ASN.1 это стандарт (ISO, ITU-T, ГОСТ) языка описывающего структурированную информацию, а также правил кодирования этой информации. Для меня как программиста это просто ещё один формат сериализации и представления данных, наравне с JSON, XML, XDR и другими. Он крайне распространён в нашей обычной жизни, и с ним многие сталкиваются: в сотовой, телефонной, VoIP связи (UMTS, LTE, WiMAX, SS7, H.323), в сетевых протоколах (LDAP, SNMP, Kerberos), во всём, что касается криптографии (X.509, CMS, PKCS-стандарты), в банковских картах и биометрических паспортах, и много где ещё.
В этой статье рассматривается PyDERASN: Python ASN.1 библиотека активно применяющаяся в проектах связанных с криптографией в ФГУП «НТЦ „Атлас“.

Вообще-то рекомендовать ASN.1 для криптографических задач не стоит: ASN.1 и его кодеки — сложны. Это означает, что код будет не прост, а это всегда лишний вектор атаки. Достаточно посмотреть на список уязвимостей в ASN.1 библиотеках. Брюс Шнайер в своей Cryptography engineering также не советует использовать этот стандарт из-за его сложности: „The best-known TLV encoding is ASN.1, but it is incredibly complex and we shy away from it“. Но, к сожалению, сегодня мы имеем инфраструктуры открытых ключей в которых активно используются X.509 сертификаты, CRL, OCSP, TSP, протоколы CMP, CMC, сообщения CMS, и масса стандартов PKCS. Поэтому приходится уметь работать с ASN.1, если вы занимаетесь чем-то связанным с криптографией.
ASN.1 может быть закодирован множеством способов/кодеков:
и рядом других. Но в криптографических задачах на практике используется два: BER и DER. Даже в подписанных XML-документах (XMLDSig, XAdES) всё равно будут Base64-закодированные ASN.1 DER объекты, как и в JSON-ориентированном протоколе ACME от Let's Encrypt-а. Лучше разобраться во всех этих кодеках и принципах кодирования BER/CER/DER можно в статьях и книгах: ASN.1 простыми словами, ASN.1 — Communication between heterogeneous systems by Olivier Dubuisson, ASN.1 Complete by Prof John Larmouth.
BER является бинарным байт-ориентированным (например PER, популярный в сотовой связи — бит-ориентирован) TLV-форматом. Каждый элемент кодируется в виде: тэга (Tag), идентифицирующего тип кодируемого элемента (целое число, строка, дата, и т.д.), длины (Length) содержимого и самого содержимого (Value). BER опционально позволяет не указывать значение длины, выставляя особое indefinite length значение и оканчивая сообщение End-Of-Octets меткой. Кроме кодирования длины, в BER много вариативности в способе кодирования типов данных, как например:
Из-за всего вышеназванного, закодировать данные так, чтобы они были идентичны оригинальной форме — не всегда возможно. Поэтому было придумано подмножество правил: DER — жёстко регламентирующий только один допустимый способ кодирования, что критично для криптографических задач, где, например, изменение одного бита сделает подпись или контрольную сумму недействительной. DER имеет существенный недостаток: длины всех элементов должны быть заранее известны во время кодирования, что не позволяет потоково сериализовать данные. CER кодек лишён этого недостатка, аналогично гарантируя однозначное представление данных. К сожалению (или счастью что не имеем ещё более сложные декодеры?), он не стал популярен. Поэтому на практике мы встречаем „смешанное“ использование BER и DER закодированных данных. Так как и CER и DER являются подмножеством BER, то любой BER-декодер способен их обработать.
На работе мы пишем много программ на Python связанных с криптографией. И несколько лет назад выбора свободных библиотек практически не было: либо это очень низкоуровневые библиотеки, позволяющие просто закодировать/декодировать, например, целое число и заголовок структуры, либо это библиотека pyasn1. На ней мы жили несколько лет и поначалу были очень довольны, так как она позволяет работать с ASN.1 структурами как с высокоуровненными объектами: например декодированный объект X.509 сертификата позволяет обращаться к своим полям через интерфейс-словаря: cert[»tbsCertificate"][«serialNumber»] нам покажет серийный номер этого сертификата. Аналогично, можно «собирать» сложные объекты работая с ними как со списками, словарями, а потом просто вызвать функцию pyasn1.codec.der.encoder.encode и получить сериализованное представление документа.
Однако, вскрывались недостатки, проблемы и ограничения. В pyasn1 были и, к сожалению, до сих пор остаются ошибки: на момент написания статьи, в pyasn1 один из базовых типов — GeneralizedTime, некорректно декодируется и кодируется.
В наших проектах, для экономии места, мы часто храним только путь к файлу, смещение и длину в байтах объекта на который хотим сослаться. Например, произвольный подписанный файл наверняка будет находится в CMS SignedData ASN.1 структуре:
и мы можем достать оригинальный подписанный файл по смещению 65 байт, длиной 751 байт. pyasn1 не хранит этой информации в своих декодированных объектах. Был написан так называемый TLVSeeker — небольшая библиотека, позволяющая декодировать тэги и длины объектов, в интерфейсе которой мы командовали «перейди к следующему тэгу», «войди внутрь тэга» (переходим внутрь SEQUENCE объекта), «перейди к следующему тэгу», «сообщи свой offset и длину объекта, где мы находимся». Это было «ручное» хождение по ASN.1 DER-сериализованным данным. Но так нельзя было так работать с BER-сериализованными данными, так как, например, байтовая строка OCTET STRING могла быть закодирована в виде нескольких chunk-ов.
Другой недостаток для наших задач pyasn1 — невозможность понять по декодированным объектам, присутствовало ли заданное поле в SEQUENCE или нет. Например, если структура содержит поле Field SEQUENCE OF Smth OPTIONAL, то оно могло полностью отсутствовать в пришедших данных (OPTIONAL), а могло присутствовать, но быть при этом нулевой длины (пустой список). В общем случае этого нельзя было выяснить. А это необходимо для жёсткой проверки валидности пришедших данных. Представьте, что какой-нибудь удостоверяющий центр выпустил бы сертификат с «не совсем» валидными с точки зрения ASN.1-схем данными! Например удостоверяющий центр «TÜRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı» в своём корневом сертификате вышел за допустимые RFC 5280 границы длины компонента subject — его невозможно честно декодировать по схеме. DER кодек требует, чтобы поле, у которого значение равно DEFAULT-ному, не кодировалось при передаче — в жизни такие документы встречаются, и первая версия PyDERASN даже осознанно допускала такое невалидное (с точки зрения DER) поведение ради обратной совместимости.
Ещё одно ограничение — невозможность легко узнать, в каком виде (BER/DER) был закодирован тот или иной объект в структуре. Например, CMS стандарт говорит, что сообщение BER-кодируется, но поле signedAttrs, над которым формируется криптографическая подпись, должно быть в DER. Если мы декодируем DER-ом, то упадём на обработке самой CMS, если декодируем BER-ом, то не узнаем в каком виде был signedAttrs. В итоге придётся TLVSeeker-ом (аналога которого нет в pyasn1) искать местоположение каждого из signedAttrs полей, и его отдельно, достав из сериализованного представления, декодировать DER-ом.
Очень желанной была для нас возможность автоматической обработки DEFINED BY полей, кои встречаются очень часто. После декодирования ASN.1 структуры у нас может остаться множество ANY полей, которые должны быть обработаны дальше по схеме, выбираемой на основе OBJECT IDENTIFIER заданном в поле структуры. В Python коде это означает написание if и дальнейший вызов декодера для ANY поля.
В Атласе мы регулярно, найдя какие-то проблемы или дорабатывая используемые свободные программы, отправляем патчи наверх. В pyasn1 мы несколько раз отправляли доработки, но код pyasn1 не самый простой для понимания и иногда в нём происходили несовместимые изменения API, бившие нас по рукам. Плюс мы привыкли к написанию тестов с генеративным тестированием, чего не было в pyasn1.
В один прекрасный день я решил, что хватить это терпеть и пора попробовать написать собственную библиотеку с __slot__-ами, offset-ами и прекрасно отображаемыми blob-ами! Просто создать ASN.1 кодек было бы недостаточно — нужно перевести все наши друг от друга зависимые проекты на неё, а это сотни тысяч строк кода в которых полно работы с ASN.1-структурами. То есть одно из требований для неё: лёгкость перевода текущего pyasn1 кода. Потратив весь свой отпуск, я написал эту библиотеку, все проекты перевёл на неё. Так как они имеют практически 100%-ный coverage тестами, то это означало и полную работоспособность библиотеки.
PyDERASN, аналогично, имеет практически 100%-ое покрытие тестами. Используется генеративное тестирование с замечательной библиотекой hypothesis. Также проводился и fuzzing py-afl-ем на 32-х ядерных машинах. Не смотря на то, что у нас практически не осталось Python2 кода, PyDERASN всё равно блюдёт совместимость с ним и из-за этого имеет единственную six зависимость. Кроме того, он протестирован напротив ASN.1:2008 compliance test suite.
Принцип работы с ним аналогичен pyasn1 — работа с высокоуровненными объектами Python. Описание ASN.1 схем схоже.
Однако, PyDERASN имеет подобие строгой типизации. В pyasn1 если поле имело тип CMSVersion(INTEGER), то ему можно было присвоить int или INTEGER. PyDERASN жёстко требует чтобы присваиваемый объект был именно CMSVersion. Кроме того, что мы пишем Python3 код, мы используем и typing annotations, поэтому в наших функциях будут не непонятные аргументы типа def func(serial, contents), а def func(serial: CertificateSerialNumber, contents: EncapsulatedContentInfo), и PyDERASN помогает блюсти такой код.
При этом в PyDERASN есть крайне удобные поблажки этой самой типизации. pyasn1 не позволял в SubjectKeyIdentifier().subtype(implicitTag=Tag(...)) поле присваивать SubjectKeyIdentifier() объект (без нужного IMPLICIT TAG-а) и приходилось часто копировать и пересоздавать объекты только из-за изменённых IMPLICIT/EXPLICIT тэгов. PyDERASN строго блюдёт только базовый тип — тэги он автоматически подставит из уже имеющейся схемы ASN.1 структуры. Это существенно упрощает код приложений.
Если происходит ошибка во время декодирования, то в pyasn1 не просто понять, где именно она произошла. Например в уже выше упоминавшемся турецком сертификате мы получим вот такую ошибку: UTF8String (tbsCertificate:issuer:rdnSequence:3:0:value:DEFINED BY 2.5.4.10:utf8String) (at 138) unsatisfied bounds: 1 ⇐ 77 ⇐ 64 При написании ASN.1 структур люди могут ошибаться, и это помогает легче отлаживать приложения или выяснять проблемы закодированных документов противоположной стороны.
В первой версии PyDERASN не было поддержки BER-кодирования. Появилась сильно позже и до сих пор ещё не поддерживается обработка UTCTime/GeneralizedTime с часовыми поясами. Это придёт в будущем, ведь проект пишется в основном в свободное от работы время.
Также в первой версии не было работы с DEFINED BY полями. Через несколько месяцев эта возможность появилась и начала активно использоваться, существенно сокращая код приложений — за одну операцию декодирования можно было получить полностью всю структуру разобранную до самой глубины. Для этого, в схеме задаются какие поля что «определяют». Например, описание схемы CMS:
говорит о том, что если contentType будет содержать OID с значением id_signedData, то поле content (находящееся в этом же SEQUENCE) нужно декодировать по схеме SignedData. Почему так много скобочек? Поле может «определять» несколько полей одновременно, как это бывает в EnvelopedData структурах. Определяемые поля идентифицируются по так называемому decode path — оно задаёт точное местоположение любого элемента во всех структурах.
Не всегда хочется или не всегда есть возможность сразу же в схему внести эти defines. Могут быть application-specific случаи когда OID-ы и структуры известны только в стороннем проекте. PyDERASN предоставляет возможность задания этих defines прямо в момент декодирования структуры:
Здесь мы говорим, что в CMS SignedData для всех приложенных сертификатов, декодировать все их расширения (AuthorityKeyIdentifier, BasicConstraints, SubjectSignTool, и т.д.). Мы указываем через decode path, какому элементу нужно «подставить» defines, как будто он был задан в схеме.
Наконец, PyDERASN имеет возможность работы из командной строки для декодирования ASN.1 файлов и имеет богатый pretty printing. Можно декодировать произвольный ASN.1, а можно задать чётко заданную схему и увидеть нечто подобное:
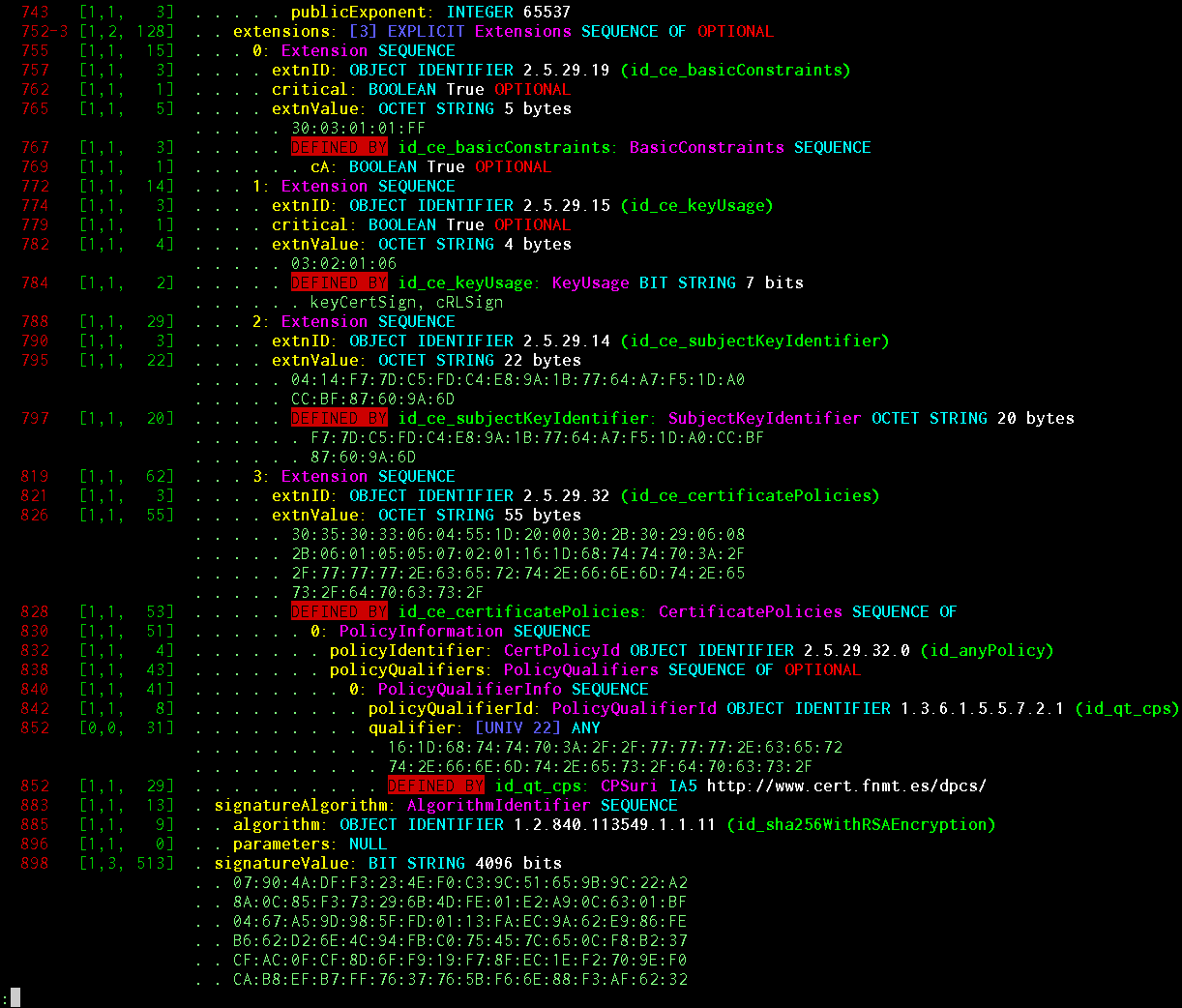
Показываемая информация: смещение объекта, длина тэга, длина длины, длина содержимого, наличие EOC (end-of-octets), признак BER-кодирования, признак indefinite-length кодирования, длина и смещение EXPLICIT тэга (если есть), глубина вложенности объекта в структурах, IMPLICIT/EXPLICIT значение тэга, название объекта по схеме, его базовый ASN.1 тип, порядковый номер внутри SEQUENCE/SET OF, значением CHOICE (если есть), человекочитаемое название INTEGER/ENUMERATED/BIT STRING по схеме, значение любого базового типа, DEFAULT/OPTIONAL флаг из схемы, признак что объект был автоматически декодирован как DEFINED BY и за счёт какого OID-а это произошло, человекочитаемый OID.
Система pretty printing-а специально сделана так, что она генерирует последовательность PP-объектов, которые визуализируются уже отдельными средствами. На screenshot-е показан renderer в простой цветной текст. Существуют и renderer-ы в JSON/HTML формат, чтобы это можно было с подсветкой увидеть в броузере ASN.1 как в asn1js проекте.
Это не было целью, но PyDERASN получился существенно более быстрым чем pyasn1. Например, декодирование CRL файлов мегабайтных размеров может занимать настолько продолжительное время, что придётся думать про промежуточные форматы хранения данных (быстрых) и менять архитектуру приложений. pyasn1 декодирует CRL CACert.org на моём ноутбуке более 20 минут, тогда как PyDERASN всего за 28 секунд! Есть проект asn1crypto, нацеленный на быструю работу с криптографическими структурами: он декодирует (полностью, не лениво) этот же самый CRL за 29 секунд, однако потребляет почти в два раза больше оперативной памяти при запуске под Python3 (983 MiB против 498-ми), и в 3.5 раза под Python2 (1677 против 488), тогда как pyasn1 потребляет аж в 4.3 раза больше (2093 против 488).
asn1crypto, который я упомянул, мы не рассматривали, потому что проект ещё только зарождался, и мы не слышали про него. Сейчас бы тоже не стали смотреть в его сторону, так как мною сразу обнаружилось, что тот же GeneralizedTime он не принимает произвольного вида, а при сериализации он молча убирает доли секунды. Это приемлемо для работы с X.509 сертификатами, но в общем случае не подойдёт.
На данный момент, PyDERASN самый строгий из свободных Python/Go DER-декодеров мне известных. В encoding/asn1 библиотеке мною любимого Go не строгая проверка OBJECT IDENTIFIER и UTCTime/GeneralizedTime строк. Иногда строгость может помешать (в первую очередь, из-за обратной совместимости со старыми приложениями, которые никто не будет исправлять), поэтому в PyDERASN во время декодирования можно передавать различные настройки ослабляющие проверки.
Код проекта старается быть максимально простым. Вся библиотека — один файл. Код написан с упором на простоту понимания, без излишних оптимизаций производительности и DRY-кода. В нём нет, как уже говорил, поддержки полноценного BER-декодирования UTCTime/GeneralizedTime строк, а также REAL, RELATIVE OID, EXTERNAL, INSTANCE OF, EMBEDDED PDV, CHARACTER STRING типов данных. Во всех остальных случаях лично я не вижу смысла использовать в Python другие библиотеки.
Как и все мои проекты, типа PyGOST, GoGOST, NNCP, GoVPN, PyDERASN является полностью свободным ПО, распространяемым на условиях LGPLv3+, и доступен для бесплатного скачивания. Примеры использования есть тут и в тестах PyGOST.
Сергей Матвеев, шифропанк, член Фонда СПО, Python/Go-разработчик, главный специалист ФГУП «НТЦ „Атлас“.
В этой статье рассматривается PyDERASN: Python ASN.1 библиотека активно применяющаяся в проектах связанных с криптографией в ФГУП «НТЦ „Атлас“.
Вообще-то рекомендовать ASN.1 для криптографических задач не стоит: ASN.1 и его кодеки — сложны. Это означает, что код будет не прост, а это всегда лишний вектор атаки. Достаточно посмотреть на список уязвимостей в ASN.1 библиотеках. Брюс Шнайер в своей Cryptography engineering также не советует использовать этот стандарт из-за его сложности: „The best-known TLV encoding is ASN.1, but it is incredibly complex and we shy away from it“. Но, к сожалению, сегодня мы имеем инфраструктуры открытых ключей в которых активно используются X.509 сертификаты, CRL, OCSP, TSP, протоколы CMP, CMC, сообщения CMS, и масса стандартов PKCS. Поэтому приходится уметь работать с ASN.1, если вы занимаетесь чем-то связанным с криптографией.
ASN.1 может быть закодирован множеством способов/кодеков:
- BER (Basic Encoding Rules)
- CER (Canonical Encoding Rules)
- DER (Distinguished Encoding Rules)
- GSER (Generic String Encoding Rules)
- JER (JSON Encoding Rules)
- LWER (Light Weight Encoding Rules)
- OER (Octet Encoding Rules)
- PER (Packed Encoding Rules)
- SER (Signalling specific Encoding Rules)
- XER (XML Encoding Rules)
и рядом других. Но в криптографических задачах на практике используется два: BER и DER. Даже в подписанных XML-документах (XMLDSig, XAdES) всё равно будут Base64-закодированные ASN.1 DER объекты, как и в JSON-ориентированном протоколе ACME от Let's Encrypt-а. Лучше разобраться во всех этих кодеках и принципах кодирования BER/CER/DER можно в статьях и книгах: ASN.1 простыми словами, ASN.1 — Communication between heterogeneous systems by Olivier Dubuisson, ASN.1 Complete by Prof John Larmouth.
BER является бинарным байт-ориентированным (например PER, популярный в сотовой связи — бит-ориентирован) TLV-форматом. Каждый элемент кодируется в виде: тэга (Tag), идентифицирующего тип кодируемого элемента (целое число, строка, дата, и т.д.), длины (Length) содержимого и самого содержимого (Value). BER опционально позволяет не указывать значение длины, выставляя особое indefinite length значение и оканчивая сообщение End-Of-Octets меткой. Кроме кодирования длины, в BER много вариативности в способе кодирования типов данных, как например:
- INTEGER, OBJECT IDENTIFIER, BIT STRING и длина элемента могут быть ненормализованы (не закодированы в минимальной форме);
- BOOLEAN является истинным при любом ненулевом содержимого;
- BIT STRING может содержать „лишние“ нулевые биты;
- BIT STRING, OCTET STRING и все их производные строковые типы, в том числе дата/время, могут быть разбиты на кусочки (chunk) переменной длины, длина которых во время (де)кодирования заранее не известна;
- UTCTime/GeneralizedTime могут иметь разные способы задания смещения временной зоны и „лишние“ нулевые доли секунд;
- DEFAULT значения SEQUENCE можно кодировать, а можно и нет;
- Именованные значения последних бит в BIT STRING можно по желанию не кодировать;
- SEQUENCE (OF)/SET (OF) могут иметь произвольный порядок элементов.
Из-за всего вышеназванного, закодировать данные так, чтобы они были идентичны оригинальной форме — не всегда возможно. Поэтому было придумано подмножество правил: DER — жёстко регламентирующий только один допустимый способ кодирования, что критично для криптографических задач, где, например, изменение одного бита сделает подпись или контрольную сумму недействительной. DER имеет существенный недостаток: длины всех элементов должны быть заранее известны во время кодирования, что не позволяет потоково сериализовать данные. CER кодек лишён этого недостатка, аналогично гарантируя однозначное представление данных. К сожалению (или счастью что не имеем ещё более сложные декодеры?), он не стал популярен. Поэтому на практике мы встречаем „смешанное“ использование BER и DER закодированных данных. Так как и CER и DER являются подмножеством BER, то любой BER-декодер способен их обработать.
Проблемы с pyasn1
На работе мы пишем много программ на Python связанных с криптографией. И несколько лет назад выбора свободных библиотек практически не было: либо это очень низкоуровневые библиотеки, позволяющие просто закодировать/декодировать, например, целое число и заголовок структуры, либо это библиотека pyasn1. На ней мы жили несколько лет и поначалу были очень довольны, так как она позволяет работать с ASN.1 структурами как с высокоуровненными объектами: например декодированный объект X.509 сертификата позволяет обращаться к своим полям через интерфейс-словаря: cert[»tbsCertificate"][«serialNumber»] нам покажет серийный номер этого сертификата. Аналогично, можно «собирать» сложные объекты работая с ними как со списками, словарями, а потом просто вызвать функцию pyasn1.codec.der.encoder.encode и получить сериализованное представление документа.
Однако, вскрывались недостатки, проблемы и ограничения. В pyasn1 были и, к сожалению, до сих пор остаются ошибки: на момент написания статьи, в pyasn1 один из базовых типов — GeneralizedTime, некорректно декодируется и кодируется.
В наших проектах, для экономии места, мы часто храним только путь к файлу, смещение и длину в байтах объекта на который хотим сослаться. Например, произвольный подписанный файл наверняка будет находится в CMS SignedData ASN.1 структуре:
0 [1,3,1018] ContentInfo SEQUENCE 4 [1,1, 9] . contentType: ContentType OBJECT IDENTIFIER 1.2.840.113549.1.7.2 (id_signedData) 19-4 [0,0,1003] . content: [0] EXPLICIT [UNIV 16] ANY 19 [1,3, 999] . . DEFINED BY id_signedData: SignedData SEQUENCE 23 [1,1, 1] . . . version: CMSVersion INTEGER v3 (03) 26 [1,1, 19] . . . digestAlgorithms: DigestAlgorithmIdentifiers SET OF [...] 47 [1,3, 769] . . . encapContentInfo: EncapsulatedContentInfo SEQUENCE 51 [1,1, 8] . . . . eContentType: ContentType OBJECT IDENTIFIER 1.3.6.1.5.5.7.12.2 (id_cct_PKIData) 65-4 [1,3, 751] . . . . eContent: [0] EXPLICIT OCTET STRING 751 bytes OPTIONAL ТУТ СОДЕРЖИМОЕ ПОДПИСЫВАЕМОГО ФАЙЛА РАЗМЕРОМ 751 байт 820 [1,2, 199] . . . signerInfos: SignerInfos SET OF 823 [1,2, 196] . . . . 0: SignerInfo SEQUENCE 826 [1,1, 1] . . . . . version: CMSVersion INTEGER v3 (03) 829 [0,0, 22] . . . . . sid: SignerIdentifier CHOICE subjectKeyIdentifier [...] 956 [1,1, 64] . . . . . signature: SignatureValue OCTET STRING 64 bytes . . . . . . C1:B3:88:BA:F8:92:1C:E6:3E:41:9B:E0:D3:E9:AF:D8 . . . . . . 47:4A:8A:9D:94:5D:56:6B:F0:C1:20:38:D2:72:22:12 . . . . . . 9F:76:46:F6:51:5F:9A:8D:BF:D7:A6:9B:FD:C5:DA:D2 . . . . . . F3:6B:00:14:A4:9D:D7:B5:E1:A6:86:44:86:A7:E8:C9
и мы можем достать оригинальный подписанный файл по смещению 65 байт, длиной 751 байт. pyasn1 не хранит этой информации в своих декодированных объектах. Был написан так называемый TLVSeeker — небольшая библиотека, позволяющая декодировать тэги и длины объектов, в интерфейсе которой мы командовали «перейди к следующему тэгу», «войди внутрь тэга» (переходим внутрь SEQUENCE объекта), «перейди к следующему тэгу», «сообщи свой offset и длину объекта, где мы находимся». Это было «ручное» хождение по ASN.1 DER-сериализованным данным. Но так нельзя было так работать с BER-сериализованными данными, так как, например, байтовая строка OCTET STRING могла быть закодирована в виде нескольких chunk-ов.
Другой недостаток для наших задач pyasn1 — невозможность понять по декодированным объектам, присутствовало ли заданное поле в SEQUENCE или нет. Например, если структура содержит поле Field SEQUENCE OF Smth OPTIONAL, то оно могло полностью отсутствовать в пришедших данных (OPTIONAL), а могло присутствовать, но быть при этом нулевой длины (пустой список). В общем случае этого нельзя было выяснить. А это необходимо для жёсткой проверки валидности пришедших данных. Представьте, что какой-нибудь удостоверяющий центр выпустил бы сертификат с «не совсем» валидными с точки зрения ASN.1-схем данными! Например удостоверяющий центр «TÜRKTRUST Elektronik Sertifika Hizmet Sağlayıcısı» в своём корневом сертификате вышел за допустимые RFC 5280 границы длины компонента subject — его невозможно честно декодировать по схеме. DER кодек требует, чтобы поле, у которого значение равно DEFAULT-ному, не кодировалось при передаче — в жизни такие документы встречаются, и первая версия PyDERASN даже осознанно допускала такое невалидное (с точки зрения DER) поведение ради обратной совместимости.
Ещё одно ограничение — невозможность легко узнать, в каком виде (BER/DER) был закодирован тот или иной объект в структуре. Например, CMS стандарт говорит, что сообщение BER-кодируется, но поле signedAttrs, над которым формируется криптографическая подпись, должно быть в DER. Если мы декодируем DER-ом, то упадём на обработке самой CMS, если декодируем BER-ом, то не узнаем в каком виде был signedAttrs. В итоге придётся TLVSeeker-ом (аналога которого нет в pyasn1) искать местоположение каждого из signedAttrs полей, и его отдельно, достав из сериализованного представления, декодировать DER-ом.
Очень желанной была для нас возможность автоматической обработки DEFINED BY полей, кои встречаются очень часто. После декодирования ASN.1 структуры у нас может остаться множество ANY полей, которые должны быть обработаны дальше по схеме, выбираемой на основе OBJECT IDENTIFIER заданном в поле структуры. В Python коде это означает написание if и дальнейший вызов декодера для ANY поля.
Появление PyDERASN
В Атласе мы регулярно, найдя какие-то проблемы или дорабатывая используемые свободные программы, отправляем патчи наверх. В pyasn1 мы несколько раз отправляли доработки, но код pyasn1 не самый простой для понимания и иногда в нём происходили несовместимые изменения API, бившие нас по рукам. Плюс мы привыкли к написанию тестов с генеративным тестированием, чего не было в pyasn1.
В один прекрасный день я решил, что хватить это терпеть и пора попробовать написать собственную библиотеку с __slot__-ами, offset-ами и прекрасно отображаемыми blob-ами! Просто создать ASN.1 кодек было бы недостаточно — нужно перевести все наши друг от друга зависимые проекты на неё, а это сотни тысяч строк кода в которых полно работы с ASN.1-структурами. То есть одно из требований для неё: лёгкость перевода текущего pyasn1 кода. Потратив весь свой отпуск, я написал эту библиотеку, все проекты перевёл на неё. Так как они имеют практически 100%-ный coverage тестами, то это означало и полную работоспособность библиотеки.
PyDERASN, аналогично, имеет практически 100%-ое покрытие тестами. Используется генеративное тестирование с замечательной библиотекой hypothesis. Также проводился и fuzzing py-afl-ем на 32-х ядерных машинах. Не смотря на то, что у нас практически не осталось Python2 кода, PyDERASN всё равно блюдёт совместимость с ним и из-за этого имеет единственную six зависимость. Кроме того, он протестирован напротив ASN.1:2008 compliance test suite.
Принцип работы с ним аналогичен pyasn1 — работа с высокоуровненными объектами Python. Описание ASN.1 схем схоже.
class TBSCertificate(Sequence): schema = ( ("version", Version(expl=tag_ctxc(0), default="v1")), ("serialNumber", CertificateSerialNumber()), ("signature", AlgorithmIdentifier()), ("issuer", Name()), ("validity", Validity()), ("subject", Name()), ("subjectPublicKeyInfo", SubjectPublicKeyInfo()), ("issuerUniqueID", UniqueIdentifier(impl=tag_ctxp(1), optional=True)), ("subjectUniqueID", UniqueIdentifier(impl=tag_ctxp(2), optional=True)), ("extensions", Extensions(expl=tag_ctxc(3), optional=True)), )
Однако, PyDERASN имеет подобие строгой типизации. В pyasn1 если поле имело тип CMSVersion(INTEGER), то ему можно было присвоить int или INTEGER. PyDERASN жёстко требует чтобы присваиваемый объект был именно CMSVersion. Кроме того, что мы пишем Python3 код, мы используем и typing annotations, поэтому в наших функциях будут не непонятные аргументы типа def func(serial, contents), а def func(serial: CertificateSerialNumber, contents: EncapsulatedContentInfo), и PyDERASN помогает блюсти такой код.
При этом в PyDERASN есть крайне удобные поблажки этой самой типизации. pyasn1 не позволял в SubjectKeyIdentifier().subtype(implicitTag=Tag(...)) поле присваивать SubjectKeyIdentifier() объект (без нужного IMPLICIT TAG-а) и приходилось часто копировать и пересоздавать объекты только из-за изменённых IMPLICIT/EXPLICIT тэгов. PyDERASN строго блюдёт только базовый тип — тэги он автоматически подставит из уже имеющейся схемы ASN.1 структуры. Это существенно упрощает код приложений.
Если происходит ошибка во время декодирования, то в pyasn1 не просто понять, где именно она произошла. Например в уже выше упоминавшемся турецком сертификате мы получим вот такую ошибку: UTF8String (tbsCertificate:issuer:rdnSequence:3:0:value:DEFINED BY 2.5.4.10:utf8String) (at 138) unsatisfied bounds: 1 ⇐ 77 ⇐ 64 При написании ASN.1 структур люди могут ошибаться, и это помогает легче отлаживать приложения или выяснять проблемы закодированных документов противоположной стороны.
В первой версии PyDERASN не было поддержки BER-кодирования. Появилась сильно позже и до сих пор ещё не поддерживается обработка UTCTime/GeneralizedTime с часовыми поясами. Это придёт в будущем, ведь проект пишется в основном в свободное от работы время.
Также в первой версии не было работы с DEFINED BY полями. Через несколько месяцев эта возможность появилась и начала активно использоваться, существенно сокращая код приложений — за одну операцию декодирования можно было получить полностью всю структуру разобранную до самой глубины. Для этого, в схеме задаются какие поля что «определяют». Например, описание схемы CMS:
class ContentInfo(Sequence): schema = ( ("contentType", ContentType(defines=((("content",), { id_authenticatedData: AuthenticatedData(), id_digestedData: DigestedData(), id_encryptedData: EncryptedData(), id_envelopedData: EnvelopedData(), id_signedData: SignedData(), }),))), ("content", Any(expl=tag_ctxc(0))), )
говорит о том, что если contentType будет содержать OID с значением id_signedData, то поле content (находящееся в этом же SEQUENCE) нужно декодировать по схеме SignedData. Почему так много скобочек? Поле может «определять» несколько полей одновременно, как это бывает в EnvelopedData структурах. Определяемые поля идентифицируются по так называемому decode path — оно задаёт точное местоположение любого элемента во всех структурах.
Не всегда хочется или не всегда есть возможность сразу же в схему внести эти defines. Могут быть application-specific случаи когда OID-ы и структуры известны только в стороннем проекте. PyDERASN предоставляет возможность задания этих defines прямо в момент декодирования структуры:
ContentInfo().decode(data, ctx={"defines_by_path": (( ( "content", DecodePathDefBy(id_signedData), "certificates", any, "certificate", "tbsCertificate", "extensions", any, "extnID", ), ((("extnValue",), { id_ce_authorityKeyIdentifier: AuthorityKeyIdentifier(), id_ce_basicConstraints: BasicConstraints(), [...] id_ru_subjectSignTool: SubjectSignTool(), }),), ),)})
Здесь мы говорим, что в CMS SignedData для всех приложенных сертификатов, декодировать все их расширения (AuthorityKeyIdentifier, BasicConstraints, SubjectSignTool, и т.д.). Мы указываем через decode path, какому элементу нужно «подставить» defines, как будто он был задан в схеме.
Наконец, PyDERASN имеет возможность работы из командной строки для декодирования ASN.1 файлов и имеет богатый pretty printing. Можно декодировать произвольный ASN.1, а можно задать чётко заданную схему и увидеть нечто подобное:
Показываемая информация: смещение объекта, длина тэга, длина длины, длина содержимого, наличие EOC (end-of-octets), признак BER-кодирования, признак indefinite-length кодирования, длина и смещение EXPLICIT тэга (если есть), глубина вложенности объекта в структурах, IMPLICIT/EXPLICIT значение тэга, название объекта по схеме, его базовый ASN.1 тип, порядковый номер внутри SEQUENCE/SET OF, значением CHOICE (если есть), человекочитаемое название INTEGER/ENUMERATED/BIT STRING по схеме, значение любого базового типа, DEFAULT/OPTIONAL флаг из схемы, признак что объект был автоматически декодирован как DEFINED BY и за счёт какого OID-а это произошло, человекочитаемый OID.
Система pretty printing-а специально сделана так, что она генерирует последовательность PP-объектов, которые визуализируются уже отдельными средствами. На screenshot-е показан renderer в простой цветной текст. Существуют и renderer-ы в JSON/HTML формат, чтобы это можно было с подсветкой увидеть в броузере ASN.1 как в asn1js проекте.
Другие библиотеки
Это не было целью, но PyDERASN получился существенно более быстрым чем pyasn1. Например, декодирование CRL файлов мегабайтных размеров может занимать настолько продолжительное время, что придётся думать про промежуточные форматы хранения данных (быстрых) и менять архитектуру приложений. pyasn1 декодирует CRL CACert.org на моём ноутбуке более 20 минут, тогда как PyDERASN всего за 28 секунд! Есть проект asn1crypto, нацеленный на быструю работу с криптографическими структурами: он декодирует (полностью, не лениво) этот же самый CRL за 29 секунд, однако потребляет почти в два раза больше оперативной памяти при запуске под Python3 (983 MiB против 498-ми), и в 3.5 раза под Python2 (1677 против 488), тогда как pyasn1 потребляет аж в 4.3 раза больше (2093 против 488).
asn1crypto, который я упомянул, мы не рассматривали, потому что проект ещё только зарождался, и мы не слышали про него. Сейчас бы тоже не стали смотреть в его сторону, так как мною сразу обнаружилось, что тот же GeneralizedTime он не принимает произвольного вида, а при сериализации он молча убирает доли секунды. Это приемлемо для работы с X.509 сертификатами, но в общем случае не подойдёт.
На данный момент, PyDERASN самый строгий из свободных Python/Go DER-декодеров мне известных. В encoding/asn1 библиотеке мною любимого Go не строгая проверка OBJECT IDENTIFIER и UTCTime/GeneralizedTime строк. Иногда строгость может помешать (в первую очередь, из-за обратной совместимости со старыми приложениями, которые никто не будет исправлять), поэтому в PyDERASN во время декодирования можно передавать различные настройки ослабляющие проверки.
Код проекта старается быть максимально простым. Вся библиотека — один файл. Код написан с упором на простоту понимания, без излишних оптимизаций производительности и DRY-кода. В нём нет, как уже говорил, поддержки полноценного BER-декодирования UTCTime/GeneralizedTime строк, а также REAL, RELATIVE OID, EXTERNAL, INSTANCE OF, EMBEDDED PDV, CHARACTER STRING типов данных. Во всех остальных случаях лично я не вижу смысла использовать в Python другие библиотеки.
Как и все мои проекты, типа PyGOST, GoGOST, NNCP, GoVPN, PyDERASN является полностью свободным ПО, распространяемым на условиях LGPLv3+, и доступен для бесплатного скачивания. Примеры использования есть тут и в тестах PyGOST.
Сергей Матвеев, шифропанк, член Фонда СПО, Python/Go-разработчик, главный специалист ФГУП «НТЦ „Атлас“.

