1. Понятие случайной базы данных.
Первые же бизнес-связи человека описываются формальными и неформальными документами такими, как заявление, декларация, трудовой контракт, заявка на размещение, заявка на ресурс. Эти документы создают логические связи между бизнес-процессами, но, как правило, являются продуктом мышления офис-менеджеров и плохо формализуются.
Задачей любой хоть сколько-то сложной оптимизации является не только понять формальные и неформальные правила, но, зачастую, привести разрозненные знания к общей информационной базе.
Определение. Случайной базой данных назовем набор из фактов, документов, ручных заметок, формальных документов, которые обрабатываются человеком для определенного бизнес-процесса, но полностью автоматически обработаны быть не могут из-за сильного влияния человеческого фактора.
Пример. Секретарь формально принимает звонок. Звонящий интересуется товаром или услугой. Звонящий не известен CRM. Вопрос: что должен говорить звонящий, чтобы быть услышанным специалистом?
Если сформулировать точнее: насколько бизнес-инструкции секретаря позволяют вести формальный диалог о бизнесе, если ответственный специалист не готов к такого вида активности?
Получается, что мы снова приходим к определению случайной базы данных.
Может быть, она содержит больше фактов, чем может знать секретарь. Но лишней информация, полученная в ней, быть не может. В целом, когда на вход формализованной системы поступают случайные факты случайной базы данных, то тут и возникает такое понятие, как информационная перегрузка — а вся информационная перегрузка может сказаться на производительности не только секретаря, но и всей компании.
Если ее использовать для целей обработки, то машина, считывающая состояния этой информации, приходит на основании логических выводов в противоположное человеку состояние — информационную перегрузку. Логика человека более гибка.
2. Применение определения к реальным задачам.
Представим себе магазин, в котором ценники на случайные товары заметно завышены или занижены. При выходе из этого магазина в голове неискушенного списком покупок покупателя останется цена 5-7 (а то и 3) наиболее ходовых товаров, цена которых может повлиять на размер суммарного чека. Получается, что если бы можно было знать список товаров, цену на которые чаще всего вспоминают покупатели, то и остальные цены можно было бы варьировать в сравнительно широком диапазоне.
Вы никогда не задумывались, почему перед Великим постом мясо сначала резко дешевеет, а потом может резко подорожать, а потом — исчезнуть? Цена на продукт, спрос на который может упасть до нуля, сначала подогревается искусственно, потом, переходя некоторую планку спроса, начинает фиксироваться, а, через некоторое время форсированно растет, так как жадность не позволяет отдать уже неликвидный товар по справедливой цене.
Почти аналогичная ситуация складывается и на рынке данных. Самая полезная информация почти всегда находится под спудом вторичных гипотез о ее применимости и извлекаемости.
Достаточно на любом сравнительно незащищенном ресурсе выложить любую информацию, которая интересна 5000-7000 человек, обязательно найдутся сайты-копипастеры.
Или знаменитая игра с телефонными кодами «Кто мне звонил?». Около тысячи сайтов в рунете состоят только из номеров телефонов различных операторов, чтобы быть в поисковой выдаче немного повыше, стремясь хоть как-то продать доменное имя и рекламу подороже.
3. Цена вопроса при работе «грязными» данными.
По исследованиям автора статьи, до 10% процентов трудовых ресурсов каждого проекта отвлекается на написание тех или иных процедур очистки данных. Если не останавливаться на совсем банальных типе и длине, то есть еще уникальные идентификаторы, правила целостности базы данных и бизнес-правила целостности, шкалы единиц количественные и качественные, системы единиц трудоемкости и любых других состояний, влияний, переходов, составление которых требует как обычного статистического, так и логического и серьезного бизнес-анализа. Формализация требований приходит к необходимости формализовать связь факт-измерение как для построения хранилищ, так и для решения вопросов по фронтенду.
Согласитесь, если 70% времени работы любого хранилища занимают процессы ETL, то экономия 5-7% ресурсов на правильной вычистке данных на условном хранилище в 200 000 клиентов — уже неплохой бонус?
Немного осветим вопросы «грязных» данных в уже готовых системах. Скажем, вы на 10 000 клиентов через почту отсылаете поздравление с национальным праздником. Сколько людей выкинут ваше письмо с самой хорошей открыткой в почтовый ящик, если вы сделаете ошибку в имени, фамилии, или неправильно в бланке заполните пол? Цена ваших усилий может свести настроение любого пользователя к нулю!
4. Oracle Enterprise Data Quality — щит и меч корпоративного хранилища.
На приводимых нами скриншотах описываются возможности продукта Oracle Enterprise Data Quality.
Итак, пусть на вашу базу данных или текстовый документ кто-то пролил воду.

Приведем список стандандартных процессоров (логических единиц, позволяющих применять
к данным те или иные гипотезы, либо искать требуемое):

Действие профилировщика случайной базы данных:

Элементарная проверка финансовой состоятельности:

Работа с почтовым индексом:

Работы по чистке почтового адреса:
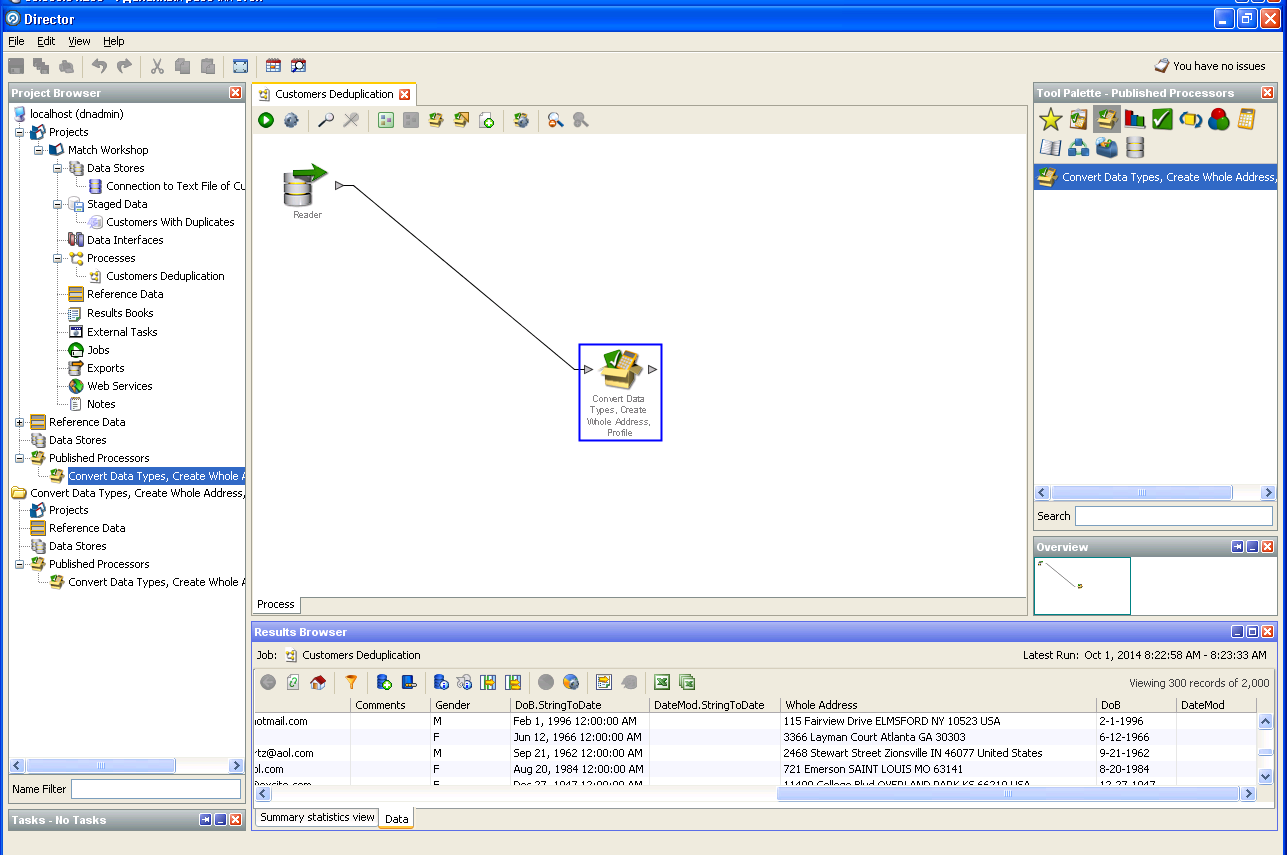
Очистка данных о пользователе:

Отнесение записи к тому или иному доверительному интервалу:

Определение пола пользователя из косвенных данных:

Определение города и страны, штата:

Простейший поиск ключей в случайной базе данных:

Дедубликация данных о пользователе:

5. Забавные наблюдения, сделанные над результатами работы на Oracle EDQ.
Одним из принципов сравнения вклада писателей и поэтов в литературу является сопоставление их поэтических и писательских словарей. Приводим ряд словарей, составленных в свободное время для тестов готовых решений на Oracle EDQ, Python, Java. Будем благодарны, если авторы-филологи в комментариях выложат свои результаты.
| Номер п.п. |
Слово |
Частота вхождения |
|||
| Лев
|
И.
|
И.
|
Н.
|
||
| 1. |
и |
10351 |
в |
в |
и |
| 3. |
в |
5185 |
и |
и |
в |
| 4. |
не |
4292 |
не |
не |
не |
| 5. |
что |
3845 |
на |
на |
я |
| 6. |
он |
3730 |
как |
как |
с |
| 7. |
на |
3305 |
с |
с |
на |
| 8. |
с |
3030 |
что |
что |
как |
| 9. |
как |
2097 |
к |
И |
что |
| 10. |
я |
1896 |
от |
я |
он |
| 11. |
его |
1882 |
из |
к |
ты |
| 12. |
к |
1771 |
я |
от |
но |
| 13. |
то |
1600 |
где |
все |
а |
| 14. |
она |
1564 |
чем |
по |
так |
| 15. |
но |
1234 |
за |
ты |
к |
| 16. |
это |
1208 |
по |
В |
всё |
| 17. |
сказал |
1135 |
Но |
за |
за |
| 18. |
было |
1125 |
ни |
из |
мне |
| 19. |
так |
1032 |
бы |
но |
да |
| 20. |
князь |
1012 |
то |
он |
его |
| 21. |
за |
985 |
ты |
Но |
то |
| 22. |
а |
962 |
о |
то |
был |
| 23. |
ему |
918 |
но |
о |
по |
| 24. |
всё |
908 |
есть |
это |
нет |
| 25. |
по |
895 |
Я |
Я |
ни |
| 26. |
ее |
885 |
|
а |
о |
| 27. |
из |
845 |
|
где |
их |
| 28. |
|
|
|
чем |
из |
| 29. |
|
|
|
А |
от |
| 30. |
|
|
|
же |
мы |
Вывод: статистика русского языка за последние сто лет по частотности отдельных слов почти не поменялась, у поэтов — слова более «певучие». Кстати, у Дарьи Донцовой статистика во многом совпадает со Львом Толстым в области частотного словаря полного собрания сочинений.
6. Несколько формальных выкладок в качестве заключения.
В нашей стране проживает примерно 60 тысяч Ивановых Иванов Ивановичей. Принимая, что где-то гипотетически в средней базе данных хранится 100 таблиц, в каждой таблице по 10 ключевых полей, а каждый ключ может принимать по 60 тысяч значений, получаем, что суммарное количество уникальных состояний ключей внутри базы данных примерно 60 миллионов. Если даже в одной таблице перепутаются два ключа, то они могут породить до 20 уникальных состояний в одной таблице. Всего в базе уникальных состояний может набежать до нескольких тысяч. Согласитесь, что тратить 10% времени разработки и 5-7% времени исполнения ETL для вылавливания таких мелочей — непозволительная роскошь?
UPD1 Если вам в вашей работе надоедает таскать систему контроля за каждым более-менее важным справочником, то на помощь вам придут системы MDM (Master Data Management). Разумеется, мы поставляем такие системы на рынок, в том числе есть версия на свободно-распространяемом программном обеспечении.
UPD2 Очень часто на конференциях задается вопрос: «Как подешевле создать систему управления качеством данных». Прошу считать эту статью небольшим введением в этот вопрос, с некоторым упрощением функциональности EDQ. Да, и еще, можно взять связку ODI + EDQ и сделать совсем хорошо, но это — предмет дальнейшего повествования.

