"Какого дьявола я должен помнить наизусть все эти чёртовы алгоритмы и структуры данных?".
Примерно к этому сводятся комментарии большинства статей про прохождение технических интервью. Основной тезис, как правило, заключается в том, что всё так или иначе используемое уже реализовано по десять раз и с наибольшей долей вероятности заниматься этим рядовому программисту вряд ли придётся. Что ж, в какой-то мере это верно. Но, как оказалось, реализовано не всё, и мне, к сожалению (или к счастью?) создавать Структуру Данных всё-таки пришлось.
Загадочное Modified Merkle Patricia Trie.
Так как на хабре информации об этом дереве нет вообще, а на медиуме — немногим больше, хочу поведать о том, что же это за зверь, и с чем его едят.

Что это?
Disclaimer: основным источником информации при реализации для меня являлись Yellow paper, а также исходные коды parity-ethereum и go-ethereum. Теоретической информации по поводу обоснования тех или иных решений было минимум, поэтому все выводы по поводу причин принятия тех или иных решений — мои личные. В случае, если я в чем-то заблуждаюсь — буду рад исправлениям в комментариях.
Дерево — структура данных, представляющая собой связный ациклический граф. Тут всё просто, все с этим знакомы.
Префиксное дерево — корневое дерево, в котором можно хранить пары ключ-значение за счёт того, что узлы делятся на два типа: те, что содержат часть пути (префикс), и конечные узлы, которые содержат хранимое значение. Значение присутствует в дереве тогда и только тогда, когда мы, используя ключ, можем пройти от корня дерева весь путь и в конце найти узел со значением.
PATRICIA-дерево — это префиксное дерево, в котором префиксы бинарны — то есть, каждый узел-ключ хранит информацию об одном бите.
Дерево Мёркла — это дерево хешей, построенное над какой-то цепочкой данных, агрегирующее эти самые хеши в один (корневой), хранящий информацию о состоянии всех блоков данных. То есть, корневой хеш — это эдакая "цифровая подпись" состояния цепи блоков. Используется эта штука активно в блокчейне, и подробнее про неё можно почитать тут.

Итого: Modified Merkle Patricia Trie (далее MPT для краткости) — это дерево хешей, хранящее пары ключ-значение, при этом ключи представлены в бинарном виде. А в чем именно заключается "Modified" мы узнаем чуть позже, когда будем обсуждать реализацию.
Зачем это?
MPT используется в проекте Ethereum для хранения данных об аккаунтах, транзакциях, результатах их выполнения и прочих данных, необходимых для функционирования системы.
В отличие от Bitcoin, в котором состояние неявно и вычисляется каждым узлом самостоятельно, в эфире баланс каждого аккаунта (а также ассоциированные с ним данные) хранятся непосредственно в блокчейне. Более того, нахождение и неизменность данных должны быть обеспечены криптографически — мало кто станет пользоваться криптовалютой, в которой баланс случайного аккаунта может измениться без объективных на то причин.
Основной проблемой, с которой столкнулись разработчики Ethereum — это создание структуры данных, которая позволяет эффективно хранить пары ключ-значение и при этом обеспечивать верификацию хранимых данных. Так и появилось MPT.
Как это?
MPT является префиксным PATRICIA-деревом, в котором ключами являются последовательности байтов.
Ребрами в данном дереве являются последовательности нибблов (половинок байтов). Соответственно, у одного узла может быть до шестнадцати потомков (соответствующих веткам от 0x0 до 0xF).
Узлы делятся на 3 вида:
- Branch node. Узел, используемый для ветвления. Содержит до от 1 до 16 ссылок на дочерние узлы. Также может содержать значение.
- Extension node. Вспомогательный узел, который хранит какую-то часть пути, общую для нескольких дочерних узлов, а также ссылку на branch node, лежащий далее.
- Leaf node. Узел, содержащий часть пути и хранимое значение. Является конечным в цепочке.
Как уже было упомянуто, MPT строится поверх другого kv-хранилища, в котором хранятся узлы в виде "ссылка" => "RLP-закодированный узел".
И тут мы встречаемся с новым понятием: RLP. Если коротко — то это метод кодирования данных, представляющих собой списки или байтовые последовательности. Пример: [ "cat", "dog" ] = [ 0xc8, 0x83, 'c', 'a', 't', 0x83, 'd', 'o', 'g' ]. Вдаваться в подробности я особо не буду, и в реализации для этого использую готовую библиотеку, поскольку освещение еще и данной темы слишком раздует и без того немаленькую статью. Если же вам всё же интересно, более подробно вы можете почитать тут. Мы же ограничимся тем, что мы можем закодировать данные в RLP и раскодировать их обратно.
Ссылка на узел же определяется следующим образом: в случае, если длина RLP-закодированного узла составляет 32 или более байт, то ссылкой является keccak-хеш от RLP-представления узла. Если же длина меньше 32 байт, то ссылкой является само RLP-представление узла.
Очевидно, что во втором случае сохранять узел в базу данных не нужно, т.к. он целиком будет сохранен внутри родительского узла.
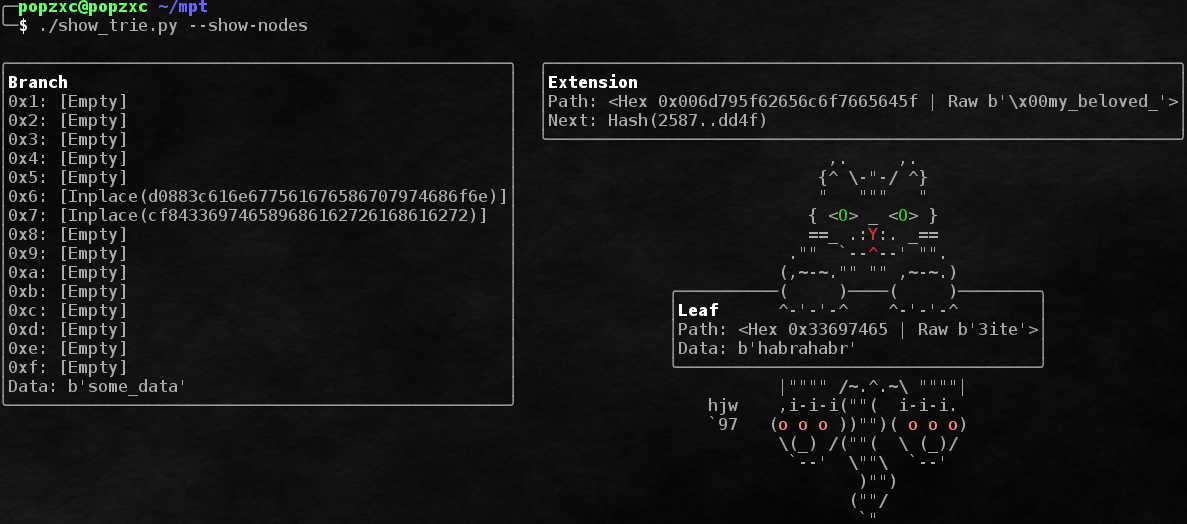
Комбинация трёх видов узлов позволяет эффективно хранить данные и в случае, когда ключей мало (тогда большая часть путей будет храниться в extension и leaf нодах, а branch-узлов будет мало), и в случае, когда узлов много (пути не будут храниться явно, а будут "собираться" во время прохода по branch нодам).
Полный пример дерева, использущего все виды узлов:
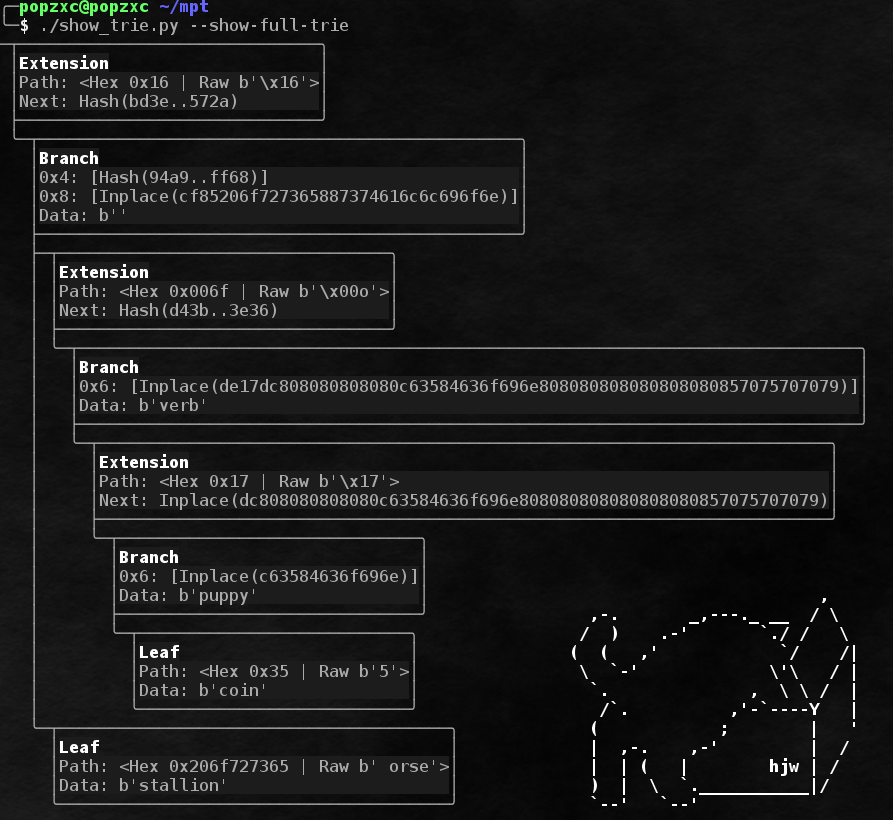
Как вы могли заметить, хранимые части путей имеют префиксы. Префиксы нужны для нескольких целей:
- Чтобы отличать extension-узлы от leaf-узлов.
- Чтобы выравнивать последовательности, состоящие из нечетного количества нибблов.
Правила создания префиксов очень просты:
- Префикс занимает 1 ниббл. Если длина пути (без учета префикса) нечетная, то путь начинается сразу же после префикса. Если длина пути четная — для выравнивания после префикса сперва добавляется ниббл 0x0.
- Префикс изначально равен 0x0.
- Если длина пути нечетная, то к префиксу добавляется 0x1, если четная — 0x0.
- Если путь ведет к Leaf-узлу, то к префиксу добавляется 0x2, если к Extension узлу — 0x0.
На битиках, думаю, будет понятнее:
0b0000 => четная длина, Extension узел 0b0001 => нечетная длина, Extension узел 0b0010 => четная длина, Leaf узел 0b0011 => нечетная длина, Leaf узел
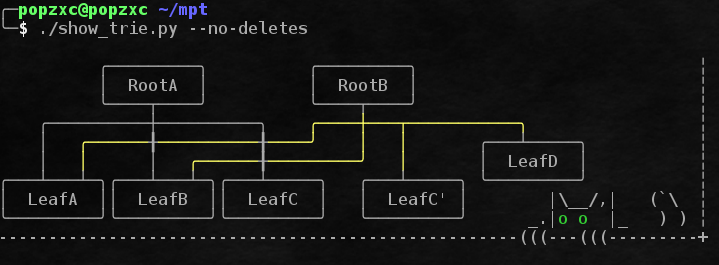
Удаление, которое не удаление
Несмотря на то, что дерево имеет операцию удаления узлов, на самом деле всё, что однажды было добавлено, остается в дереве навсегда.
Нужно это для того, чтобы не создавать полное дерево для каждого блока, а хранить только разницу между старой и новой версией дерева.
Соответственно, используя разные root-хеши в качестве точки входа, мы сможем получить любое из состояний, в котором когда-либо пребывало дерево.
Это не все оптимизации. Там есть ещё, но об этом не будем — и так статья большая. Впрочем, можете почитать сами.
Реализация
С теорией покончено, переходим к практике. Использовать будем лингва франка от мира IT, то бишь python.
Так как кода будет много, и для формата статьи многое придется сокращать и разделять, сразу же оставлю ссылку на github.
В случае необходимости, там можно посмотреть на картину целиком.
Для начала определим интерфейс дерева, который мы хотим получить в итоге:
class MerklePatriciaTrie: def __init__(self, storage, root=None): pass def root(self): pass def get(self, encoded_key): pass def update(self, encoded_key, encoded_value): pass def delete(self, encoded_key): pass
Интерфейс предельно прост. Доступные операции — получение, удаление, вставка и измененение (объединенные в update), а также получение корневого хеша.
В метод __init__ будет передаваться хранилище — dict-like структура данных, в которой мы будем хранить узлы, а также root — "вершина" дерева. В случае, если в качестве root передан None — считаем, что дерево пустое и работаем с нуля.
_Ремарка: возможно, вам интересно, почему переменные в методах названы как encoded_key и encoded_value, а не просто key/value. Ответ прост: по спецификации все ключи и значения должны быть закодированы в RLP. Мы же этим себя утруждать не будем и оставим сие занятие на плечи пользователей библиотеки._
Однако, прежде чем мы приступим к реализации самого дерева, необходимо сделать две важных вещи:
- Реализовать класс
NibblePath, представляющий собой цепочки нибблов, чтобы не кодировать их вручную. - Реализовать класс
Nodeи в рамках данного класса —Extension,LeafиBranch.
NibblePath
Итак, NibblePath. Так как по дереву мы будем активно передвигаться, основой функциональности нашего класса должна быть возможность задавать "смещение" от начала пути, а также получать конкретный ниббл. Зная это, определим основу нашего класса (а также пару полезных констант для работы с префиксами далее):
class NibblePath: ODD_FLAG = 0x10 LEAF_FLAG = 0x20 def __init__(self, data, offset=0): self._data = data # Данные, по которым итерируемся. self._offset = offset # Насколько мы сдвинулись от начала def consume(self, amount): # "Поглощение" N нибблов можно реализовать через увеличение смещения. self._offset += amount return self def at(self, idx): # Определяем индекс нужного нам ниббла idx = idx + self._offset # Зная номер нужного ниббла, рассчитываем номер байта, в котором он лежит, # а также определяем, нужный нам ниббл - первый или второй в этом байте. byte_idx = idx // 2 nibble_idx = idx % 2 # Берем нужный байт. byte = self._data[byte_idx] # Берем нужный ниббл в этом байте. nibble = byte >> 4 if nibble_idx == 0 else byte & 0x0F return nibble
Всё довольно просто, не так ли?
Осталось написать только функции для кодирования и декодирования последовательности нибблов.
class NibblePath: # ... def decode_with_type(data): # Смотрим на флаги: # определяем, четное или нечетное количество нибблов, а также тип узла. is_odd_len = data[0] & NibblePath.ODD_FLAG == NibblePath.ODD_FLAG is_leaf = data[0] & NibblePath.LEAF_FLAG == NibblePath.LEAF_FLAG # Если количество нибблов четное, то за нибблом префикса # идёт пустой ниббл выравнивания. offset укажет нам, # сколько нибблов нужно пропустить до начала "актуальных" данных. offset = 1 if is_odd_len else 2 return NibblePath(data, offset), is_leaf def encode(self, is_leaf): output = [] # Для начала нужно определить, четное или нечетное количество у нас нибблов. nibbles_len = len(self._data) * 2 - self._offset is_odd = nibbles_len % 2 == 1 # Определяем префикс. prefix = 0x00 # Если количество нибблов нечетное, то выравнивание не нужно. # Сразу же берем первый ниббл (self.at(0)) и добавляем к байту префикса. # В противном случае за нибблом префикса должен быть пустой ниббл (0x0). prefix += self.ODD_FLAG + self.at(0) if is_odd else 0x00 # Устанавливаем флаг, обозначающий Leaf node, если нужно. prefix += self.LEAF_FLAG if is_leaf else 0x00 output.append(prefix) # Определяем, добавили ли мы уже один ниббл, или нет. pos = nibbles_len % 2 # К этому моменту количество нибблов уже выравнено и кратно двум, # поэтому просто берем по 2 ниббла, формируем из них байт, # и добавляем к закодированной последовательности, # пока путь не кончится. while pos < nibbles_len: byte = self.at(pos) * 16 + self.at(pos + 1) output.append(byte) pos += 2 return bytes(output)
В принципе, это минимум, необходимый для удобной работы с нибблами. Разумеется, в настоящей реализации есть еще некоторое количество вспомогательных методов (таких как combine, сливающий два пути в один), но их реализация весьма тривиальна. Если интересно — полную версию можно найти тут.
Node
Как мы уже знаем, узлы у нас делятся на три вида: Leaf, Extension и Branch. Все они могут быть закодированы и декодированы, а единственное отличие — данные, которые хранятся внутри. Если честно, тут так и просятся алгебраические типы данных, и на Rust, например, я бы написал что-то в духе:
pub enum Node<'a> { Leaf(NibblesSlice<'a>, &'a [u8]), Extension(NibblesSlice<'a>, NodeReference), Branch([Option<NodeReference>; 16], Option<&'a [u8]>), }
Однако, в питоне как таковых АТД нет, поэтому мы определим класс Node, а внутри него — три класса, соответствующие типам узлов. Кодирование реализуем непосредственно в классах узлов, а декодирование — в классе Node.
Реализация, тем не менее, элементарна:
Leaf:
class Leaf: def __init__(self, path, data): self.path = path self.data = data def encode(self): # Закодированная версия узла -- список из двух элементов, # где первый - путь нибблов, а второй - хранимые данные. return rlp.encode([self.path.encode(True), self.data])
Extension:
class Extension: def __init__(self, path, next_ref): self.path = path self.next_ref = next_ref def encode(self): # Закодированная версия узла -- список из двух элементов, # где первый - путь нибблов, а второй - ссылка на следующий узел. next_ref = _prepare_reference_for_encoding(self.next_ref) return rlp.encode([self.path.encode(False), next_ref])
Branch:
class Branch: def __init__(self, branches, data=None): self.branches = branches self.data = data def encode(self): # Закодированная версия узла -- список из семнадцати элементов, где # первые 16 - ссылки на дочерние узлы (некоторые могут отсутствовать), # а семнадцатый - хранимые данные (также могут отсутствовать). branches = list(map(_prepare_reference_for_encoding, self.branches)) return rlp.encode(branches + [self.data])
Всё очень просто. Единственное, что может вызвать вопросы — функция _prepare_reference_for_encoding.
Тут каюсь, пришлось использовать небольшой костыль. Дело в том, что используемая библиотека rlp декодирует данные рекурсивно, а ссылка на другой узел, как мы знаем, может быть rlp-данными (в случае, если длина закодированного узла менее 32 символов). Работать с ссылками в двух форматах — байты хеша и декодированная нода — весьма неудобно. Поэтому я написал две функции, которые после расшифровки узла возвращают ссылки в формат байтов, а перед сохранением, если нужно, декодируют их. Вот эти функции:
def _prepare_reference_for_encoding(ref): # Если ссылка короткая (то есть, не является хешом) -- раскодируем её. # Перед сохранением она будет закодирована обратно :) if 0 < len(ref) < 32: return rlp.decode(ref) return ref def _prepare_reference_for_usage(ref): # Если ссылка была раскодирована - кодируем её обратно. # В результате вне зависимости от типа ссылки работаем с байтиками. if isinstance(ref, list): return rlp.encode(ref) return ref
Закончим с узлами, написав класс Node. В нём будет всего 2 метода: раскодировать узел и превратить узел в ссылку.
class Node: # class Leaf(...) # class Extension(...) # class Branch(...) def decode(encoded_data): data = rlp.decode(encoded_data) # 17 элементов - гарантированно Branch узел. if len(data) == 17: branches = list(map(_prepare_reference_for_usage, data[:16])) node_data = data[16] return Node.Branch(branches, node_data) # Если узлов не 17, значит их 2. И первый - путь. # Декодируем его и смотрим на то, что же это за узел. path, is_leaf = NibblePath.decode_with_type(data[0]) if is_leaf: return Node.Leaf(path, data[1]) else: ref = _prepare_reference_for_usage(data[1]) return Node.Extension(path, ref) def into_reference(node): # Превращаем узел в ссылку. # Если длина закодированного узла меньше 32 байтов, # то ссылка - сам закодированный узел. # В противном случае считаем хеш от данных. encoded_node = node.encode() if len(encoded_node) < 32: return encoded_node else: return keccak_hash(encoded_node)
Перерыв
Фух! Информации получается много. Думаю, самое время отдохнуть. Вот вам ещё один котик:

Милота, правда? Ладно, вернемся к нашим деревьям.
MerklePatriciaTrie
Ура — вспомогательные элементы готовы, переходим к самому вкусному. На всякий случай напомню интерфейс нашего дерева. Заодно реализуем метод __init__.
class MerklePatriciaTrie: def __init__(self, storage, root=None): self._storage = storage self._root = root def root(self): pass def get(self, encoded_key): pass def update(self, encoded_key, encoded_value): pass def delete(self, encoded_key): pass
А вот с оставшимися методами будем разбираться по одному.
get
Метод get (как, в принципе, и остальные методы) будут у нас состоять из двух частей. Сам метод будет производить подготовку данных и приведение результата к ожидаемой форме, тогда как настоящая работа будет происходить внутри вспомогательного метода.
Основной метод чрезвычайно прост:
class MerklePatriciaTrie: # ... def get(self, encoded_key): if not self._root: raise KeyError path = NibblePath(encoded_key) # Вспомогательному методу нужно передать ссылку на # корневой узел, а так же путь, по которому нужно пройти. result_node = self._get(self._root, path) if type(result_node) is Node.Extension or len(result_node.data) == 0: raise KeyError return result_node.data
Впрочем, _get не сильно сложнее: для того, чтобы добраться до искомого узла, нам нужно пройти от корня весь предоставленный путь. Если в конце мы обнаружили узел с данными (Leaf или Branch) — ура, данные получены. Если же пройти не удалось — то искомый ключ отсутствует в дереве.
Реализация:
class MerklePatriciaTrie: # ... def _get(self, node_ref, path): # Получаем ноду по ссылке из хранилища. node = self._get_node(node_ref) # Если путь пустой -- наше приключение закончено. # Родительский метод проверит, есть ли в этой ноде данные. if len(path) == 0: return node if type(node) is Node.Leaf: # Если мы дошли до Leaf-узла, то либо это наш узел, # либо нужный ключ отсутсвует в дереве. if node.path == path: return node elif type(node) is Node.Extension: # Если текущий узел -- Extension, нам нужно спускаться дальше. if path.starts_with(node.path): rest_path = path.consume(len(node.path)) return self._get(node.next_ref, rest_path) elif type(node) is Node.Branch: # Если текущий узел -- Branch, просто идём в соответствующую ветку. # Заботиться о том, что путь окончен и нам нужны данные из этого узла # не нужно: это уже проверено в начале метода. branch = node.branches[path.at(0)] if len(branch) > 0: return self._get(branch, path.consume(1)) # Если мы оказались тут, значит ни один из приемлемых вариантов не сработал, # и ключ в дереве отсутствует. raise KeyError
Ну и заодно напишем методы для сохранения и загрузки узлов. Они простые:
class MerklePatriciaTrie: # ... def _get_node(self, node_ref): raw_node = None if len(node_ref) == 32: raw_node = self._storage[node_ref] else: raw_node = node_ref return Node.decode(raw_node) def _store_node(self, node): reference = Node.into_reference(node) if len(reference) == 32: self._storage[reference] = node.encode() return reference
update
Метод update уже интереснее. Просто пройти до конца и вставить Leaf-узел получится далеко не всегда. Вполне вероятна ситуация, что точка разделения ключей будет находиться где-то внутри уже сохраненного Leaf или Extension узла. В таком случае придется их разделить и создать несколько новых узлов.
В целом, всю логику можно описать следующими правилами:
- Пока путь целиком совпадает с уже имеющимися узлами, рекурсивно спускаемся по дереву.
- Если путь окончен и мы находимся в Branch или Leaf узле — значит,
updateпросто обновляет значение, соответствующее данному ключу. - Если пути разделились (то есть, мы не обновляем значение, а вставляем новое), и мы находимся в Branch-узле — создаем Leaf-узел и указываем ссылку на него в соответствующей ветке Branch-узла.
- Если пути разделились и мы находися в Leaf или Extension узле — нам нужно создать Branch узел, разделяющий пути, а также, если необходимо — Extension узел для общей части пути.
Давайте постепенно выражать это в коде. Почему постепенно? Потому что метод большой и скопом его понять будет тяжеловато.
Впрочем, ссылку на полный метод я оставлю тут.
class MerklePatriciaTrie: # ... def update(self, encoded_key, encoded_value): path = NibblePath(encoded_key) result = self._update(self._root, path, encoded_value) self._root = result def _update(self, node_ref, path, value): # Если ссылка на узел не предоставлена (например, дерево пока пустое), # значит нам нужно просто создать новый узел. if not node_ref: return self._store_node(Node.Leaf(path, value)) # В противном случае мы смотрим на тип текущего узла # и ориентируемся по ситуации. node = self._get_node(node_ref) if type(node) == Node.Leaf: ... elif type(node) == Node.Extension: ... elif type(node) == Node.Branch: ...
Общей логики довольно мало, все самое интересное находится внутри ifов.
if type(node) == Node.Leaf
Сперва разберемся с Leaf узлами. С ними возможны всего 2 сценария:
Остаток пути, по которому мы идём, полностью совпадает с путём, хранящимся в Leaf-узле. В таком случае нам нужно просто поменять значение, сохранить новый узел и вернуть ссылку на него.
Пути отличаются.
В таком случае нужно создать Branch узел, который разделит эти два пути.
Если один из путей пуст — то его значение перекочует непосредственно в Branch-узел.
В противном случае, нам придется создать два Leaf-узла, укороченных на длину общей части путей + 1 ниббл (этот ниббл будет обозначен индексом соответствующей ветки Branch-ноды).
Также нужно будет проверить, есть ли общая часть пути, чтобы понять, нужно ли нам создавать ещё и Extension-узел.
В коде это будет выглядеть так:
if type(node) == Node.Leaf: if node.path == path: # Пути совпадают. Просто обновляем значение и сохраняем новый узел. node.data = value return self._store_node(node) # Нам нужно разделить узлы. # Ищем общую часть путей. common_prefix = path.common_prefix(node.path) # Обрезаем общую часть от обоих путей. path.consume(len(common_prefix)) node.path.consume(len(common_prefix)) # Создаем Branch узел. branch_reference = self._create_branch_node(path, value, node.path, node.data) # Проверяем, нужен ли нам Extension-узел. if len(common_prefix) != 0: return self._store_node(Node.Extension(common_prefix, branch_reference)) else: return branch_reference
Процедура _create_branch_node выглядит следующим образом:
def _create_branch_node(self, path_a, value_a, path_b, value_b): # Создаем ветки для Branch-узла. branches = [b''] * 16 # Определяем, будут ли в нашем Branch-узле данные. branch_value = b'' if len(path_a) == 0: branch_value = value_a elif len(path_b) == 0: branch_value = value_b # Создаем внутри веток Leaf-узлы, если необходимо. self._create_branch_leaf(path_a, value_a, branches) self._create_branch_leaf(path_b, value_b, branches) # Сохраняем Branch-узел и возвращаем на него ссылку. return self._store_node(Node.Branch(branches, branch_value)) def _create_branch_leaf(self, path, value, branches): # Смотрим, нужен ли нам вообще Leaf-узел. if len(path) > 0: # Берем первый ниббл (индекс ветки). idx = path.at(0) # Создаем Leaf-узел с остатком пути, кладем его в соответствующую ветку. leaf_ref = self._store_node(Node.Leaf(path.consume(1), value)) branches[idx] = leaf_ref
if type(node) == Node.Extension
В случае с Extension-узлом всё похоже на Leaf-узел.
Если путь из Extension-узла является префиксом для нашего пути — просто рекурсивно движемся дальше.
В противном случае нам нужно сделать разделение с использованием Branch-узла, как и в вышеописанном случае.
Соответственно, код:
elif type(node) == Node.Extension: if path.starts_with(node.path): # Просто движемся дальше и обновляем ссылку в текущем узле. new_reference = \ self._update(node.next_ref, path.consume(len(node.path)), value) return self._store_node(Node.Extension(node.path, new_reference)) # Разделяем Extension-узел. # Находим общую часть для путей. common_prefix = path.common_prefix(node.path) # Делаем обрезание. path.consume(len(common_prefix)) node.path.consume(len(common_prefix)) # Создаем Branch-узел и, если нужно, добавляем в него значение. branches = [b''] * 16 branch_value = value if len(path) == 0 else b'' # По необходимости создаем дочерние Leaf- и Extension- узлы. self._create_branch_leaf(path, value, branches) self._create_branch_extension(node.path, node.next_ref, branches) branch_reference = self._store_node(Node.Branch(branches, branch_value)) # Проверяем, нужен ли нам Extension-узел. if len(common_prefix) != 0: return self._store_node(Node.Extension(common_prefix, branch_reference)) else: return branch_reference
Процедура _create_branch_extension логически эквивалентна процедуре _create_branch_leaf, но работает с Extension-узлом.
if type(node) == Node.Branch
А вот с Branch-узлом всё просто. Если путь пустой — мы просто сохраняем в текущем Branch-узле новое значение. Если же путь не пустой — "откусываем" от него один ниббл и рекурсивно идём ниже.
Код, думаю, в комментариях не нуждается.
elif type(node) == Node.Branch: if len(path) == 0: return self._store_node(Node.Branch(node.branches, value)) idx = path.at(0) new_reference = self._update(node.branches[idx], path.consume(1), value) node.branches[idx] = new_reference return self._store_node(node)
delete
Фух! Остался последний метод. Он же — самый веселый. Сложность удаления заключается в том, что нам необходимо вернуть структуру в то состояние, в которое она попала бы, если бы мы проделали всю цепочку update-ов, исключив только удаляемый ключ.
Это крайне важно, так как в противном случае возможна ситуация, в которой для двух деревьев, содержащих одни и те же данные, будет отличаться корневой хеш. А такая "особенность", как вы понимаете, перечеркнет весь смысл данной структуры данных.
Данное требование порождает довольно большое количество возможных сценариев действий. Более того, функция на N-ном уровне вложенности после непосредственно удаления должна будет знать, что произошло на N+1 уровне. Для этого мы введем дополнительный enum — DeleteAction, который будем возвращать наверх.
Выглядить остов метода delete будет следующим образом:
class MerklePatriciaTrie: # ... # Enum, показывающий, что за действие было произведено на предыдущем шаге удаления. class _DeleteAction(Enum): # Узел был полностью удален. # Когда мы возвращаем данный вариант, # возвращаемым типом будет кортеж из двух элементов (_DeleteAction, None). DELETED = 1, # Узел был изменен (например, в нем поменялась ссылка). # Когда мы возвращаем данный вариант, возвращаемым типом будет # кортеж из двух элементов: (_DeleteAction, ссылка_на_новый_узел). UPDATED = 2, # На предыдущем шаге Branch-узел стал бесполезным. Возвращаемый тип -- # кортеж из двух элементов: # (_DeleteAction, (путь_до_следующего_узла, ссылка_на_новый_узел)) USELESS_BRANCH = 3 def delete(self, encoded_key): if self._root is None: return path = NibblePath(encoded_key) action, info = self._delete(self._root, path) if action == MerklePatriciaTrie._DeleteAction.DELETED: # Дерево стало пустым. self._root = None elif action == MerklePatriciaTrie._DeleteAction.UPDATED: # Поменялся корневой узел. new_root = info self._root = new_root elif action == MerklePatriciaTrie._DeleteAction.USELESS_BRANCH: # Поменялся корневой узел. _, new_root = info self._root = new_root def _delete(self, node_ref, path): node = self._get_node(node_ref) if type(node) == Node.Leaf: pass elif type(node) == Node.Extension: pass elif type(node) == Node.Branch: pass
В целом выглядит похоже на то, что мы видели в методах get и update. Разбираться также будем по частям. Ссылка на полный метод вот.
if type(node) == Node.Leaf
Самая простая часть. Мы добрались до конечного узла. И либо это искомый узел — и мы его просто удалим, либо это не тот узел, который мы ищем.
Код элементарен:
if type(node) == Node.Leaf: if path == node.path: return MerklePatriciaTrie._DeleteAction.DELETED, None else: raise KeyError
На всякий случай напомню, что "удаление" — не совсем настоящее удаление. Старые узлы остаются в хранилище и доступны, если создать дерево от старого корня. А вот в дереве от нового корня мы этот узел уже найти не сможем.
if type(node) == Node.Extension
C Extension-узлом программа действий следующая:
- Сперва проверяем, является ли сохраненный в Extension-узле путь префиксом для пути удаляемого узла. Если нет — ключ отсутствует в дереве.
- Рекурсивно вызываем
_delete, "откусив" нужную часть пути. - Смотрим на произошедшее действие. Возможные варианты:
- Следующий узел был удален. Тогда со спокойной совестью удаляем также и текущий узел.
- Следующий узел был обновлен. Тогда мы просто меняем сохраненную ссылку.
- Следующий узел был ставшим ненужным Branch-узлом. В таком случае мы должны создать вспомогательный узел вместо текущего. Тип нового узла зависит от того, почему Branch-узел стал не нужен. Если в нём не осталось веток, но было значение, то мы создаем Leaf-узел. В противном случае — мы создаем Extension-узел.
В коде это выглядит так:
elif type(node) == Node.Extension: if not path.starts_with(node.path): raise KeyError # Рекурсивно продолжаем удаление. # Получаем тип действия и соответствующую ему информацию. action, info = self._delete(node.next_ref, path.consume(len(node.path))) if action == MerklePatriciaTrie._DeleteAction.DELETED: return action, None elif action == MerklePatriciaTrie._DeleteAction.UPDATED: # Берем из информации ссылку, которую мы теперь должны хранить. child_ref = info new_ref = self._store_node(Node.Extension(node.path, child_ref)) return action, new_ref elif action == MerklePatriciaTrie._DeleteAction.USELESS_BRANCH: # Берем информацию об удаленном Branch-узле. stored_path, stored_ref = info # Смотрим, что же хранил этот Branch-узел. child = self._get_node(stored_ref) new_node = None if type(child) == Node.Leaf: # В branch-узле были данные. # Объединяем пути и создаем Leaf-узел вместо Extension. path = NibblePath.combine(node.path, child.path) new_node = Node.Leaf(path, child.data) elif type(child) == Node.Extension: # В Branch-узле хранился Extension-узел. # Просто объединяем эти два пути в один. path = NibblePath.combine(node.path, child.path) new_node = Node.Extension(path, child.next_ref) elif type(child) == Node.Branch: # В Branch-узле была ссылка на ещё один Branch-узел. # Добавляем к нашему Extension-узлу ниббл и обновляем ссылку. path = NibblePath.combine(node.path, stored_path) new_node = Node.Extension(path, stored_ref) new_reference = self._store_node(new_node) return MerklePatriciaTrie._DeleteAction.UPDATED, new_reference
if type(node) == Node.Branch
Вот и конец.
Ну, почти. Если мы удаляем Branch-узел, то вещи становятся несколько запутанными…
Почему? Потому что Branch-узел одновременно может выступать в роли Leaf-узла (хранить значение) и в роли набора Extension-узлов (хранить ссылки на другие узлы).
Соответственно, в результате удаления данный узел может стать ненужным. Если в нём не останется ссылок, но останется значение — ему на замену придет Leaf-узел. Если в нём нет значения и останется одна ссылка — его нужно будет заменить на Extension-узел. Если же останется хотя бы одна ссылка и значение, либо не будет значения, но ссылок сохранится 2 и более — то Branch-узел будет просто обновлен.
И как нам это распутывать? Давайте разбираться:
Сперва разбираемся с удалением:
- Если путь уже пуст, удаляем хранимое значение.
- Если путь не пуст, вызываем
_deleteдля соответствующей ветки.
В коде это выглядит вот так:
elif type(node) == Node.Branch: action = None idx = None info = None if len(path) == 0 and len(node.data) == 0: raise KeyError elif len(path) == 0 and len(node.data) != 0: node.data = b'' action = MerklePatriciaTrie._DeleteAction.DELETED else: # Сохраняем индекс ветки, с которой мы работаем. # Он нам понадобится позже. idx = path.at(0) if len(node.branches[idx]) == 0: raise KeyError action, info = self._delete(node.branches[idx], path.consume(1)) # Обозначаем ветку, с которой работали, как пустую. # Если действием окажется не удаление - на это место # будет добавлена обновленная ссылка. node.branches[idx] = b''
В результате мы имеем _DeleteAction и можем начать разбираться с текущим узлом.
- Если произошло обновление узла или нижележащий Branch-узел стал ненужным, наш узел гарантированно остается нужным (не было ни удаления значения, ни удаления веток). В таком случае нам нужно просто обновлить ссылку в ветке по индексу.
if action == MerklePatriciaTrie._DeleteAction.UPDATED: # Просто обновляем ссылку. next_ref = info node.branches[idx] = next_ref reference = self._store_node(node) return MerklePatriciaTrie._DeleteAction.UPDATED, reference elif action == MerklePatriciaTrie._DeleteAction.USELESS_BRANCH: # Также просто обновляем ссылку. _, next_ref = info node.branches[idx] = next_ref reference = self._store_node(node) return MerklePatriciaTrie._DeleteAction.UPDATED, reference
- Если же произошло удаление (либо данных, либо ветки), нам необходимо проверить, не стал ли наш узел ненужным.
Для этого подсчитаем количество непустых веток. Возможные варианты:
- Нет ни одной ветки и нет данных. Если честно, я не думаю, что такой вариант возможен, но будем обрабатывать его на всякий случай. Защитное программирование, все дела.
- Все ветки пустые, но есть данные. Нужно создать Leaf-узел с этими данными. Обработают его выше по стеку вызовов.
- Данных нет, осталась одна ветка. Нужно создать новый узел, исходя из того, что именно хранится в этой ветке.
- Если вышеописанное неверно, значит, наш Branch-узел по прежнему нужен. Сохраняем его и говорим, что
_DeleteAction—UPDATED.
if action == MerklePatriciaTrie._DeleteAction.DELETED: non_empty_count = sum(map(lambda x: 1 if len(x) > 0 else 0, node.branches)) if non_empty_count == 0 and len(node.data) == 0: # Branch-узел пуст, удаляем его. return MerklePatriciaTrie._DeleteAction.DELETED, None elif non_empty_count == 0 and len(node.data) != 0: # Нет веток, есть только значение. path = NibblePath([]) reference = self._store_node(Node.Leaf(path, node.data)) return MerklePatriciaTrie._DeleteAction.USELESS_BRANCH, (path, reference) elif non_empty_count == 1 and len(node.data) == 0: # Нет значения, только одна ветка. return self._build_new_node_from_last_branch(node.branches) else: # Есть 1+ ветка и значение, либо 2+ ветки. # Branch-узел не бесполезен, поэтому действие - UPDATED. reference = self._store_node(node) return MerklePatriciaTrie._DeleteAction.UPDATED, reference
Метод _build_new_node_from_last_branch находит ту самую единственную ветку и создает из неё новый узел.
Если нижележащий узел — Leaf или Extension, то нам нужно добавить в начало хранимого в них пути ниббл, соотвтетствующий индексу ветки.
Если же нижележащий узел — Branch, то нам нужно создать дополнительный Extension узел, путь в котором будет состоять из одного ниббла, а ссылка будет вести на Branch.
def _build_new_node_from_last_branch(self, branches): # Ищем индекс последней ветки. idx = 0 for i in range(len(branches)): if len(branches[i]) > 0: idx = i break # Создаем из этого ниббла путь. prefix_nibble = NibblePath([idx], offset=1) # Смотрим на нижележащий узел child = self._get_node(branches[idx]) path = None node = None # Создаем новый узел. if type(child) == Node.Leaf: path = NibblePath.combine(prefix_nibble, child.path) node = Node.Leaf(path, child.data) elif type(child) == Node.Extension: path = NibblePath.combine(prefix_nibble, child.path) node = Node.Extension(path, child.next_ref) elif type(child) == Node.Branch: path = prefix_nibble node = Node.Extension(path, branches[idx]) # Завершаем работу. reference = self._store_node(node) return MerklePatriciaTrie._DeleteAction.USELESS_BRANCH, (path, reference)
Остальное
Наше выстраданное дерево готово к бою. Хотя стоп, нет… Осталось реализовать метод root.
Вот:
class MerklePatriciaTrie: # ... def root(self): return self._root
Это было сложно, но мы справились.
Ах да… Ещё тесты. Но тут, к нашему счастью, за нас всё продумали авторы Ethereum и разместили стандартные тестовые векторы для проверки реализаций тут. Описывать, как их подключить, я, пожалуй не буду. Но созданная нами реализация их проходит, поверьте на слово :)
Теперь, если захотите поиграться с этим чудовищем, вам достаточно сделать pip install -U eth_mpt — и всё.

Результаты
К чему же это всё было?
Ну, во-первых, я не теряю надежды на то, что кто-то тоже будет биться с реализацией этой структуры, и моя статья ему поможет понять, что к чему. Если это произойдет — то ура, всё было не зря и я доволен.
Во-вторых, мне хотелось показать, что ситуации, когда сражаться на доселе неизведанном поле алгоритмов и структур данных приходится — возможны. Не скажу, что это повод мучать кандидатов задачками на skip list и interval tree, но способность их написать — навык, определенно, полезный.
В-третьих, изложение материала полностью соответствует тому, как я сам разбирался с вопросом и писал код в первый раз. Не исключаю вероятности, что это может быть интересно как описание процесса знакомства с чем-то с нуля.
В-четвертых, это же просто увлекательно — изучать нечто новое.
В любом случае, статья окончена, и если вы дочитали до этого момента — спасибо вам за терпение!
Арты
Арты были взяты со следующих сайтов: 1, 2, 3. Спасибо их авторам! А вам рекомендую посмотреть, там еще много красивого.

