 Гугл любит пасхалки. Любит настолько, что найти их можно практически в каждом продукте компании. Традиция пасхалок в Android тянется с самых первых версий операционной системы (я думаю, все в курсе, что будет, если в настройках несколько раз нажать на строчку с версией Android).
Гугл любит пасхалки. Любит настолько, что найти их можно практически в каждом продукте компании. Традиция пасхалок в Android тянется с самых первых версий операционной системы (я думаю, все в курсе, что будет, если в настройках несколько раз нажать на строчку с версией Android).Но бывает и так, что пасхалки обнаруживаются в самых неожиданных местах. Есть даже такая легенда: однажды один программист загуглил «mutex lock», а вместо результатов поиска попал на страницу foo.bar, решил все задачи и устроился на работу в Google.
Реконструкция событий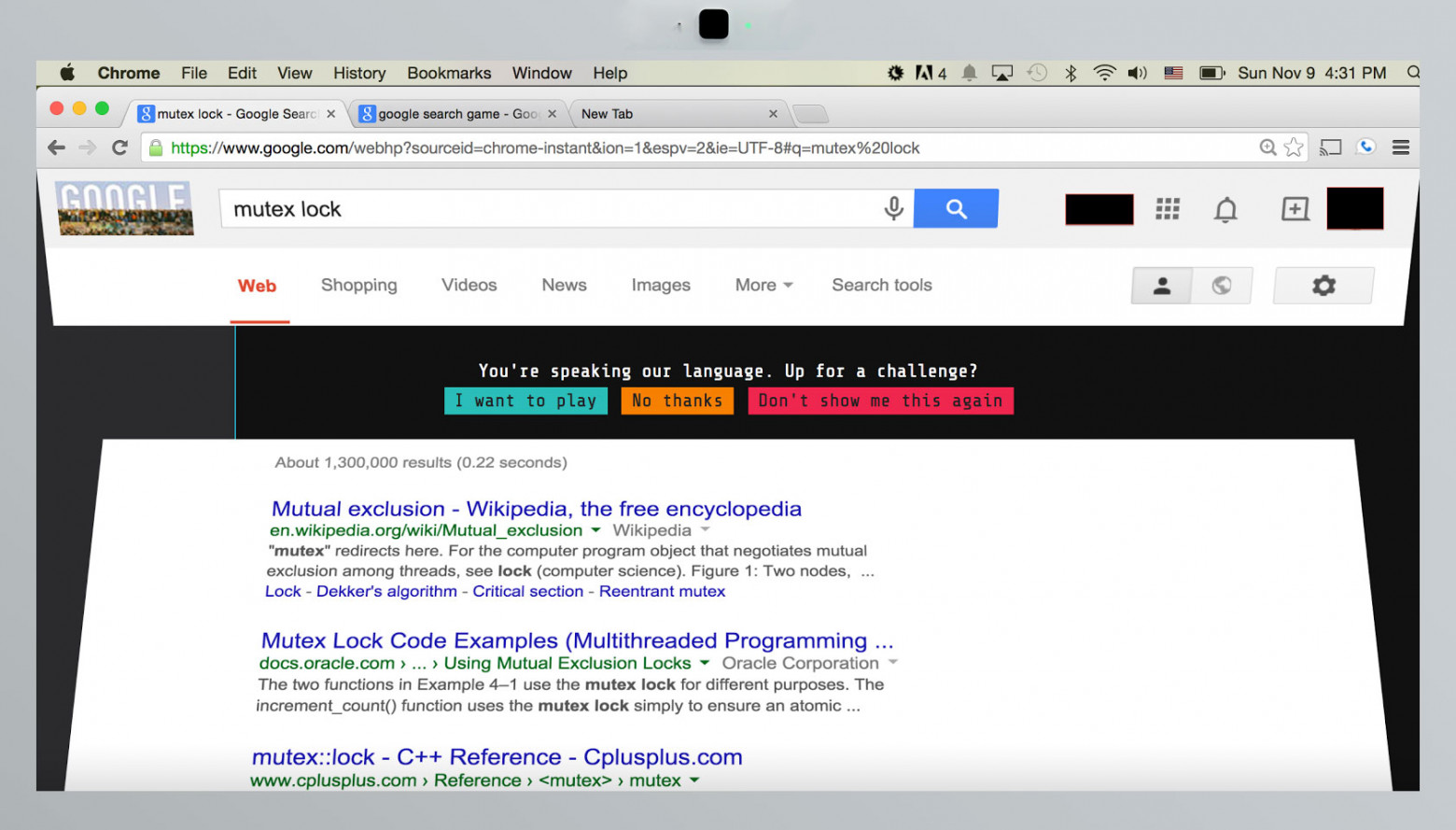
Вот такая же удивительная история (только без хэппи-энда) произошла со мной. Скрытые послания там, где их точно не может быть, реверс Java кода и нативных библиотек, секретная виртуальная машина, прохождение собеседования в Google — все это под катом.
DroidGuard
Одним скучным вечером я сделал factory reset и начал заново настраивать смартфон. Первым делом свежий Android попросил меня ввести мой гугловый аккаунт. «Интересно, а как вообще происходит регистрация и логин в Android?»- подумал я. Вечер переставал быть томным.
Для перехвата и анализа трафика я использую Burp Suite от PortSwigger. Бесплатной Community версии будет достаточно. Чтобы мы смогли увидеть https запросы, для начала нужно установить на девайс сертификат от PortSwigger. Для тестов у меня в закромах нашелся восьмилетний Samsung Galaxy S с Android 4.4 на борту. Если у вас что-то посвежее, то могут возникнуть проблемы с https: certificate pinning и все такое.
На самом деле, ничего особо интересного в обращениях к Google API нет. Девайс отправляет данные о себе, в ответ получает токены… Единственный непонятный момент — POST запрос к anti-abuse сервису.
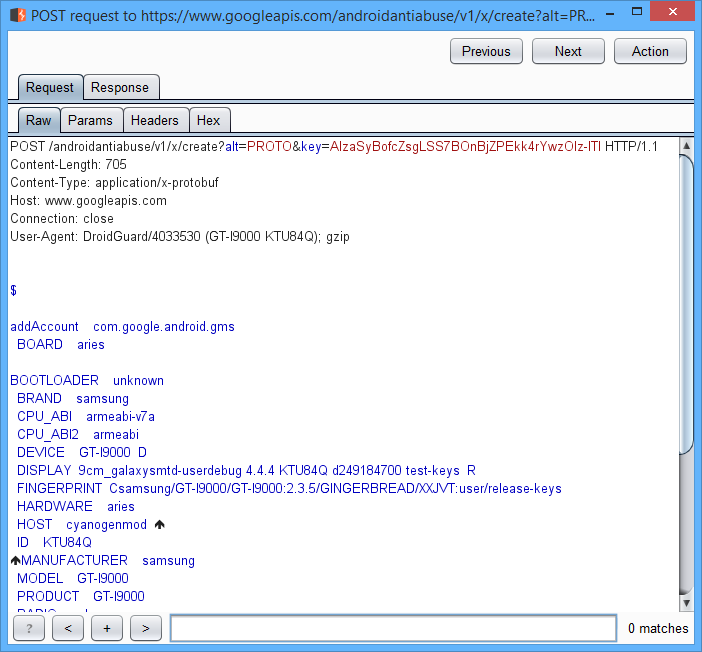
После этого запроса среди непримечательных параметров появляется один загадочный, с названием droidguard_result. Представляет он собой очень длинную Base64 строку:
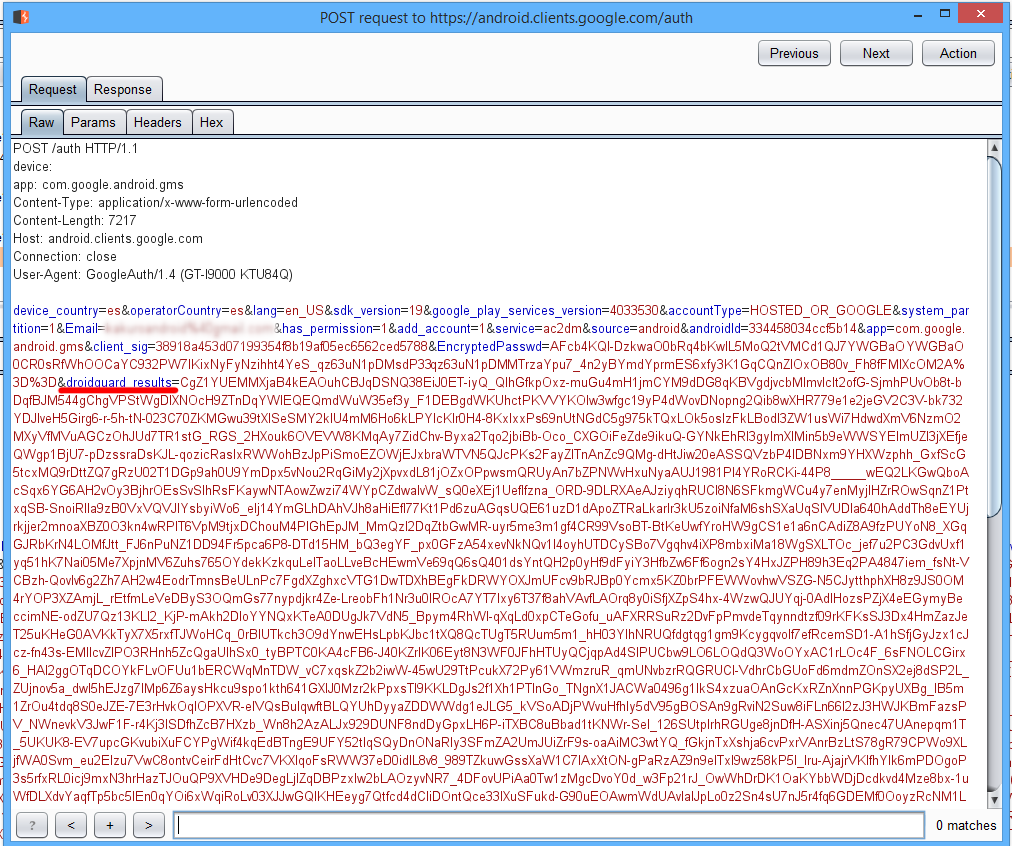
DroidGuard — это механизм Google для отделения ботов и эмуляторов от настоящих устройств. SafetyNet в своей работе тоже использует данные от DroidGuard. Похожая штука у Google есть и для браузеров — Botguard.
Но все-таки, что это за данные, что в них передается? Сейчас будем разбираться.
Protocol Buffers
Откуда вообще берется ссылка www.googleapis.com/androidantiabuse/v1/x/create?alt=PROTO&key=AIzaSyBofcZsgLSS7BOnBjZPEkk4rYwzOIz-lTI, кто именно в системе Android делает этот запрос? Нетрудно найти, что эта ссылка прямо в таком виде хранится в одном из обфусцированных классов Google Play Services:
public bdd(Context var1, bdh var2) { this(var1, "https://www.googleapis.com/androidantiabuse/v1/x/create?alt=PROTO&key=AIzaSyBofcZsgLSS7BOnBjZPEkk4rYwzOIz-lTI", var2); }
Как мы уже видели в Burp, Content-Type у POST запросов по этой ссылке — application/x-protobuf (Google Protocol Buffers, протокол для бинарной сериализации от Google). Не json, конечно — так сразу и не поймешь, что там пересылается.
Работает protocol buffers таким образом:
- сначала описываем структуру сообщения в специальном формате и сохраняем в .proto файл
- компилируем .proto файлы, на выходе компилятор protoc генерирует исходный код на выбранном языке программирования (в случае с Android это Java)
- используем сгенерированные классы в проекте
Чтобы декодировать сообщения в формате protobuf у нас есть два пути. Первый — использовать какой-либо инструмент для анализа protobuf и пытаться воссоздать оригинальное описание .proto файлов. Второй — выдернуть готовые сгенерированные protoc-компилятором классы из Google Play Services. По второму пути я и пошел.
Берем apk файл Google Play Services той же версии, что установлен на девайсе (а если девайс рутованый, то apk можно скопировать прямо с него же). С помощью dex2jar перегоняем .dex файл обратно в .jar и открываем любимым декомпилятором. Мне в последнее время очень нравится Fernflower от JetBrains. Работает он как плагин к IntelliJ IDEA (или Android Studio), поэтому просто открываем в Android Studio класс с той самой заветной ссылкой. Если proguard старался не сильно, то декомпилированный Java код для создания сообщений protobuf можно просто целиком копировать себе в проект.
По декомпилированному коду видно, что в protobuf сообщении на сервер уходят константы Build.* (ладно, это сразу было очевидно):
... var3.a("4.0.33 (910055-30)"); a(var3, "BOARD", Build.BOARD); a(var3, "BOOTLOADER", Build.BOOTLOADER); a(var3, "BRAND", Build.BRAND); a(var3, "CPU_ABI", Build.CPU_ABI); a(var3, "CPU_ABI2", Build.CPU_ABI2); a(var3, "DEVICE", Build.DEVICE); ...
А вот в ответе сервера, к сожалению, все поля protobuf сообщения после обфускации превратились в бессмысленные буквы латинского алфавита. Но что в этих полях хранится, можно узнать по обработке ошибок. Вот так проверяются данные, которые приходят с сервера:
if (!var7.d()) { throw new bdf("byteCode"); } if (!var7.f()) { throw new bdf("vmUrl"); } if (!var7.h()) { throw new bdf("vmChecksum"); } if (!var7.j()) { throw new bdf("expiryTimeSecs"); }
Судя по всему, именно так и назывались поля до обфускации: byteCode, vmUrl, vmChecksum и expiryTimeSecs. Такой нейминг уже наталкивает на определенные догадки.
Собираем все декомпилированные классы из Google Play Services в тестовый проект, переименовываем, набиваем тестовые константы Build.* и запускаем (при желании можно имитировать параметры любого девайса). Если кто-то хочет повторить, то вот ссылка на мой гитхаб.
При корректном запросе с сервера возвращается такой результат:
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — byteCode size: 34446
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — vmChecksum: C15E93CCFD9EF178293A2334A1C9F9B08F115993
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — vmUrl: www.gstatic.com/droidguard/C15E93CCFD9EF178293A2334A1C9F9B08F115993
00:06:26.761 [main] INFO d.a.response.AntiabuseResponse — expiryTimeSecs: 10
Первый этап позади. Сейчас посмотрим, что интересного прячется за ссылкой vmUrl.
Секретный apk
Ссылка ведет нас прямиком к .apk файлу, название которого соответствует его SHA-1 хэшу. Размер и содержимое apk файла скромные — файл весит 150 килобайт. Экономия тут не лишняя: если его загружает каждое из двух миллиардов Android устройств, то набегает уже 270 терабайт трафика.
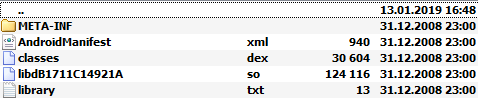
DroidGuardService, который является частью Google Play Services, заботливо загружает этот файл на девайс, распаковывает, извлекает .dex и .so файлы и бесцеремонно, через reflection, использует класс com.google.ccc.abuse.droidguard.DroidGuard. Если происходит какая-то ошибка, то DroidGuardService переключается с DroidGuard на Droidguasso. Но как работает Droidguasso — это отдельная история.По сути, класс
DroidGuard — это просто JNI обертка вокруг нативной .so библиотеки. ABI нативной библиотеки соответствует тому, что мы отправляли в protobuf запросе в поле CPU_ABI: можем запросить armeabi, можем x86, а можем даже mips.Сам сервис
DroidGuardService не содержит какой-либо интересной логики для работы с загруженным классом DroidGuard. Он просто создает новый экземпляр класса DroidGuard, передав ему в конструктор byteCode из protobuf сообщения, вызывает публичный метод, который возвращает массив байт. Этот массив байт и отправляется на сервер в параметре droidguard_result.Чтобы получить примерное представление о том, что происходит внутри
DroidGuard мы можем повторить логику DroidGuardService (только без загрузки apk, раз нативная библиотека у нас и так уже есть). Мы можем взять .dex файл из секретного APK, перегнать в .jar и после этого использовать в проекте. Единственная проблема заключается в том, как класс DroidGuard загружает нативную библиотеку. В статическом блоке инициализации вызывается метод loadDroidGuardLibrary():static { try { loadDroidGuardLibrary(); } catch (Exception ex) { throw new RuntimeException(ex); } }
В свою очередь, метод
loadDroidGuardLibrary() читает файл library.txt (который лежит в корне .apk файла) и загружает библиотеку с таким именем через вызов System.load(String filename). Не самый удобный для нас способ, придется что-то выдумывать при сборке apk, чтобы положить в корень library.txt и .so файл. Было бы удобнее стандартно хранить .so файл в папке lib и загружать через System.loadLibrary(String libname). Исправить это несложно. Для этого будем использовать smali/baksmali — ассемблер/дизассемблер для dex формата. С его помощью classes.dex превращается в набор .smali файлов. Класс
com.google.ccc.abuse.droidguard.DroidGuard нужно поправить таким образом, чтобы в статическом блоке инициализации вызывался метод System.loadLibrary("droidguard") вместо loadDroidGuardLibrary(). Синтаксис smali довольно простой, выглядеть новый блок инициализации будет вот так:.method static constructor <clinit>()V .locals 1 const-string v0, "droidguard" invoke-static {v0}, Ljava/lang/System;->loadLibrary(Ljava/lang/String;)V return-void .end method
С помощью утилиты baksmali все это собирается обратно в .dex, который в свою очередь конвертируется в .jar. После этих манипуляций на выходе получаем jar файл, который можем использовать в тестовом проекте. Кстати, вот и он.
Вся работа с
DroidGuard занимает пару строчек. Самое важное — загрузить массив байт, который мы получили на прошлом шаге после запроса к anti-abuse сервису и передать его в конструктор DroidGuard.private fun runDroidguard() { var byteCode: ByteArray? = loadBytecode("bytecode.base64"); byteCode?.let { val droidguard = DroidGuard(applicationContext, "addAccount", it) val params = mapOf("dg_email" to "test@gmail.com", "dg_gmsCoreVersion" to "910055-30", "dg_package" to "com.google.android.gms", "dg_androidId" to UUID.randomUUID().toString()) droidguard.init() val result = droidguard.ss(params) droidguard.close() } }
Теперь с помощью профайлера Android Studio мы можем посмотреть, что происходит во время работы DroidGuard.
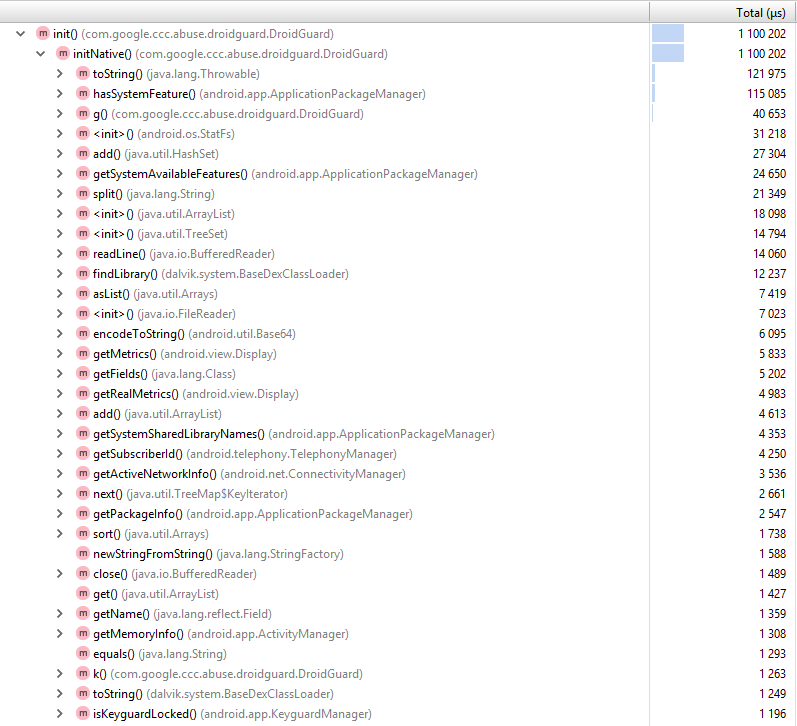
Нативный метод
initNative() собирает информацию о девайсе и вызывает java-методы: hasSystemFeature(), getMemoryInfo(), getPackageInfo()… Уже что-то, но конкретной логики по прежнему не видно. Ладно, ничего не остается, кроме как дизассемблировать .so файл.libdroidguard.so
На самом деле, анализ нативной библиотеки не намного сложнее, чем анализ .dex и .jar файлов. Понадобится программа, похожая на Hex-Rays IDA и изредка небольшое знание ассемблера под arm или x86, на выбор. Я выбрал arm, потому что у меня есть подходящий для дебага рутованный девайс. Если под рукой такого нет, то можно взять библиотеку под x86 и дебажить в эмуляторе.
Программа, похожая на Hex-Rays IDA, декомпилирует бинарник в что-то похожее на c-код. Если откроем код метода
Java_com_google_ccc_abuse_droidguard_DroidGuard_ssNative, то увидим приблизительно такую картину:__int64 __fastcall Java_com_google_ccc_abuse_droidguard_DroidGuard_initNative(int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8, int a9) ... v14 = (*(_DWORD *)v9 + 684))(v9, a5); v15 = (*(_DWORD *)v9 + 736))(v9, a5, 0); ...
Выглядит так себе. Для начала надо сделать пару предварительных шагов, чтобы привести это в приличный вид. Декомпилятор ничего не знает о JNI, поэтому устанавливаем Android NDK и импортируем файл jni.h. Как мы прекрасно знаем, первые два параметра JNI метода — это
JNIEnv* и jobject (this). Типы остальных параметров и их назначение мы можем узнать из Java кода DroidGuard. После присвоения нужных типов, бессмысленные смещения превращаются в вызовы JNI методов:__int64 __fastcall Java_com_google_ccc_abuse_droidguard_DroidGuard_initNative(_JNIEnv *env, jobject thiz, jobject context, jstring flow, jbyteArray byteCode, jobject runtimeApi, jobject extras, jint loggingFd, int runningInAppSide) { ... programLength = _env->functions->GetArrayLength)(_env, byteCode); programBytes = (jbyte *)_env->functions->GetByteArrayElements)(_env, byteCode, 0); ...
Если запастись терпением и проследить за путем массива байт, который мы получили от anti-abuse сервера, то можно расстроиться. К сожалению, простого ответа на вопрос «что здесь вообще происходит?» не будет. Это действительно самый настоящий байт-код, а нативная библиотека — виртуальная машина. Немного AES шифрования, а дальше виртуальная машина байт за байтом читает байт-код и выполняет команды. Каждый байт — это команда, за которой следуют операнды. Команд не так много, всего штук 70: прочитать int, прочитать byte, прочитать строку, вызывать java метод, умножить два числа, if-goto и так далее.
Wake up, Neo
Я решил пойти еще чуть дальше и разобраться с форматом байт-кода для этой виртуальной машины. С командами есть одна проблема: периодически (раз в несколько недель) появляется новая версия нативной библиотеки, в которой каждой команде соответствует другой байт. Меня это не остановило, и я решил воссоздать эту виртуальную машину на Java.
Байт-код как раз и выполняет всю рутинную работу по сбору информации о девайсе. Например, загружает строку с именем метода, получает его адрес через dlsym и выполняет. В своей java версии виртуальной машины я реализовал от силы 5 методов и научился интерпретировать буквально первые 25 команд байт-кода anti-abuse сервиса. На 26-ой по счету команде виртуальная машина прочитала очередную зашифрованную строку из байт-кода. Внезапно оказалось, что это далеко не имя очередного метода.
Virtual Machine command #26
Method invocation vm->vm_method_table[2 * 0x77]
Method vmMethod_readString
index is 0x9d
string length is 0x0066
(new key is generated)
encoded string bytes are EB 4E E6 DC 34 13 35 4A DD 55 B3 91 33 05 61 04 C0 54 FD 95 2F 18 72 04 C1 55 E1 92 28 11 66 04 DD 4F B3 94 33 04 35 0A C1 4E B2 DB 12 17 79 4F 92 55 FC DB 33 05 35 45 C6 01 F7 89 29 1F 71 43 C7 40 E1 9F 6B 1E 70 48 DE 4E B8 CD 75 44 23 14 85 14 A7 C2 7F 40 26 42 84 17 A2 BB 21 19 7A 43 DE 44 BD 98 29 1B
decoded string bytes are 59 6F 75 27 72 65 20 6E 6F 74 20 6A 75 73 74 20 72 75 6E 6E 69 6E 67 20 73 74 72 69 6E 67 73 20 6F 6E 20 6F 75 72 20 2E 73 6F 21 20 54 61 6C 6B 20 74 6F 20 75 73 20 61 74 20 64 72 6F 69 64 67 75 61 72 64 2D 68 65 6C 6C 6F 2B 36 33 32 36 30 37 35 34 39 39 36 33 66 36 36 31 40 67 6F 6F 67 6C 65 2E 63 6F 6D
decoded string value is (You're not just running strings on our .so! Talk to us at droidguard@google.com)
Очень странно, до этого момента виртуальные машины никогда не разговаривали со мной. Мне показалось, это тревожный звоночек, если ты видишь адресованные тебе секретные послания. Чтобы убедиться, что крыша у меня все еще на месте, я решил прогнать через свою виртуальную машину пару сотен разных ответов от anti-abuse сервиса с байт-кодом. Каждый раз буквально через 25-30 команд в байт-коде пряталось сообщение. Часто они повторялись, но я отобрал уникальные. Адрес почты, правда, я поменял. Плюс в каждом таком сообщении адрес почты имел формат «droidguard+tag@google.com»: для каждого запроса к anti-abuse сервису этот tag уникальный.
droidguard@google.com: Don't be a stranger!
You got in! Talk to us at droidguard@google.com
Greetings from droidguard@google.com intrepid traveller! Say hi!
Was it easy to find this? droidguard@google.com would like to know
The folks at droidguard@google.com would appreciate hearing from you!
What's all this gobbledygook? Ask droidguard@google.com… they'd know!
Hey! Fancy seeing you here. Have you spoken to droidguard@google.com yet?
You're not just running strings on our .so! Talk to us at droidguard@google.com
Наверное, я тот самый избранный? Я решил, что пора прекратить копаться в DroidGuard и связаться с Google, раз они меня об этом просят.
Ваш звонок очень важен для нас
О результатах своих исследований я решил сообщить по указанному адресу. Чтобы результаты выглядели внушительнее, я немного автоматизировал процесс анализа виртуальной машины. Дело в том, что строки и массивы байт в байте-кода хранятся зашифрованными. Виртуальная машина декодирует используя константы, которые заинлайнил компилятор. С помощью программы, похожей на Hex-Rays IDA, достать их оттуда не трудно. Но с каждой новой версией нативной библиотеки эти константы меняются и доставать их вручную неудобно.
На Java парсинг нативной библиотеки получился на удивление нетрудным. При помощи jelf (библиотека для парсинга ELF файлов) находится смещение метода
Java_com_google_ccc_abuse_droidguard_DroidGuard_initNative в бинарнике, а дальше с помощью Capstone (фреймворк для дизассемблинга, есть биндинги для разных языков программирования, в том числе Java) можно получить код на ассемблере и поискать в нем загрузку констант в регистры.По итогу получилась программка, которая повторяет всю работу DroidGuard: делает запрос к anti-abuse сервису, загружает apk, распаковывает, парсит нативную библиотеку, достает оттуда нужные константы, подбирает мапинг команд виртуальной машины и интерпретирует байт-код. Собрав все это в кучу, я отправил письмо в Google. Параллельно я стал готовиться к переезду и полез изучать glassdoor на тему средней зарплаты в компании. Меньше чем на шестизначную сумму я решил не соглашаться.
Ответ не заставил себя долго ждать. Письмо от члена команды DroidGuard было довольно лаконичным: «Зачем ты этим вообще занимаешься?».

«Прост» — ответил я. Сотрудник Google объяснил мне, для чего нужен DroidGuard: для защиты Android от злоумышленников (не может быть!). И было бы разумным нигде не размещать мои исходники виртуальной машины DroidGuard. На этом наше общение закончилось.
Собеседование
Месяц спустя неожиданно пришло еще одно письмо. В команду DroidGuard в Цюрихе нужен новый сотрудник. Может я хотел бы присоединиться к ним? Еще бы!
Никаких окольных путей для устройства в Google нет. Максимум, что мог сделать для меня мой визави — переслать мое резюме в hr отдел. После этого запускается стандартная бюрократическая процедура из серии собеседований.
Информации о собеседовании в Google в интернете с избытком. Алгоритмы, олимпиадные задачки и программирование в Google Doc не было моим коньком, поэтому я стал усердно готовиться. Я затер до дыр курс «Алгоритмы» на coursera, прорешал сотню задачек на hackerrank, мог с закрытыми глазами написать обход графа в ширину и в глубину…
В подготовке прошло два месяца. Сказать, что я был готов — ничего не сказать. Google Doc стала моей любимой IDE. Мне казалось, что я знал об алгоритмах практически все. Конечно, я адекватно оценивал свои силы и понимал, что 5 очных собеседований в Цюрихе я навряд ли пройду. Но бесплатно съездить в Диснейленд для программистов в Швейцарию — это тоже неплохо. Первый этап — это собеседование по телефону, чтобы отсеять совсем слабых кандидатов и не тратить время разработчиков на очные собеседования. Был назначен день, я стал ждать звонка…
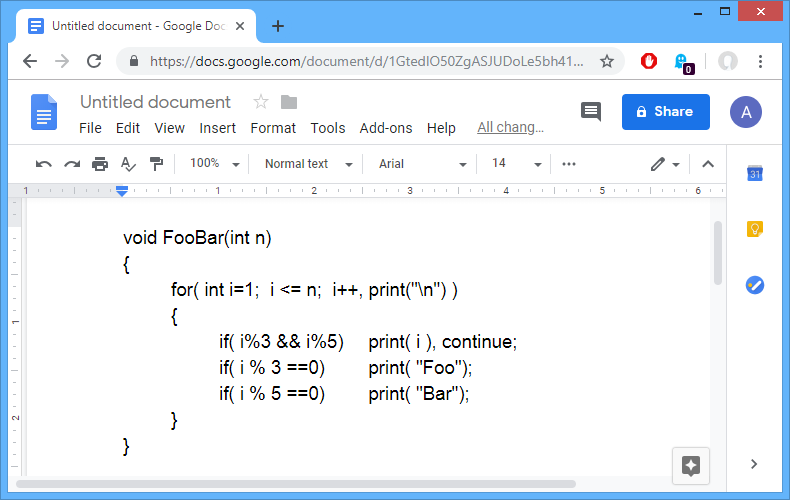
… и я сразу же провалил самое первое собеседование по телефону. Мне повезло, мне попался вопрос, который я заранее видел в интернете и который я уже решал перед собеседованием. Задача заключалась в сериализации массива строк. Я предложил кодировать строки в Base64 и сохранять их через разделитель. В ответ интервьюер предложил мне реализовать алгоритм Base64. После этого собеседование превратилось скорее в монолог, в котором интервьюер объяснял мне как работает Base64, а я вспоминал битовые операции в Java.
Если статью читают сотрудники Google
Ребята, вы гении, если вы туда смогли попасть! Серьезно. Я не представляю, как можно пройти через эту полосу препятствий.
Через 3 дня после звонка я получил письмо, в котором мне сообщали, что собеседовать дальше меня не хотят. На этом мое общение с Google полностью закончилось.
Зачем в DroidGuard спрятаны сообщения, призывающие пообщаться, я так и не понял. Возможно, просто для статистики. Как мне сказали, пишут им с разной частотой: иногда каждую неделю по три человека, а иногда раз в год.
Я думаю, чтобы попасть на собеседование в Google есть способы намного проще. В конце концов, с таким же успехом можно попросить любого из ста тысяч сотрудников компании (хотя разработчиков там поменьше, конечно). Но опыт получился интересным.

