

Это десятая подборка советов про Python и программирование из моего авторского канала @pythonetc.
Предыдущие подборки.
0_0
0_0 — полностью корректное выражение на Python.Сортировка списка с None
Сортировка списка с
None-значениями может быть весьма непростой задачей:In [1]: data = [ ...: dict(a=1), ...: None, ...: dict(a=-3), ...: dict(a=2), ...: None, ...: ] In [2]: sorted(data, key=lambda x: x['a']) ... TypeError: 'NoneType' object is not subscriptable
Можно попробовать удалить все None и вернуть их обратно после сортировки (в начало или в конец списка, в зависимости от задачи):
In [3]: sorted( ...: (d for d in data if d is not None), ...: key=lambda x: x['a'] ...: ) + [ ...: d for d in data if d is None ...: ] Out[3]: [{'a': -3}, {'a': 1}, {'a': 2}, None, None]
Но это неудобно. Лучше использовать более сложный
key:In [4]: sorted(data, key=lambda x: float('inf') if x is None else x['a']) Out[4]: [{'a': -3}, {'a': 1}, {'a': 2}, None, None]
Если же речь идёт о типах, для которых бесконечность недопустима, можно сортировать кортежи:
In [5]: sorted(data, key=lambda x: (1, None) if x is None else (0, x['a'])) Out[5]: [{'a': -3}, {'a': 1}, {'a': 2}, None, None]
Вызов random.seed()
Когда вы форкаете процесс, то используемый вами random seed будет копироваться во все получившиеся процессы. В результате в них может генерироваться одинаковый «случайный» результат.
Чтобы этого избежать, нужно в каждом процессе вручную вызывать
random.seed(). Но если воспользуетесь модулем multiprocessing, то он будет делать это за вас.Например:
import multiprocessing import random import os import sys def test(a): print(random.choice(a), end=' ') a = [1, 2, 3, 4, 5] for _ in range(5): test(a) print() for _ in range(5): p = multiprocessing.Process( target=test, args=(a,) ) p.start() p.join() print() for _ in range(5): pid = os.fork() if pid == 0: test(a) sys.exit() else: os.wait() print()
Получите нечто подобное:
4 4 4 5 5 1 4 1 3 3 2 2 2 2 2
Более того, если вы используете Python 3.7 и выше, то благодаря новому хуку
at_fork можете делать то же самое с помощью os.fork.Вышеприведённый код на Python 3.7 даёт такой результат:
1 2 2 1 5 4 4 4 5 5 2 4 1 3 1
Сложение с 0
На первый взгляд кажется, что
sum([a, b, c]) эквивалентно a + b + c, хотя на самом деле эквивалентом будет 0 + a + b + c. Значит это выражение не может работать с типами, которые не поддерживают сложение с 0:class MyInt: def __init__(self, value): self.value = value def __add__(self, other): return type(self)(self.value + other.value) def __radd__(self, other): return self + other def __repr__(self): class_name = type(self).__name__ return f'{class_name}({self.value})' In : sum([MyInt(1), MyInt(2)]) ... AttributeError: 'int' object has no attribute 'value'
Чтобы это исправить, можете предоставлять кастомный начальный элемент, который будет использоваться вместо
0:In : sum([MyInt(1), MyInt(2)], MyInt(0)) Out: MyInt(3)
sum предназначена для сложения float и int-типов, хотя может работать и с любыми другими кастомными типами. Однако он отказывается складывать bytes, bytearray и str, поскольку для этого предназначена join:In : sum(['a', 'b'], '') ... TypeError: sum() can't sum strings [use ''.join(seq) instead] In : ints = [x for x in range(10_000)] In : my_ints = [Int(x) for x in ints] In : %timeit sum(ints) 68.3 µs ± 142 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) In : %timeit sum(my_ints, Int(0)) 5.81 ms ± 20.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)

Завершение индексов в Jupyter Notebook
С помощью метода
_ipython_key_completions_ можно кастомизировать завершения индексов в Jupyter Notebook. Таким образом вы сможете контролировать, что отобразится на экране, если нажать Tab после чего-нибудь вроде d["x: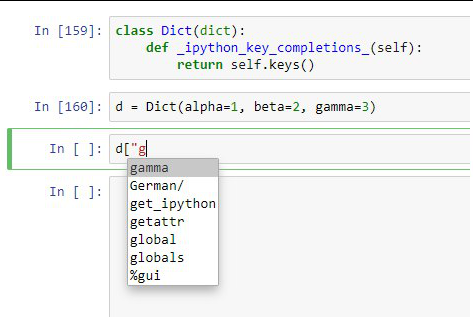
Обратите внимание, что метод не получает искомую строку в качестве аргумента.
