Переходим от данных к результатам, не покидая рамки своего компьютера

Стек изображений небольшой зоны в Словении, и карта с классифицированным покровом земли, полученная, используя методы, описанные в статье.
Предисловие
Вторая часть серии статей про классификацию покрова земли, используя библиотеку eo-learn. Напоминаем, что в первой статье было продемонстрировано следующее:
- Разделение AOI (area of interest, зоны интереса) на фрагменты под названием EOPatch
- Получение изображений и облачных масок со спутников Sentinel-2
- Расчёт дополнительной информации, такой как NDWI, NDVI
- Создание референсной маски и добавление её к исходным данным
К тому же, мы провели поверхностное исследование данных, что является крайне важным шагом перед началом погружения в машинное обучение. Вышеупомянутые задачи дополнялись примером в виде блокнота Jupyter Notebook, который теперь содержит материал из этой статьи.
В этой статье, мы закончим подготовку данных, а также построим первую модель для построения карт покрова земли для Словении в 2017 году.
Подготовка данных
Количество кода, которое непосредственно касается машинного обучения, достаточно мало по сравнению с полной программой. Львиная доля работы состоит в очистке данных, манипуляцией над данными таким образом, что бы обеспечить бесшовное использование с классификатором. Далее будет описана именно эта часть работы.

Диаграмма конвейера для машинного обучения, которая показывает что сам код, использующий ML, является малой долей всего процесса. Источник
Фильтрация облачных изображений
Облака — это сущности, которые обычно появляются в масштабах, превышающих наш средний EOPatch (1000х1000 пикселей, разрешение 10м). Это означает, что любой участок может быть полностью покрыт облаками в случайные даты. Такие снимки не содержат полезной информации и только потребляют ресурсы, поэтому мы пропускаем их, исходя из соотношения валидных пикселей к полному количеству, и устанавливаем порог. Валидными мы можем назвать все пиксели, которые не классифицированы как облака и находятся внутри спутникового снимка. Заметим также, что мы не используем маски, поставляемые вместе со снимками Sentinel-2, поскольку они рассчитываются на уровне полных снимков (размер полного снимка S2 составляет 10980х10980 пикселей, примерно 110х110 км), а значит по большей части не нужны для нашей AOI. Для определения облаков, будем использовать алгоритм из пакета s2cloudless для получения маски облачных пикселей.
В нашем блокноте, порог установлен в 0.8, таким образом мы выбираем только снимки, заполненные нормальными данными на 80%. Это может прозвучать как довольно высокое значение, но поскольку облака не являются слишком большой проблемой для нашей AOI, мы можем себе это позволить. Стоит учесть, что такой подход нельзя бездумно применять к любой точке на планете, поскольку выбранная вами местность может быть покрыта облаками весомую часть года.
Темпоральная интерполяция
Ввиду того, что снимки в некоторые даты могут быть пропущены, а также из-за непостоянных дат получения снимков по AOI, недостаток данных является очень частым явлением в области наблюдения за Землёй. Один из способов решения этой проблемы — это наложение маски валидности пикселей (из предыдущего шага) и интерполяция значений для "заполнения дырок". В результате процесса интерполяции, недостающие пиксельные значения могут быть рассчитаны для создания EOPatch, который содержит в себе снимки по равномерно распределённым дням. В этом примере, мы использовали линейную интерполяцию, но существуют другие методы, некоторые из них уже реализованы в eo-learn .

Слева изображен стек снимков Sentinel-2 по случайно выбранной AOI. Прозрачные пиксели подразумевают пропущенные данные ввиду облаков. Изображение справа демонстрирует стек после интерполяции, при учёте масок облачности.
Темпоральная информация крайне важна в классификации покрова, и еще более важна в задаче определения прорастающей культуры. Это всё ввиду того, что большое количество информации про покров земли сокрыто в том, как участок меняется на протяжении года. Например, при просмотре интерполированных значений NDVI, можно заметить, что значения на территориях лесов и полей достигают своих максимумов весной\летом и сильно падают осенью\зимой, в то время как вода и искусственные поверхности сохраняют эти значения примерно постоянными на протяжении года. Искусственные поверхности имеют слегка более высокие значения NDVI по сравнению с водой, и частично повторяют развитие лесов и полей, поскольку в городах часто часто можно найти парки и другую растительность. Также следует учитывать ограничения, связанные с разрешением снимков — часто на зоне, которую покрывает один пиксель, можно наблюдать одновременно несколько типов покрытия.

Темпоральное развитие значений NDVI для пикселей из конкретных типов земляного покрова на протяжении года
Отрицательная буферизация
Хотя разрешения снимков в 10м достаточно для весьма широкого спектра задач, побочные эффекты небольших объектов весьма значительны. Такие объекты находятся на границе между разными типами покрова, и этим пикселям присваиваются значения лишь одного из типов. Из-за этого при тренировке классификатора во входных данных присутствует лишний шум, что ухудшает результат. К тому же, дороги и другие объекты шириной в 1 пиксель присутствуют на исходной карте, хотя их крайне сложно опознать по изображениям. Мы применяем отрицательную буферизацию в 1 пиксель к референсной карте, удаляя из входных данных почти все проблемные участки.

Референсная карта AOI до(слева) и после(справа) отрицательной буферизации
Случайный выбор данных
Как упоминалось в прошлой статье, полная AOI разделена примерно на 300 фрагментов, каждый из которых состоит из ~1 миллиона пикселей. Это довольно внушительное количество этих самых пикселей, так что мы равномерно берём примерно 40000 пикселей на каждый EOPatch что бы получить набор данных из 12 миллионов экземпляров. Поскольку пиксели взяты равномерно, большое количество не имеют значения на референсной карте, поскольку эти данные неизвестны (или были утеряны после предыдущего шага). Имеет смысл отсеять такие данные для упрощения тренировки классификатора, поскольку нам нет необходимости учить его определять метку "no data". Аналогичную процедуру повторяем для проверочного множества, поскольку такие данные искусственно ухудшают показатели качества предсказаний классификатора.
Разделение и формирование данных
Входные данные мы разделили на множества тренировки/проверки в соотношении 80/20% соответственно еще на уровне EOPatch, что гарантирует нам, что эти множества не пересекаются. Пиксели из множества для тренировки мы также делим на множества для тестирования и кросс-валидации тем же образом. После разделения, мы получаем массив numpy.ndarray размерностью (p,t,w,h,d), где:
p — количество EOPatch в наборе данных
t — количество интерполированных снимков для каждого EOPatch
*w, h, d — ширина, высота, и количество слоёв в снимках, соответственно.
После выбора подмножеств, ширина w соответствует количеству выбранных пикселей (напр. 40000), при этом размерность h равна 1. Разница в форме массива не меняет ничего, эта процедура необходима только для упрощения работы с изображениями.
Данные с сенсоров и маски d в любом снимке t определяют входные данные для тренировки, где таких экземпляров в сумме p*w*h. Для того что бы преобразовать данные в форму, удобоваримую для классификатора, мы должны уменьшить размерность массива с 5 до матрицы, формы (p*w*h, d*t). Это легко сделать используя следующий код:
import numpy as np p, t, w, h, d = features_array.shape # передвинуть ось t axis с позиции 1 к позиции 3 features_array = np.moveaxis(features_array, 1, 3) # изменить форму массива features_array = features_array.reshape(p*w*h, t*d)
Такая процедура позволит делать предсказание по новым данным такой же формы, и потом преобразовать их назад и визуализировать их стандартными средствами.
Создание модели для машинного обучения
Оптимальный выбор классификатора сильно зависит от конкретной задачи, и даже при правильном выборе нельзя забывать про параметры конкретной модели, которые нужно менять от задачи к задаче. Обычно необходимо проведение множества экспериментов с разными наборами параметров для того, что бы точно сказать, что необходимо в конкретной ситуации.
В этом цикле статей мы используем пакет LightGBM, поскольку он представляет собой интуитивный, быстрый, распределённый и производительный фреймворк для построения моделей, основанных на деревьях решений. Для подбора гиперпараметров классификатора, можно использовать разные подходы, такие как поиск по решётке, которые следует испытывать на проверочном множестве. Для простоты примера, этот шаг мы упустим и будем использовать параметры по умолчанию.
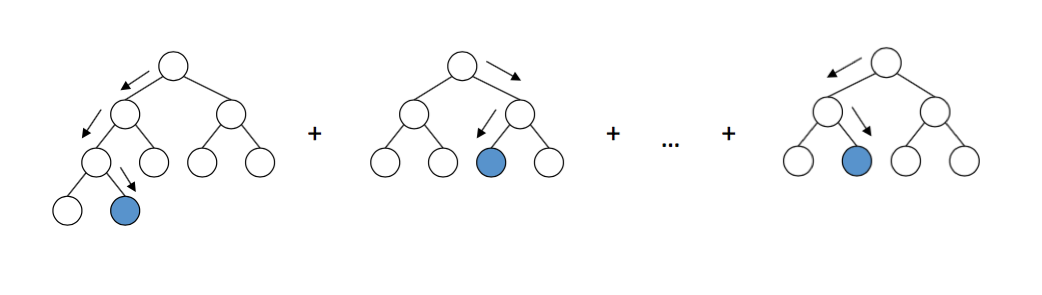
Схема работы деревьев решений в LightGBM. Источник
Реализация модели довольна простая, и поскольку данные уже приходят в форме матрицы, мы просто подаём эти данные на вход модели и ждём. Поздравляем! Теперь вы можете рассказывать всем, что вы занимаетесь машинным обучением и будете самым модным парнем на тусовке, в то время как ваша мама будет нервничать по поводу восстания роботов и смерти человечества.
Валидация модели
Тренировка моделей в машинном обучении — дело лёгкое. Сложность заключается в том, что бы натренировать их хорошо. Для этого, нам необходим подходящий алгоритм, надёжная референсная карта, и достаточное количество вычислительных ресурсов. Но даже в этом случае результаты могут быть не тем, чего вы хотели, так что проверка классификатора матрицами ошибок и другими метриками абсолютно необходима для хоть какой-то уверенности в результатах своего труда.
Матрица ошибок
Матрицы ошибок — это первое, на что следует смотреть при оценке качества классификаторов. Они показывают количество правильно и неправильно предсказанных меток для каждой метки из референсной карты и наоборот. Обычно, используют нормализированную матрицу, где все значения в строчках делят на общую сумму. Это показывает, нет ли у классификатора смещения в сторону определённого типа покрова относительно другого

Две нормализированные матрицы ошибок натренированной модели.
Для большинства классов модель показывает хорошие результаты. Для некоторых классов возникают ошибки, связанные с несбалансированностью входных данных. Мы видим, что проблему представляют, например, кусты и вода, для которых модель часто путает метки пикселей и идентифицирует их неправильно. С другой стороны, то, что помечено как куст или вода соотносится достаточно хорошо с референсной картой. Из следующего изображения мы можем заметить, что проблемы возникают для классов, у которых малое количество тренировочных экземпляров — в основном, это из-за малого количество данных в нашем примере, но эта проблема может возникнуть в любой реальной задаче.
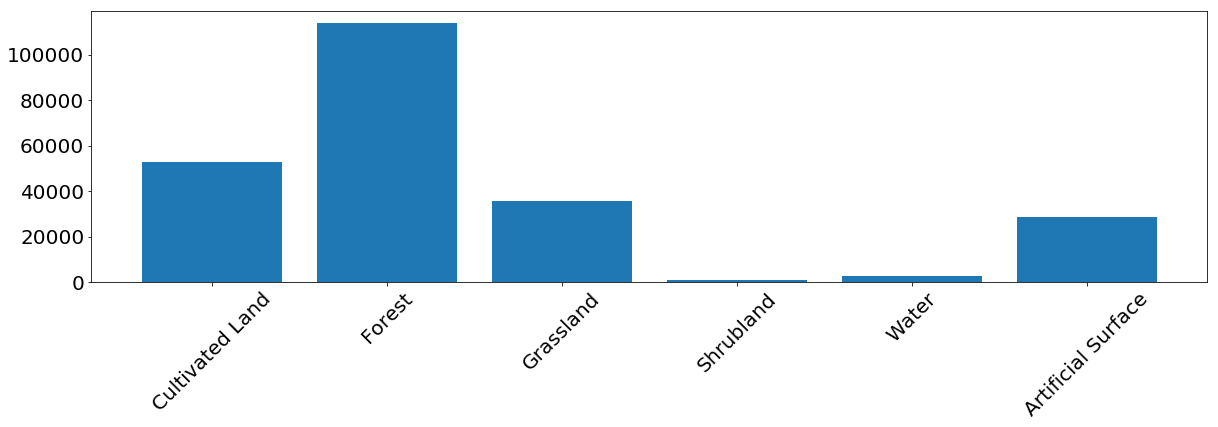
Частота появления пикселей каждого класса в тренировочном множестве.
Reciever Operating Characteristic — ROC-кривая
Классификаторы предсказывают метки с определённой уверенностью, но этот порог для конкретной метки можно менять. ROC-кривая показывает способность классификатора к правильным предсказаниям при смене порога чувствительности. Обычно этот график используют для бинарных систем, но его можно использовать в нашем случае, если мы посчитаем характеристику "метка против всех остальных" для каждого класса. По оси x отображены ложно-положительные результаты (нам нужно минимизировать их количество), а по оси y изображены истинно-положительные результаты (нам нужно увеличить их количество) на разных порогах. Хороший классификатор можно описать кривой, под которой площадь кривой максимальна. Этот показатель также известен как area under curve, AUC. Из графиков ROC-кривых можно сделать те же выводы про недостаточное количество примеров класса "куст", хотя кривая для воды выглядит гораздо лучше — это ввиду того, что визуально вода сильно отличается от других классов, даже при недостаточном количестве примеров в данных.

ROC-кривые классификатора, в виде "один против всех" для каждого класса. Числа в скобках — это значения AUC.
Важность признаков
Если хочется копнуть глубже в тонкости работы классификатора, можно посмотреть на график важности признаков (feature importance), который говорит нам, какие из признаков сильнее повлияли на конечный результат. Некоторые алгоритмы машинного обучения, например, который использовали мы в этой статье, возвращают эти значения. Для других моделей эту метрику необходимо считать самим.

Матрица важности признаков для классификатора из примера
Несмотря на то, что другие признаки весной (NDVI) в целом более важны, мы видим что есть точная дата когда один из признаков (B2 — синий) является самым важным. Если посмотреть на снимки, оказывается, что AOI в этот период была покрыта снегом. Можно сделать вывод, что снег открывает информацию про подлежащий покров, что сильно помогает классификатору определить тип поверхности. Стоит помнить, что подобное явление специфично для наблюдаемой AOI и в целом на него нельзя полагаться.

Часть AOI в виде сетки 3х3 EOPatch, покрытые снегом
Результаты предсказаний
После проведения валидации, мы лучше понимаем достоинства и недостатки нашей модели. Если нас не устраивает текущее положение дел, можно внести изменения в конвейер и попробовать снова. После оптимизации модели, мы определяем простую EOTask, которая принимает EOPatch и модель классификатора, делает предсказание и применяет его к фрагменту.
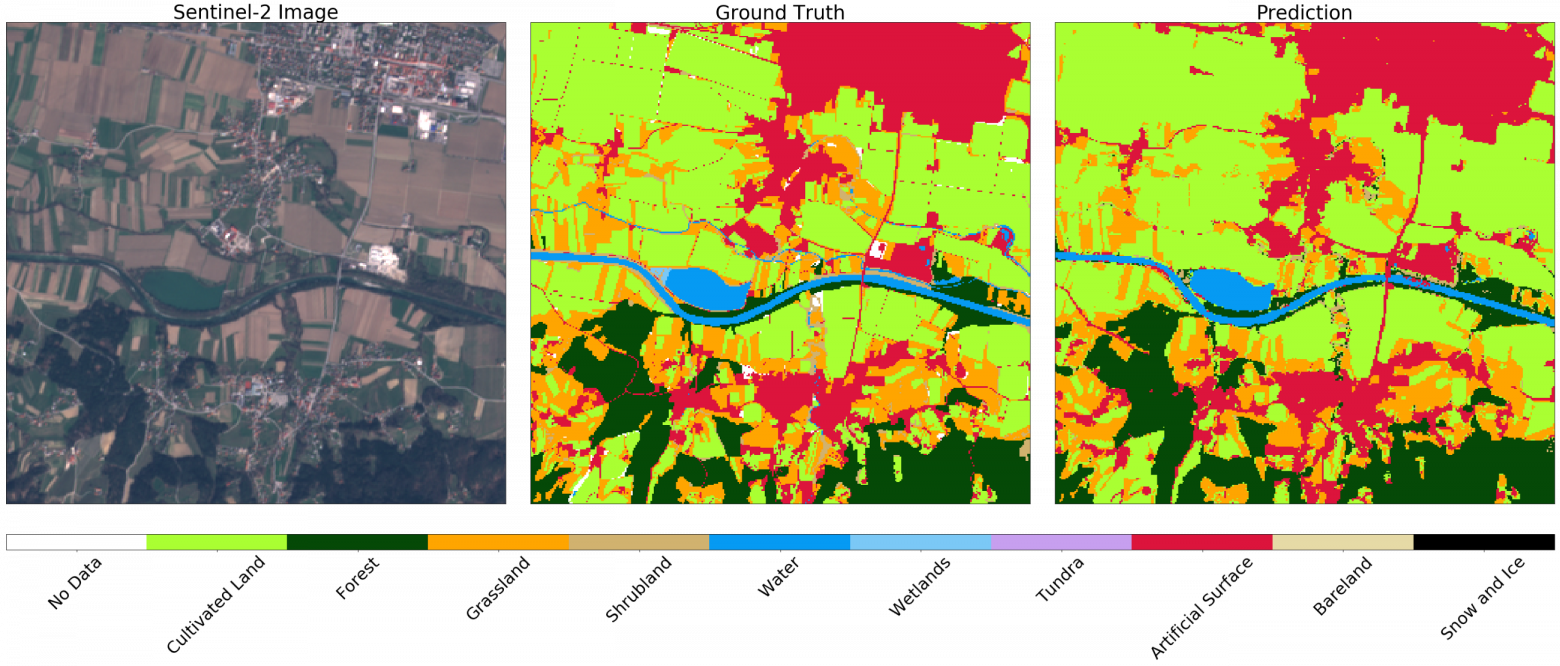
Изображение Sentinel-2(слева), истина(центр) и предсказание(справа) для случайного фрагмента из AOI. Можно заметить некоторые различия в изображениях, которые можно объяснить применением отрицательной буферизации на исходной карте. В целом результат для данного примера удовлетворителен.
Дальнейший путь ясен. Необходимо повторить процедуру для всех фрагментов. Можно даже экспортировать их в формате GeoTIFF, и склеить их при помощи gdal_merge.py .
Мы загрузили склеенный GeoTIFF на наш портал GeoPedia, вы можете посмотреть результаты в деталях здесь

Скриншот предсказания покрытия земли Словения-2017 используя подход из этого поста. Доступен в интерактивном формате по ссылке выше
Вы также можете сравнить официальные данные с результатом работы классификатора. Обратите внимание на разницу между понятиями land use и land cover, которая часто встречается в задачах машинного обучения — не всегда можно легко отобразить данные из официальных реестров на классы в природе. В качестве примера, мы покажем два аэропорта в Словении. Первый — Левец, возле города Целе. Этот аэропорт маленький, в основном используется для частных самолётов, и покрыт травой. Официально территория помечена как искусственная поверхность, хотя классификатор способен правильно определить территорию как траву, см. ниже.

Изображение Sentinel-2(слева), истина(центр), и предсказание(справа) для зоны вокруг маленького спортивного аэропорта. Классификатор определяет посадочную полосу как траву, хотя она помечена как искусственная поверхность в настоящих данных.
С другой стороны, в самом большом аэропорту Словении, Любляна, зоны, помеченные как искусственная поверхность на карте — являются дорогами. В этом случае классификатор различает строения, при этом корректно отличает траву и поля на соседней территории.

Изображение Sentinel-2(слева), истина(центр), и предсказание(справа) для зоны вокруг Любляны. Классификатор определяет взлётную полосу и дороги, при этом корректно отличает траву и поля по соседству
Вуаля!
Теперь вы знаете как создать надёжную модель в масштабе целой страны! Не забудьте добавить это в ваше резюме.

