Разбивая крупные числа на мелкие, исследователи превысили фундаментальное математическое ограничение скорости

Четыре тысячи лет назад жители Вавилонии изобрели умножение. А в марте этого года математики усовершенствовали его.
18 марта 2019 два исследователя описали самый быстрый из известных методов перемножения двух очень больших чисел. Работа отмечает кульминацию давнишнего поиска наиболее эффективной процедуры выполнения одной из базовых операций математики.
«Все думают, что метод умножения, который они учили в школе, наилучший, но на самом деле в этой области идут активные исследования», — говорит Йорис ван дер Хувен, математик из Французского национального центра научных исследований, один из соавторов работы.
Сложность множества вычислительных задач, от подсчёта новых цифр числа π до обнаружения крупных простых чисел сводится к скорости перемножения. Ван дер Хувен описывает их результат как назначение своего рода математического ограничения скорости решения множества других задач.
«В физике есть важные константы типа скорости света, позволяющие вам описывать всякие явления, — сказал ван дер Хувен. – Если вы хотите знать, насколько быстро компьютеры могут решать определённые математические задачи, тогда перемножение целых чисел возникает в виде некоего базового строительного блока, по отношению к которому можно выразить такую скорость».
Почти все учатся перемножать числа одинаково. Записываем числа в столбик, перемножаем верхнее число на каждую цифру нижнего (с учётом разрядов) и складываем результат. При перемножении двух двузначных чисел приходится проделать четыре более мелких перемножения для получения итогового результата.
Школьный метод "переноса" требует выполнения n2 шагов, где n – количество цифр в каждом из перемножаемых чисел. Вычисления с трёхзначными числами требуют девяти перемножений, а со стозначными – 10 000.
Метод переноса нормально работает с числами, состоящими из нескольких цифр, однако начинает буксовать при перемножении чисел, состоящих из миллионов или миллиардов цифр (чем и занимаются компьютеры при точном подсчёте π или при всемирном поиске больших простых чисел). Чтобы перемножить два числа с миллиардом цифр, нужно будет произвести миллиард в квадрате, или 1018, умножений, – на это у современного компьютера уйдёт порядка 30 лет.
Несколько тысячелетий считалось, что быстрее перемножать числа нельзя. Затем в 1960 году 23-летний советский и российский математик Анатолий Алексеевич Карацуба посетил семинар, который вёл Андрей Николаевич Колмогоров, советский математик, один из крупнейших математиков XX века. Колмогоров заявил, что не существует обобщённого способа умножения, требующего меньше, чем n2 операций. Карацуба решил, что такой способ есть – и после недели поисков он его обнаружил.

Анатолий Алексеевич Карацуба
Умножение Карацубы заключается в разбиении цифр числа и повторной их комбинации новым способом, который позволяет вместо большого количества умножений провести меньшее количество сложений и вычитаний. Метод экономит время, поскольку на сложения уходит всего 2n шагов вместо n2.

Традиционный метод умножения 25х63 требует четыре умножения на однозначное число и несколько сложений

Умножение Карацубы 25х63 требует трёх умножений на однозначное число и несколько сложений и вычитаний.
a) разбиваем числа
b) перемножаем десятки
c) перемножаем единицы
d) складываем цифры
e) перемножаем эти суммы
f) считаем e – b – c
g) собираем итоговую сумму из b, c и f
При росте количества знаков в числах метод Карацубы можно использовать рекурсивно.

Традиционный метод умножения 2531х1467 требует 16 умножений на однозначное число.
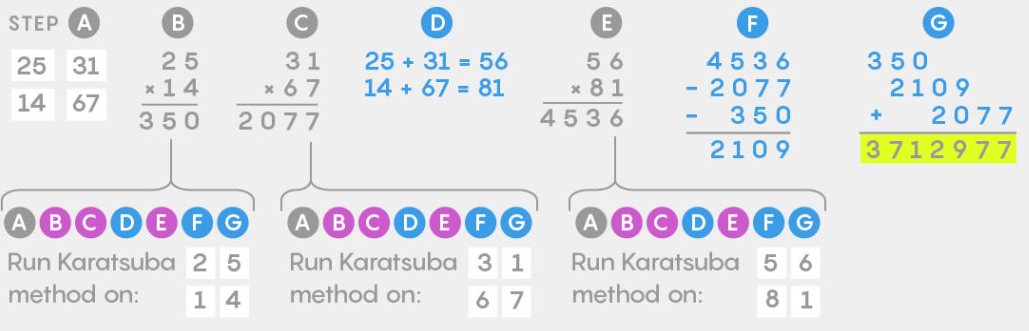
Умножение Карацубы 2531х1467 требует 9 умножений.
«Сложение в школе проходят на год раньше, потому что это гораздо проще, оно выполняется за линейное время, со скоростью чтения цифр слева направо», — сказал Мартин Фюрер, математик из Пенсильванского государственного университета, создавший в 2007 быстрейший на то время алгоритм умножения.
Имея дело с крупными числами, умножение Карацубы можно повторять рекурсивно, разбивая изначальные числа почти на столько частей, сколько в них знаков. И с каждым разбиением вы меняете умножение, требующее выполнения многих шагов, на сложение и вычитание, требующие куда как меньше шагов.
«Несколько умножений можно превратить в сложения, учитывая, что с этим компьютеры будут справляться быстрее», — сказал Дэвид Харви, математик из Университета Нового Южного Уэльса и соавтор новой работы.
Метод Карацубы сделал возможным умножать числа с использованием лишь n1,58 умножений на однозначное число. Затем в 1971 году Арнольд Шёнхаге и Фолькер Штрассен опубликовали метод, позволяющий умножать большие числа за n × log n × log(log n) небольших умножений. Для умножения двух чисел из миллиарда знаков каждое метод Карацубы потребует 165 трлн шагов.

Йорис ван дер Хувен, математик из Французского национального центра научных исследований
Метод Шёнхаге-Штрассена используется компьютерами для умножения больших чисел, и привёл к двум другим важным последствиям. Во-первых, он ввёл в использование технику из области обработки сигналов под названием быстрое преобразование Фурье. С тех пор эта техника была основой всех быстрых алгоритмов умножения.
Во-вторых, в той же работе Шёнхаге и Штрассен предположили возможность существования ещё более быстрого алгоритма – метода, требующего всего n × log n умножений на один знак – и что такой алгоритм будет наибыстрейшим из возможных. Это предположение было основано на ощущении, что у такой фундаментальной операции, как умножение, ограничение операций должно записываться как-то более элегантно, чем n × log n × log(log n).
«Большинство в общем-то сошлось на том, что умножение – это такая важная базовая операция, что с чисто эстетической точки зрения ей требуется красивое ограничение по сложности, — сказал Фюрер. – По опыту мы знаем, что математика базовых вещей в итоге всегда оказывается элегантной».
Нескладное ограничение Шёнхаге и Штрассена, n × log n × log(log n), держалось 36 лет. В 2007 году Фюрер побил этот рекорд, и всё завертелось. За последнее десятилетие математики находили всё более быстрые алгоритмы умножения, каждый из которых постепенно подползал к отметке в n × log n, не совсем достигая её. Затем в марте этого года Харви и ван дер Хувен достигли её.
Их метод является улучшением большой работы, проделанной до них. Он разбивает числа на знаки, использует улучшенную версию быстрого преобразования Фурье и пользуется другими прорывами, сделанными за последние 40 лет. «Мы используем быстрое преобразование Фурье гораздо более грубо, используем его несколько раз, а не один, и заменяем ещё больше умножений сложением и вычитанием», — сказал ван дер Хувен.
Алгоритм Харви и ван дер Хувена доказывает, что умножение можно провести за n × log n шагов. Однако он не доказывает отсутствия более быстрого метода. Гораздо сложнее будет установить, что их подход максимально быстрый. В конце февраля команда специалистов по информатике из Орхусского университета опубликовала работу, где утверждает, что если одна из недоказанных теорем окажется верной, то этот метод и вправду будет скорейшим из способов умножения.
И хотя в теории этот новый алгоритм весьма важен, на практике он мало что поменяет, поскольку лишь немного выигрывает у уже используемых алгоритмов. «Всё, на что мы можем надеяться, это на трёхкратное ускорение, — сказал ван дер Хувен. – Ничего запредельного».
Кроме того, поменялись схемы компьютерного оборудования. Двадцать лет назад компьютеры выполняли сложение гораздо быстрее умножения. Разрыв в скоростях умножения и сложения с тех пор серьёзно уменьшился, в результате чего на некоторых чипах умножение может даже обгонять сложение. Используя определённые виды оборудования, «можно ускорить сложение, заставляя компьютер умножать числа, и это какое-то безумие», — сказал Харви.
Оборудование меняется со временем, но лучшие алгоритмы своего класса вечны. Вне зависимости от того, как компьютеры будут выглядеть в будущем, алгоритм Харви и ван дер Хувена всё ещё будет самым эффективным способом умножать числа.

