, а вторая чтобы перечисляемый тип сообщил, что является удачным кодом возврата, так как мы собираемся сравнивать с ним в операторе bool().Ясно, что эти функции могут быть предоставлены пользователем, и мы честно можем их вызывать в нашем конструкторе через механизм аргумент-зависимого поиска.
Например:
enum class CategoryError { Nv = 100, Cpu = 200 }; enum class Cpu_Error { Ok, Alu, Rom } ; inline tU32 GetCategory(Cpu_Error errorNum) { return static_cast<tU32>(CategoryError::Cpu); } inline tU32 GetOkCode(Cpu_Error) { return static_cast<tU32>(Cpu_Error::Ok); }
Это требует дополнительных усилий от разработчика. Нужно для каждого перечисляемого типа, который мы хотим категоризировать добавлять эти два метода и обновлять
CategoryError перечисление.Однако наше желание это чтобы разработчик вообще практически ничего не добавлял в код и не заморачивался по поводу того, как ему расширить свой перечисляемый тип.
Что же можно сделать.
- Во-первых было замечательно, чтобы категория вычислялась автоматически, и разработчику не надо было бы предоставлять реализацию метода
GetCategory()для каждого перечисления. - Во-вторых, в 90% случаев в нашем коде, для возврата хорошего кода у нас используется Ok. Поэтому можно написать общую реализацию для этих 90%, а для 10% придется делать специализацию.
Итак, сконцентрируемся на первой задаче — автоматическое вычисление категории. Идея, подсказанная моим коллегой, заключается в том, чтобы разработчик имел возможность зарегистрировать свой перечисляемый тип. Это можно сделать используя шаблон с переменным количеством аргументов. Объявим такую структуру
template <typename... Types> struct EnumTypeRegister{}; // структура для регистрации типов
Теперь чтобы зарегистрировать новое перечисление, которое должно быть расширено категорией просто зададим новый тип
using CategoryErrorsList = EnumTypeRegister<Cpu_Error, Measure_Error>;
Если вдруг нам надо добавить еще одно перечисление, то просто добавляем его в список параметров шаблона:
using CategoryErrorsList = EnumTypeRegister<Cpu_Error, Measure_Error, My_Error>;
Очевидно, что категорией для наших перечислений может быть позиция в списке параметров шаблона, т.е. для
Cpu_Error это 0, для Measure_Error, это 1, для My_Error это 2. Осталось заставить компилятор вычислить это автоматически. Для С++14 делаем так:template <typename QueriedType, typename Type> constexpr tU32 GetEnumPosition(EnumTypeRegister<Type>) { static_assert(std::is_same<Type, QueriedType>::value, "Тип не зарегистрирован в списке EnumTypeRegister"); return tU32(0U) ; } template <typename QueriedType, typename Type, typename... Types> constexpr std::enable_if_t<std::is_same<Type, QueriedType>::value, tU32> GetEnumPosition(EnumTypeRegister<Type, Types...>) { return 0U ; } template <typename QueriedType, typename Type, typename... Types> constexpr std::enable_if_t<!std::is_same<Type, QueriedType>::value, tU32> GetEnumPosition(EnumTypeRegister<Type, Types...>) { return 1U + GetEnumPosition<QueriedType>(EnumTypeRegister<Types...>()) ; }
Что тут происходит. В кратце, функция
GetEnumPosition<T<>> , с входным параметром являющимся списком перечисляемых типов EnumTypeRegister, в нашем случае EnumTypeRegister<Cpu_Error, Measure_Error, My_Error>, и параметром шаблона T — являющимся перечисляемым типом, индекс которого мы должны найти в этом списке, пробегается по списку и в случае, если Т совпадает с одним из типов в списке возвращает его индекс, в противном случае выдается сообщение "«Тип не зарегистрирован в списке EnumTypeRegister»"//Т.е. если определен список constexpr EnumTypeRegister<Cpu_Error, Measure_Error, My_Error> list //то вызов GetEnumPosition<Measure_Error>(list) // должен вернуть 1 - что является индексом Measure_Error в данном списке.
Разберем подробнее. Самую нижняя функцию
template <typename QueriedType, typename Type, typename... Types> constexpr std::enable_if_t<!std::is_same<Type, QueriedType>::value, tU32> GetEnumPosition(TypeRegister<Type, Types...>) { return 1U + GetEnumPosition<QueriedType>(TypeRegister<Types...>()) ; }
Здесь ветка
std::enable_if_t<!std::is_same.. проверяет совпадает ли запрошенный тип с первым типом в списке шаблона, если нет, то возвращаемый тип функции GetEnumPosition будет tU32 и далее выполняется тело функции, а именно рекурсивный вызов опять этой же функции, при этом количество аргументов шаблона уменьшается на 1, а возвращаемое значение увеличится на 1. Т.е на каждой итерации будет что-то похожее на это://Iteration 1, 1+: tU32 GetEnumPosition<T>(EnumTypeRegister<Cpu_Error, Measure_Error, My_Error>) //Iteration 2, 1+1+: tU32 GetEnumPosition<T>(EnumTypeRegister<Measure_Error, My_Error>) //Iteration 3, 1+1+1: tU32 GetEnumPosition<T>(EnumTypeRegister<My_Error>)
Как только все типы в списке закончатся,
std::enable_if_t не сможет вывести тип возвращаемого значения функции GetEnumPosition() и на этом итерации закончатся://Как только итерации дойдут до последнего типа в списке GetEnumPosition<T>(TypeRegister<>) template <typename QueriedType, typename Type> constexpr tU32 GetEnumPosition(EnumTypeRegister<Type>) { static_assert(std::is_same<Type, QueriedType>::value, "Тип не зарегистрирован в списке EnumTypeRegister"); return tU32(0U) ; }
Что же произойдет, если тип есть в списке. В этом случае, будет работать другая ветка ветка c
std::enable_if_t<std::is_same..:template <typename QueriedType, typename Type, typename... Types> constexpr std::enable_if_t<std::is_same<Type, QueriedType>::value, tU32> GetEnumPosition(TypeRegister<Type, Types...>) { return 0U ; }
Тут идет проверка на совпадение типов
std::enable_if_t<std::is_same... И если, скажем на входе будет тип Measure_Error, то получится следующая последовательность://Iteration 1, tU32 GetEnumPosition<Measure_Error>(EnumTypeRegister<Cpu_Error, Measure_Error, My_Error>) { return 1U + GetEnumPosition<Measure_Error>(EnumTypeRegister<Measure_Error, My_Error>) } //Iteration 2: tU32 GetEnumPosition<Measure_Error>(EnumTypeRegister<Measure_Error, My_Error>) { return 0 ; }
На второй итерации рекурсионный вызов функции прекратиться и на выходе получим 1(из первой итерации) + 0(из второй) = 1 — это и есть индекс типа Measure_Error в списке
EnumTypeRegister<Cpu_Error, Measure_Error, My_Error> Поскольку это функция
constexpr, то все вычисления делаются на этапе компиляции и собственно никакого кода не генериться.Все это можно было не писать, будь в распоряжении С++17. К сожалению мой IAR компилятор не поддерживает в полной мере С++17, а так можно было всю портянку заменить на следующий код:
//for C++17 template <typename QueriedType, typename Type, typename... Types> constexpr tU32 GetEnumPosition(EnumTypeRegister<Type, Types...>) { // если обнаружил тип в списке заканчиваем рекурсию if constexpr (std::is_same<Type, QueriedType>::value) { return 0U ; } else { return 1U + GetEnumPosition<QueriedType>(EnumTypeRegister<Types...>()) ; } }
Осталось теперь сделать шаблонные методы
GetCategory() и GetOk(), которые будут вызывать GetEnumPosition.template<typename T> constexpr tU32 GetCategory(const T) { return static_cast<tU32>(GetEnumPosition<T>(categoryDictionary)); } template<typename T> constexpr tU32 GetOk(const T) { return static_cast<tU32>(T::Ok); }
Вот и все. Давайте теперь посмотрим, что происходит при таком конструировании объекта:
ReturnCode result(Measure_Error::Ok) ;
Вернемся обратно к конструктору класса
ReturnCodetemplate<class T> explicit ReturnCode(const T initReturnCode): errorValue(static_cast<tU32>(initReturnCode)), errorCategory(GetCategory(initReturnCode)), goodCode(GetOk(initReturnCode)) { static_assert(std::is_enum<T>::value, "The type have to be enum") ; }
Он шаблонный, и в случае, если
T есть Measure_Error а значит вызывается инстанциация шаблона метода GetCategory(Measure_Error), для типа Measure_Error, который в свою очередь вызывает GetEnumPosition с типом Measure_Error, GetEnumPosition<Measure_Error>(EnumTypeRegister<Cpu_Error, Measure_Error, My_Error>), который возвращает позицию Measure_Error в списке. Позиция равна 1. И собственно весь код конструктора при инстанциации типа Measure_Error заменяется компилятором на:explicit ReturnCode(const Measure_Error initReturnCode): errorValue(1), errorCategory(1), goodCode(1) { }
Итог
Для разработчика, который возжелал пользоваться
ReturnCode нужно сделать только одну вещь:Зарегистрировать свой перечисляемый тип в списке.
// Add enum in the category using CategoryErrorsList = EnumTypeRegister<Cpu_Error, Measure_Error, My_Error>;
И никаких лишних движений, существующий код не трогается, а для расширения нужно всего лишь зарегистрировать тип в списке. Причем, все это сделается на этапе компиляции, и компилятор не только рассчитает все категории, но и предупредит вас в случае, если вы забыли зарегистрировать тип, или попытались передать тип не являющийся неперечисляемым.
Справедливость ради, стоит отметь, что в тех 10% кода, где у перечислений вместо кода Ок используется другое названия, придется сделать свою специализацию для этого типа.
template<> constexpr tU32 GetOk<MyError>(const MyError) { return static_cast<tU32>(MyError::Good) ; } ;
Я выложил небольшой пример здесь: пример кода
В общем виде, вот такое приложение:
enum class Cpu_Error { Ok, Alu, Rom, Ram } ; enum class Measure_Error { OutOfLimits, Ok, BadCode } ; enum class My_Error { Error1, Error2, Error3, Error4, Ok } ; // Add enum in the category list using CategoryErrorsList = EnumTypeRegister<Cpu_Error, Measure_Error, My_Error>; Cpu_Error CpuCheck() { return Cpu_Error::Ram; } My_Error MyCheck() { return My_Error::Error4; } int main() { ReturnCode result(CpuCheck()); //cout << " Return code: "<< result.GetValue() // << " Return category: "<< result.GetCategoryValue() << endl; if (result) //if something wrong { result = MyCheck() ; // cout << " Return code: "<< result.GetValue() // << " Return category: "<< result.GetCategoryValue() << endl; } result = Measure_Error::BadCode ; //cout << " Return code: "<< result.GetValue() // << " Return category: "<< result.GetCategoryValue() << endl; result = Measure_Error::Ok ; if (!result) //if all is Ok { Measure_Error mError = result ; if (mError == Measure_Error::Ok) { // cout << "mError: "<< tU32(mError) << endl; } } return 0; }
Выведет следующие строки:
Return code: 3 Return category: 0
Return code: 3 Return category: 2
Return code: 2 Return category: 1
mError: 1

