Алгоритмы рекомендаций, предсказания событий либо оценки рисков – трендовое решение в банках, страховых компаниях и многих других отраслях бизнеса. Например, эти программы помогают на основе анализа данных предположить, когда клиент вернет банковский кредит, какой будет спрос в ритейле, какова вероятность наступления страхового случая или оттока клиентов в телекоме и т.д. Для бизнеса это ценная возможность оптимизировать свои расходы, повысить скорость работы и в целом улучшить сервис.
Вместе с тем, для построения подобных программ не годятся традиционные подходы – классификация и регрессия. Рассмотрим эту проблему на примере кейса, посвященного предсказанию медицинских эпизодов: проанализируем нюансы в природе данных и возможные подходы к моделированию, построим модель и проанализируем ее качество.
Предсказание эпизодов мы проводим на основе анализа исторических данных. Датасет при этом состоит из двух частей. Первая – это данные о ранее предоставленных пациенту услугах. Эта часть датасета включает социально-демографические данные о пациенте, такие как возраст и пол, а также выставленные ему в разные моменты времени диагнозы в кодировке ICD10-CM [1] и выполненные процедуры по HCPCS [2]. Эти данные формируют последовательности во времени, которые позволяют получить представление о состоянии пациента в интересующий момент. Для обучения моделей, как и для работы в production, достаточно персонализированных данных.
Вторая часть датасета – перечень эпизодов, возникающих для пациента. Для каждого эпизода указываем его тип и дату возникновения, а также временной период, включенные услуги и прочую информацию. Из этих данных формируются целевые переменные для предсказания.
В решаемой задаче важен аспект времени: нас интересуют только эпизоды, которые могут возникнуть в ближайшее время. С другой стороны, имеющийся в нашем распоряжении датасет собирался в течение ограниченного промежутка времени, за пределами которого данных нет. Таким образом мы не можем сказать, возникают ли эпизоды за пределами периода наблюдений, какие это эпизоды, в какой именно момент времени они возникают. Эта ситуация называется правое цензурирование (right censoring).
Аналогичным образом возникает и левое цензурирование (left censoring): для некоторых пациентов эпизод может начать развиваться раньше, чем доступно нашему наблюдению. Для нас это будет выглядеть как эпизод, возникший без всякой предыстории.
Существует еще один вид цензурирования данных – прерывание наблюдения (если период наблюдения не закончен и событие не наступило). Например, из-за переезда пациента, сбоя в системе сбора данных и так далее.
На рис. 1 схематично показаны разные виды цензурирования данных. Все они искажают статистику и затрудняют построение модели.
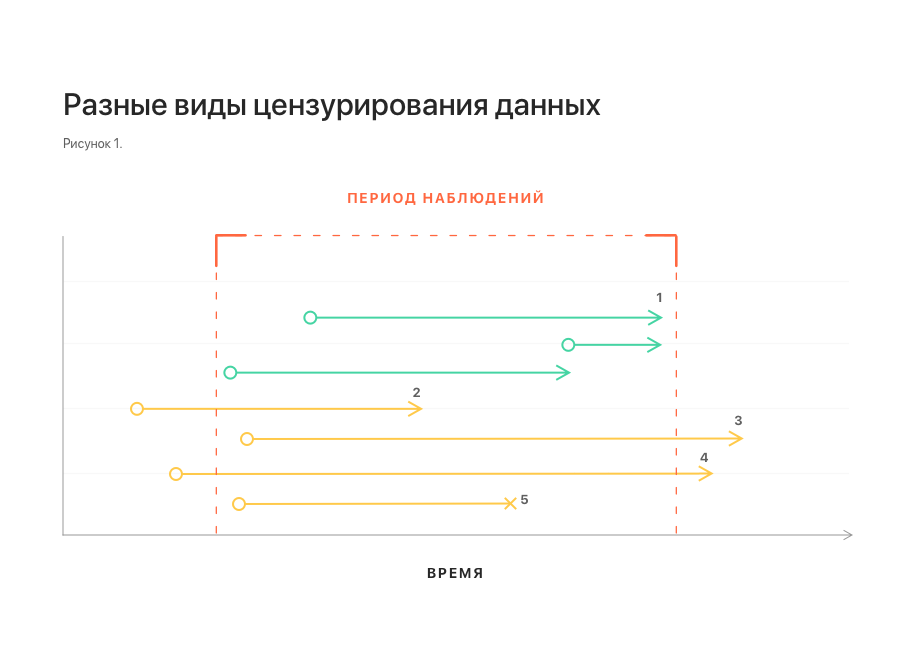
Примечания: 1 – нецензурированные наблюдения; 2, 3 – левое и правое цензурирование соответственно; 4 – левое и правое цензурирование одновременно;
5 – прерывание наблюдения.
Другая важная особенность датасета связана с природой потока данных в реальной жизни. Некоторые данные могут поступать с опозданием, в этом случае они недоступны на момент предсказания. Чтобы учесть эту особенность, необходимо дополнить датасет, выбрасывая по несколько элементов из хвоста каждой из последовательностей.
Естественно, первой мыслью будет свести задачу к хорошо известным классификации и регрессии. Однако эти подходы встречают серьезные трудности.
Почему нам не подходит регрессия, ясно из рассмотренных явлений правого и левого цензурирования: распределение времени возникновения эпизода в датасете может быть смещено. При этом величину, да и сам факт наличия этого смещения невозможно определить с помощью самого датасета. Построенная модель может показывать сколь угодно хорошие результаты с любыми подходами к валидации, но с ее пригодностью к прогнозированию на production-данных это, скорее всего, не будет иметь ничего общего.
Более перспективной, на первый взгляд, выглядит попытка свести задачу к классификации: задать некоторый промежуток времени и определять эпизод, который возникнет в этот промежуток. Основная трудность здесь – привязка интересующего нас промежутка времени. Надежно его можно привязать только к моменту последнего обновления истории пациента. При этом запрос на предсказание эпизода вообще никак не привязан ко времени и может прийти в любой момент, как внутри этого промежутка (и тогда эффективный период интереса сокращается), так и вовсе за его пределами – и тогда предсказание вообще теряет смысл (см. рис. 2). Это естественным образом побуждает увеличивать интересующий период, что, в конечном итоге, все равно снижает ценность предсказания.
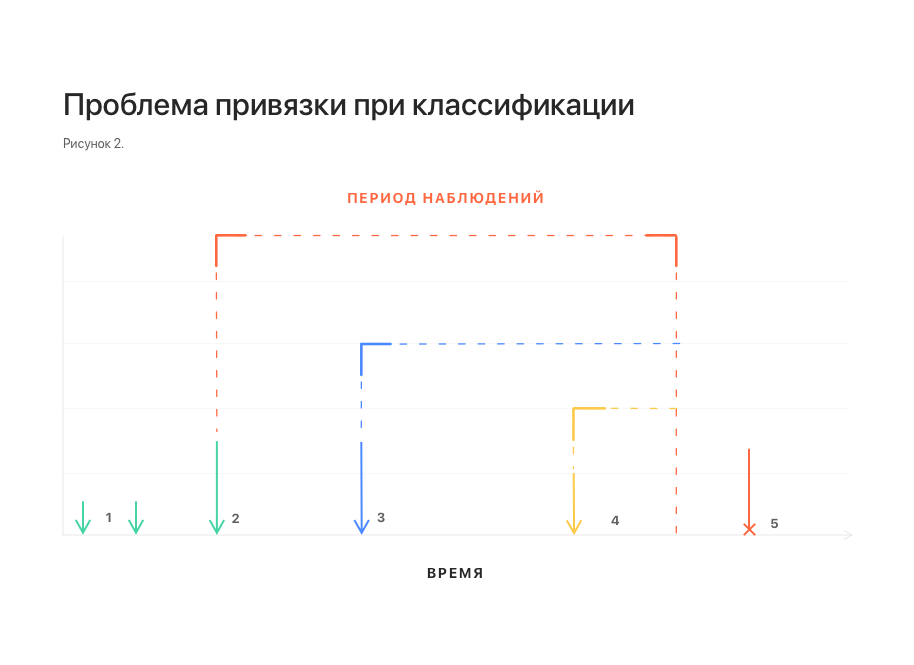
Примечания: 1 – обновления истории пациента; 2 – последнее обновление и привязанный к нему промежуток времени; 3, 4 – запросы на предсказание эпизодов, поступившие в течение данного промежутка. Видно, что эффективный промежуток предсказания для них меньше; 5 – запрос, поступивший вне промежутка. Для него предсказание невозможно.
В качестве альтернативы можно рассмотреть подход, в русскоязычной литературе называемый анализом выживаемости (survival analysis, или time-to-event analysis) [3]. Это семейство моделей, созданных специально для работы с цензурированными данными. В его основе лежит аппроксимация функции риска (hazard function, интенсивность наступления событий), которая оценивает распределение вероятности наступления события во времени. Такой подход позволяет корректно учитывать наличие разных типов цензурирования.
Для решаемой задачи такой подход дополнительно позволяет объединить в одной модели оба аспекта задачи: определение типа эпизода и прогнозирование времени его возникновения. Для этого достаточно строить по отдельной модели для каждого типа эпизодов, аналогично подходу one-vs-all в классификации. Тогда возникновение нецелевого эпизода можно трактовать как исключение объекта из наблюдаемой выборки без наступления события, что является еще одним типом цензурирования данных и также корректно учитывается моделью. Такая трактовка является корректной и с точки зрения бизнес-логики: если у пациента прооперировали катаракту, это не исключает в будущем возникновения для него и других эпизодов.
Среди семейства моделей для анализа выживаемости можно выделить две разновидности: аналитические и регрессионные. Аналитические модели – чисто описательные, они строятся для популяции целиком, не учитывают особенности отдельных ее членов, а следовательно, и прогнозировать могут лишь наступление события для некоторого типичного члена популяции. В отличие от аналитических, регрессионные модели строятся с учетом особенностей отдельных членов популяции и позволяют строить прогнозы также для отдельных членов с учетом их особенностей. в решаемой задаче использовалась именно эта разновидность, а точнее, модель Cox’s Proportional Hazard (далее – CoxPH).
Наиболее простым будет подход, аналогичный обычной регрессии: в качестве выхода взять математическое ожидание времени наступления события. Так как CoxPH принимает на входе данные в виде числового вектора, а наш датасет – это, по сути, последовательность кодов диагнозов и процедур (категориальные данные), требуется предварительная трансформация данных:
Полученные векторы признаков мы далее используем для тренировки модели и ее валидации. Полученная модель демонстрирует следующие значения concordance index (c-index или c-statistic) [5]:
Это сопоставимо с обычным для таких моделей уровнем 0,6-0,7 [6].
Однако если посмотреть на среднюю абсолютную ошибку (mean absolute error) между предсказанным ожидаемым временем возникновения эпизода и фактическим, окажется, что ошибка составляет 5 дней. Причина такой большой ошибки в том, что оптимизация под c-index гарантирует только правильность порядка значений: если одно событие должно наступить раньше другого, то предсказанные значения ожидаемого времени до событий будут одно меньше другого соответственно. При этом относительно самих по себе предсказанных величин никаких утверждений не делается.
Другой возможный вариант выходного значения модели – таблица значений функции риска в разные моменты времени. Этот вариант имеет более сложную структуру, он сложнее в интерпретации по сравнению с предыдущим, но вместе с тем он предоставляет больше информации.
Изменение формата вывода требует иного способа оценки качества модели: нам нужно убедиться, что для положительных примеров (когда эпизод возникает) уровень риска выше, чем для отрицательных примеров (когда эпизод не возникает). Для этого мы для каждого предсказанного распределения функции риска на отложенной выборке перейдем от таблицы значений к одному значению – максимуму. Посчитав медианные значения для положительных и отрицательных примеров, мы увидим, что они надежно различаются: 0,13 против 0,04 соответственно.
Далее мы используем эти значения для построения ROC-кривой и посчитаем площадь под ней – ROC AUC, которая составляет 0,92, что является приемлемым для решаемой задачи.
Таким образом, мы увидели, что анализ выживаемости – это подход, наилучшим образом применимый для решения задачи предсказания медицинских эпизодов, учитывающий все нюансы задачи и доступных данных. Однако, его применение предполагает иной формат выходных данных модели и иной подход к оценке ее качества.
Применение модели CoxPH к предсказанию эпизодов операции по поводу катаракты позволило добиться приемлемых показателей качества модели. Аналогичный подход может быть применен и к другим типам эпизодов, но конкретные показатели качества моделей могут быть оценены только непосредственно в процессе моделирования.
[1] ICD-10 Clinical Modification en.wikipedia.org/wiki/ICD-10_Clinical_Modification
[2] Healthcare Common Procedure Coding System en.wikipedia.org/wiki/Healthcare_Common_Procedure_Coding_System
[3] Survival analysis en.wikipedia.org/wiki/Survival_analysis
[4] GloVe: Global Vectors for Word Representation nlp.stanford.edu/projects/glove
[5] C-Statistic: Definition, Examples, Weighting and Significance www.statisticshowto.datasciencecentral.com/c-statistic
[6] V.C. Raykar et al. On Ranking in Survival Analysis: Bounds on the Concordance Index papers.nips.cc/paper/3375-on-ranking-in-survival-analysis-bounds-on-the-concordance-index.pdf
Вместе с тем, для построения подобных программ не годятся традиционные подходы – классификация и регрессия. Рассмотрим эту проблему на примере кейса, посвященного предсказанию медицинских эпизодов: проанализируем нюансы в природе данных и возможные подходы к моделированию, построим модель и проанализируем ее качество.
Задача прогнозирования медицинских эпизодов
Предсказание эпизодов мы проводим на основе анализа исторических данных. Датасет при этом состоит из двух частей. Первая – это данные о ранее предоставленных пациенту услугах. Эта часть датасета включает социально-демографические данные о пациенте, такие как возраст и пол, а также выставленные ему в разные моменты времени диагнозы в кодировке ICD10-CM [1] и выполненные процедуры по HCPCS [2]. Эти данные формируют последовательности во времени, которые позволяют получить представление о состоянии пациента в интересующий момент. Для обучения моделей, как и для работы в production, достаточно персонализированных данных.
Вторая часть датасета – перечень эпизодов, возникающих для пациента. Для каждого эпизода указываем его тип и дату возникновения, а также временной период, включенные услуги и прочую информацию. Из этих данных формируются целевые переменные для предсказания.
В решаемой задаче важен аспект времени: нас интересуют только эпизоды, которые могут возникнуть в ближайшее время. С другой стороны, имеющийся в нашем распоряжении датасет собирался в течение ограниченного промежутка времени, за пределами которого данных нет. Таким образом мы не можем сказать, возникают ли эпизоды за пределами периода наблюдений, какие это эпизоды, в какой именно момент времени они возникают. Эта ситуация называется правое цензурирование (right censoring).
Аналогичным образом возникает и левое цензурирование (left censoring): для некоторых пациентов эпизод может начать развиваться раньше, чем доступно нашему наблюдению. Для нас это будет выглядеть как эпизод, возникший без всякой предыстории.
Существует еще один вид цензурирования данных – прерывание наблюдения (если период наблюдения не закончен и событие не наступило). Например, из-за переезда пациента, сбоя в системе сбора данных и так далее.
На рис. 1 схематично показаны разные виды цензурирования данных. Все они искажают статистику и затрудняют построение модели.
Примечания: 1 – нецензурированные наблюдения; 2, 3 – левое и правое цензурирование соответственно; 4 – левое и правое цензурирование одновременно;
5 – прерывание наблюдения.
Другая важная особенность датасета связана с природой потока данных в реальной жизни. Некоторые данные могут поступать с опозданием, в этом случае они недоступны на момент предсказания. Чтобы учесть эту особенность, необходимо дополнить датасет, выбрасывая по несколько элементов из хвоста каждой из последовательностей.
Классификация и регрессия
Естественно, первой мыслью будет свести задачу к хорошо известным классификации и регрессии. Однако эти подходы встречают серьезные трудности.
Почему нам не подходит регрессия, ясно из рассмотренных явлений правого и левого цензурирования: распределение времени возникновения эпизода в датасете может быть смещено. При этом величину, да и сам факт наличия этого смещения невозможно определить с помощью самого датасета. Построенная модель может показывать сколь угодно хорошие результаты с любыми подходами к валидации, но с ее пригодностью к прогнозированию на production-данных это, скорее всего, не будет иметь ничего общего.
Более перспективной, на первый взгляд, выглядит попытка свести задачу к классификации: задать некоторый промежуток времени и определять эпизод, который возникнет в этот промежуток. Основная трудность здесь – привязка интересующего нас промежутка времени. Надежно его можно привязать только к моменту последнего обновления истории пациента. При этом запрос на предсказание эпизода вообще никак не привязан ко времени и может прийти в любой момент, как внутри этого промежутка (и тогда эффективный период интереса сокращается), так и вовсе за его пределами – и тогда предсказание вообще теряет смысл (см. рис. 2). Это естественным образом побуждает увеличивать интересующий период, что, в конечном итоге, все равно снижает ценность предсказания.
Примечания: 1 – обновления истории пациента; 2 – последнее обновление и привязанный к нему промежуток времени; 3, 4 – запросы на предсказание эпизодов, поступившие в течение данного промежутка. Видно, что эффективный промежуток предсказания для них меньше; 5 – запрос, поступивший вне промежутка. Для него предсказание невозможно.
Анализ выживаемости
В качестве альтернативы можно рассмотреть подход, в русскоязычной литературе называемый анализом выживаемости (survival analysis, или time-to-event analysis) [3]. Это семейство моделей, созданных специально для работы с цензурированными данными. В его основе лежит аппроксимация функции риска (hazard function, интенсивность наступления событий), которая оценивает распределение вероятности наступления события во времени. Такой подход позволяет корректно учитывать наличие разных типов цензурирования.
Для решаемой задачи такой подход дополнительно позволяет объединить в одной модели оба аспекта задачи: определение типа эпизода и прогнозирование времени его возникновения. Для этого достаточно строить по отдельной модели для каждого типа эпизодов, аналогично подходу one-vs-all в классификации. Тогда возникновение нецелевого эпизода можно трактовать как исключение объекта из наблюдаемой выборки без наступления события, что является еще одним типом цензурирования данных и также корректно учитывается моделью. Такая трактовка является корректной и с точки зрения бизнес-логики: если у пациента прооперировали катаракту, это не исключает в будущем возникновения для него и других эпизодов.
Среди семейства моделей для анализа выживаемости можно выделить две разновидности: аналитические и регрессионные. Аналитические модели – чисто описательные, они строятся для популяции целиком, не учитывают особенности отдельных ее членов, а следовательно, и прогнозировать могут лишь наступление события для некоторого типичного члена популяции. В отличие от аналитических, регрессионные модели строятся с учетом особенностей отдельных членов популяции и позволяют строить прогнозы также для отдельных членов с учетом их особенностей. в решаемой задаче использовалась именно эта разновидность, а точнее, модель Cox’s Proportional Hazard (далее – CoxPH).
Регрессия выживаемости и операция по поводу катаракты
Наиболее простым будет подход, аналогичный обычной регрессии: в качестве выхода взять математическое ожидание времени наступления события. Так как CoxPH принимает на входе данные в виде числового вектора, а наш датасет – это, по сути, последовательность кодов диагнозов и процедур (категориальные данные), требуется предварительная трансформация данных:
- Перевод кодов в embedded-представление с помощью предварительно обученной модели GloVe [4];
- Агрегация всех кодов, имеющихся в последнем периоде истории пациента, в единый вектор;
- One-hot-кодирование пола пациента и масштабирование возраста.
Полученные векторы признаков мы далее используем для тренировки модели и ее валидации. Полученная модель демонстрирует следующие значения concordance index (c-index или c-statistic) [5]:
- 0,71 на 5-fold валидации;
- 0,69 на отложенной выборке.
Это сопоставимо с обычным для таких моделей уровнем 0,6-0,7 [6].
Однако если посмотреть на среднюю абсолютную ошибку (mean absolute error) между предсказанным ожидаемым временем возникновения эпизода и фактическим, окажется, что ошибка составляет 5 дней. Причина такой большой ошибки в том, что оптимизация под c-index гарантирует только правильность порядка значений: если одно событие должно наступить раньше другого, то предсказанные значения ожидаемого времени до событий будут одно меньше другого соответственно. При этом относительно самих по себе предсказанных величин никаких утверждений не делается.
Другой возможный вариант выходного значения модели – таблица значений функции риска в разные моменты времени. Этот вариант имеет более сложную структуру, он сложнее в интерпретации по сравнению с предыдущим, но вместе с тем он предоставляет больше информации.
Изменение формата вывода требует иного способа оценки качества модели: нам нужно убедиться, что для положительных примеров (когда эпизод возникает) уровень риска выше, чем для отрицательных примеров (когда эпизод не возникает). Для этого мы для каждого предсказанного распределения функции риска на отложенной выборке перейдем от таблицы значений к одному значению – максимуму. Посчитав медианные значения для положительных и отрицательных примеров, мы увидим, что они надежно различаются: 0,13 против 0,04 соответственно.
Далее мы используем эти значения для построения ROC-кривой и посчитаем площадь под ней – ROC AUC, которая составляет 0,92, что является приемлемым для решаемой задачи.
Заключение
Таким образом, мы увидели, что анализ выживаемости – это подход, наилучшим образом применимый для решения задачи предсказания медицинских эпизодов, учитывающий все нюансы задачи и доступных данных. Однако, его применение предполагает иной формат выходных данных модели и иной подход к оценке ее качества.
Применение модели CoxPH к предсказанию эпизодов операции по поводу катаракты позволило добиться приемлемых показателей качества модели. Аналогичный подход может быть применен и к другим типам эпизодов, но конкретные показатели качества моделей могут быть оценены только непосредственно в процессе моделирования.
Литература
[1] ICD-10 Clinical Modification en.wikipedia.org/wiki/ICD-10_Clinical_Modification
[2] Healthcare Common Procedure Coding System en.wikipedia.org/wiki/Healthcare_Common_Procedure_Coding_System
[3] Survival analysis en.wikipedia.org/wiki/Survival_analysis
[4] GloVe: Global Vectors for Word Representation nlp.stanford.edu/projects/glove
[5] C-Statistic: Definition, Examples, Weighting and Significance www.statisticshowto.datasciencecentral.com/c-statistic
[6] V.C. Raykar et al. On Ranking in Survival Analysis: Bounds on the Concordance Index papers.nips.cc/paper/3375-on-ranking-in-survival-analysis-bounds-on-the-concordance-index.pdf

