
Эта статья об агентах машинного обучения в Unity написана Майклом Лэнхемом — техническим новатором, активным разработчиком под Unity, консультантом, менеджером и автором многих игр на движке Unity, графических проектов и книг.
Разработчики Unity внедрили поддержку машинного обучения и в частности глубинного обучения с подкреплением ради создания SDK глубинного обучения с подкреплением (deep reinforcement learning, DRL) для разработчиков игр и симуляций. К счастью, команда Unity под руководством Дэнни Лэнджа успешно реализована надёжный и современный движок DRL, способный показывать впечатляющие результаты. В качестве основы движка DRL Unity использует модель proximal policy optimization (PPO); эта модель значительно сложнее и в некоторых аспектах может отличаться.
В этой статье я познакомлю вас с инструментами и SDK для создания агентов DRL в играх и симуляциях. Несмотря на новизну и мощь этого инструмента, его легко использовать и он имеет вспомогательные инструменты, позволяющие осваивать концепции машинного обучения на ходу. Для работы с туториалом необходимо установить движок Unity.
Установка ML-Agents
В этом разделе я вкратце расскажу о тех шагах, которые необходимо сделать для установки ML-Agents SDK. Этот материал пока находится в состоянии беты и может меняться от версии к версии. Выполните следующие шаги:
- Установите на компьютер Git; он работает из командной строки. Git — это очень популярная система управления исходным кодом, и в Интернете есть множество ресурсов об установке и использовании Git на разных платформах. После установки Git, убедитесь, что она работает, создав клон любого репозитория.
- Откройте командную строку или обычную оболочку. Пользователи Windows могут открыть окно Anaconda.
- Перейдите в рабочую папку, в которую вы хотите поместить свой новый код, и введите следующую команду (пользователи Windows могут выбрать C:\ML-Agents):
git clone https://github.com/Unity-Technologies/ml-agents
- Так вы клонируете репозиторий ml-agents на свой компьютер и создадите новую папку с тем же именем. Можно также добавить к названию папки номер версии. Unity, как и почти весь мир искусственного интеллекта, постоянно меняется, по крайней мере, сейчас. Это означает, что постоянно появляются новые изменения. На момент написания статьи мы клонируем репозиторий в папку ml-agents.6:
git clone https://github.com/Unity-Technologies/ml-agents ml-agents.6
- Создайте новую виртуальную среду для ml-agents и укажите версию 3.6, вот так:
#Windows conda create -n ml-agents python=3.6 #Mac Use the documentation for your preferred environment
- Активируйте среду снова с помощью Anaconda:
activate ml-agents
- Установите TensorFlow. В Anaconda это можно сделать следующей командой:
pip install tensorflow==1.7.1
- Установите пакеты Python. В Anaconda введите следующее:
cd ML-Agents #from root folder cd ml-agents or cd ml-agents.6 #for example cd ml-agents pip install -e . or pip3 install -e . - Так вы установите все необходимые для Agents SDK пакеты; это может занять несколько минут. Не закрывайте окно, скоро оно нам пригодится.
Так мы выполнили установку и настройку Unity Python SDK для ML-Agents. В следующем разделе мы узнаем, как настроить и обучить одну из множества сред, предоставляемых Unity.
Обучение агента
Теперь мы можем сразу приступить к делу и изучить примеры, в которых применяется глубинное обучение с подкреплением (DRL). К счастью, в составе тулкита нового агента есть несколько примеров для демонстрации мощи движка. Откройте Unity или Unity Hub, и выполните следующие действия:
- Нажмите на кнопку Open project в верхней части диалогового окна Project.
- Найдите и откройте папку проекта UnitySDK, как показано на скриншоте:
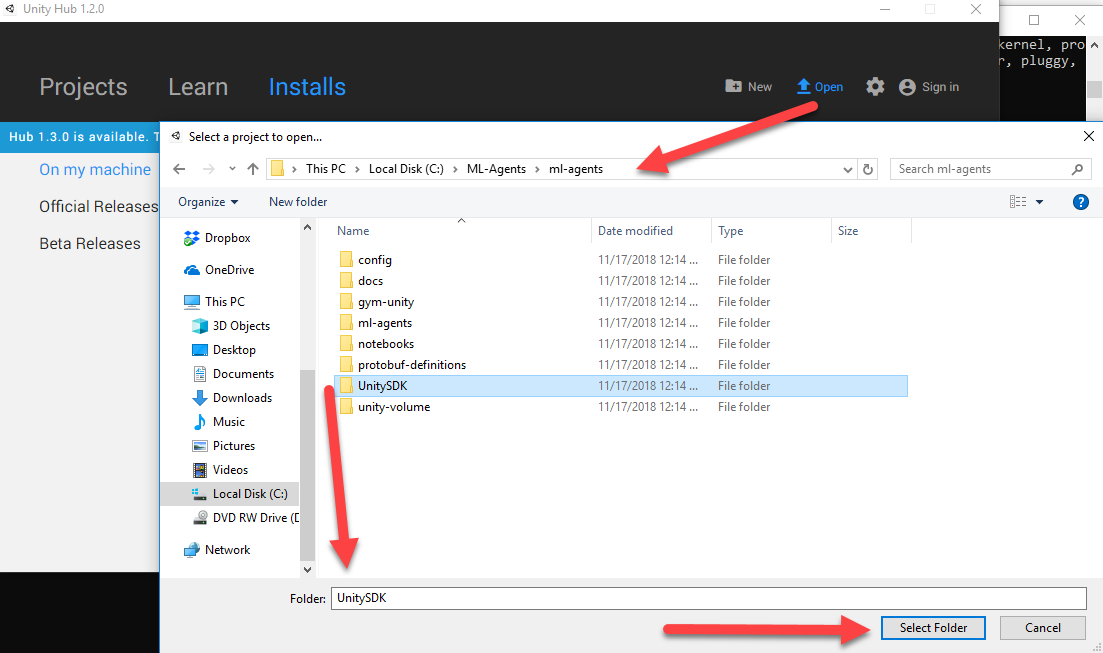
Открываем проект Unity SDK Project - Дождитесь загрузки проекта, а затем откройте окно Project в нижней части редактора. Если откроется окно с запросом обновления проекта, то выберите yes или continue. На данный момент весь код агента имеет обратную совместимость.
- Найдите и откройте сцену GridWorld, как показано на скриншоте:
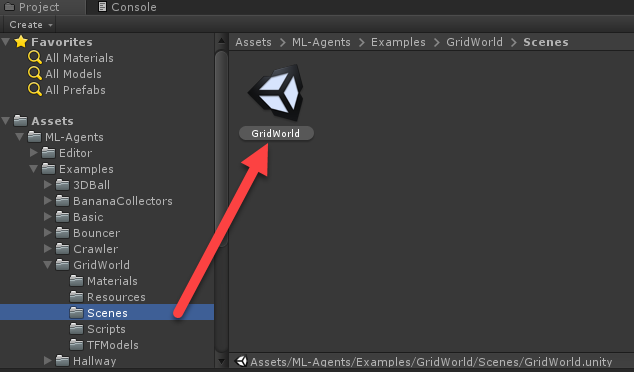
Открываем пример сцены GridWorld - Выберите в окне Hierarchy объект GridAcademy.
- Перейдите к окну Inspector и рядом с полем Brains нажмите на значок, чтобы открыть диалоговое окно выбора Brain:
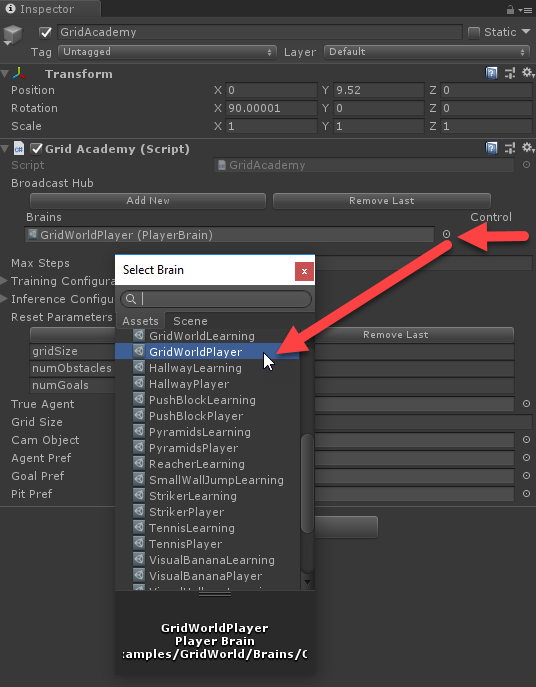
- Выберите «мозг» GridWorldPlayer. Этот мозг принадлежит игроку, то есть игрок (вы) может управлять игрой.
- Нажмите кнопку Play в верхней части редактора и понаблюдайте за средой. Так как игра сейчас настроена на управление игроком, вы можете использовать клавиши WASD для перемещения куба. Задача заключается в перемещении синего куба к зелёному символу +, избегая при этом красного X.
Освойтесь в игре. Заметьте, что игра работает только определённый промежуток времени и не является пошаговой. В следующем разделе мы узнаем, как запустить этот пример с агентом DRL.
Что в мозгу?
Один из потрясающих аспектов платформы ML-Agents заключается в возможности быстро и без проблем переключаться от управления игроком к управлению ИИ/агентом. Для этого Unity использует концепцию «мозга» (brain). Мозг может управляться или игроком, или агентом (обучающийся мозг). Самое потрясающее в том, что вы можете собрать игру и протестировать её как игрок, а затем отдать её под управление RL-агента. Благодаря этому любую написанную игру ценой небольших усилий можно заставить управляться с помощью ИИ.
Процесс настройки и запуска обучения RL-агента в Unity довольно прост. Для построения модели обучающегося мозга Unity использует внешний Python. Использование Python имеет огромный смысл, потому что уже существует несколько построенных на его основе библиотек глубинного обучения (DL). Для обучения агента среде GridWorld выполните следующие шаги:
- Снова выберите GridAcademy и выберите в поле Brains вместо GridWorldPlayer мозг GridWorldLearning:
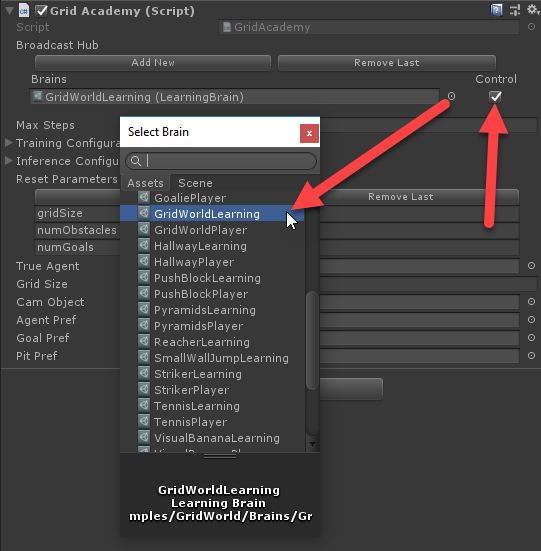
Переключаемся на использование мозга GridWorldLearning - Поставьте справа флажок Control. Этот простой параметр сообщает, что мозг может контролироваться снаружи. Эта опция обязательно должна быть включена.
- Выберите в окне Hierarchy объект trueAgent, а затем в окне Inspector измените свойство Brain в компоненте Grid Agent на мозг GridWorldLearning:
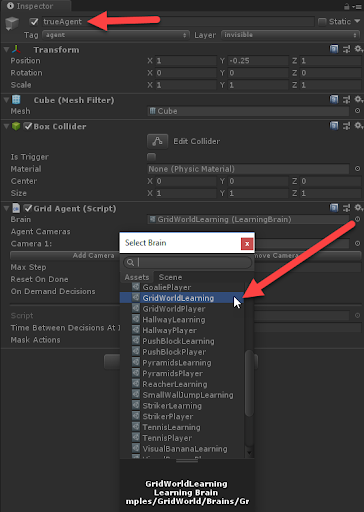
Задание мозга GridWorldLearning для агента - В этом примере нам нужно, чтобы и Academy, и Agent использовали одинаковый мозг GridWorldLearning. Переключитесь на окно Anaconda или Python и выберите папку ML-Agents/ml-agents.
- Выполните в окне Anaconda или Python следующую команду, воспользовавшись виртуальной средой ml-agents:
mlagents-learn config/trainer_config.yaml --run-id=firstRun --train
- Так вы запустите модель обучения Unity PPO и пример агента с указанной конфигурацией. На определённом этапе окно командной строки попросит запустить редактор Unity с загруженной средой.
- Нажмите Play в редакторе Unity, чтобы запустить среду GridWorld. Вскоре после этого вы должны будете увидеть обучение агента и вывод результатов в окно скрипта Python:

Выполнение среды GridWorld в режиме обучения - Заметьте, что скрипт mlagents-learn — это код на Python, который строит RL-модель для запуска агента. Как вы видите из выходных данных скрипта, существует несколько параметров (гиперпараметров), которые нужно сконфигурировать.
- Позвольте агенту поучиться несколько тысяч итераций и заметьте, насколько быстро он обучается. Используемая здесь внутренняя модель под названием PPO проявила себя как очень эффективная для множества разных задач модель обучения, и она очень хорошо подходит для разработки игр. При достаточно мощном оборудовании агент может идеально обучиться менее чем за час.
Позвольте агенту обучаться дальше и изучите другие способы отслеживания процесса обучения агента, представленные в следующем разделе.
Мониторинг обучения с помощью TensorBoard
Обучение агента при помощи модели RL или любой модели DL часто является непростой задачей и требует внимания к деталям. К счастью, в TensorFlow есть набор инструментов построения графиков под названием TensorBoard, который можно использовать для мониторинга процесса обучения. Для запуска TensorBoard выполните следующие действия:
- Откройте окно Anaconda или Python. Активируйте виртуальную среду ml-agents. Не закрывайте окно, в котором запущена модель обучения; нам нужно, чтобы оно продолжалось.
- Перейдите в папку ML-Agents/ml-agents и выполните следующую команду:
tensorboard --logdir=summaries
- Так мы запустим TensorBoard на собственном встроенном веб-сервере. Вы можете загрузить страницу при помощи URL, который показан после предыдущей команды.
- Введите URL для TensorBoard, как показано в окне, или введите в браузере localhost:6006 или machinename:6006. Спустя примерно час вы должны увидеть нечто подобное:
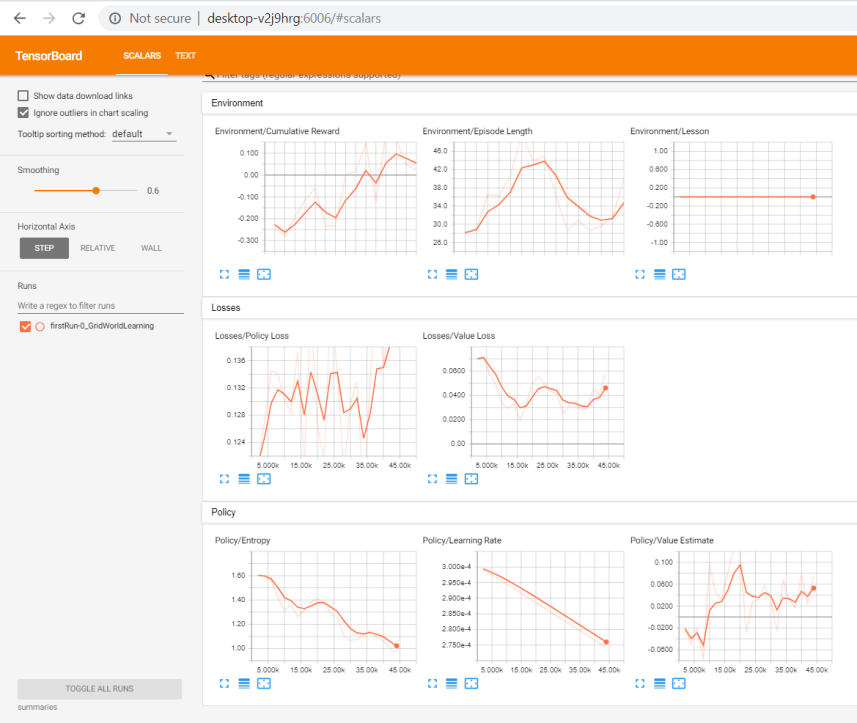
Окно графиков TensorBoard - В предыдущем скриншоте показаны графики, каждый из которых отображает отдельный аспект обучения. Чтобы понять, как обучается наш агент, нужно разобраться с каждым из этих графиков, поэтому мы проанализируем выходные данные из каждого раздела:
- Environment: в этом разделе показано, как агент проявляется себя в среде в целом. Ниже показан более подробный вид графиков с предпочтительным трендом:

Подробная картина графиков раздела Environment
- Cumulative Reward: это общее вознаграждение, которое максимизирует агент. Обычно нужно, чтобы оно увеличивалось, но по некоторым причинам оно может и уменьшаться. Всегда лучше максимизировать вознаграждения в интервале от 1 до -1. Если на графике вознаграждения выходят за пределы этого диапазона, то это тоже необходимо исправить.
- Episode Length: если это значение уменьшается, то обычно это хороший знак. В конечном итоге, чем короче эпизоды, тем больше обучения. Однако имейте в виду, что при необходимости длина эпизодов может увеличиваться, поэтому картина может быть и другой.
- Lesson: этот график даёт понять, на каком уроке находится агент; он предназначен для Curriculum Learning.
- Losses: в этом разделе показаны графики, представляющие вычисленные потери или затраты для политики и значения. Ниже показан скриншот этого раздела со стрелками, указывающими на оптимальные параметры:
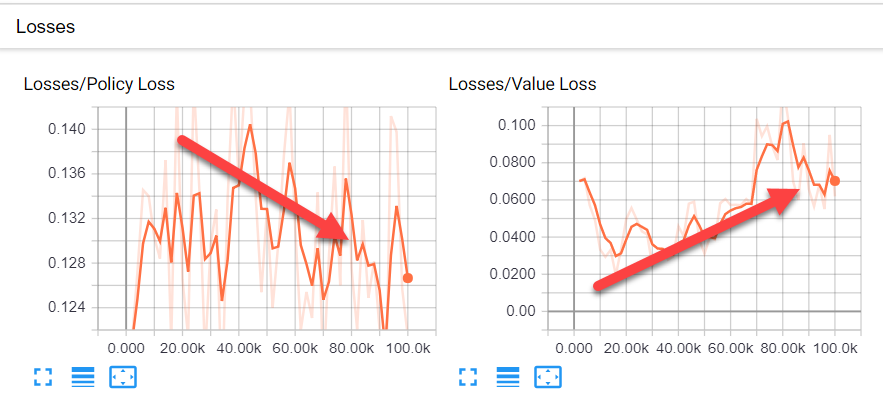
Потери и предпочтительное направление обучения
- Policy Loss: этот график определяет величину изменения политики со временем. Политика — это элемент, определяющий действия, и в общем случае этот график должен стремиться вниз, показывая, что политика всё лучше принимает решения.
- Value Loss: это средняя потеря функции значения. По сути она моделирует, насколько хорошо агент прогнозирует значение своего следующего состояния. Изначально это значение должно увеличиваться, а после стабилизации вознаграждения — уменьшаться.
- Policy: для оценки качества действий в PPO используется концепция политики, а не модели. На скриншоте ниже показаны графики политики и предпочтительный тренд:
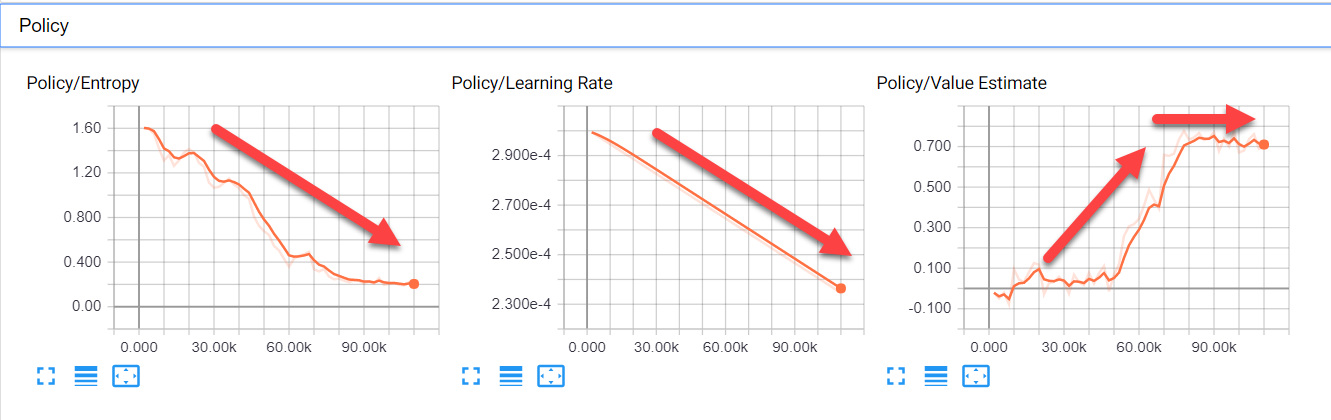
Графики политики и предпочтительные тренды - Entropy: этот график показывает величину исследования агента. Нужно, чтобы это значение уменьшалось, потому что агент узнаёт больше об окружении и ему нужно меньше исследовать.
- Learning Rate: в данном случае это значение должно постепенно линейно уменьшаться.
- Value Estimate: это среднее значение, посещённое всеми состояниями агента. Чтобы отражать увеличение знаний агента, это значение должно расти, а затем стабилизироваться.
6. Оставьте агента выполнять до завершения и не закрывайте TensorBoard.
7. Вернитесь в окно Anaconda/Python, которое обучало мозг, и выполните такую команду:
mlagents-learn config/trainer_config.yaml --run-id=secondRun --train
8. Вас снова попросят нажать Play в редакторе; так и сделайте. Позвольте агенту начать обучение и провести несколько сессий. В процессе этого следите за окном TensorBoard и замечайте, как отображается на графиках secondRun. Можете позволить этому агенту выполняться до завершения, но при желании можно его и остановить.
В предыдущих версиях ML-Agents нужно было сначала собрать исполняемый файл Unity как среду обучения игры, а затем запустить его. Внешний мозг Python должен был работать так же. Этот способ очень усложнял отладку проблем в коде или в игре. В новой методике все эти сложности были устранены.
Теперь, когда мы увидели, как легко настроить и обучить агента, перейдём к следующему разделу, в котором узнаем, как можно запустить агента без внешнего мозга Python и выполнять его напрямую в Unity.
Запуск агента
Обучение Python проходит отлично, но в реальной игре его использовать нельзя. В идеале мы бы хотели построить график TensorFlow и использовать его в Unity. К счастью, была создана библиотека TensorFlowSharp, позволяющая .NET использовать графики TensorFlow. Это позволяет нам строить офлайновые модели TFModels, а позже инъектировать их в игру. К сожалению, мы можем использовать только обученные модели, но не обучать их таким образом, по крайней мере, пока.
Давайте посмотрим, как это работает, на примере графика, который мы только что обучили для среды GridWorld; используем его как внутренний мозг в Unity. Выполните действия из следующего раздела для настройки и использования внутреннего мозга:
- Скачайте плагин TFSharp отсюда
- В меню редактора выберите Assets | Import Package | Custom Package…
- Найдите только что скачанный пакет ассета и используйте диалоговые окна импорта для загрузки плагина в проект.
- В меню выберите Edit | Project Settings. Откроется окно Settings (появилось в версии 2018.3)
- Найдите в Player options символы Scripting Define Symbols и измените текст на ENABLE_TENSORFLOW, а также включите Allow Unsafe Code, как показано на скриншоте:

Установка флага ENABLE_TENSORFLOW - Найдите объект GridWorldAcademy в окне Hierarchy и убедитесь, что он использует Brains | GridWorldLearning. Отключите в разделе Brains скрипта Grid Academy опцию Control.
- Найдите мозг GridWorldLearning в папке Assets/Examples/GridWorld/Brains и убедитесь, что параметр Model в окне Inspector задан, как показано на скриншоте:

Задание модели для мозга - В качестве модели уже должна быть задана GridWorldLearning. В этом примере мы используем TFModel, поставляемую с примером GridWorld.
- Нажмите Play, чтобы запустить редактор и посмотреть, как агент управляет кубом.
Сейчас мы запускаем среду с заранее обученным мозгом Unity. В следующем разделе мы узнаем, как использовать мозг, который мы обучили в предыдущем разделе.
Загрузка обученного мозга
Во всех примерах Unity есть заранее обученные мозги, которые можно использовать для исследования примеров. Разумеется, мы хотим иметь возможность загружать собственные графы TF в Unity и запускать их. Для загрузки обученного графа выполните следующие действия:
- Перейдите в папку ML-Agents/ml-agents/models/firstRun-0. Внутри этой папки есть файл GridWorldLearning.bytes. Перетащите этот файл в папку Project/Assets/ML-Agents/Examples/GridWorld/TFModels внутри редактора Unity:
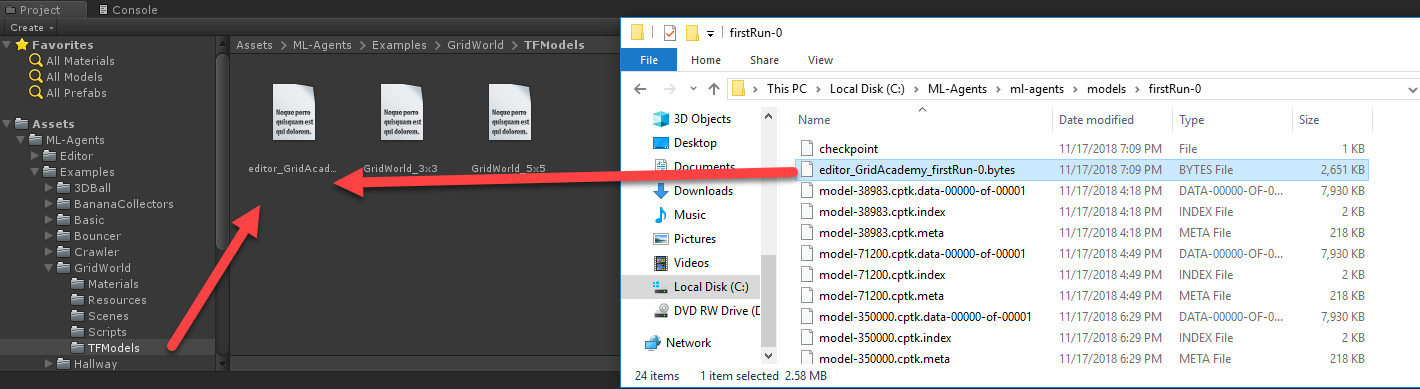
Перетаскивание графа bytes в Unity - Так мы импортируем граф в проект Unity как ресурс и переименуем его в GridWorldLearning 1. Движок делает это, потому что модель по умолчанию уже имеет такое же имя.
- Найдите в папке с мозгами GridWorldLearning, выберите его в окне Inspector и перетащите новую модель GridWorldLearning 1 в поле Model параметров Brain Parameters:
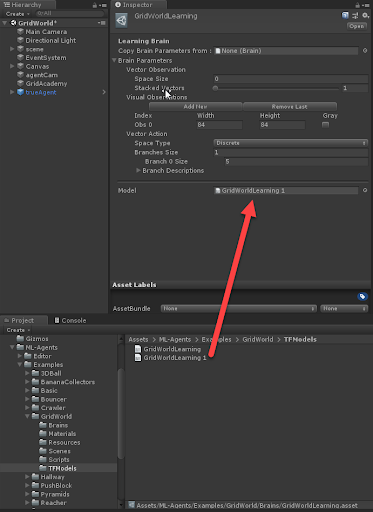
Загрузка мозга в поле Graph Model - На этом этапе нам не нужно менять никаких других параметров, но уделите особое внимание тому, как сконфигурирован мозг. Пока нам подойдут стандартные настройки.
- Нажмите Play в редакторе Unity и посмотрите, как агент успешно движется по игре.
- Успешность агента в игре зависит от времени его обучения. Если вы позволите ему завершить обучение, то агент будет аналогичен к полностью обученному агенту Unity.

